昨日このポストを書いた後、サーバーのメンテを長くやってないなと思ってアップデートをかけたら、一気に起動しなくなってしまってデータが消えてしまいました。ある程度はバックアップしてあるので、メッセージは一昨日分まで、画像などは2019年までしかなかったです。まあ、でも、Ubuntu Server 20.04に入れ替えて心機一転です。ただ、同じ内容を書いても、日が変わると内容が違って来そうで、いいのか悪いのか、ともかく昨日書いた内容を思い出しつつ、変化しながら書きます。
データベースの設計を行う上で、まず、データをどのように見るのかという基本的なことで、表を出しました。表に対して、レコードやフィールドといった名称を定義しました。多くの方が表計算ソフトを使っているので、表は便利かつ有用であるというのは理解はしていると思いますが、それが「なぜ?」を突き詰めると実はなかなか難しいということも説明しました。ほとんどの方が、表にまとめて、あるいは表にまとまったものを参照して、何か目的を達したり、より効果的に作業ができるなどの成功体験があるということがあるでしょう。そうした体験から有用性を理解しているということが、ともかくの理由でした。
なお、数学的な世界では、集合の仕組みを利用して、表そのものをきちんと定義するということは可能であり、いわゆるデータベースの教科書ではそうした集合論をベースにした表の定義が最初の方で説明されています。いきなりその辺りで挫折する方も多いかもしれません。また、そうした高度に抽象化された世界が実際のデータベース設計にどこまで役に立つのと問われると、最初のとっかかりとしてはやはりきついと思います。データベースの設計をある程度理解した時、そうか、基本は集合だったよなということを思い出すことで理解が深まるということもあります。
いずれにしても、まずはデータを表として記述することで、ある程度コンパクトに、そして存在するデータを余すことなく記述できます。つまり、Excelでなんでもできるでしょうというあたりの考えに近いかもしれません。つまり、表はそれで完結した世界です。しかしながら、私たちは書ききれないほどの大量のデータを扱いたいのでデータベースを使おうということがあります。この時、データベースは表形式にデータを扱いものの表の縦横を自由に使うのではなく、まずは行に相当するレコードに区切り、レコードはフィールドとして分割され、フィールドにデータを入力できるということを説明しました。その状況をツリーのように記述できます。ここでの線は、導出可能であるということを意味しています。つまり、あるレコードが決まれば、そのレコードからフィールドの値が取り出せるということです。プログラミング言語で処理をすると、実際にそうした側面が強く出ますが、ここではモデルの段階から表はレコードの集まり、レコードはフィールドの集まりであるということを意識したいと思います。
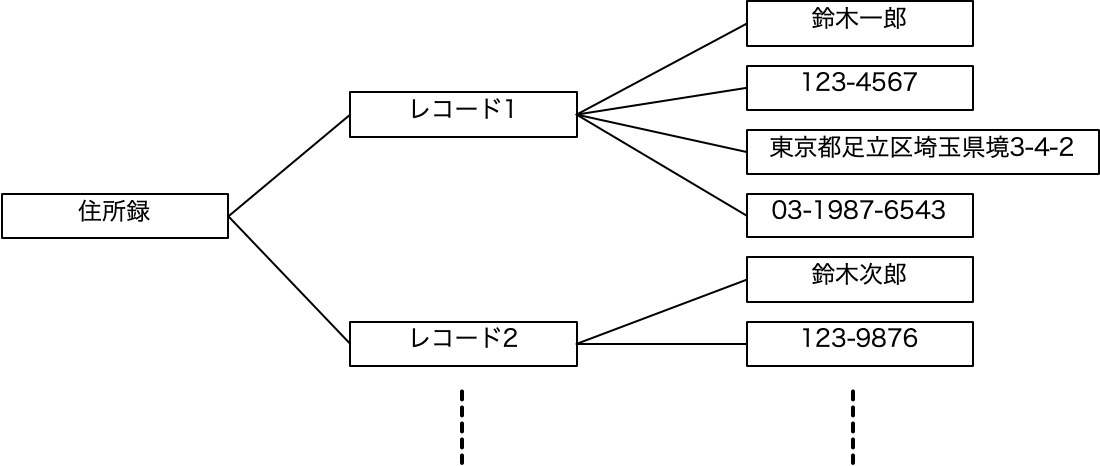
このように、表は階層的なツリー図で表現できるということであれば、表とツリーは同一のデータを示していると言えます。ただ、ツリーの方が実際に描画するのは大変そうですが、概念としては同一のものを示しています。
ここで、具体的にデータが存在するのはフィールドです。レコードもデータの集まりではあり、要するにフィールドの集合ではありますが、単一のデータを持つわけではありません。その意味では、レコード、そして表自体も存在がちょっと抽象的になります。それをまずはあえて楕円形のオブジェクトで書きます。レコードには名前等がないので、便宜的にレコード1などと数字付きで書きますが、表そのものには「住所録」といった名前があります。
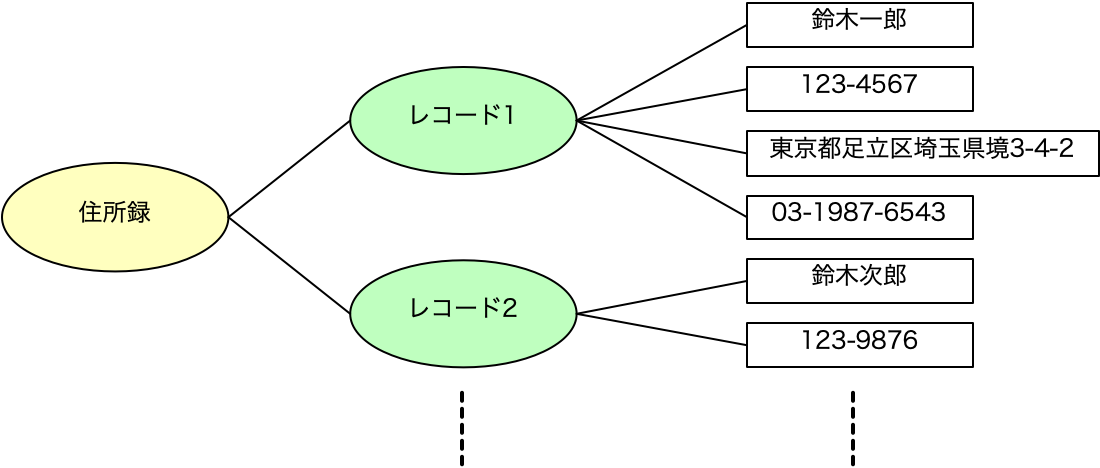
ここで、表自体の設計情報を記述する場合、もちろん、全データを書くというのは設計図としては複雑すぎて意味がありません。設計、つまりモデルは、興味のある対象に絞った情報を集めたものというのが原則です。それを、必要な情報に捨象するといった言い方をします。つまり、「どんな表なのか」ということを如実に示す情報が欲しいわけです。
