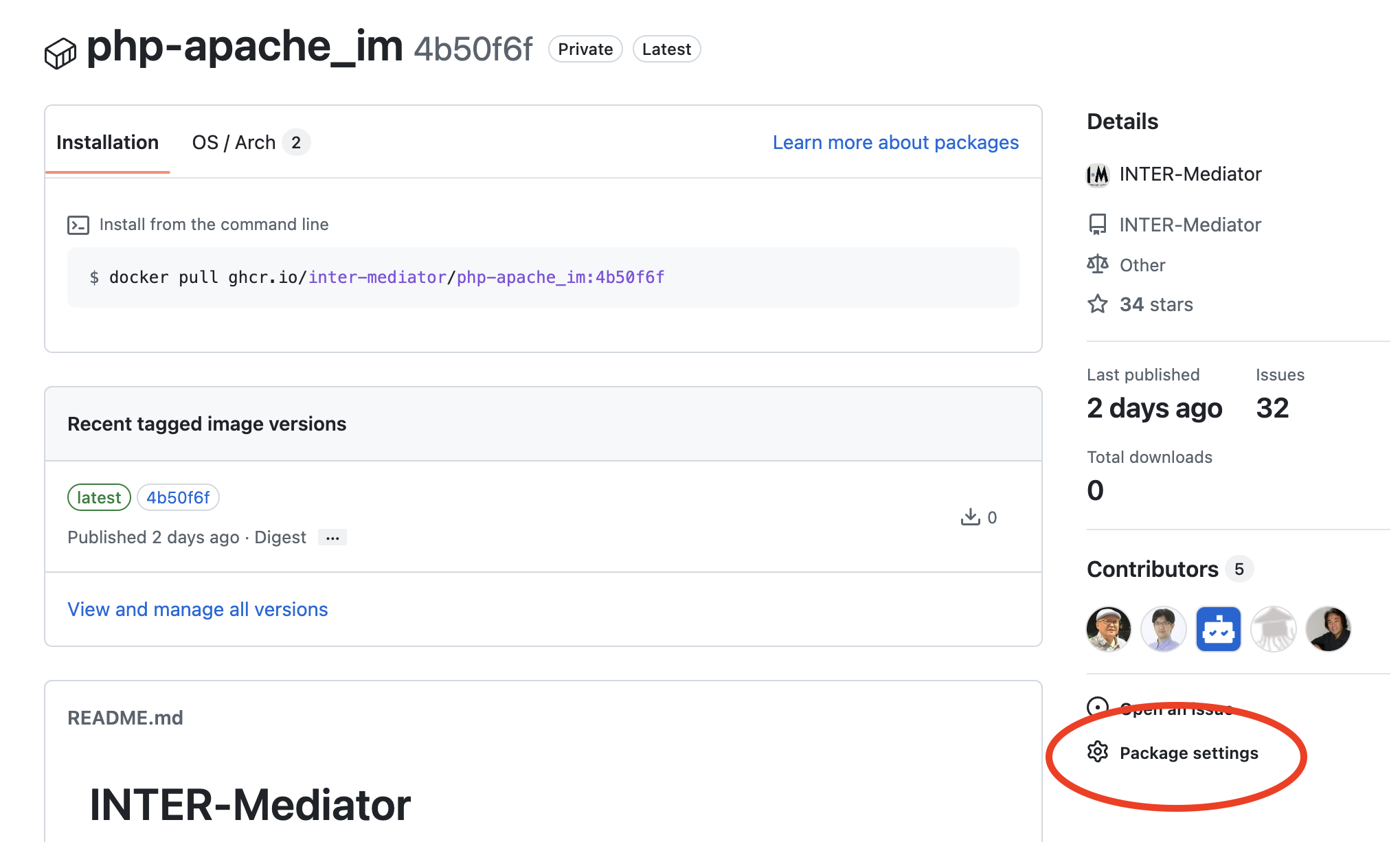
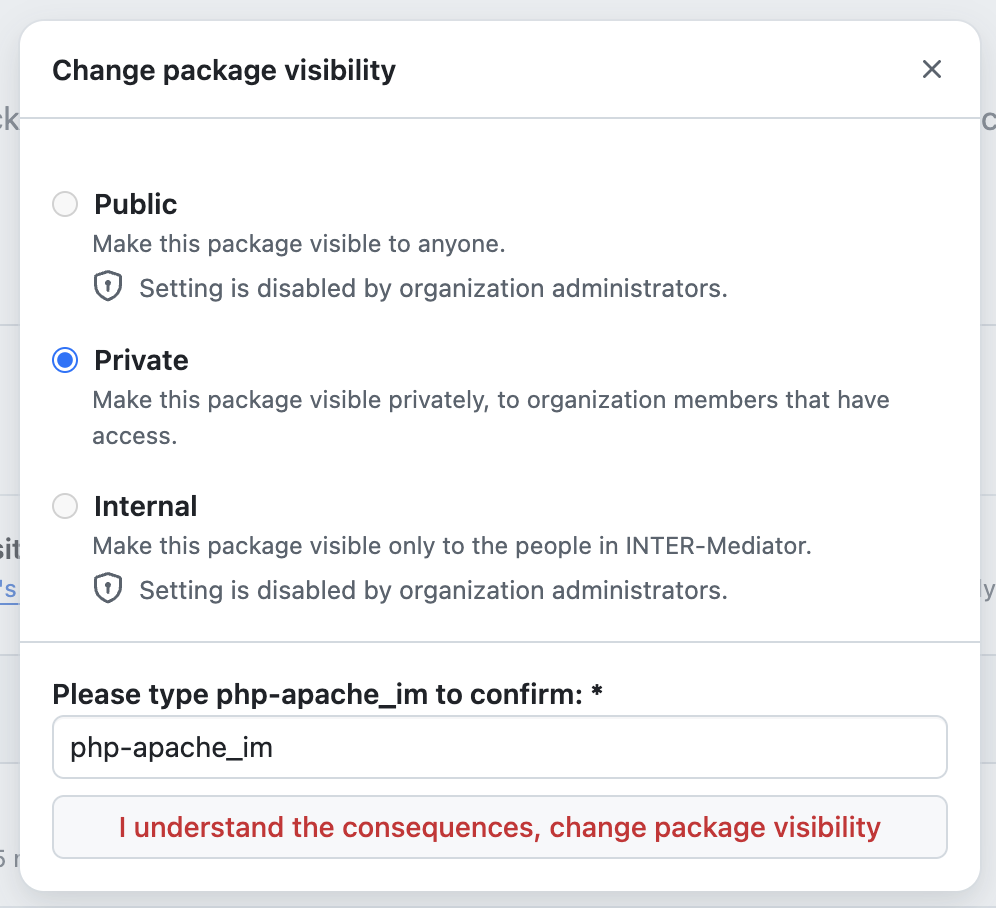
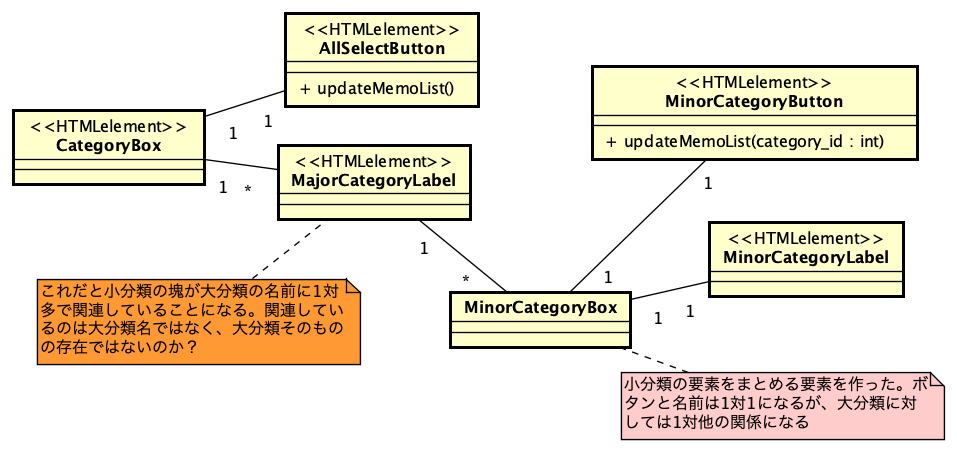
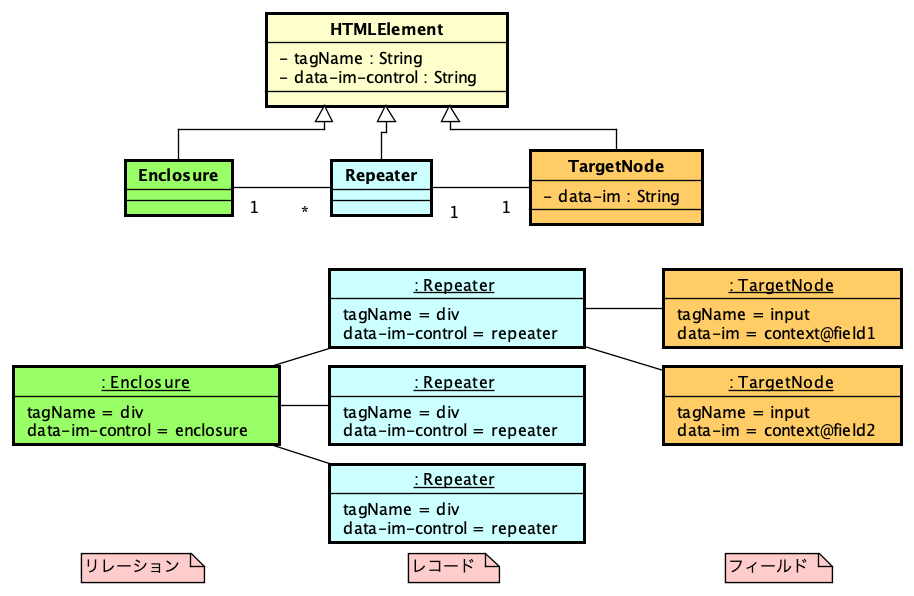
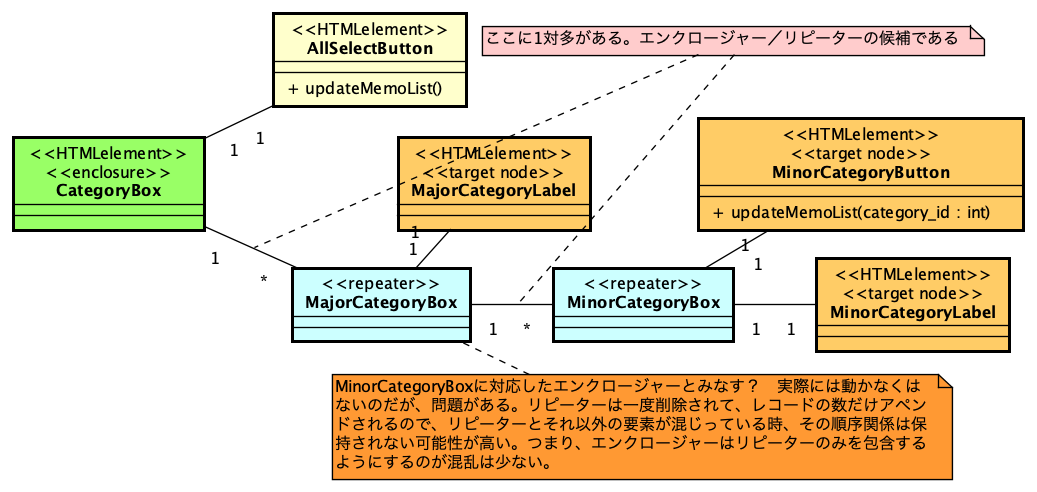
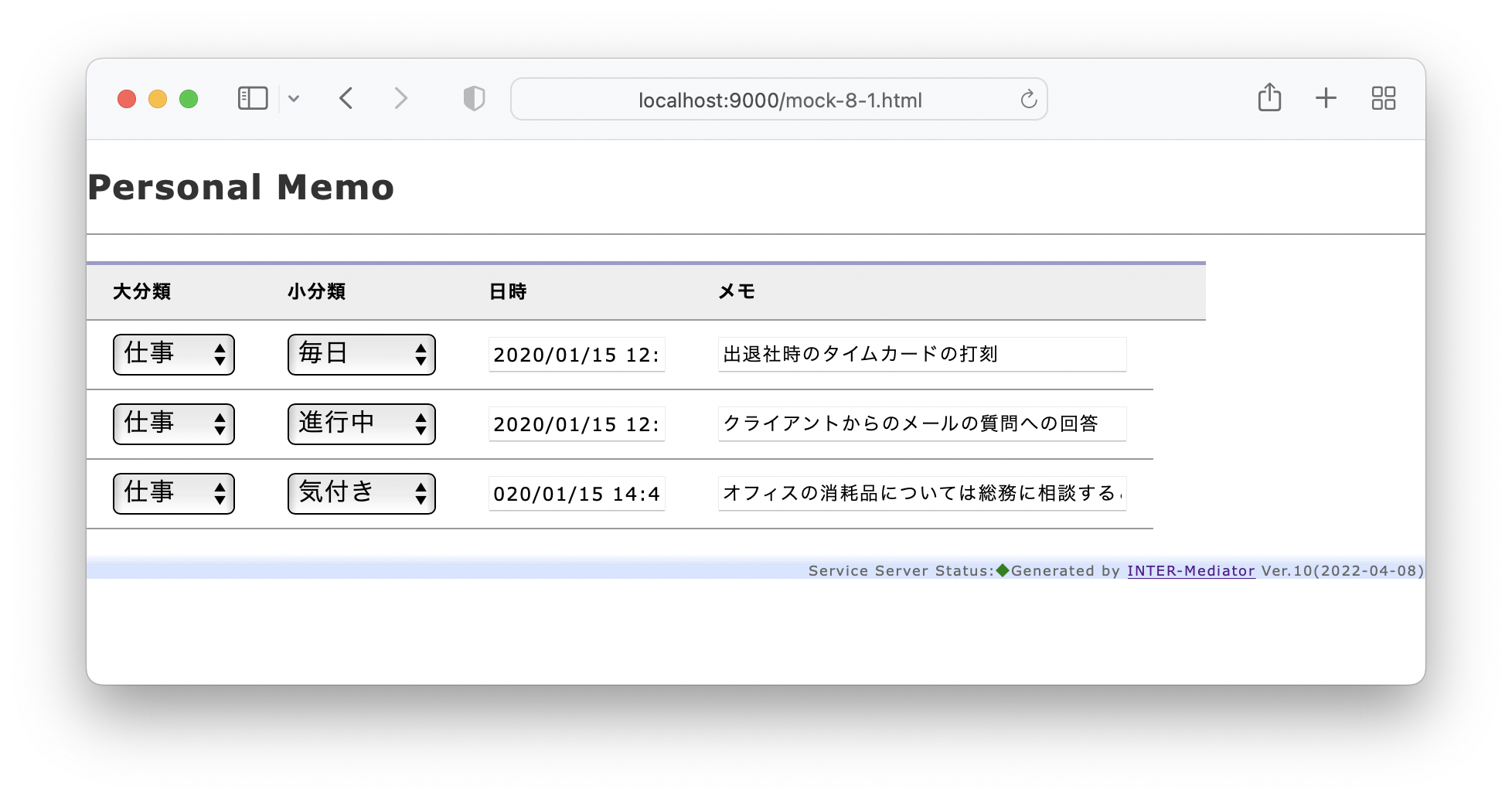
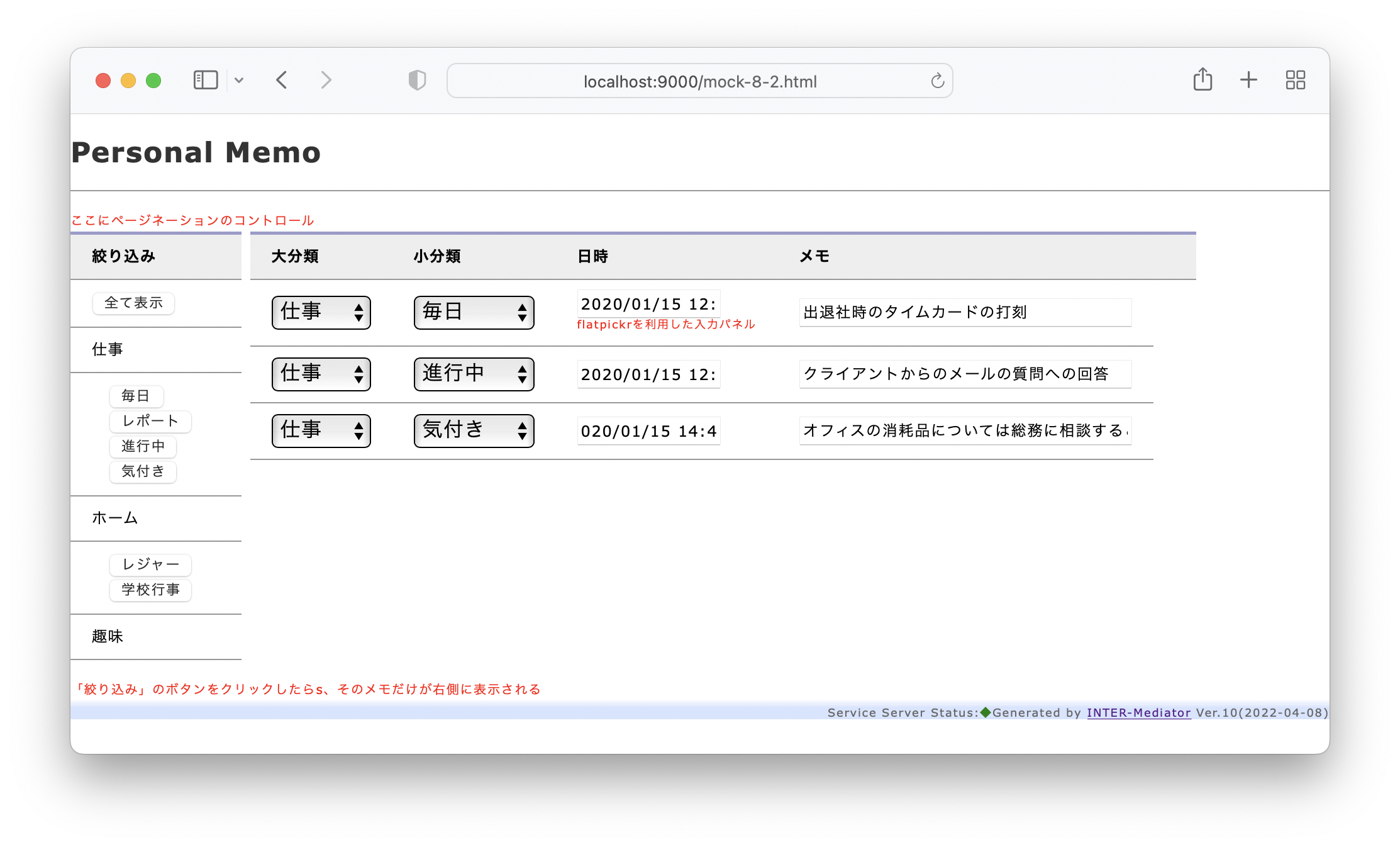
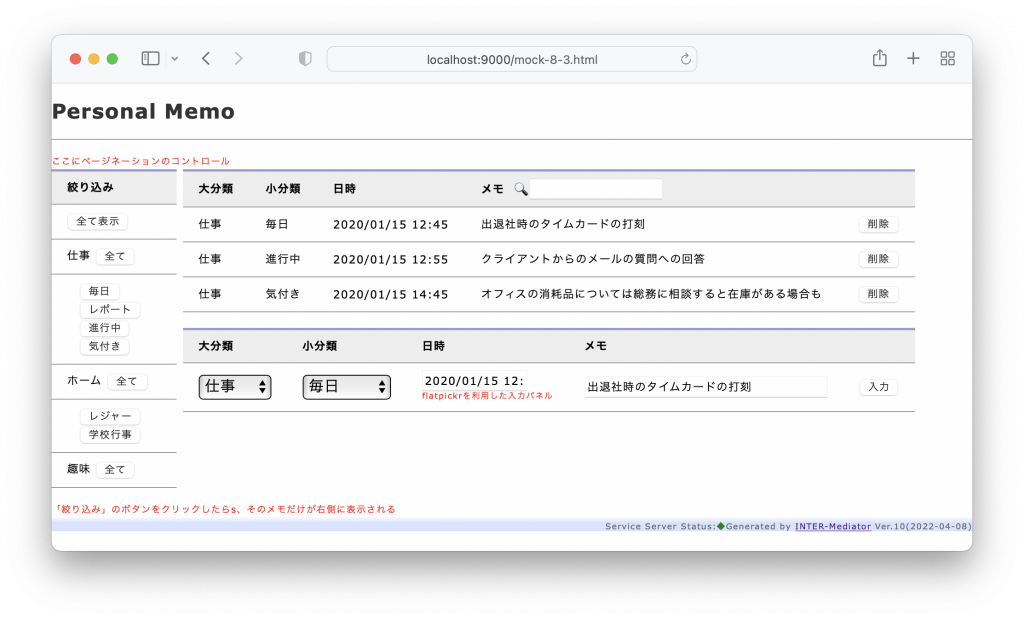
私は、Webアプリケーションのフレームワーク「INTER-Mediator」を開発している。なるべくシンプルにアプリケーション開発が可能なような仕組みをフレークワークとして提供している。例えば、HTMLページで<input data-im=”item@name”>とすれば、このテキストフィールドにitemテーブルのnameフィールドの値が表示され、変更すれば自動的にフィールドがアップデートされるといった仕組みだ。もちろん、もっと色々あるが、それはサイトを見ていただくとしよう。このINTER-Mediatorを試してみるための素材として、本体とは別にレポジトリを提供している。これを以下、「トライアル」と呼ぶ。トライアルを稼働させれば、INTER-Mediatorのコードの一部で提供しているサンプルのページを稼働させてみることができる。さらにはチュートリアルの演習を進める基盤としても稼働できるようになっている。このトライアル自体を容易にセットアップできるようにするために、Dockerの素材をレポジトリに提供している。このレポジトリをダウンロードして、レポジトリのルートで「docker compose up -d」などとすれば、ちょっと待てばサンプルアプリやチュートリアルを進めるための仕組みが稼働して、「http://localhost:9080」にブラウザから接続すれば良いという仕掛けである。
ということで、漢字をとっさに書けない私たちでも、日々、文章を書いているということは、そのほかの色々なメリットを含めて悪いことではなかったということです。おそらく、AIによるプログラミングも同じことで、AIをうまく使うというノウハウの蓄積により、過去よりも効率的に開発ができるようになるという路線がすでに先の方まで見えているのが現状でしょう。