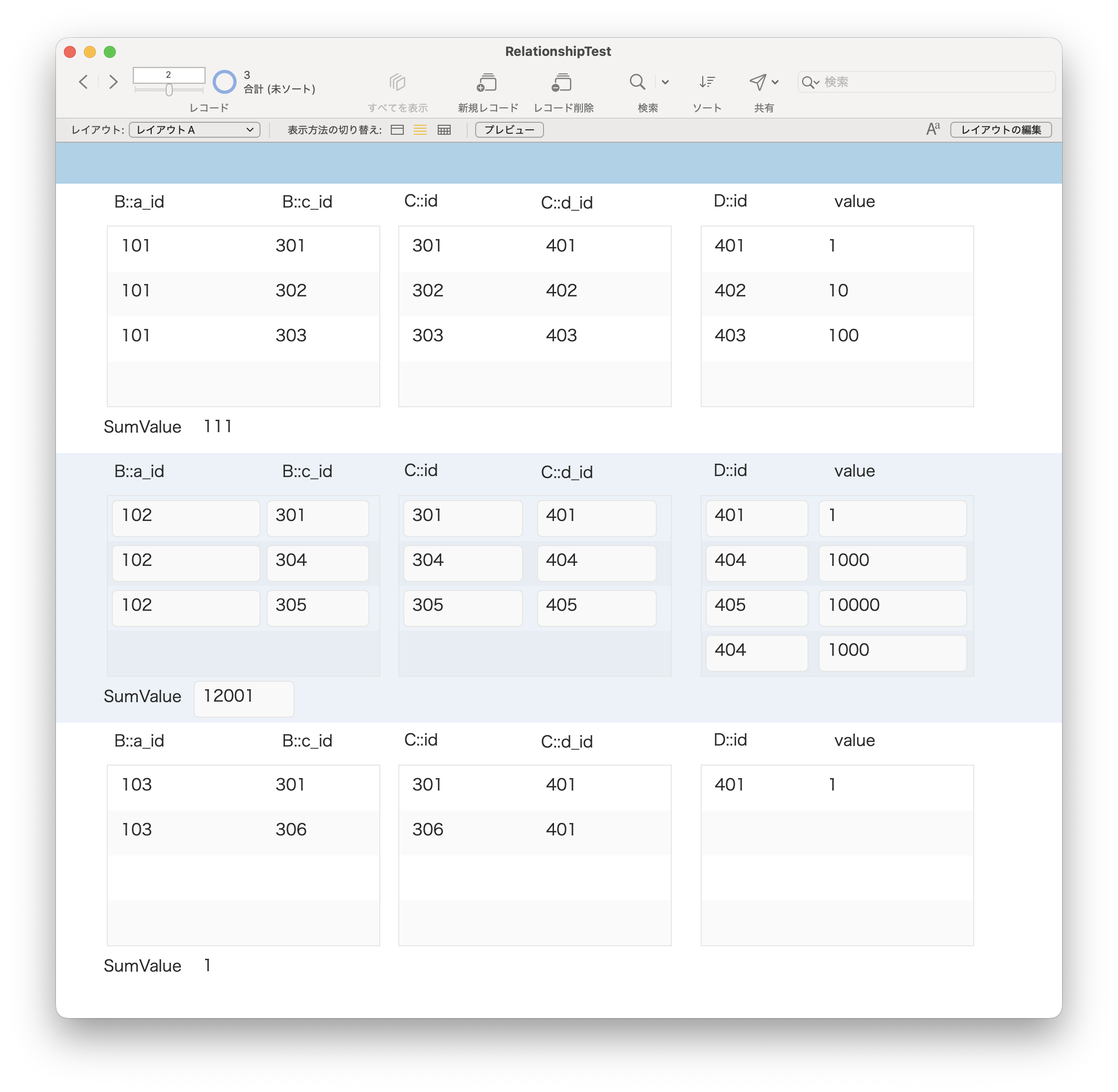
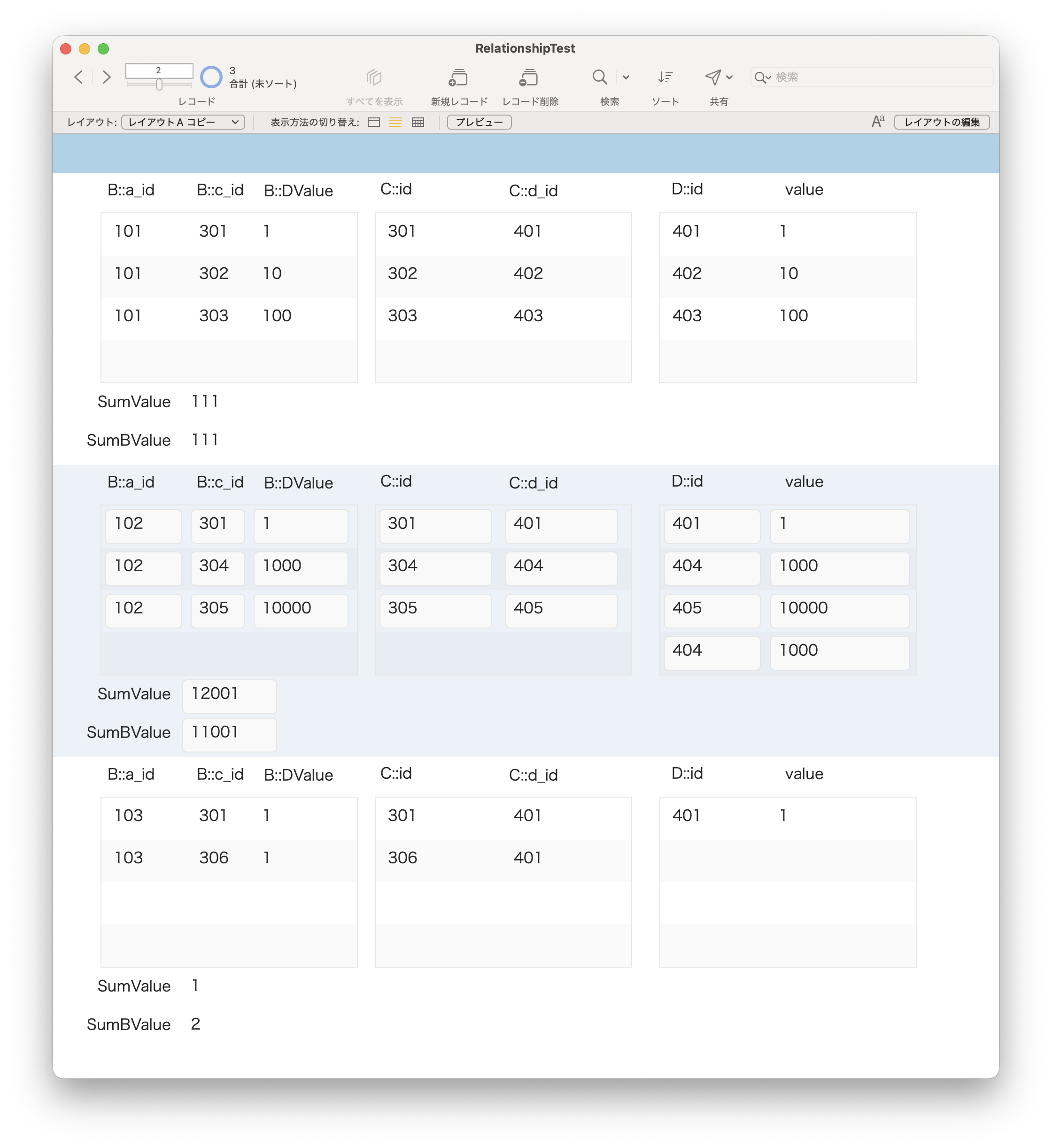
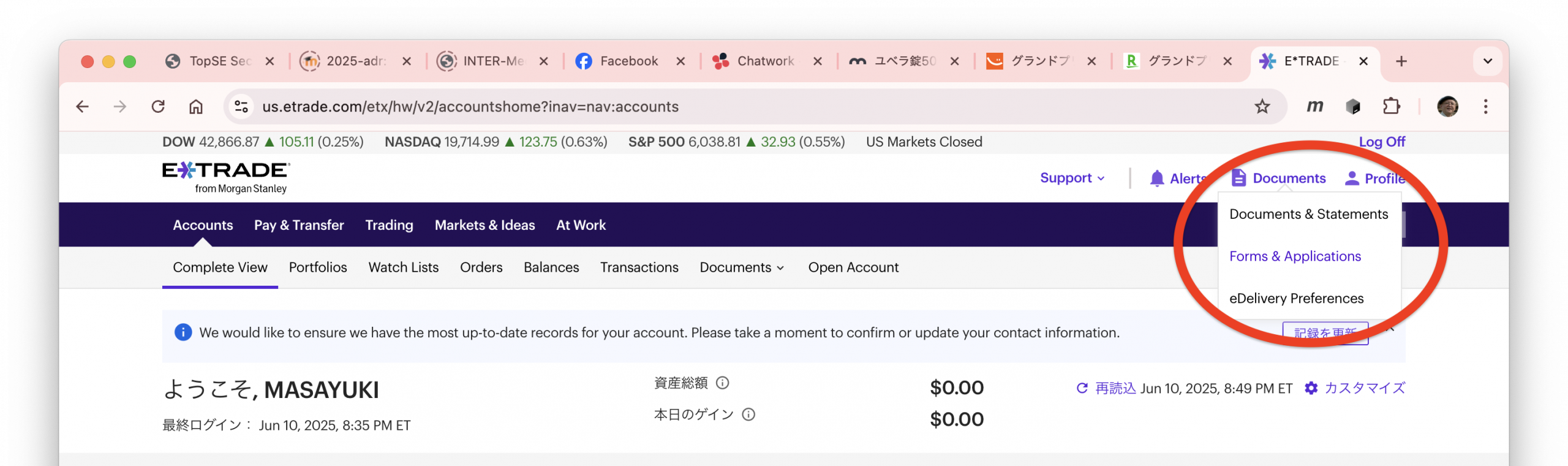
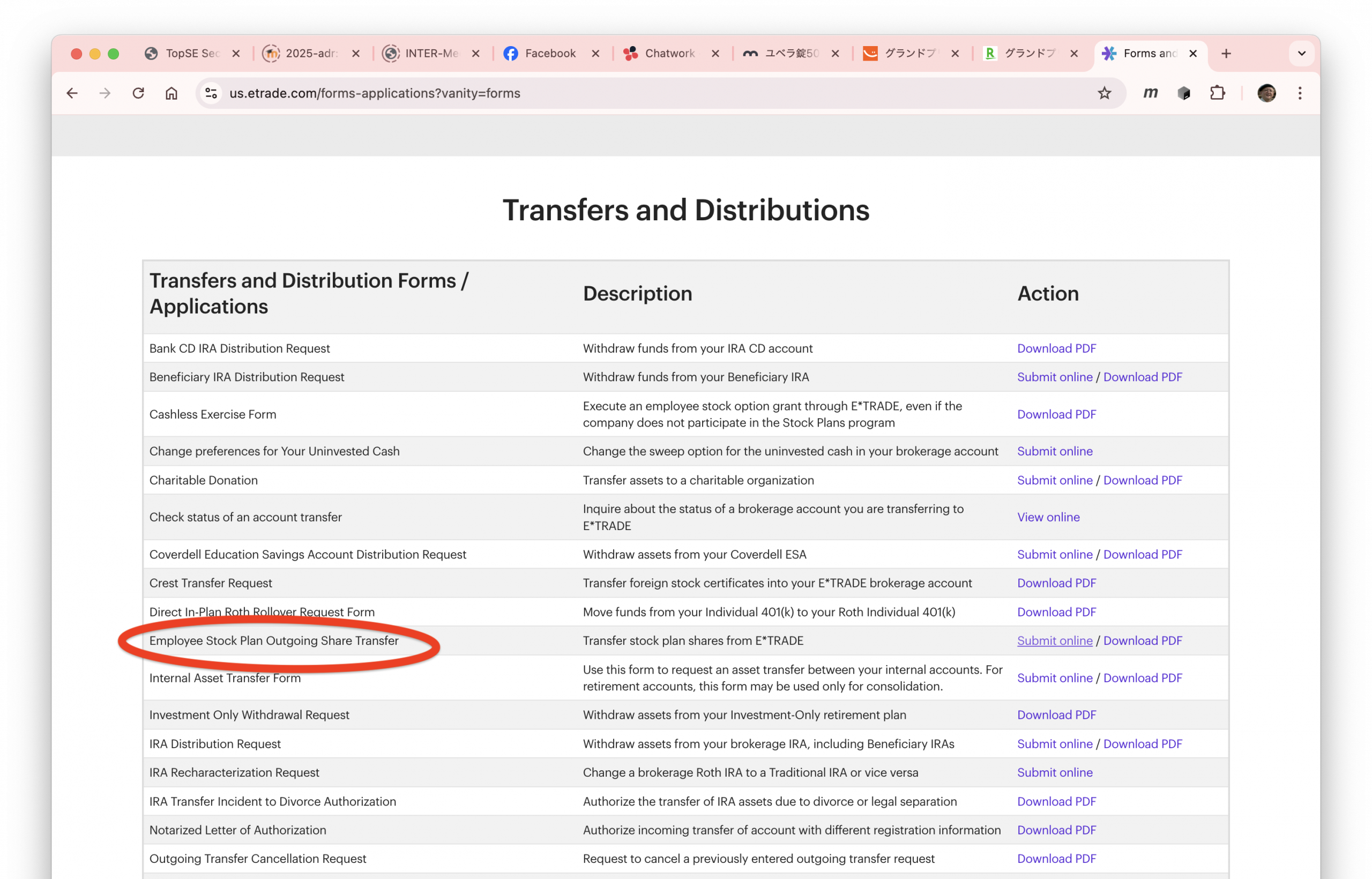
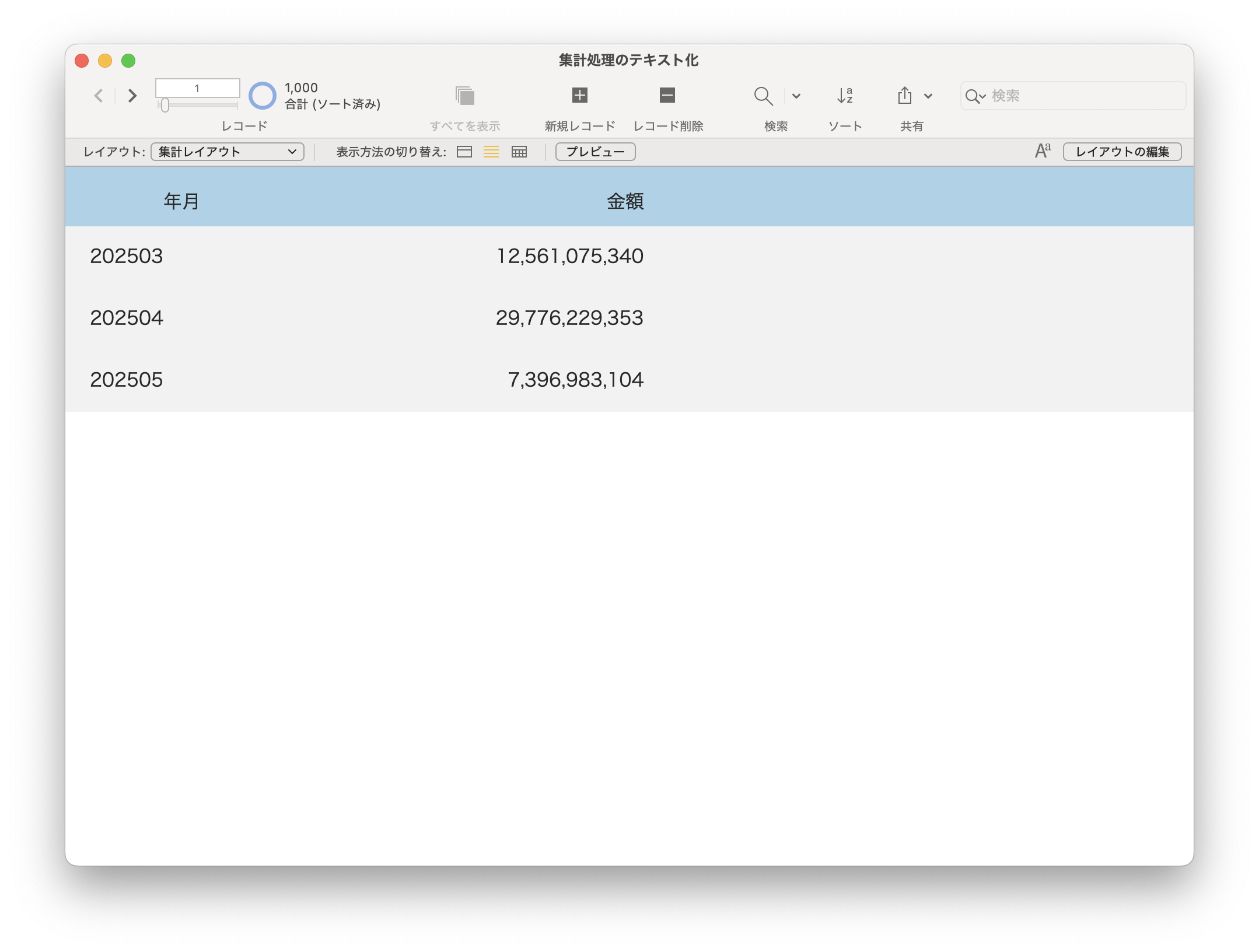
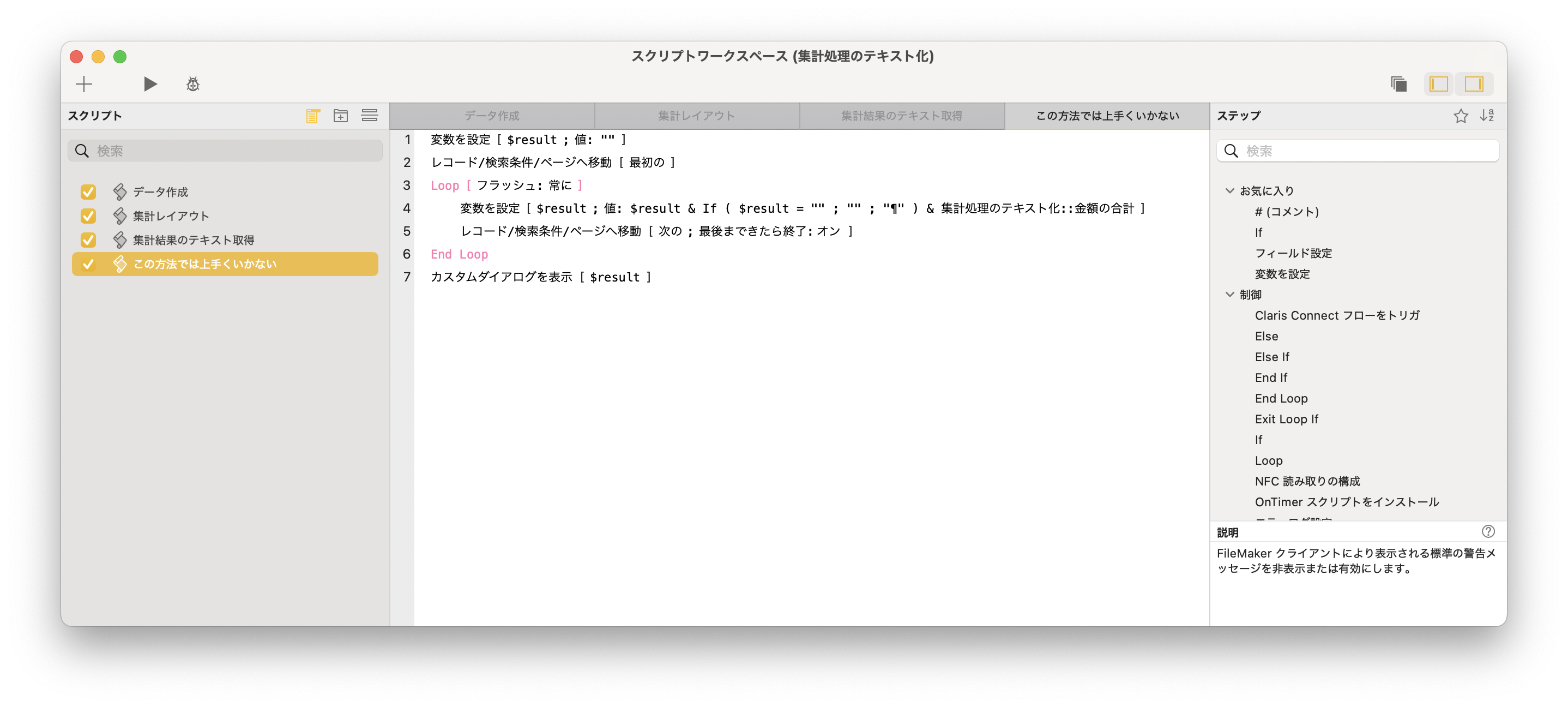
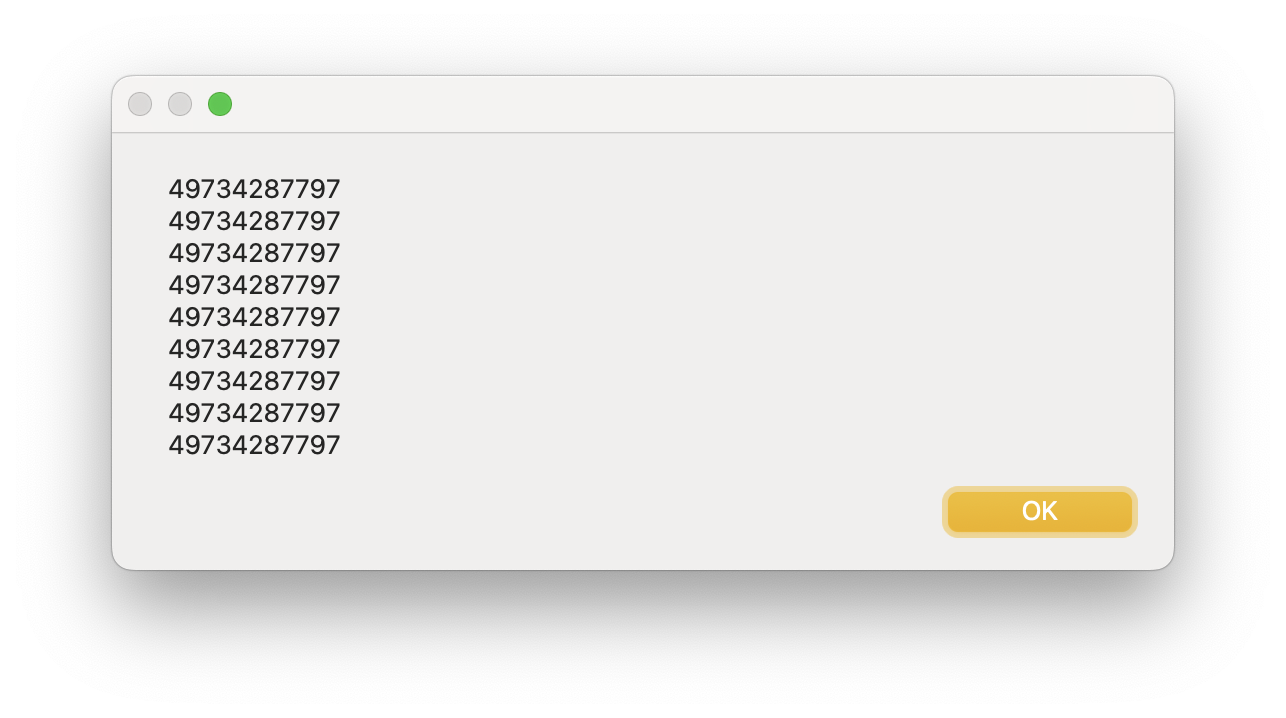
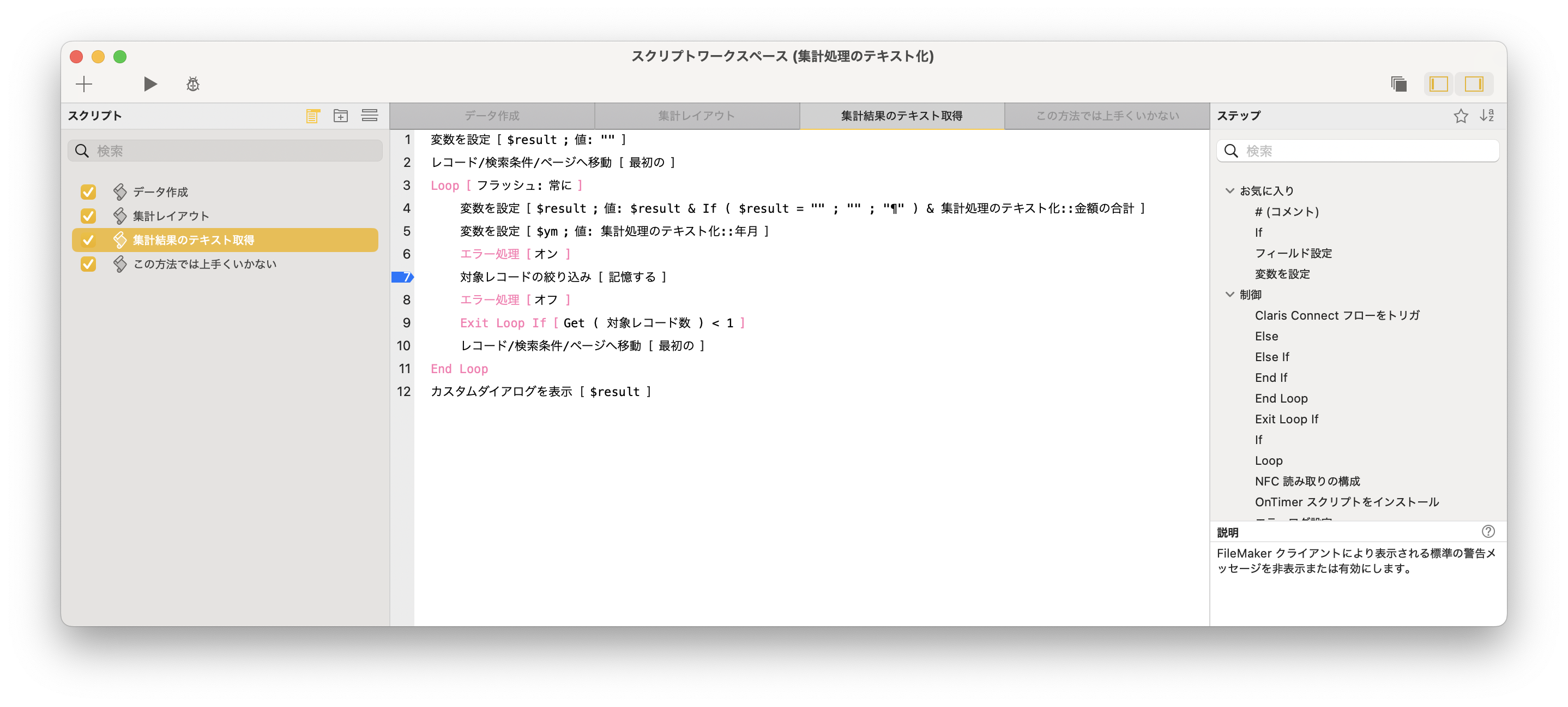
すると、リンクがずらーっと並んだページに行くので、Transfers and Distributionsというタイトルのブロックを探し、その中にあるEmployee Stock Plan Outgoing Share Transferというところの右のリンクをクリックします。実際に申請するには、Submit onlineをクリックすると、PDFが編集可能な状態で開いて、最後に自動的にアップロードされるので、普通はその手順で進めれば良いでしょう。
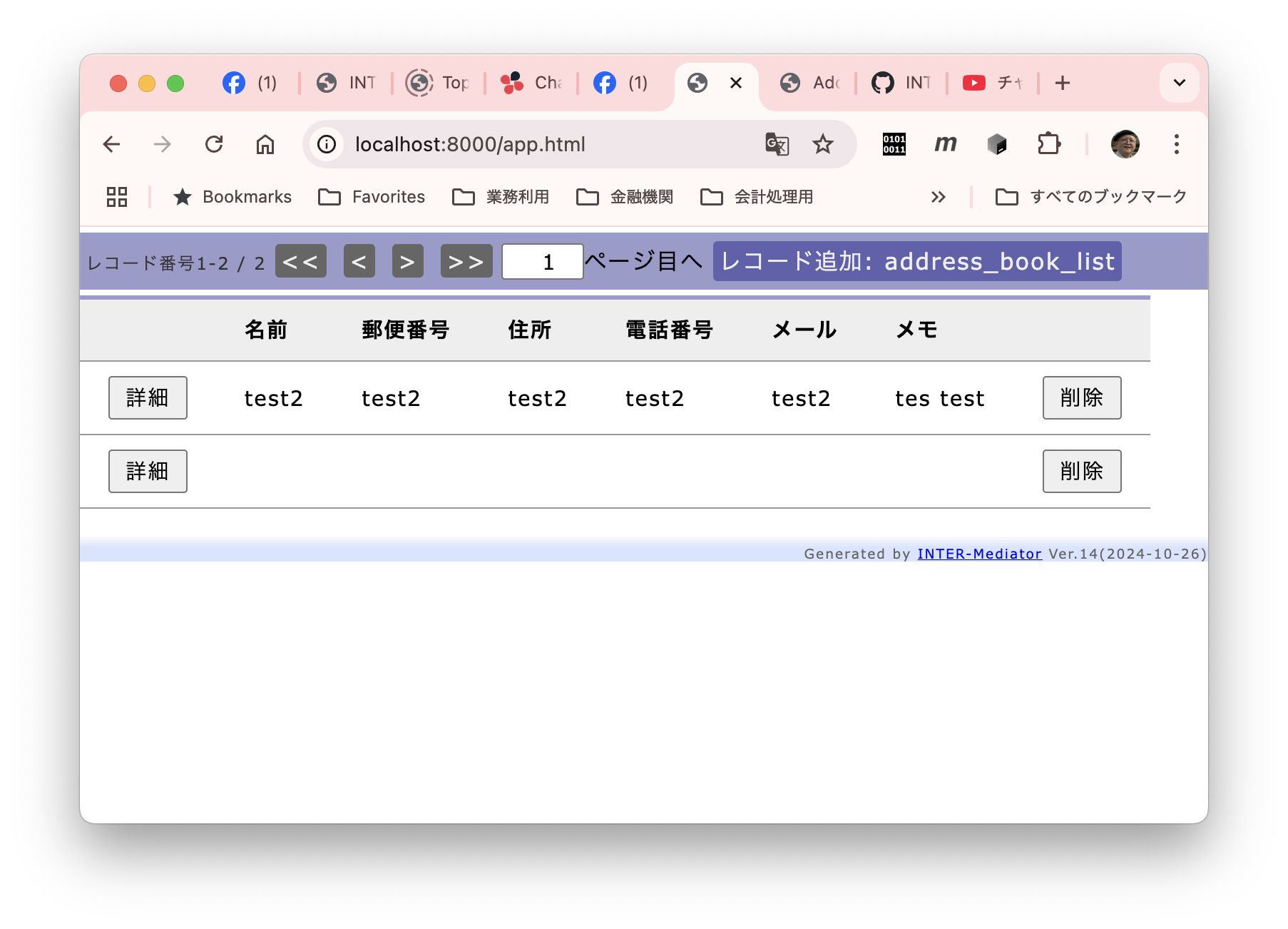
