前の記事では前提となる会社の業務を紹介しましたが、どの部署にも「商品」という単語が出てきました。データベースに慣れているみなさんは「はいはい、『商品マスター』でしょ」と思われるところかもしれません。もちろん、商品マスターは作るのですが、なぜ商品マスターが必要なのでしょうか、そして、それだけでいいのでしょうか?ここで、「商品」というキーワードをより詳細に分析してみます。
次の図では、それぞれの部門に対して、「商品とはなんでしょうか?」と質問した結果だと考えてください。実際、要求分析をするときに、そんなダイレクトな質問はいろんな意味で(機会やあるいは適切な担当者と話ができるのかなどを含めて)無理でしょうし、しかもちゃんと答えてくれるとも限りません。通常は、いろんなインタビューをもとに、分析者がこうではないだろうかと考えるのが一般的かと思います。なお、前回は経営者が出てきましたが、言っていることが曖昧なので、ここから先は3部門だけに絞りましょう。

営業部門にとって、商品は売っているものです。製造部門は作っているものです。この辺りは明確でしょうけど、どうもマーケティング部門にとっては、商品というのは何なのかということがどうも曖昧で、具体的に言いづらい感じです。おそらく、状況によって変わるのでしょう。
ここで、部署ごとに、商品をどのように扱っているのかをみてみましょう。それを示したのが次の図です。

まず、製造部門は、製造した商品1つ1つをどうやら管理したいようです。つまり、商品の箱1つ1つが対象になります。一方、営業部門は、商品の箱があることは理解しているでしょうけど、商品そのものを集合的に扱います。しかも、製造部門は、商品の物理的なことを考えなければなりませんので、在庫ということまでもしかして考えているかもしれませんが、営業部門はおそらく商品という存在を移動させているという考えが支配的ではないでしょうか。つまり、営業担当者は、実際に自分で箱を手に取って顧客に届けているというよりも、伝票を書いて、ロジスティックスに依頼をするわけで、実際に商品そのものを目に見ていることは滅多にないようなのがいわゆる営業という活動ではないかと思われます。マーケティングに至ってはなんだかわかりませんが、インタビューでどうやら商品カタログの管理くらいは必要なことがわかったという程度です。
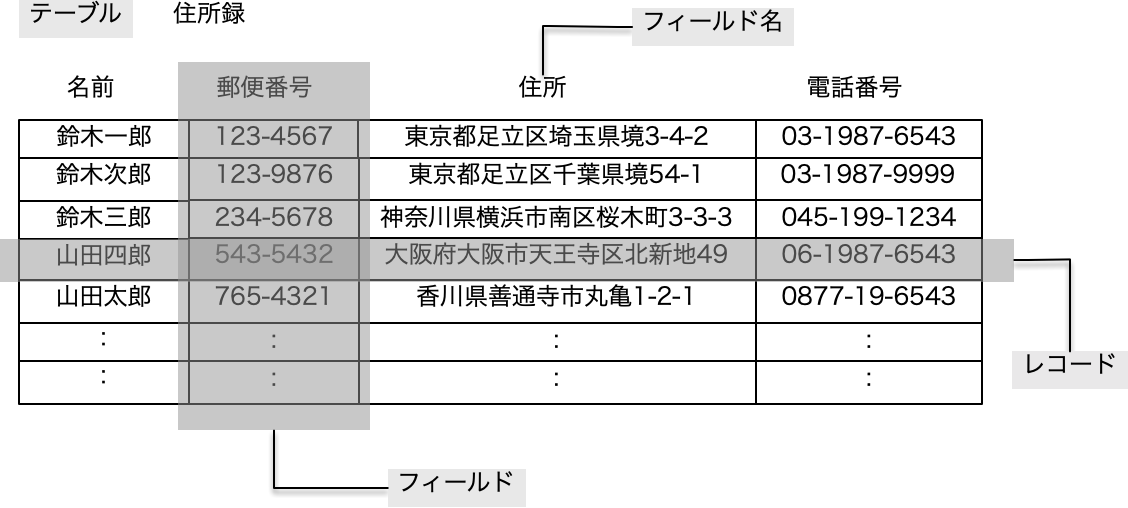
同じ商品という呼び方をしているのに、このように部署によって実は扱う概念が大きく変わってきます。当然、それらを一緒くたにするのは問題があると考えます。部署ごとに違いがある一方、共通の概念もあります。例えば、商品名は社内で統一的に扱われているはずです。一方、商品の単価が業務上必要でしょうか? 販売部門は伝票を作成するのに必要そうです。一方、製造部門は単価が存在しても、業務上は通常は使わないでしょう。一方、マーケティングはおそらく単価情報は、業績等をチェックするような場合に使うかもしれません。商品1つずつにつけるシリアル番号はどうでしょう? 製造部門には必須かもしれませんが、営業部門には興味のないデータです。このように、共通のものと共通でないものが存在するのです。
ドメイン駆動開発の世界では、こうした概念を「ユビキタス言語」として捉えます。ある特定のコミュニティで通用する言語なのですが、つまり、ここでは「営業部門言語の商品」と「製造部門言語の商品」に若干の違いがあると考えて、これらの部門間では異なるユビキタス言語が使われていると考えます。同じ言葉で違う概念があるということは、ドメインつまり「業務そのものの定義」が異なるという考え方です。実は、商品というよく似た言葉でも、このような違いがあるものの、社内で働いていると、なんとなくそういうものだということでドメインが違うことは気づきにくいものです。まさに、第三者が設計するときに、そうしたドメインの違いを見出すことができ、業務の整理が進むということが期待できます。もちろん、分析者や開発者は、顧客のドメインを理解し、ユビキタス言語を使いこなせるくらいになっていることが理想です。