もちろん、未来にも、いきなり for ( int i = 0 … などと書きじめることはなくはないでしょうけど、むしろ「繰り返して配列の要素の最大値を返して」とお願いして勝手にコードが書かれていたり、あるいはもっと大きな要求を入力して、長ーいプログラムの一部にforが書かれていたりというようなことに、もうすでになっているわけです。つまり、プログラマとしては、スクラッチから書けなくもないものの、fをキータイプすることからスタートするだけがプログラミングではないということになっているわけです。まあ、forの書き方くらいは忘れないかもしれませんが、フレームワークのAPIの引数指定などを正確に書いていかなければならなかった過去に比べて、そういう部分も大まかな指示をもとに正確にAIがコード生成します。それは、あたかも、漢字をちゃんと書けるか怪しい私たちでも文章が作れていくのと良く似ています。
素とは、なんらかのルールで分割できないものです。有名なものは素数で、1とその数以外に、割り切れる整数がないような整数を示します。整数は、整数の掛け算で表現できます。12なら2 x 6 = 2 x 2 x 3 のようになりますが、11は、2から10までの数を考えれば、いずれも余りが出てしまうので割り切れる数はありません。ちなみに、2と3から5(つまり、11➗2 = 5…1なので)の奇数の整数でそれぞれ余りがないことを判定すれば11は素数であることは示すことが可能です。もっと一般的には、素数の列で順番にチェックするということになります。
before aFunc
start aFunc
setup aFunc
send aFunc
after aFunc
receive aFunc
ここで、thenの呼び出しでエラーを出してみると、This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch().などと書かれています。はい、ここでPromiseの知識が必要です。Promiseでは、thenやcatchメソッドを呼び出すことで、「先に進める」的な動作をするというか、それを期待しているとも言えます。thenメソッドの2つの引数にresolveやrejectメソッド(もちろん、その名前でなくてもいいのですが、たぶん、皆さんは常にそう書いていると思います)が乗ってくるので、そちらの方がお馴染みかもしれません。ともかく、Promiseを書かないで、asyncにしたからと言って、そのままawaitできるのかというと、この例で示すようにできないということになります。