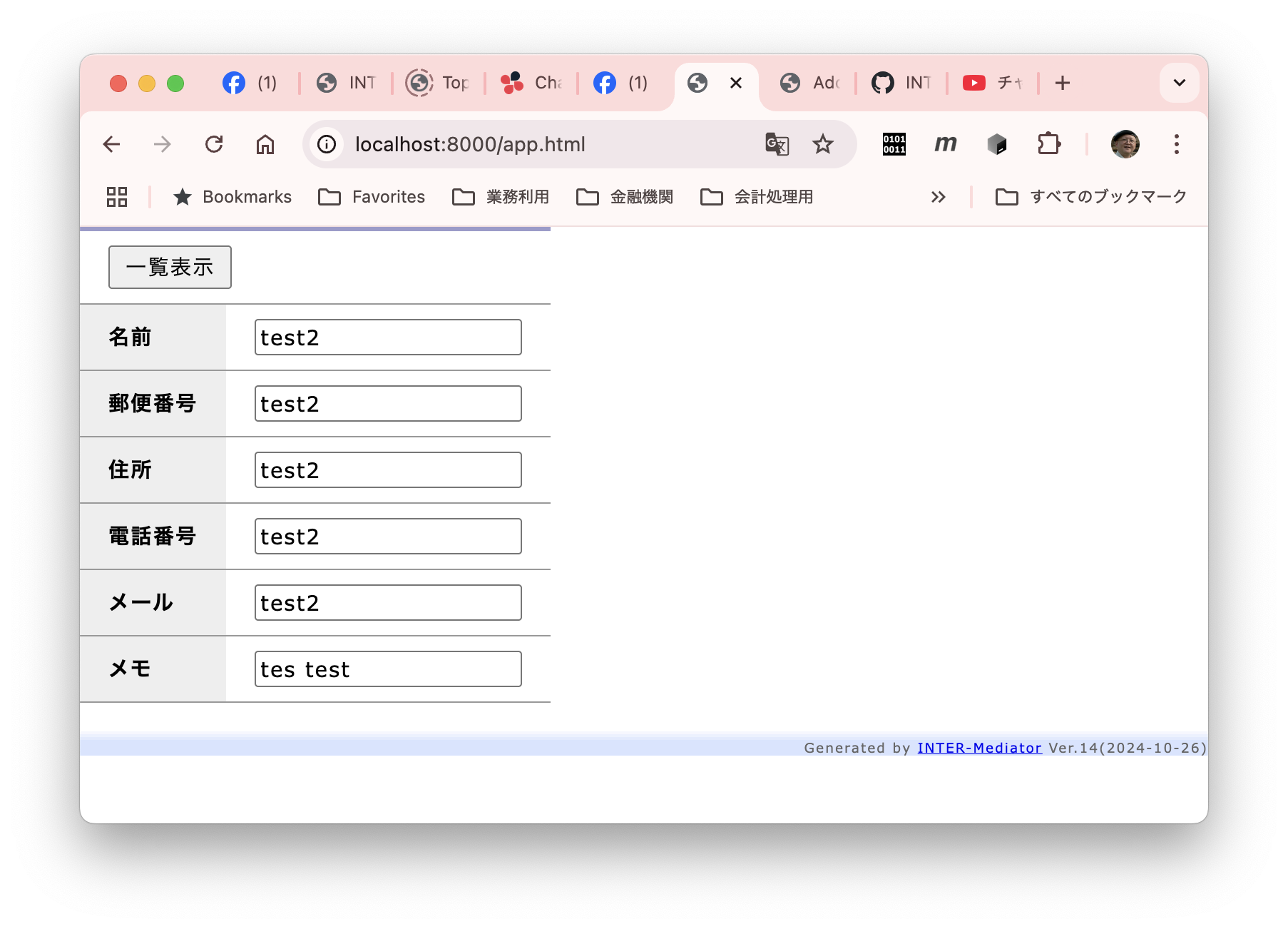
私は、Webアプリケーションのフレームワーク「INTER-Mediator」を開発している。なるべくシンプルにアプリケーション開発が可能なような仕組みをフレークワークとして提供している。例えば、HTMLページで<input data-im=”item@name”>とすれば、このテキストフィールドにitemテーブルのnameフィールドの値が表示され、変更すれば自動的にフィールドがアップデートされるといった仕組みだ。もちろん、もっと色々あるが、それはサイトを見ていただくとしよう。このINTER-Mediatorを試してみるための素材として、本体とは別にレポジトリを提供している。これを以下、「トライアル」と呼ぶ。トライアルを稼働させれば、INTER-Mediatorのコードの一部で提供しているサンプルのページを稼働させてみることができる。さらにはチュートリアルの演習を進める基盤としても稼働できるようになっている。このトライアル自体を容易にセットアップできるようにするために、Dockerの素材をレポジトリに提供している。このレポジトリをダウンロードして、レポジトリのルートで「docker compose up -d」などとすれば、ちょっと待てばサンプルアプリやチュートリアルを進めるための仕組みが稼働して、「http://localhost:9080」にブラウザから接続すれば良いという仕掛けである。
