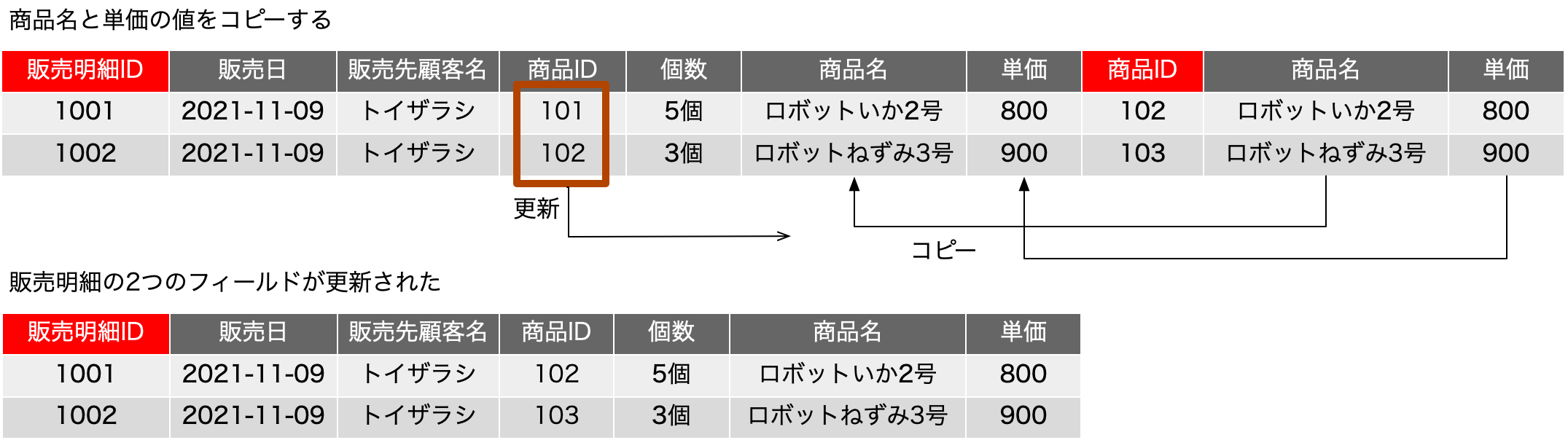
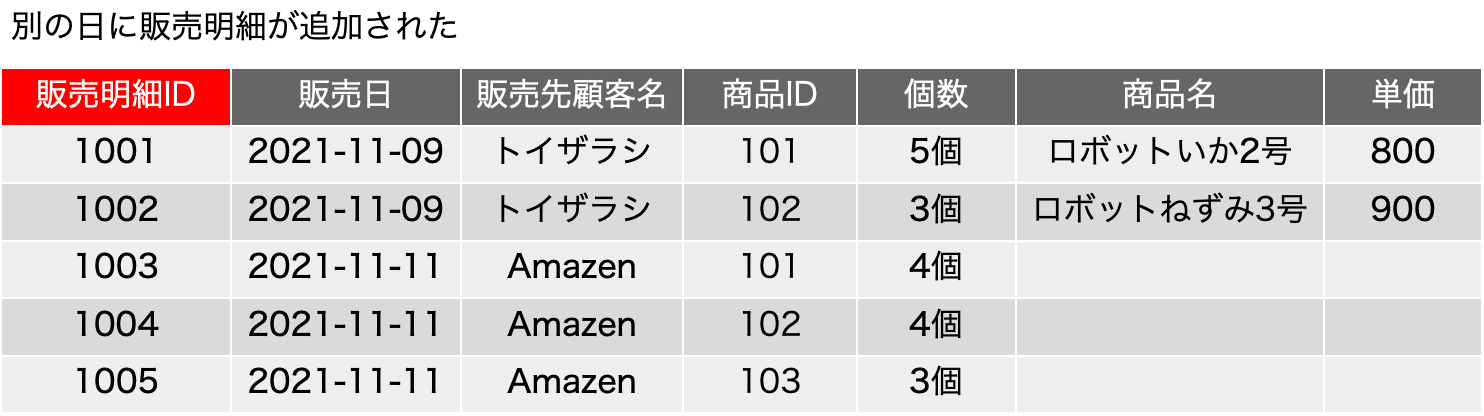
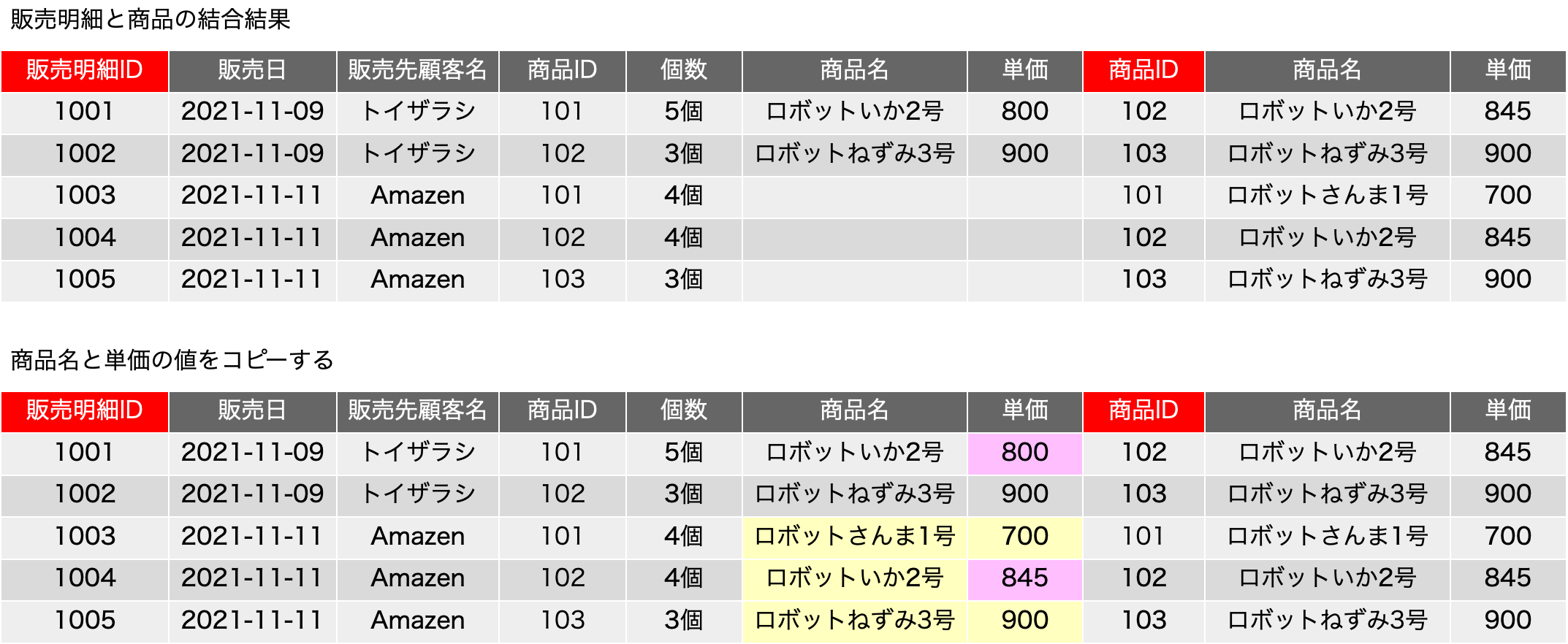
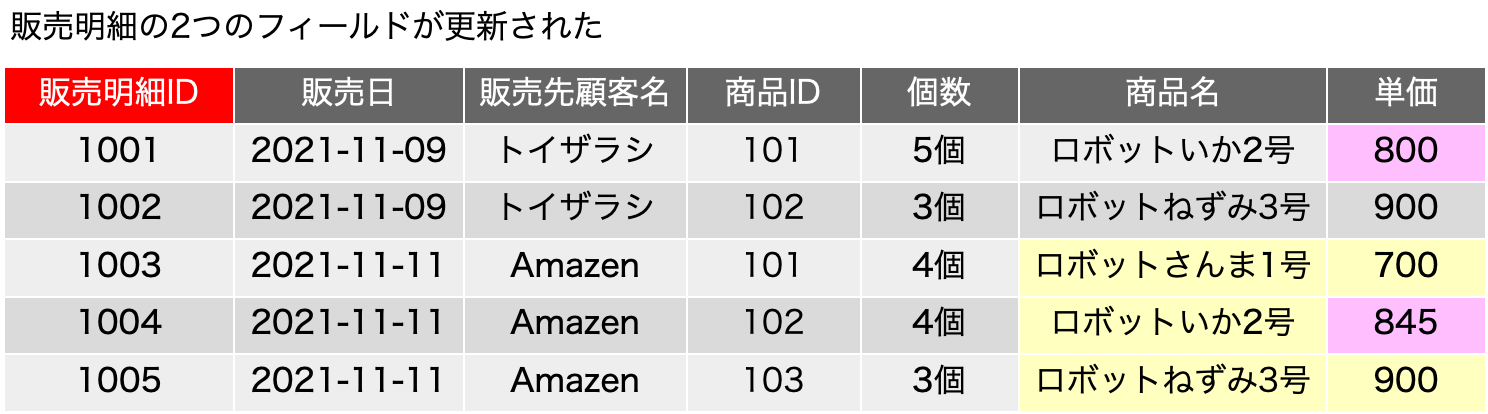
もう、だいぶん前ですが、FileMaker ServerのLinux版は、Webサーバとしてnginxを採用しました。また、もう少し前からになるでしょうか、FileMaker Server自体にPHPがバンドルされていない状態になりました。ということで、nginxでPHPダァ〜!ってなるのかと思ったら、全然情報が見つかりません。まあ、先に結論を言えば、PHPを動かすんだったら、別のサーバー立てるのが何かと安心というのがあるかと思います。しかしですね、「なんとか動かないか」と依頼されることが多々あり、手順をまとめてみました。Ubuntu Server 22.04LTSです。sudo権限を持ったmsykというアカウントでログインして作業をしました。
まず、お決まりのUbuntuのアップデート、そしてFileMaker Serverのアップデートです。Linux版は単にinstallすればアップデートもできて結構便利ですね。FileMaker Serverのインストール方法は、Clarisのドキュメントあるいはサイトをご覧ください。この記事は、FileMaker Serverをインストールした後のお話です。
sudo apt update -y
sudo apt upgrade -y
sudo apt install ./filemaker-server-21.0.2.202-arm64.debApache2は、PHPのモジュール、つまりApache2のプロセスに入り込んで動くバイナリを使っていました。一方で、nginxは、別プロセスで動くPHPに対して、ソケットや通信を使って動きます。ということで、単独のプロセスで動くPHPといえば、PHP-FPM(FastCGI Process Manager)ですね。こちらをセットアップして動くようにする必要があります。