FileMaker Server 19 for Linuxが登場したときに、VM上で動かす方法をブログに記載しました。今回は、Lightsail上で動かす方法をまとめておきましょう。Amazon Lightsailは簡単に言えば、Amazon版のVPSサービスです。コア数やメモリなどの設定が何段階かあるのですけど、FileMaker Serverの場合はメモリは4GB以上は欲しいところです。2コアで4GBメモリ、80GB SSDの設定で毎月20ドルです。EC2の同等なものがt3.mediumくらいだとすると、月に30ドルくらいになるので、それよりも安いということと、管理やセットアップが楽というのがLightsailでのマシン利用のメリットでしょう。なお、FileMaker Serverは8GB以上がメモリ推奨値です。4GBで動く保証はもちろんできませんが、大体、2GBだとサーバーは動くけどWeb系が怪しい感じ、4GBだとWebDirectも含めてとりあえず全機能は動くけど負荷増大には弱そう…という印象です。数人で使うサーバーなので、4GBで運用することにしました。
Lightsailによるクラウドコンピューターを用意
実際のセットアップを追っていきましょう。まず、Amazon Web Servicesのコンソールに入り、Lightsailのコンソールに移動します。そして、インスタンスを作成します。以下は、通常は画面を見ながら作業するところですので、設定のポイントだけを説明します。まず、ロケーションは東京を選択してあります。イメージは、Linux/Unixのうち「OSのみ」の「CentOS」を選択します。アプリが入っているものでない方が良いでしょう。
FileMaker Server 19.2.1のセットアップでは、http24というパッケージに依存しますが、こちらも最初は入っていません。以下のコマンドでインストールをします。これは、ClarisのKnowlege Baseにも記載されています。このcentos-release-sclはいろいろなソフトウエアが含まれています。その中に含まれているApacheとSSLモジュールを利用する模様です。
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Plugins selected: Authenticator manual, Installer None
Enter email address (used for urgent renewal and security notices)
(Enter 'c' to cancel): msyk@msyk.net
Starting new HTTPS connection (1): acme-v02.api.letsencrypt.org