ここでの表を見てみると、まず、どのレコードも同じフィールドを持っています。そのフィールドの実データではなく、フィールドの名前を使って、どんなフィールドが存在するのかを記述してみると、次の図のようになります。どのレコードからも、同一のフィールドが存在するので、全レコードについて記述する必要はなく、レコードは1つだけで良いでしょう。
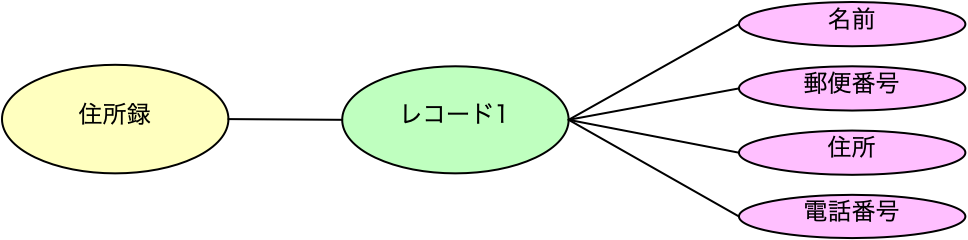
ここでさらに、表はレコードの集合であるということが決められているということでああるのなら、レコードが存在しますということをモデル上に表現する必要はないとも言えます。ただ、「しない」わけではなく、そういう表現をすることもありますが、ここではシンプルな表はみんな同じ考えで見ているとして、レコードの存在はあえて書かなくても同じフィールドを持つものが複数存在するということを前提とします。すると、残ったものは、表の名前と、フィールド名です。これらを、ちょっとわざとらしく、ボックスに書いてみると次のようになります。

これは、ER図のエンティティのようでもあり、クラス図のクラスのようでもあります。いずれにしても、こうした記述が住所録を管理する表の設計として認識できます。元は表ですが、それを階層的に見た上で、必要な情報だけを残すと、このようなものができます。データベースの設計者は、このボックスを見ることで、実データが表として展開されて、たくさんのデータが入るという状況を想定し、それが実際のシステムの用途に合致したものかどうかを検討しながら設計を進めるということができるのです。
ここで、命名が「住所録」といった集合的なものになっている点にちょっと気に掛かる人もいるかもしれません。ここはある意味好みの問題なのかもしれませんが、表に対して名前をつけているのか、レコード1つに対する名前なのかで分かれるところだと思います。データベースの設計では、レコードとして実現されるので、表とレコードは最初から組み合わされているので、ER図のような世界に入り込めるのです。これがクラス図であれば、「住所録」ではなく、「顧客」などの単一レコードを示す名称をつけ、さらに「顧客リスト」といったクラスを考えて、顧客リストは顧客の集合、つまり表とレコードの関係のような記述をする方が落ち着くと思われかもしれません。クラス図の方が抽象度が高いので、いろいろな記述のバリエーションは考えられます。これは、結果的には設計者がどう決めるかの問題です。少なくとも、1つの設計の中で、ボックスの粒度をどう扱うかを統一した上で、そのルールが他の人にわかるようなコミュニュケーションをしているかどうかということです。
私自身は、クラス図で書くことが多いのですが、いきなりデータベース設計するのではなく、まずはドメイン分析からスタートして詳細化してデータベース設計に持ち込むので、その結果クラス図で記述する異なってしまいます。もっとも、使っているツールのastah* professionalは、クラス図からER図を作成できるので、単にツールで書き換えればER図になります。また、クラス図で記述すれば、オブジェクト図を書くことができます。オブジェクト図はクラスに基づくオブジェクトであり、つまり実データが入ったボックスを記述できます。その仕組みにより実際のデータを当てはめてみて、それが意図した状態を表現できているかということを、検証することが可能です。複雑なデータであれば、そうした設計から実データ展開した検証をしたくなりますが、クラス図とオブジェクト図で、作業が可能です。クラス図でスタートしたら、結果的にクラス図で記述したデータベース設計になり、自分としては違和感ないのですが、怪訝な顔をされることもありますね。
次回からは、架空の会社の業務を想定した上で、同じ名前の対象物に対して、部署ごとに管理したい内容が違い、結果的に違う表が必要になるというお話を何回かに分けて行います。