モジュール名さえ分かっていればOKですね。以下の1行目で、phpとphp-fpmをインストールしていますが、composerも必要でしょうから一緒に入れておきます。2行目は、systemctlで指定するサービス名は「php8.1-fpm」になります。2行目はphp-fpmを再起動後も起動するように設定しておきます。なお、手元ではApache2も動いてしまっていたので、止めて再起動後にも起動しないようにしておきました。
sudo apt -y install php php-fpm composer
sudo systemctl enable php8.1-fpm
sudo systemctl stop apache2
sudo systemctl disable apache2続いて、nginxの設定ファイルを変更します。FileMaker Serverは、/opt/FileMaker/FileMaker Server以下にファイルを置きます。スペース入るの嫌ですが、仕方ないですね。その中のNginxServerのさらに下にconfがあり、4つの設定ファイルがあります。fms_nginx.confファイルを修正します。例えば、こんな感じでnanoで編集します。
cd /opt/FileMaker/FileMaker\ Server/NginxServer/conf
sudo nano fms_nginx.conf修正箇所を以下に示しますが、ファイルのほとんど末尾です。ファイル全体は、大きく分けて、ポート80に対する設定と、443に対する設定があり、後者の { } 内に以下のコードの赤字部分を追加します。最後にコメントになっている箇所があるので、その直前でいいかと思います。このままコピペして大丈夫だと思いますが、一応、設定のポイントを次に説明します。
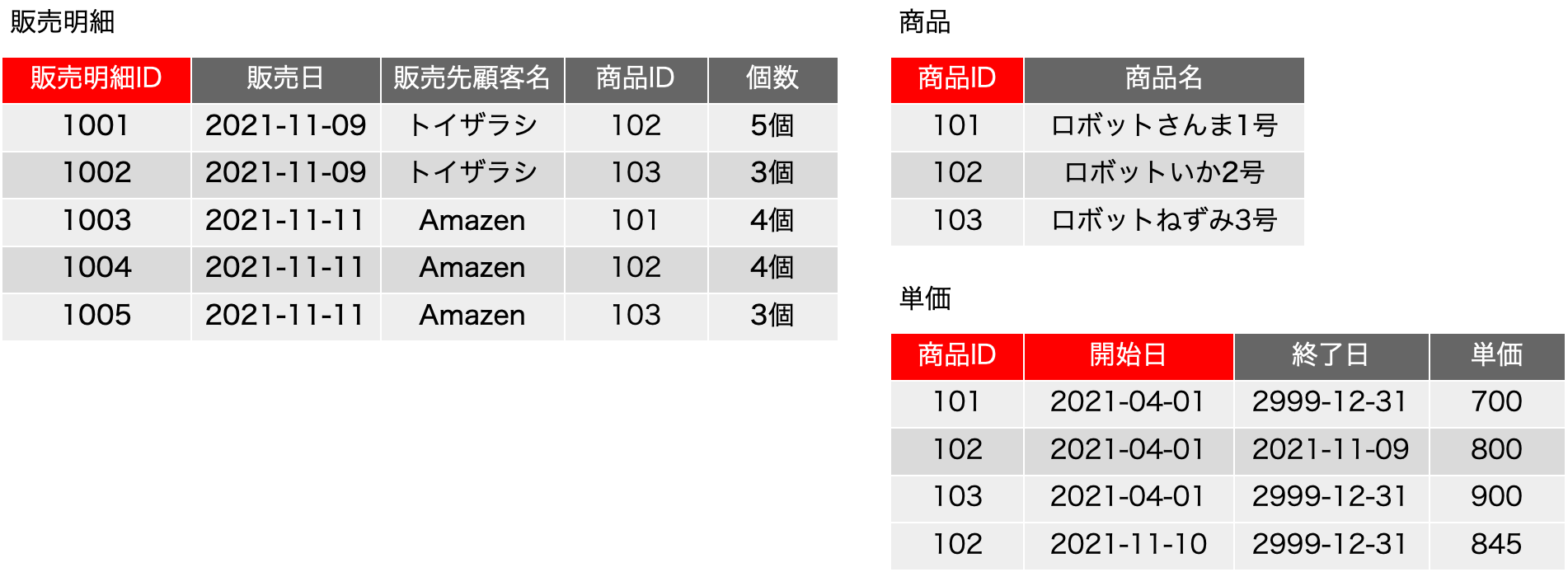
location ^~ /fmi/ {
proxy_set_header X-Forwarded-Proto https; # MWPE need ...
:
proxy_cookie_path /fmi "/; Secure; HttpOnly; Max-Age=43200";