メールアドレスを共有するかどうかを、YかNで指定します。
Would you be willing, once your first certificate is successfully issued, to share your email address with the Electronic Frontier Foundation, a founding partner of the Let's Encrypt project and the non-profit organization that develops Certbot? We'd like to send you email about our work encrypting the web, EFF news, campaigns, and ways to support digital freedom.
(Y)es/(N)o: Y
Account registered.
sudo yum install nano -y
cd /opt/FileMaker/FileMaker\ Server/HTTPServer/htdocs
sudo mkdir -r .well-known/acme-challenge
cd .well-known/acme-challenge
sudo nano q3mLUhDwx-9PFQ4PihyvUJfQAlQ-PVqE0SV3KBTxx4g
エディタでは、ターミナルに見えていた「Create a file containing just this data:」の次の行の文字列(q3mLUhDwx-9P…Vnu6zbvyJgTsの文字列)を入れてファイルとして保存します。このファイルの中身も、もちろん、ウインドウからコピペします。上記のような方法で作ったファイルはrootユーザー&rootグループになりますが、読み込み権限だけがあればいいので、全員に対するrが効いて問題なく処理できます。
ここまで準備ができれば、ターミナルの「Press Enter to Continue」と見えているウインドウに戻り、リターンキーなどを押して先に進めます。これで、通信とチャレンジが行われて、証明書が作成されます。以下のようにメッセージが出ますが、Congratulations!と出ていれば成功でしょう。その次の行以降に生成された証明書のパスが見えています。
Waiting for verification...
Cleaning up challenges