ということで、漢字をとっさに書けない私たちでも、日々、文章を書いているということは、そのほかの色々なメリットを含めて悪いことではなかったということです。おそらく、AIによるプログラミングも同じことで、AIをうまく使うというノウハウの蓄積により、過去よりも効率的に開発ができるようになるという路線がすでに先の方まで見えているのが現状でしょう。もちろん、未来にも、いきなり for ( int i = 0 … などと書きじめることはなくはないでしょうけど、むしろ「繰り返して配列の要素の最大値を返して」とお願いして勝手にコードが書かれていたり、あるいはもっと大きな要求を入力して、長ーいプログラムの一部にforが書かれていたりというようなことに、もうすでになっているわけです。つまり、プログラマとしては、スクラッチから書けなくもないものの、fをキータイプすることからスタートするだけがプログラミングではないということになっているわけです。まあ、forの書き方くらいは忘れないかもしれませんが、フレームワークのAPIの引数指定などを正確に書いていかなければならなかった過去に比べて、そういう部分も大まかな指示をもとに正確にAIがコード生成します。それは、あたかも、漢字をちゃんと書けるか怪しい私たちでも文章が作れていくのと良く似ています。
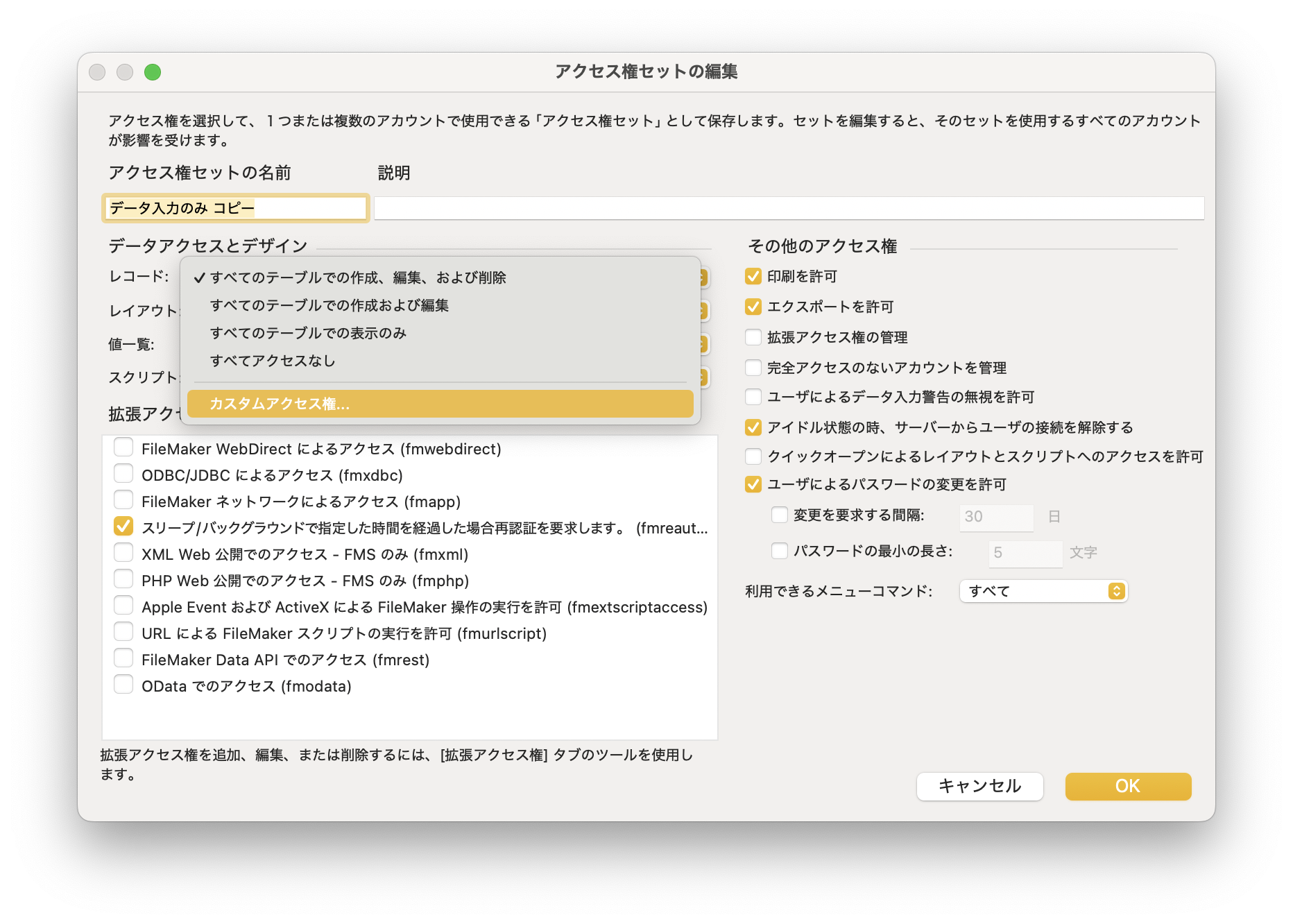
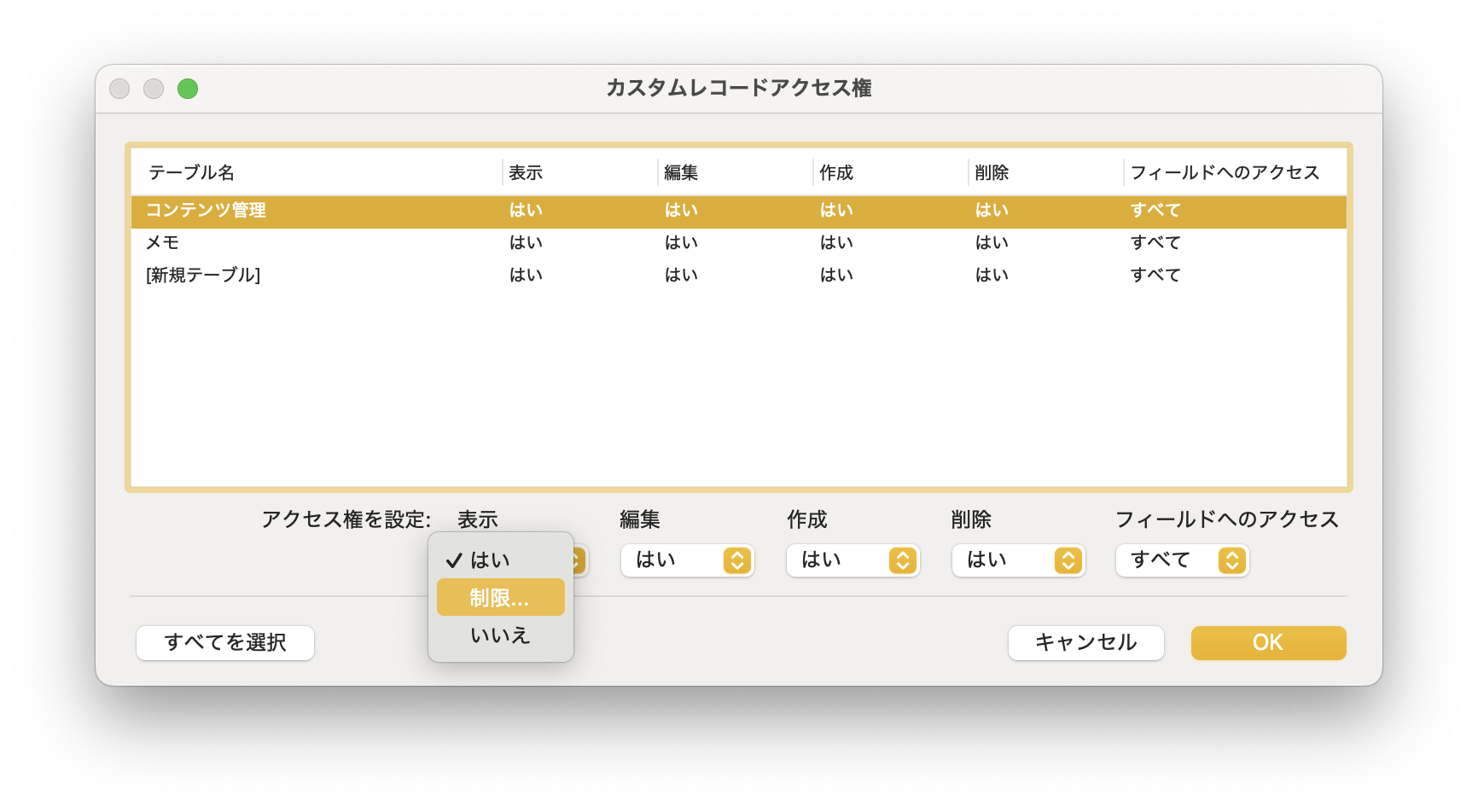
そして、カスタムレコードアクセス権の制限の式に「username = GET ( アカウント名 ) 」という式を設定しておけばOKです。この辺り、私たちの書籍「FileMaker as a Relational Database」の「8.3 レコード単位のアクセス権」に記述があります。設定手順がちょっと込み入っとるやないか!と今見たら思ってしまいますが、基本はここで説明したものと同様、アクセス権設定に対するレコード単位のアクセス権指定を行っています。
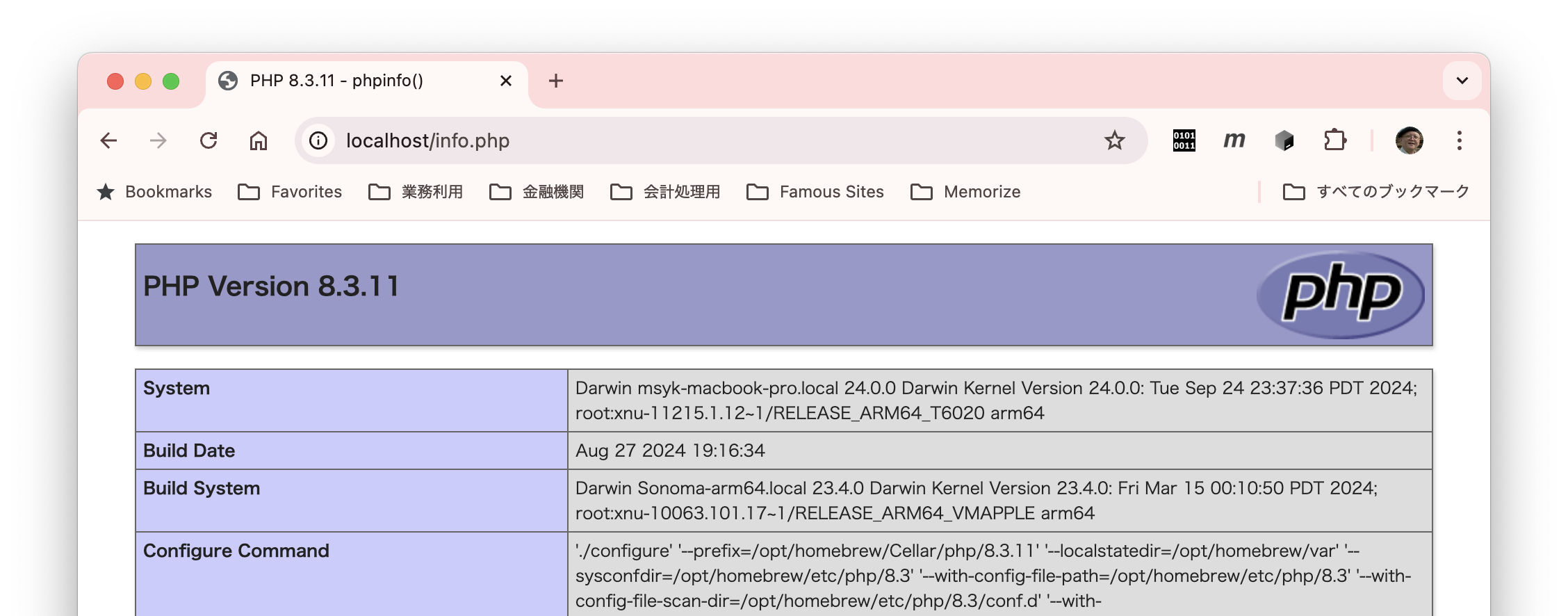
FileMaker ServerにはPHPが付属しなくなって久しいのですが、現状、特にFileMaker Serverで動かなくても不便はなく、PHPの処理が欲しい場合は別途サーバを立てるのが最善策なのはいうまでもありません。しかしながら、「どうしても動かしたい」という声が後を絶たず、ここでとりあえず動かす方法をまとめておきます。