}
location ~ \.php$ {
fastcgi_pass unix:/var/run/php/php-fpm.sock;
fastcgi_index index.php;
include /etc/nginx/fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
# location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
:まず、locationは正規表現を伴っていますが、これは、拡張子が.phpのファイルに対するリクエストが来たらこの後の定義に従うということです。fastcgi_passは、ソケットあるいはURLを指定しますが、ここではソケットを指定しています。php-fpmはソケットあるいはTCP/IPのポートが開きますが、ソケットについてはこの後のphp-fpmの設定ファイルwww.confの中に記載されているので、それと合わせる必要があります。
fastcgi_indexは、ディレクトリへのリクエストの場合、index.phpファイルを探して、そのファイルへのリクエストとして処理するという意味です。
includeの後に、ファイルのパスを指定しますが、ここで指定したファイルはFileMaker以下ではなく、/etc/nginx以下、つまり一般的なnginx側のファイルです。よほど、複製して使う方がいいかと思いましたが、書き換えないので、標準nginxのファイルをそのまま使います。このファイルや、次のfastcgi_paramでは、CGI呼び出しのパラメータを指定します。PHP的にいえば、$_SERVER変数で得られる値を定義します。もちろん、キーと値を指定します。fastcgi_paramsファイルには一般的なCGIのパラメータがほぼ記載されているのですが、$_SERVER[‘SCRIPT_FILENAME’]の値については、モジュールで動かすPHPと若干違っているので、その設定がファイルに加わっています。