Subscribe to the EFF mailing list (email: msyk@msyk.net).
Starting new HTTPS connection (1): supporters.eff.org
IMPORTANT NOTES:
- Congratulations! Your certificate and chain have been saved at:
/etc/letsencrypt/live/fms.msyk.net/fullchain.pem
Your key file has been saved at:
/etc/letsencrypt/live/fms.msyk.net/privkey.pem
Your cert will expire on 2021-03-30. To obtain a new or tweaked
version of this certificate in the future, simply run certbot
again. To non-interactively renew *all* of your certificates, run
"certbot renew"
- If you like Certbot, please consider supporting our work by:
Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate
Donating to EFF: https://eff.org/donate-le
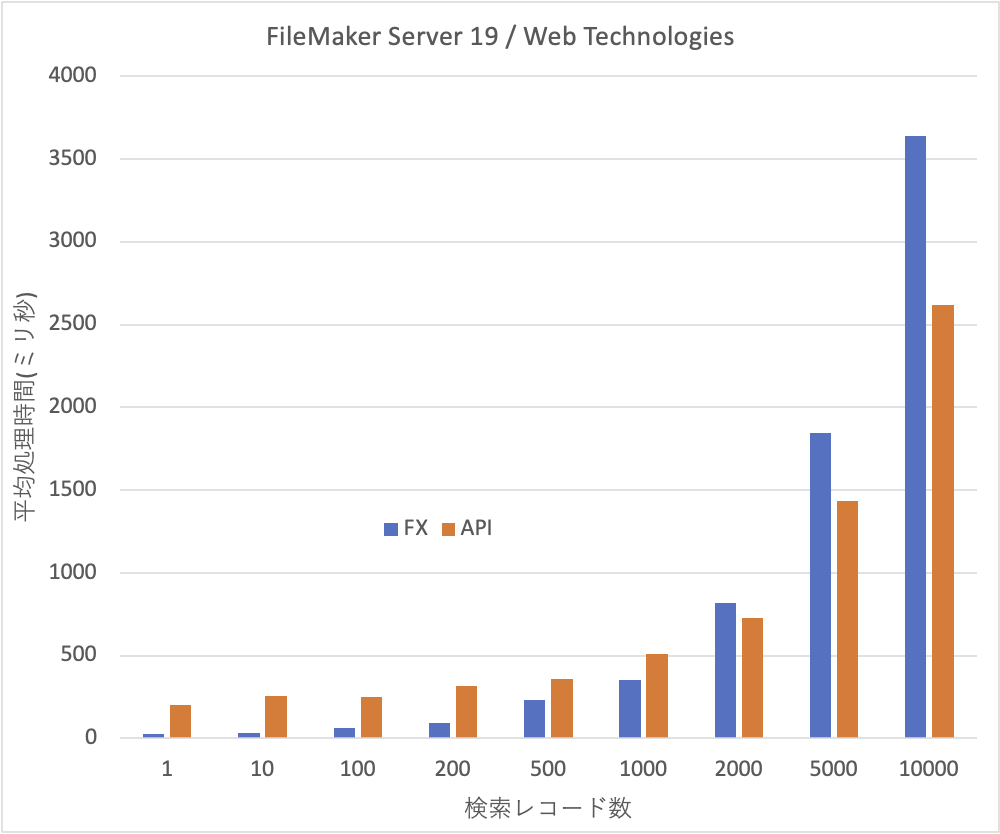
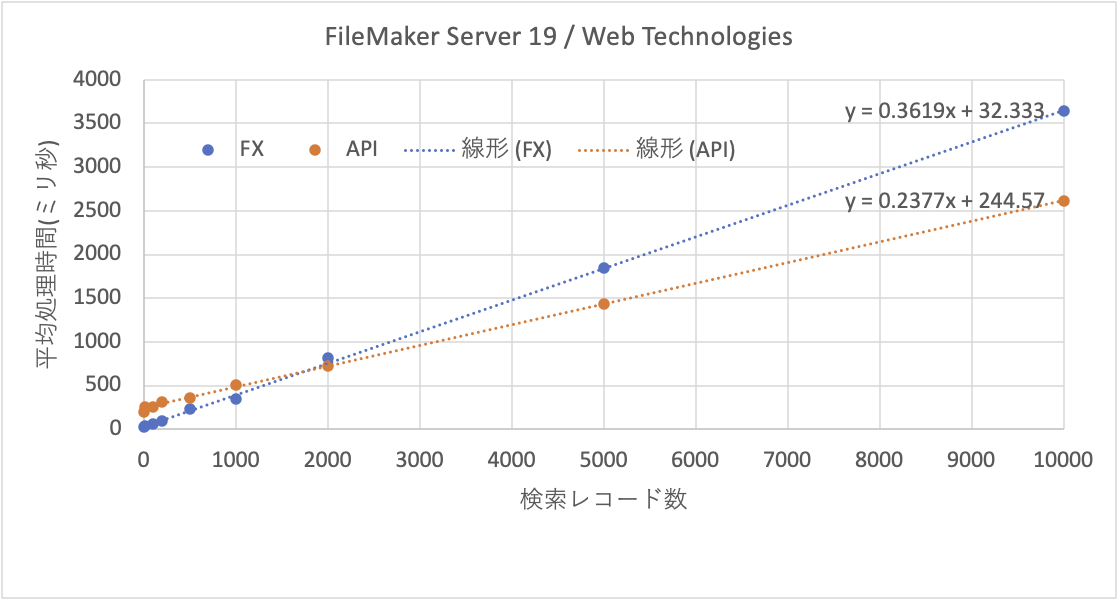
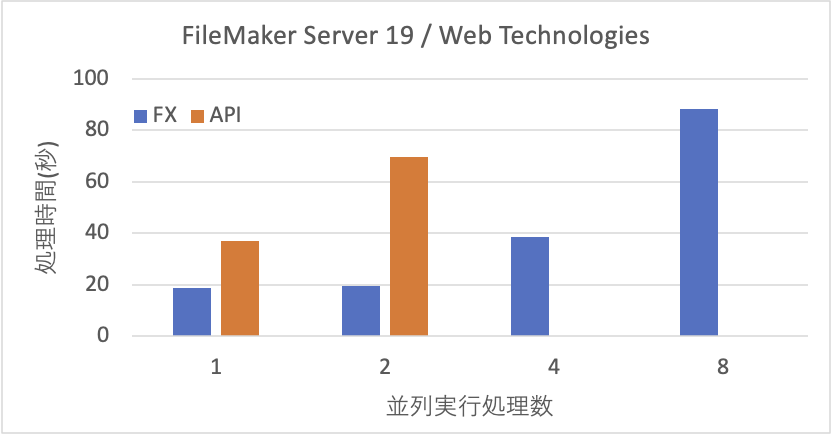
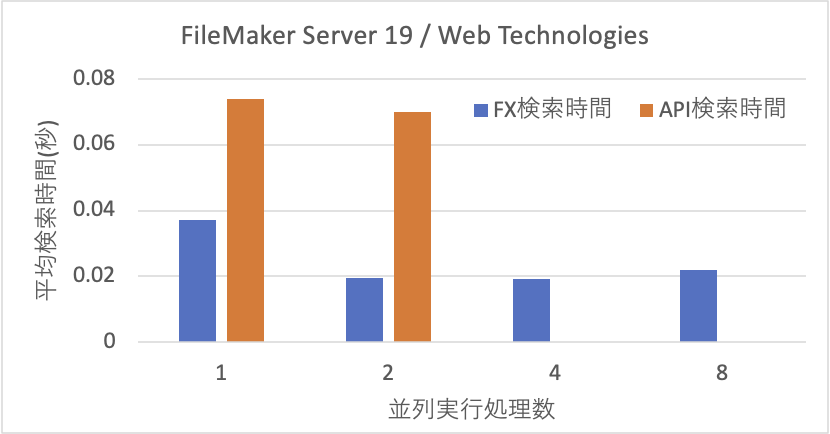
以上のことから、APIはやはりWebアプリケーションに使うとしてもアクセスが集中しないような用途に限定すべきでしょう。FXでもある意味そうなのですが、まだ、性能が高い面があります。また、Webアプリケーションでは小さなレコード数のアクセスが多いだけにFXで運用する方が有利ではないでしょうか。FileMaker Data APIはもちろん汎用的に使えるのですが、レコード数の増大に強い面があるとしたら、やはり大量のデータ交換に耐えうる設計がなされていると見るべきでしょう。
