前回までに、単純な「商品」という単語でも、状況によって異なるものを示すことを説明しました。実際の開発では、これと同じように、たくさんのユビキタス言語を認識して、それらを分析し、必要な仕組みを考えていくことになります。その時に有用な考え方が、まさに「表」です。それぞれの部署で記録したいデータを実際に表に作ってみます。場合によってはすでにその部署で表が作られている可能性もあります。しかしながら、もっと大雑把なデータしか得られないかもしれません。これは利用者側作るものではあるのですが、表の内容が無茶苦茶でないかなどはやはりエンジニアリング的な視点でチェックしないといけません。表の内容が途中から変わってしまっているような表の利用は要注意です。
それで、ここでの実例でできたおもちゃロボットメーカーについて、ちょっと恣意的ですが、システム化したい業務についての根幹となるデータを表にしてみます。現実にはこんなに単純明快ではないとは思いますが、考え方のサンプルということです。

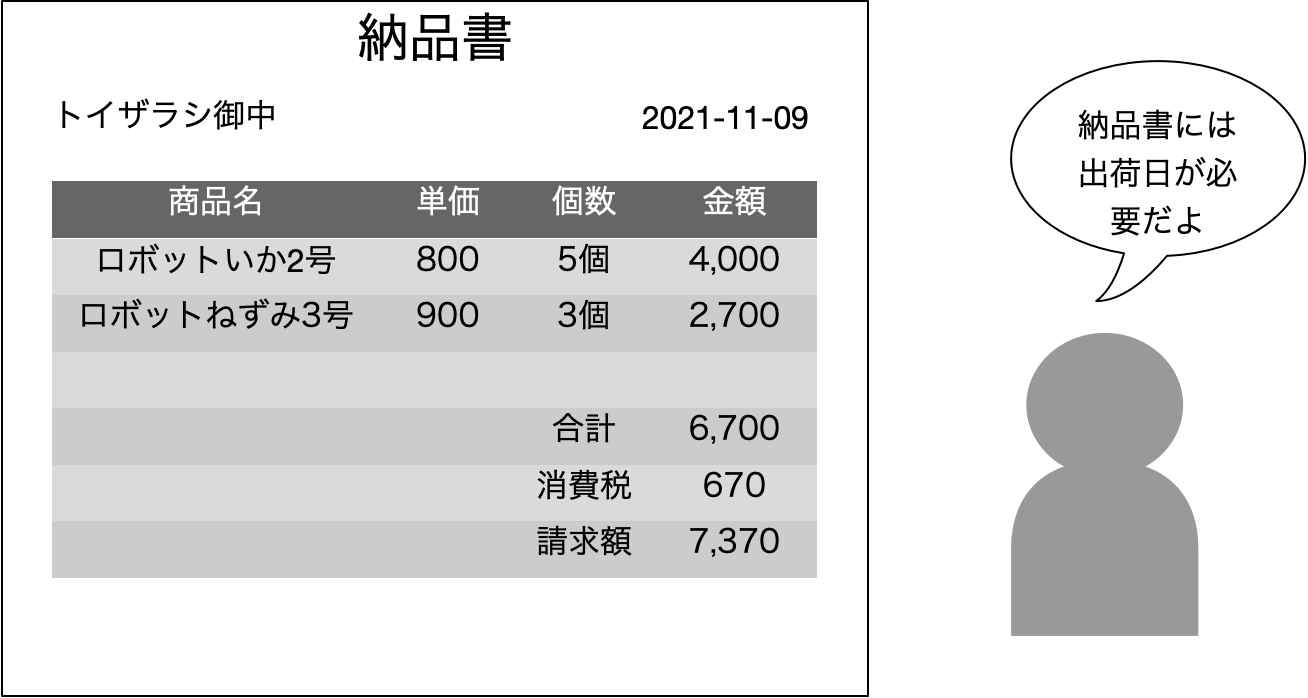
現状、多くの仕事はExcelが絡んでくるので、中途半端にシステム化されていることが多いでしょう。特にExcel自体を「便利に使っている」ような職場では、システム化と言っても、ヘタをするとExcelの再発明を求められてしまうことも、結構あります。表にするのですが、ここで何を求めたいかのかというと、1レコードに相当するものとして何を見るのかということです。実は営業部門が一番わかりにくいです。営業については実際にはリレーショナルデータベースの典型的な例でもあるので、少し先に詳しく説明しますが、あえて「営業は、紙の納品書を作っている」くらいの感じで考えていただければ、いつ、どの顧客に、どの商品をいくつ売ったのかという情報を記録することで、月末にまとめて請求ということができるかと考えます。ここでの表は、納品書の明細が1レコードになりそうです。言い換えれば、それより小さな単位がなさそうであるというくらいの根拠です。商品や顧客は当然ながら表には繰り返し登場します。
製造部門はある意味わかりやすいです。作った箱入り製品1つずつを管理したいのですから、1レコードは、1ボックスということになります。マーケティング部門は、とりあえず製品カタログの残り部数を管理するとしたら、1レコードは、まさにマーケティング部門が把握する1商品ということになります。
なお、このままだと、データベースの設計に持ち込めません、ここからまだやるべきことはあるのですが、重要なことは、実際に現場で発生しているデータを記述するということです。ここで、単に曖昧に記述するのではなく、表の形で頑張って記述するということです。全部でなくても構いませんが、少なくとも、表の数行分を記述してみることが必要と考えます。もっとも、そういう表の形になったものを頭の中で再現して、何も書かずにできる人もいます。設計が得意な方はそれができるかもしれません。しかしながら、こうして作り込んで行くコアな考え方が正しいかどうかを検証するのは設計が不得意な人かもしれません。記述して見える化するという意味では、表は出発点としてはみんなが理解できるものとも言えるもので、大変有益でしょう。
ちなみに、ここではそれなりに整理してしまっている感じですが、空白があるのは当然としても、同じ列に途中からデータの種類が変わってしまうこともあります。その場合は列を分けるなどします。つまり、列で分類するという言い方もできるでしょう。そうしているうちに、列に名称をつけることができるようになります。その列にあるデータの代表的な名前をつければ、逆にその列に何のデータが入れられるのかも理解しやすくなります。もちろん、それがすでに紹介したフィールド名になります。

フィールド名の命名ルールは結構人それぞれですが、少なくとも、「代表名」であるというのはほぼ全ての方に同意いただけるでしょう。また、データベース上では同一のフィールド名を複数つけることは許されていませんので、異なるフィールド名にしなければなりません。また、長すぎると式を書いたりするような時に結構面倒です。ということで色々悩みます。以前に大変分析が困難なデータベースにあたったのですが、どう困難かというと色々あるのですけど、「適用_編集用」と「適用編集用」みたいなフィールドがあって、フィールド名で判断が極めて困難という状況でした。このようなフィールド名だと、「フィールド1」「フィールド2」と付けられているのとあまり変わりません。さらにその時にはオチがあって、それらのフィールドの前者はPDF出力時、後者は印刷時に使われるというこれまたクイズのような(パズルではなく!)データベースでした。