変数$fastcgi_script_nameは、例えば、「/info.php」のような、リクエストで指定したパスです。変数$document_rootは、nginxのドキュメントルートで、root “…”で指定すると勝手に変数が定義されます。これらの変数をつなげることで、つまりは、稼働しているスクリプトへの絶対パスがパラメータとして伝達されるということです。
続いて、php-fpmの設定を行います。モジュール版の場合、Ubuntsuではwww-dataという名前およびグループのプロセスとしてApache2が稼働しているので、それらのユーザが前提となります。一方、FileMaker Serverは、nginxも、fmsuser/fmsadminというユーザ・グループで稼働します。それに合わせるため、設定を変更します。例えば、次のようなコマンドで編集作業を行います。
cd /etc/php/8.1/fpm/pool.d/
sudo nano www.conf修正箇所は2箇所4行ですが、他の部分を入れ混ぜるとちょっと冗長なので、修正部分だけを以下に抜き出します。つまり、user, group, listen-*をそれぞれFileMaker Server向けに書き換えます。
:
user = fmserver
group = fmsadmin
:
listen.owner = fmserver
listen.group = fmsadmin
:設定はこれだけです。ということで、プロセスを再起動して…と言いたいのですが、FileMaker ServerはApache2だけの頃からも再起動が怪しかったですが、nginxでもやっぱりダメです。こちらのブログ「FileMakerServer での nginx チューニングをするための前準備」で細かく検討されていますが、ここではサーバを再起動させることにします。
再起動後、ドキュメントのルート、/opt/FileMaker/FileMaker\ Server/NginxServer/htdocs/httpsRootに、ファイル名info.php、中身は「<?php phpinfo();」というお決まりのテストファイルを作成します。はい、無事に出ました。