Apache2のインストールについては、あとで結果を書きますが、FileMaker Serverのインストール時に自動的にインストールされます。ここでは、CentOSのMinimal版だからかもしれませんが、「sudo yum list installed|grep httpd」とコマンドを入れても何も出力されず、Apache2は入っていません。従ってそのまま進めます。もし、「systemctl status httpd」により、httpdプロセスが既にアクティブになっている場合には、それは止める必要があると考えられます。「sudo systemctl stop httpd」で停止できますし、起動時に自動的に起動していたら「sudo systemctl disable httpd」で自動起動できないようにしておきます。Apache2自体は使うのですが、サービスの起動はFileMaker Serverに任せないと、動かない機能が出るのはプレビュー版で経験したことがあります。
では、FileMaker Serverダウンロードです。私はFDS会員なので以下のようなページが供給されていますが、そこにあるFileMaker Server 19のCentoOS Linuxの部分でコンテキストメニューをだし、「リンクアドレスをコピー」を選んで、URLをクリップボードにコピーします。
I confirm that I have read and agree to the terms of the Claris FileMaker Server Software License Agreement included with the software.
Agree (y) Decline (n) [y/n] y
Perform installation for Claris FileMaker Server…
Set up the Claris FileMaker Server Admin Console account for Claris FileMaker Server.
Use this account when you sign into Claris FileMaker Server Admin Console.
Enter User Name: admin
Create a password to sign into Claris FileMaker Server Admin Console.
Enter password:
Confirm password:
Create a 4-digit PIN needed to reset Claris FileMaker Server Admin Console account password via the command line interface.