そもそも、Clarisからの文書として「FileMaker ServerインストーラへのPHP添付の廃止について」があるのですが、内容が非常に込み入っていて、しかも何をしているのかわかりにくいこともあって、PHPを動かすことに躊躇している人も多いかもしれません。この文書は、FileMaker API for PHPという懐かしいライブラリを利用するための方法まで書いてありますが、今時のPHPのバージョンでこのライブラリが無事に動くとは考えづらく、その方法までは不要なのが一般的ではないかと思われます。
以下の方法が成功したのは、macOS Sequoia上のFileMaker Server 2024の場合です。これは対応OSではないのに成功したということです。また、Sequioa上ではFileMaker Server 2023でも成功しました。これも対応OSではありません(2024版はSequioa対応かどうかは公表されていないですね)。一方、macOS Ventura上のFileMaker Server 2023ではエラーになってうまくいきませんでした。これは対応OSであるのに上手くいかなかった組み合わせです。macOS内蔵のApache2に、外部からインストールするphpのモジュールという組み合わせの相性があるようなので、上手くいかない場合もあるという覚悟で進めましょう。
[Tue Oct 08 12:44:50.253541 2024] [so:notice] [pid 17129] AH06662: Allowing module loading process to continue for module at /opt/homebrew/opt/php/lib/httpd/modules/libphp.so because module signature matches authority "Developer ID Application: Nii Masayuki (W3WVRUYJRT)" specified in LoadModule directive
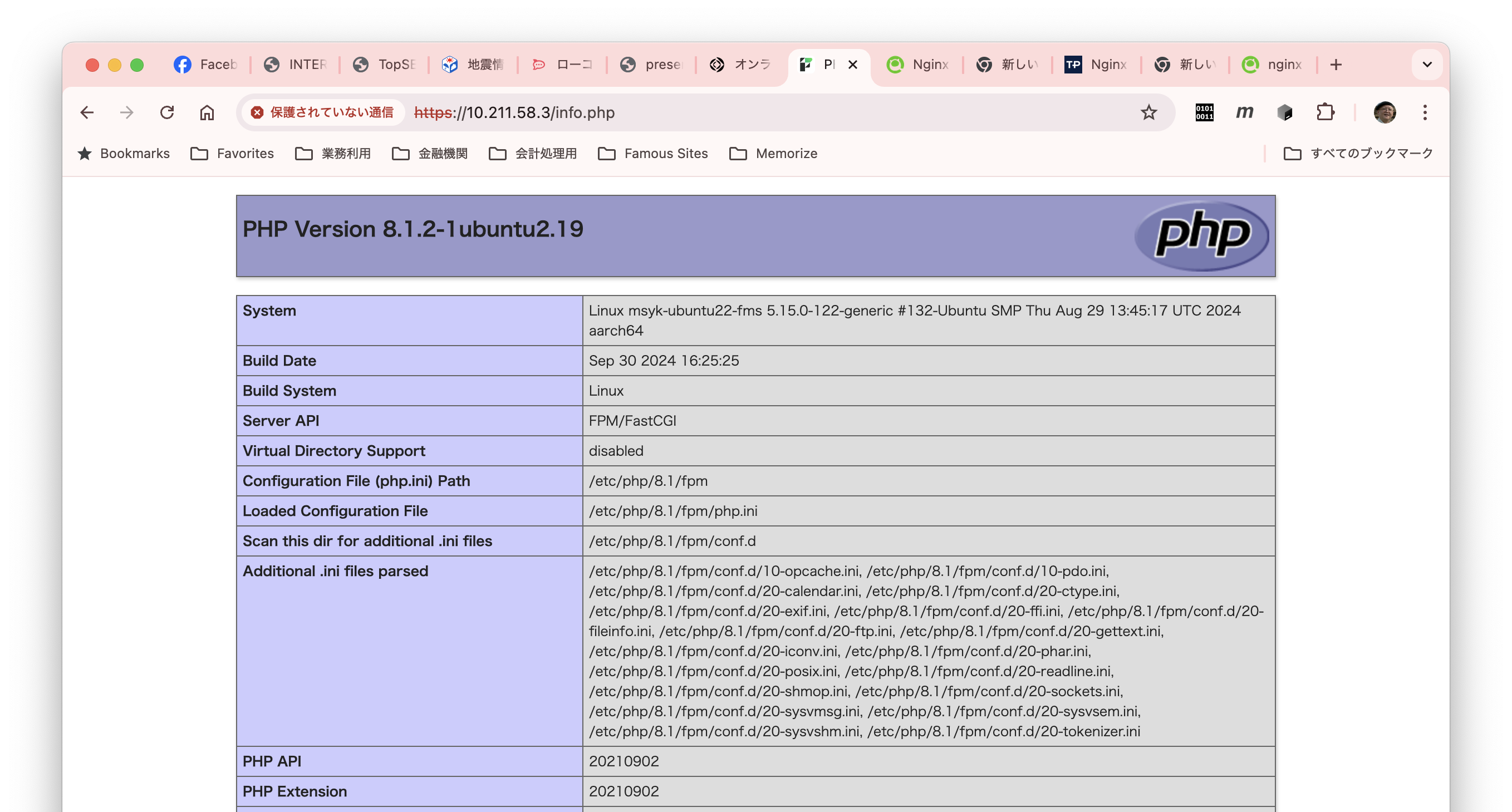
もう、だいぶん前ですが、FileMaker ServerのLinux版は、Webサーバとしてnginxを採用しました。また、もう少し前からになるでしょうか、FileMaker Server自体にPHPがバンドルされていない状態になりました。ということで、nginxでPHPダァ〜!ってなるのかと思ったら、全然情報が見つかりません。まあ、先に結論を言えば、PHPを動かすんだったら、別のサーバー立てるのが何かと安心というのがあるかと思います。しかしですね、「なんとか動かないか」と依頼されることが多々あり、手順をまとめてみました。Ubuntu Server 22.04LTSです。sudo権限を持ったmsykというアカウントでログインして作業をしました。
Apache2は、PHPのモジュール、つまりApache2のプロセスに入り込んで動くバイナリを使っていました。一方で、nginxは、別プロセスで動くPHPに対して、ソケットや通信を使って動きます。ということで、単独のプロセスで動くPHPといえば、PHP-FPM(FastCGI Process Manager)ですね。こちらをセットアップして動くようにする必要があります。モジュール名さえ分かっていればOKですね。以下の1行目で、phpとphp-fpmをインストールしていますが、composerも必要でしょうから一緒に入れておきます。2行目は、systemctlで指定するサービス名は「php8.1-fpm」になります。2行目はphp-fpmを再起動後も起動するように設定しておきます。なお、手元ではApache2も動いてしまっていたので、止めて再起動後にも起動しないようにしておきました。
location ^~ /fmi/ {
proxy_set_header X-Forwarded-Proto https; # MWPE need ...