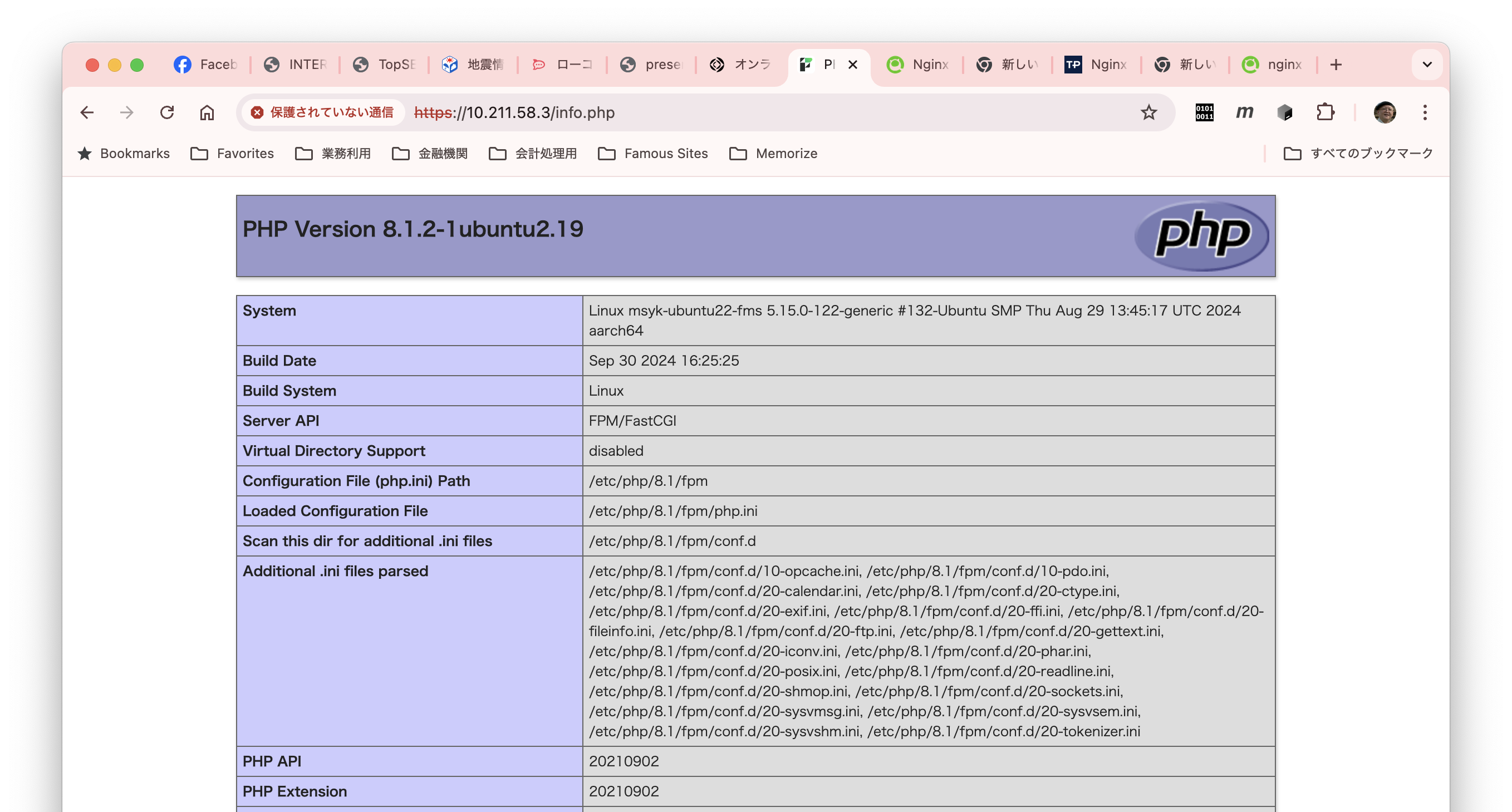
なお、ドキュメントルートは、例えば以下のコマンドで、自分のアカウントに書き込み権限があるようにしておくと良いでしょう。実行については読み出し権限がグループのfmsadminに設定されているので問題ありません。
cd /opt/FileMaker/FileMaker\ Server/NginxServer/
sudo chown -R msyk htdocs
cd htdocs/httpsRoot
echo "<?php phpinfo();" > info.phpちなみに、FileMaker Serverでnginxをセットアップしているので、NginxServer/logsにログがあるのではと思うところで、実際にアクセスログなどはあります。ですが、設定ファイルのエラー等は、/var/log/nginx/error.logに書かれます。設定ファイルの間違い探しでは、こちらのファイルを参照しなければなりません。なお、PHPはそのままにしているので、/var/log/php8.1-fpm.logに書かれます。iniファイルは、/etc/php/8.1/fpm/php.iniですので、必要ならそのファイルを修正しましょう。
さて、FileMakerでPHPとなると、普通はFMDataAPIクラスを使うと思いますが、FMDataAPIも順調にバージョンアップして、Ver.32になっています。なお、Ver.32以降はPHP 8.1が最低条件ですので、PHP 7の方は前のバージョンを使ってください。Ubuntu 22はかろうじてPHP 8.1ですので最新版を使えます。例えば、次のようにコマンドを入れて、サンプルを動かしてみましょう。サンプルのデータベースは、FMDataAPIのページを参考にして、FileMaker Serverにセットアップしておいてください。
cd /opt/FileMaker/FileMaker\ Server/NginxServer/htdocs/httpsRoot
git clone https://github.com/msyk/FMDataAPI
cd FMDataAPI
composer updateこれで必要なライブラリがセットアップされる…と思ったら、Problemとして2つ項目が出ます。
Composer is operating significantly slower than normal because you do not have the PHP curl extension enabled.
Loading composer repositories with package information
Updating dependencies
Your requirements could not be resolved to an installable set of packages.
Problem 1
- Root composer.json requires PHP extension ext-curl * but it is missing from your system. Install or enable PHP\'s curl extension.
Problem 2
- phpunit/phpunit[3.7.0, ..., 3.7.38, 4.0.0, ..., 4.8.36, 5.0.0, ..., 5.2.7, 8.5.12, ..., 8.5.40, 9.3.0, ..., 9.6.21, 10.0.0, ..., 10.5.36] require ext-dom * -> it is missing from your system. Install or enable PHP\'s dom extension.
- phpunit/phpunit 4.8.20 requires php ~5.3.3|~5.4|~5.5|~5.6 -> your php version (8.1.2) does not satisfy that requirement.
- phpunit/phpunit[5.2.8, ..., 5.7.27] require php ^5.6 || ^7.0 -> your php version (8.1.2) does not satisfy that requirement.