いずれにしても、フィールド名はよく考えて、統一的な名前で、かつそこに入ってくるデータが連想しやすいものにするのが言うまでもありません。例えば、「平均値」と言う名前のフィールドをつけたけど、そこには月間の平均値が入っているとします。しかし、やっぱり週の平均値も欲しいので「平均値_週間」フィールドを作ったとします。そうなると、「平均値」ではなく、「平均値_月間」フィールドにするのがベターな方法ではあるのですが、そこをそのままにするエンジニアが多く、後からデータベースに関わる人たちに混乱をもたらしてくれます。もちろん、プログラム内にフィールド名が文字列で記述するような場合、下手にフィールド名は変えたくないと思うかもしれませんが、一括置換すればいいことです。また、FileMakerでは基本的に気軽にフィールド名は後から変えられます。今、この平均値が売上だったとして、個数の平均値が欲しいとなると、どうしましょう。この集計した結果のフィールドは「売上_平均_月間」のように、処理対象、処理方法、グループ化基準といった情報が、どのフィールドにも、同一のルールで、同一の用語で入っていないと、分析が辛くなります。日本語の用語だと思っていたら、途中から突然英語になってしかもカタカナだと(「売上_アベレージ_年間」みたいな)何かのギャグか嫌がらせかと思ってしまします。用語のルールも重要ですが、自分で決めたルールを全体にわたって最後まで踏襲するということがもっと重要なことになります。
ところで、フィールド名自体に「データ」的な性質の文字列が入るのは、ちょっと違和感あるものの、ある意味便利なのかもしれません。例えば、アマゾンから購入したかどうかを記録する「Amazon購入」フィールドはどうでしょう? では楽天やモノタロウと購入先を増えてきた時にそれぞれ別々に管理したければ、フィールドを増やすしかありません。通常、そうなると、「購入先」と言うフィールドに文字や数字で区別して購入先を記録するのが妥当な気がします。となると、フィールド名は抽象度の上がった名称であるとも言えて、実はフィールド名にデータ(この場合は「Amazon」と言う文字列がある意味ではデータです)が入ることはないと言うことも言えます。しかし、単にAmazonだけ特別で管理したい場合には、「Amazon購入」フィールドは、わかりやすいので悪くはないと思います。この問題は、結果的に最後まで作ってみないと正しかったのか、正しくなかったのかはわからないものの、ルール的には一概に決められないと言うことでもあります。
そういえば、フィールド名に表の名前を入れるかどうか問題もあります。これに関しては入れないのが基本だと思います。入れるとしたら、全部のフィールドに入れないと妙にも思えるからで、それは非効率的です。ところが、「名前」と言うフィールド名は、それだけ単独あってもわかりづらいです。そのような場合は「商品_名前」にするという手もありますが、SQLの世界では「テーブル名.フィールド名」の記述が随所にできるので、表の名前はフィールドになくても、表現は可能とも言えます。ですが、極めて一般的な名称については、やっぱり表の名前をつけたり、あるいはそれを連想させる名前をつけたくなってしまいたくなります。これは感覚的な問題です。加えて、あちこちのテーブルに「名前」フィールドがあるのも、混乱の元かもしれません。
ついでに、フィールド名に誤変換や間違えたスペルはなるべくやめましょう。データベースを分析しているときにストレスが強くかかります。見る度に、何だか設計・分析とは違うスイッチが入るのですよ。スペルは今時の開発ツールではみてくれますが、誤変換は自分で見つけるしかありません。データベース全体に渡って「精算」であるはずが「清算」だったものを見たことがあります。レイアウト上は流石に利用者が指摘したのか「精算」になっているのですが、フィールド名が全部「清算」でした。
次回は、この表にした結果をもう少し分析してみましょう。