:
proxy_cookie_path /fmi "/; Secure; HttpOnly; Max-Age=43200";
}
location ~ \.php$ {
fastcgi_pass unix:/var/run/php/php-fpm.sock;
fastcgi_index index.php;
include /etc/nginx/fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
# location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
:
cd /opt/FileMaker/FileMaker\ Server/NginxServer/htdocs/httpsRoot
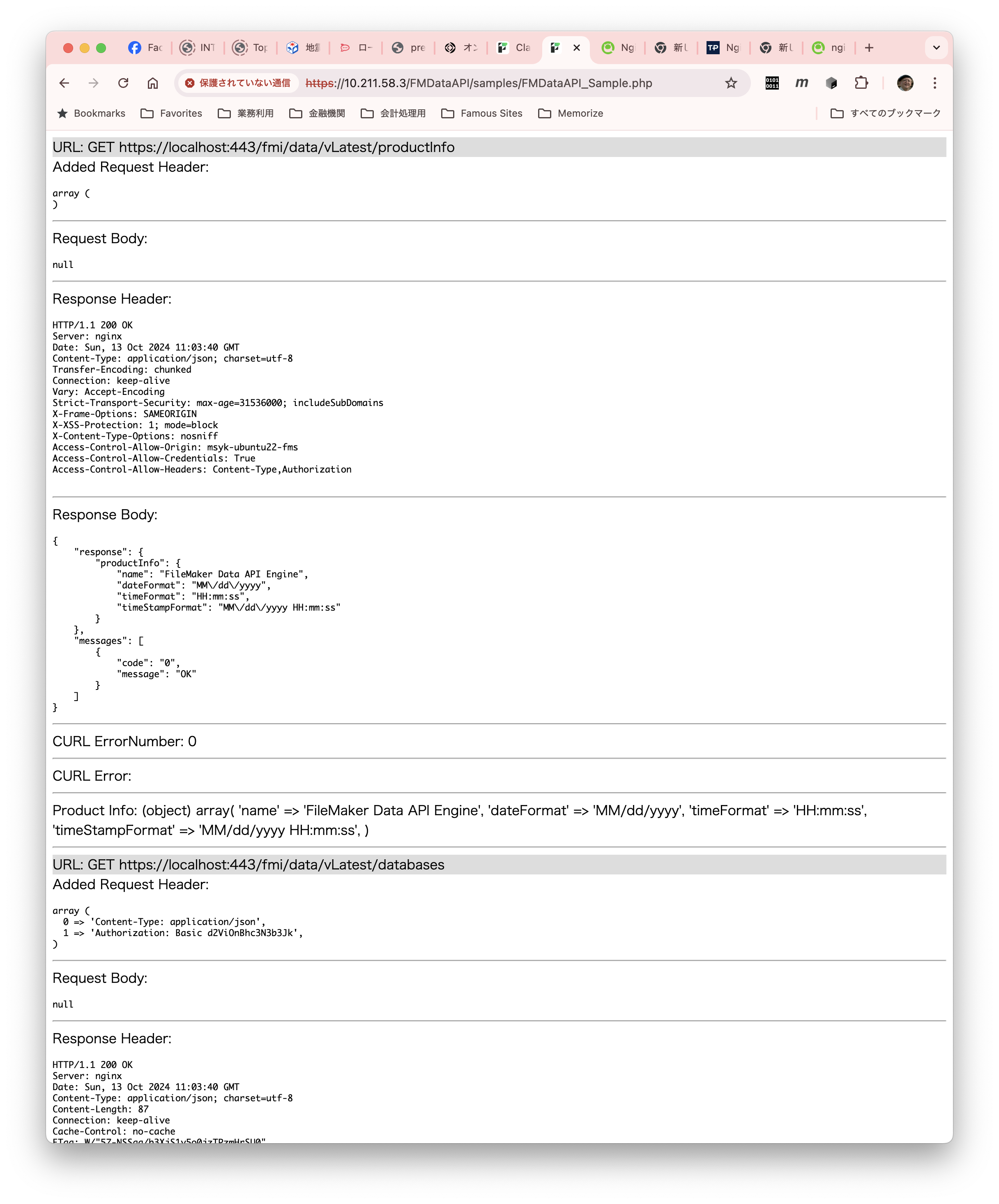
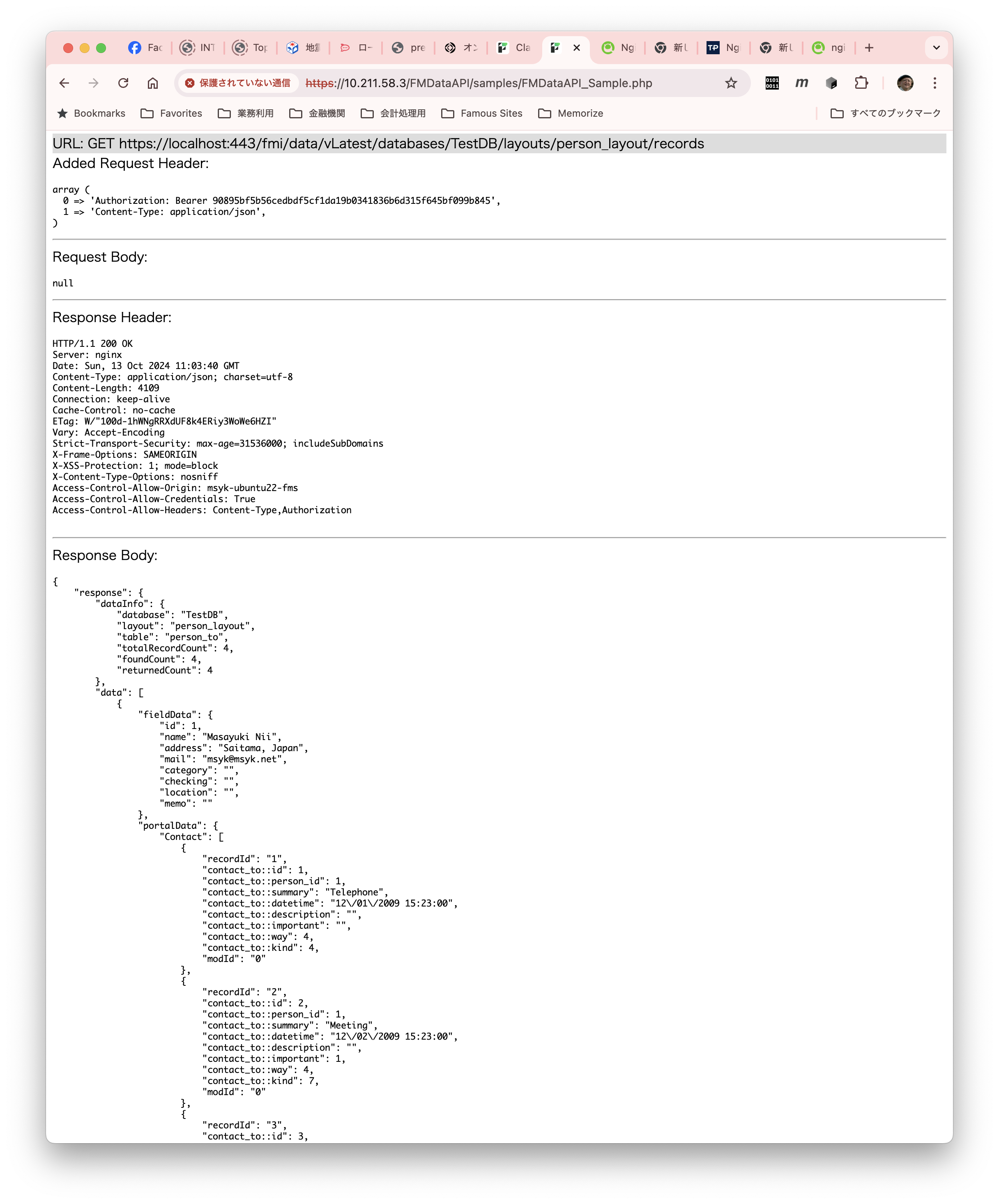
git clone https://github.com/msyk/FMDataAPI
cd FMDataAPI
composer update
これで必要なライブラリがセットアップされる…と思ったら、Problemとして2つ項目が出ます。
Composer is operating significantly slower than normal because you do not have the PHP curl extension enabled.
Loading composer repositories with package information
Updating dependencies
Your requirements could not be resolved to an installable set of packages.
Problem 1
- Root composer.json requires PHP extension ext-curl * but it is missing from your system. Install or enable PHP\'s curl extension.
Problem 2
- phpunit/phpunit[3.7.0, ..., 3.7.38, 4.0.0, ..., 4.8.36, 5.0.0, ..., 5.2.7, 8.5.12, ..., 8.5.40, 9.3.0, ..., 9.6.21, 10.0.0, ..., 10.5.36] require ext-dom * -> it is missing from your system. Install or enable PHP\'s dom extension.
- phpunit/phpunit 4.8.20 requires php ~5.3.3|~5.4|~5.5|~5.6 -> your php version (8.1.2) does not satisfy that requirement.
- phpunit/phpunit[5.2.8, ..., 5.7.27] require php ^5.6 || ^7.0 -> your php version (8.1.2) does not satisfy that requirement.