色々書いてありますが、要するにcurlとdomの機能が入っていません。これらは、モジュール版と同様に、aptコマンドでインストーすることができます。インストール後、念のためphp-fpmを再起動します。前の続きなら、途中のcdコマンドは不要ですが、カレントディレクトリを明示するために書いておきます。
sudo apt install -y php-curl php-dom
sudo systemctl restart php8.1-fpm
cd /opt/FileMaker/FileMaker\ Server/NginxServer/htdocs/httpsRoot/FMDataAPI
composer updateこれで、ブラウザからサンプルコードの.phpファイル(例えば、https://localhost/FMDataAPI/samples/FMDataAPI_Sample.php)を開くと、個別の通信が示されて、途中にはデータベースからデータを取り出す部分などが参照できます。
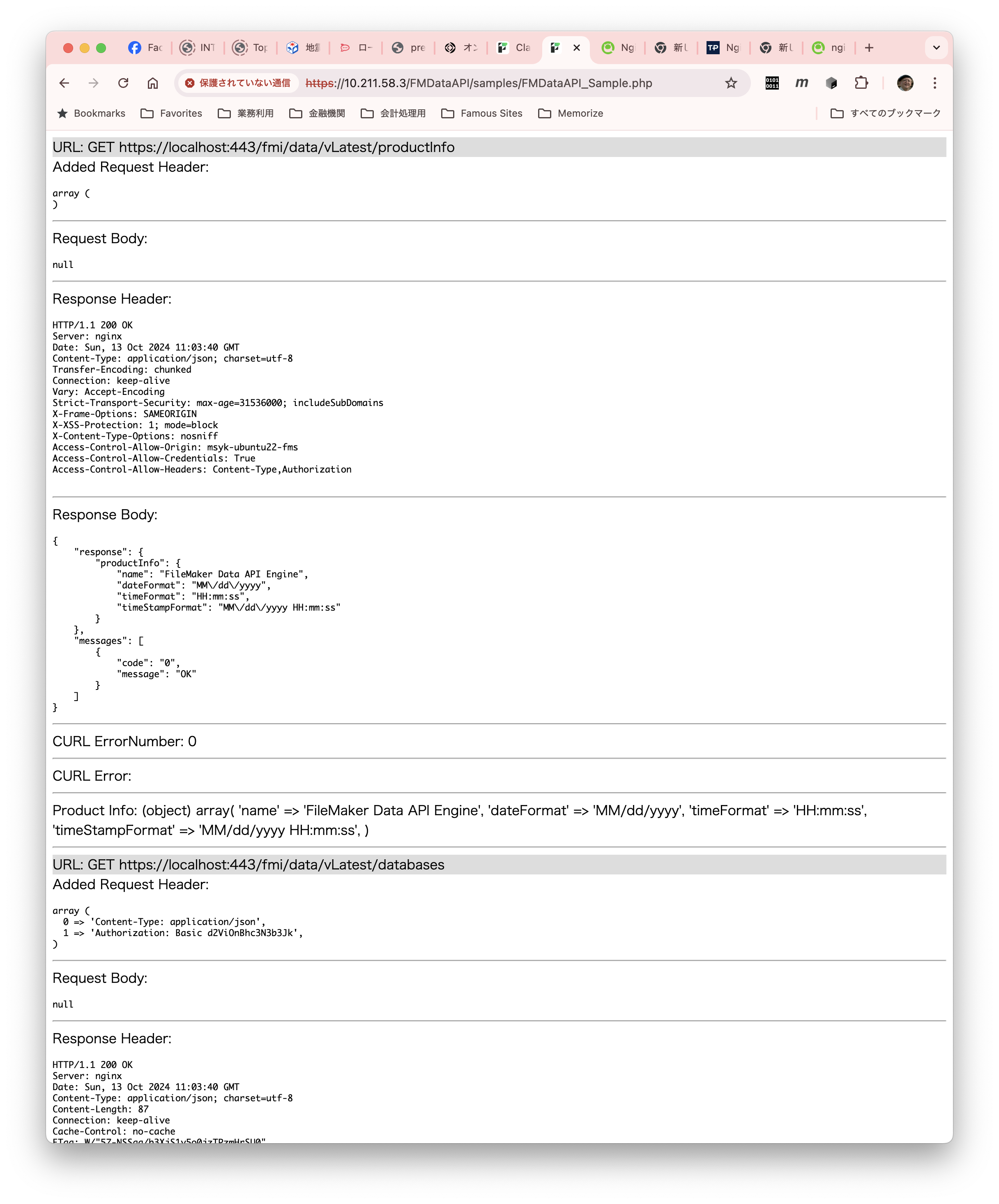
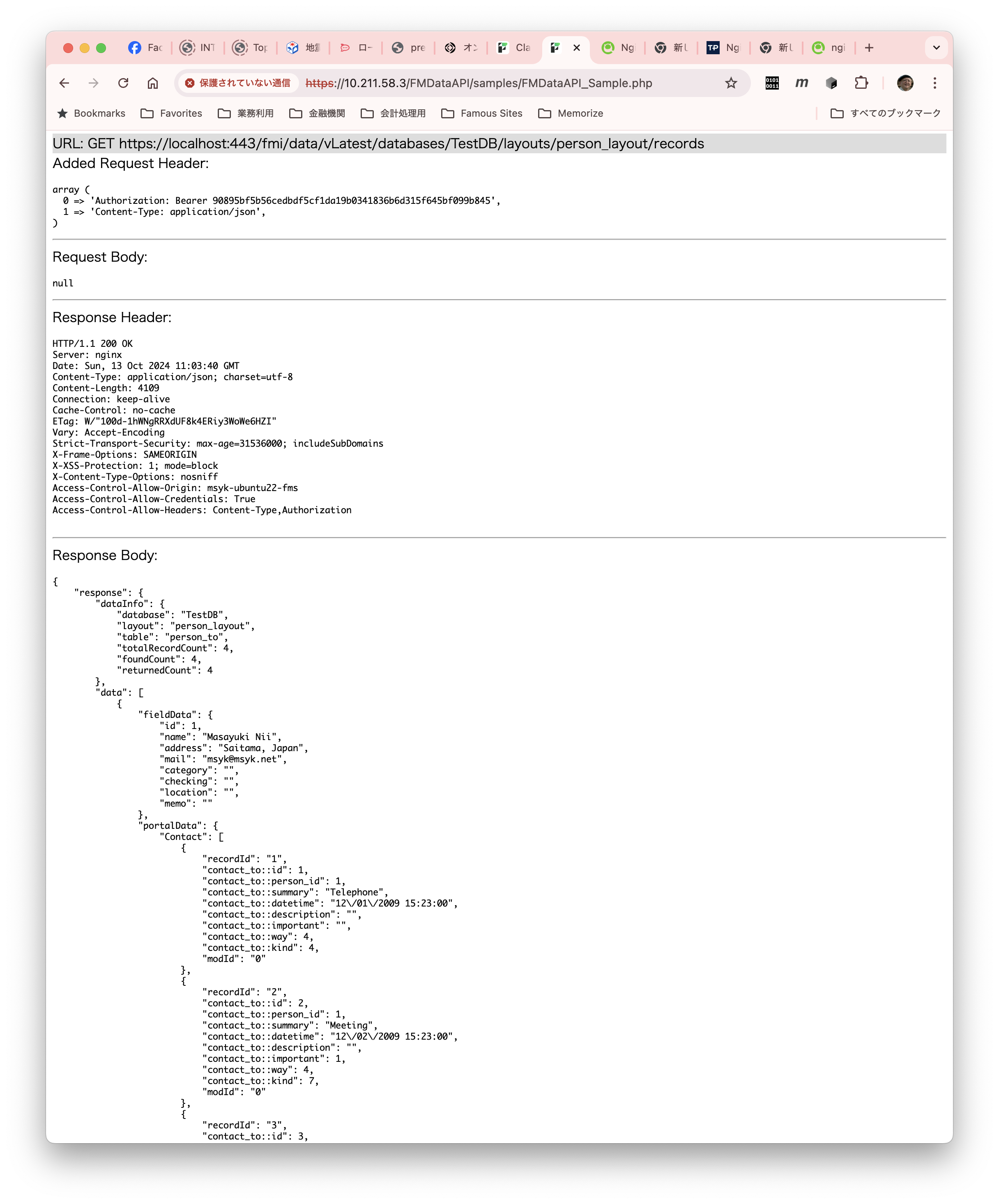
ちなみに、Ubuntsu上での動いているプロセスを見てみます。例えば、以下のようなコマンドで見てください。綺麗にレイアウトされないので、ここには結果は出しません。
ps auxここでは、プロセス名php-fpmで稼働ののち、FileMaker Serverがnginxプロセスを起動して、その後にFileMaker Serverのさまざまなプロセスが稼働しているのがよ句わかります。php-fpmはfmsuserがプロセスのオーナーになっていますし、nginxも同様です。
ということで、FileMaker Server 2024 on Ubuntsu 22において、PHP 8.1が起動しました。ここにはいちいち書きませんが、INTER-Mediatorも動いてサンプルが稼働しています(MySQLでテストしましたが〜笑)。