ここまでのところで、業務分析して、各部署で必要なデータがどんなものかを見える化するために、表を作りました。表の1行1行が表現している内容を考えれば、同じ商品という単語を使っていても、部署ごとに扱い、つまりは商品に対する概念や定義が違っていることに気づきました。また、一方、共通の概念もあり、それは商品の名前は共通であるということで、商品マスターに名前を覚えさせておこうという判断ができたわけです。
この時、商品の表を、製造管理の表の「商品名」フィールドをごっそり持ってくるということでいいのですが、同一名称の行が発生します。今のところ、商品名だけしか商品の表では登場していないので、重複したデータはなくてもいいだろうと考えます。1つだけ記憶していれば問題はないと考えます。製造管理の表では複数の同一商品が存在しますが、それぞれが同一の商品の行を参照すれば、問題はないわけです。ということで、商品の表は商品名の重複がないものにして、番号を振ったということです。
こうして分離しても、元の製造管理の表が得られます。その手続きは次の表の通りです。少ないデータだけならこうして具体的にデータを並べて考えてみるのがわかりやすいでしょう。
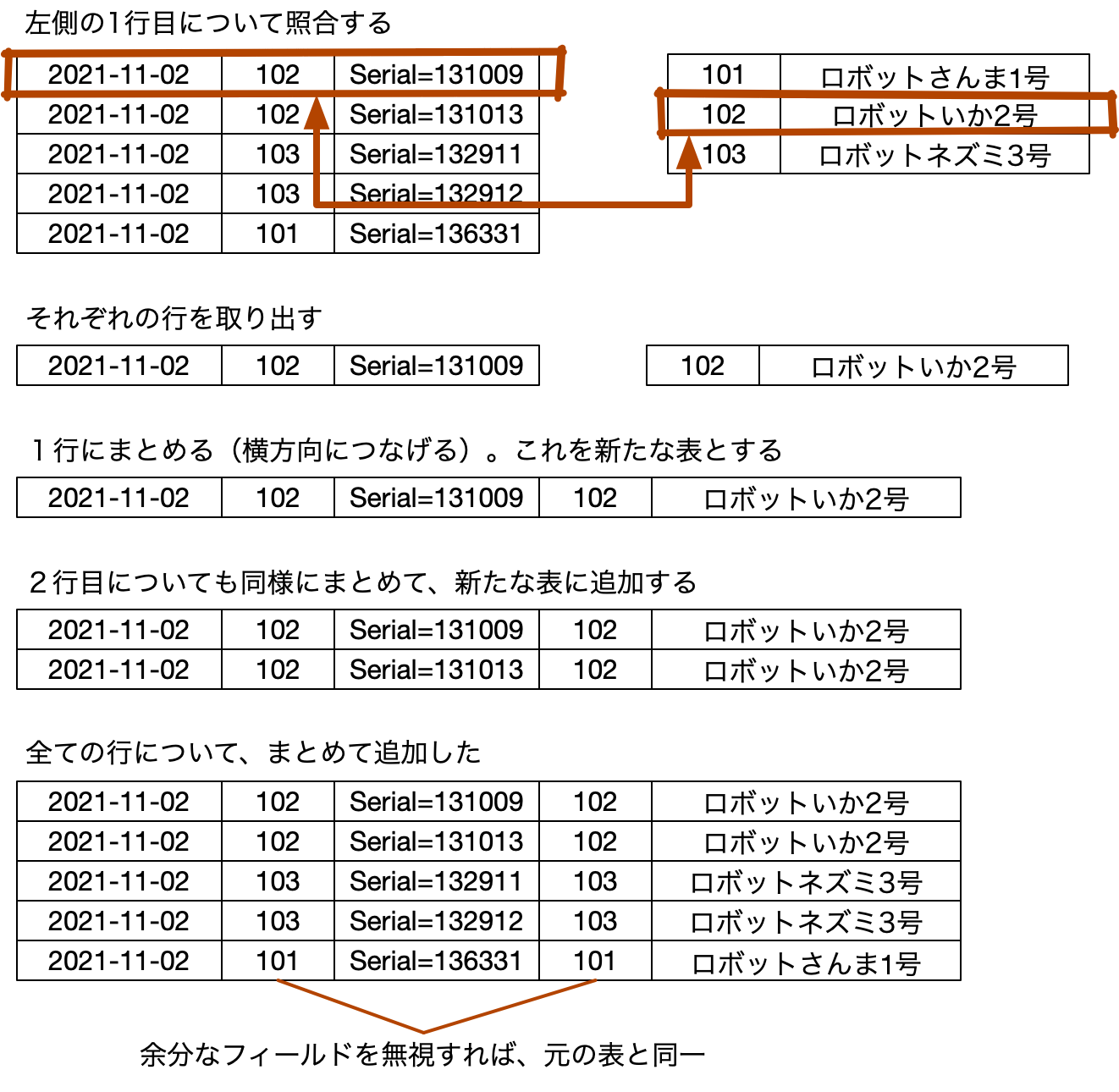
最初は分離した表になっていますが、左側の製造管理について、最初の1行を取り出します。すると、商品の102番を参照するようになっているので、商品の表の102番の行を照合し、そしてそれぞれ取り出します。続いて、この2つの1行を、1行にまとめます。つまり、単につなげます。この作業を、左側の製造管理の各行について行うと、最後の表になります。これは、商品の表を分離する前の製造管理の表と基本的に同じです。フィールドの順序は違いますし、商品IDも入っていますが、表として表現していることは同等であると言えるはずです。つまり、どちらの表でも、業務は同様に可能です。
このような、表から表を作る処理を「結合」と呼びます。リレーショナルデータベースの代表的な処理です。SQLでは、JOINというキーワードでステートメント内で記述します。ただ、JOINの処理にもいくつか種類がありますが、これはまた別の機会に説明しましょう。
ここで注目していただきたいのは、商品の表は重複を削除していても、問題なく元の表が再現できるということです。「ロボットいか2号」という文字列を、図で見たように、1つ目と2つ目のレコードで使いまわしています。言い換えれば共有しているのです。どちらも『行を取り出す』と記載する部分で、いわば元の行の複製を作っていて、それを結合した表に持ち込んでいます。結合した表の商品名は、全て、商品の表から複製した情報であるため、当たり前ですが、商品テーブルのデータが正確に結合した表に組み込まれていて、同一の商品の商品名は常に同一であるということです。
この結合結果は、基本的には一時的に使うのものであって、この結合した表自体を永続的に記録しているわけではありません。永続的に記録されているのは、ここでは手続きの最初の2つの表であるのが、データベースの一般的な実装になります。ただし、データ処理を高速化するために結合結果をどこかに覚えておくような最適化処理は今時のデータベースは普通になされていると言ってもよく、厳密に技術的な意味では永続化されているかもしれません。しかしながら、設計の段階では、必要に応じて結合した表を一時的に、つまり、現状の情報を一覧表を作って参照すると言ったような用途で作るという流れが一般的であると考えてください。
次回は、販売明細について検討を進めてみましょう。