Enter PIN:
Confirm PIN:
Set Claris FileMaker Server Admin Console account information.
Claris FileMaker Server is being installed by msyk to run as fmserver of fmsadmin group…
Create fmsadmin group…
Create fmserver user in fmsadmin group…
Add msyk user to fmsadmin group…
その後、インストール作業が再開されて、いろんなメッセージが見えますが、ここはしばらく傍観します。
インストール中 : filemaker_server-19.1.2-234.x86_64 118/141
=== Perform post-installation…
Set up core dump location at /var/crash…
Deployment type: Claris FileMaker Server
Retrieved Claris FileMaker Server Admin Console account information from cache.
Install default license certificate.
Create a default Claris FileMaker Server configuration with Japanese locale.
Open HTTP connection port 80…
Open HTTPS connection port 443…
Open Claris FileMaker Server connection port 5003…
Open ODBC connection port 2399…
Open Claris FileMaker Server Admin Console connection port 16000…
Enable and start HTTP server service…
Enable Claris FileMaker Server service…
Reload system daemons…
Check for Avahi daemon…
Avahi daemon has not started yet, wait for 2 seconds…
Avahi daemon has not started yet, wait for 2 seconds…
Avahi daemon has not started yet, wait for 2 seconds…
Avahi daemon has not started yet, wait for 2 seconds…
Avahi daemon has not started yet, wait for 2 seconds…
Start Claris FileMaker Server service…
Claris FileMaker Server service has started…
Waiting for connection session…
Sending Claris FileMaker Server Admin Console account information to Claris FileMaker Server…
Claris FileMaker Server Admin Console account is set up successfully.
HTTP Server has not started yet, wait for 2 seconds…
HTTP Server has not started yet, wait for 2 seconds…
HTTP Server has not started yet, wait for 2 seconds…
HTTP Server has not started yet, wait for 2 seconds…
HTTP Server has not started yet, wait for 2 seconds…
Warning! Failed to start HTTP server, please reboot the system.
インストール中 : 1:xorg-x11-font-utils-7.5-21.el7.x86_64 119/141
インストール中 : 1:cups-libs-1.6.3-43.el7.x86_64 120/141
インストール中 : libtiff-4.0.3-32.el7.x86_64 121/141
:
次のインストール項目に移る前に「Warning! Failed to start HTTP server, please reboot the system.」と見えています。これはインストール作業直後に「sudo reboot」をしなさいということです。しばらく待ってプロンプトが」出れば、「sudo reboot」とコマンドを打ち込んで再起動します。