ユビキタス言語は、そのドメインのモデルの基礎になるものです。言語を構成する概念を整理したものがモデルとして利用できるでしょう。ユビキタス言語はモデルが表面に出てきたものでもあります。私たちは、ドメインのモデルを知りたいのです。そのモデルをデータベースに実装すれば、システムは成功するはずです。モデルを探るのが要求分析であり設計です。その手がかりがユビキタス言語にもあるということです。
ちなみに、1つの言葉が異なる概念を示すだけでなく、異なる言葉が同じものを指す場合もありますし、1つの単語が状況によって異なるものを示す場合もあります。最後の例は1つの単語が同一職場の同一業務で状況によって違っていたのですが、よくそれでトラブル発生しないもんだと思ってしまいます。たまたま問題にならなかったのでしょう。言葉というのはコンテキストを引き連れて登場するので、区別は可能なのかもしれませんが、外部からその世界に入ってきた人には面食らってしまう事象です。こういう事例があった場合は、ドメインをまたがって用語の整理をするのが理想なのですが、なかなか業務の上で使い続けている言葉は変えてもらえないのが実情です。
ドメイン駆動開発といえば、現在はマイクロサービシズで話題になっていますが、ドメイン駆動開発の方が先に提唱されていた概念です。マイクロサービシズでは、どんなサービスに分割をするのかというのが設計上の大きな問題です。ここでサービスの分割を考えるとき、ユビキタス言語の通用する範囲を重視するという考え方があります。これを、非常に雑に考えると、要するに部署ごとに別システムであり、部署間の動きが必要ならそれはシステム連携だろう、そしてシステムは1つのマイクロサービスであるとも言えるとも言えます。実は、マイクロサービスシズの勉強を一時期頑張っていた時期があり、いろんな資料に当たったのですが、あっさりと「マイクロサービシズは、部署ごとに分ます、以上」と説明されているものがありました。その資料ではドメイン駆動開発やユビキタス言語といった抽象概念はすっ飛ばしていました。あらあらと思いつつ、非常に大まかに言えばそういうことで、間違いはないかもしれませんが、会社の部門構成が最適化されていないと色々苦しいだろうなと思ったりもします。しかし、最適化されていない会社ってきっと破綻するでしょうから、システム作っても早晩使われなくなる? ということで、部署でサービス分けるというのはあながち悪いサジェスチョンではないと思った次第です。そこで、ここでの実例も、部署を単位にしてみました。
商品のような基本的な単語でも、そのドメインによって役割が違うようです。実際、みなさんの会社やあるいは扱った案件ではどうでしょう? 他には「在庫」なんてどうでしょう。在庫と言ってもいろんな概念があります。会計的には在庫は金額ですが、倉庫で働く人にとってはそこにあるたくさんの段ボールだったりします。商品や在庫などはどの会社でもあるようなものなので、ある意味では扱い方はある程度はわかっているようなものでもあり、経験則も適用できるかもしれませんが、むしろ、わかったつもりになるのは危険で、そのドメイン特有のルールや扱い方がないかを常にアンテナを張るくらいの気持ちがないと、後から気づいて大きく出戻りが発生するということにもなりかねません。商品や在庫だけでなく、部署ごとに違う、あるいは担当者ごとに違うような概念がないかを見つけてみるのも良いでしょう。また、部署で違うだけでなく、部署を横断するようなドメインの存在も見えてくるかもしれません。要求分析以降は常にドメインやそこでのモデルを意識する必要があります。
次回は、異なる概念を表を作って捉えるということを説明しましょう。