一部に間違いがあり、修正しました。修正箇所は青字で記載してあります。(2017-06-17)
FileMaker 16の大きな機能アップの1つは、OAuth対応だ。GoogleのアカウントでFieMakerデータベースへのログイン認証ができるようになったのである。OAuthの大きな特徴は、1度パスワードを入れれば、その後に認証されたことが異なるサービスに対しても継続されることである。これは「パスワードを覚えていて、その都度送り出す」のではなく、認証した事実を別のサーバーにうまく伝達を行うことで、サービスをまたいだ認証の継続を実現している。パスワードのやりとりは最初のログイン時だけになるので、概してより安全な認証方法と言うべきだろう。FileMakerがOAuthにどのように対応したのかを、データベースログインをGoogleアカウントでログインできるようにするための設定を通じて説明する。
FileMakerデータベースへのログイン
FileMakerデータベースをFileMaker Serverで公開したとする。以下はINTER-MediatorのサンプルデータベースをプライベートネットワークにあるFileMaker Server 16で公開した結果を示す。上記のサンプルで改変した点は本文途中で示す。
公開したデータベースをFileMaker Pro/Advancedで開こうとすると、次のようなダイアログボックスが表示され、そして、アカウント名とパスワードを入力して、「サインイン」ボタンをクリックする。
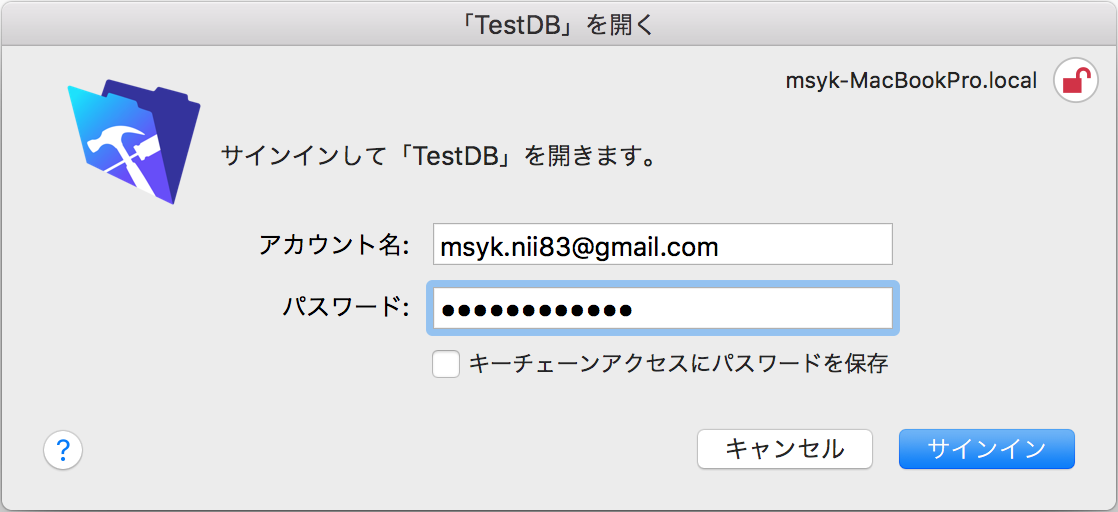
ここで、FileMaker Server 16で、Googleを認証サーバーとして利用するような設定を行い、加えてデータベース側にそのGoogleのアカウントを追加設定すると、サインインのダイアログボックスがでは以下のように、「Google」のボタンが下部に追加される。このダイアログボックスが表示された時には、「Google」ボタンをクリックするだけでOKである。アカウント名やパスワードのテキストフィールドに、Googleのユーザー名やパスワードを入力することは不要である。
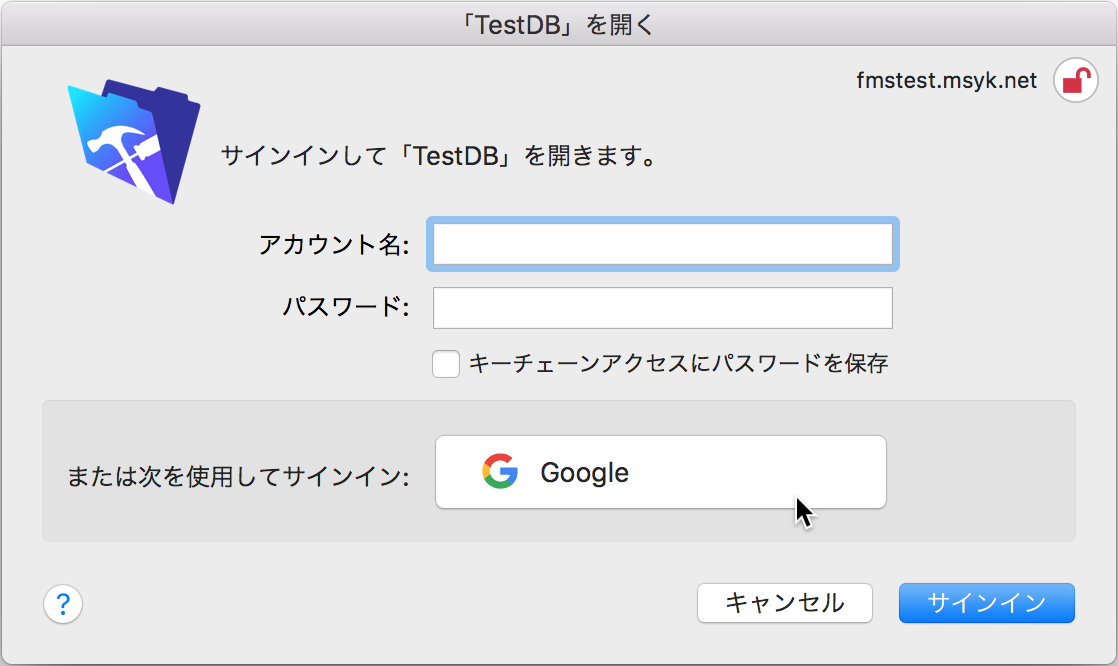
そうすると、デフォルトのブラウザが開き、Googleアカウントのログインの「アカウントの選択」の画面になる。ちなみに筆者が複数のGoogleアカウントでログインをしているのでアカウントの選択になるのだが、アカウントが単独の場合には何も出ないかもしれない。あるいはまだログインをしていないのなら、さらにパスワードの入力や場合によってはアカウントの入力も必要だろう。何れにしても、サインインのダイアログボックスで「Google」ボタンをクリックすると、Webブラウザを利用してGoogleでの認証結果を確認する。その時に、Googleのアカウントでログインしていなければログインをするが、ログインして入ればそのまま処理が継続される。
ログインが成功するか、ログインされて入れば、次の図のようなダイアログボックスが表示される。これは認証が成功したことを示しており、データベースを利用するには「FileMaker Pro Advancedを開く」(もちろん、Proの場合もある)ボタンをクリックする。なお、「開かない」にしたら、何もしないので、ここでは必ず「〜を開く」ボタンをクリックする必要がある。

そうすれば、データベースが開かれる。この時、Get(アカウント名)等の取得関数の結果もデータビューアで示したが、ログインしているGoogleアカウントのアカウント名がそのまま見えている。
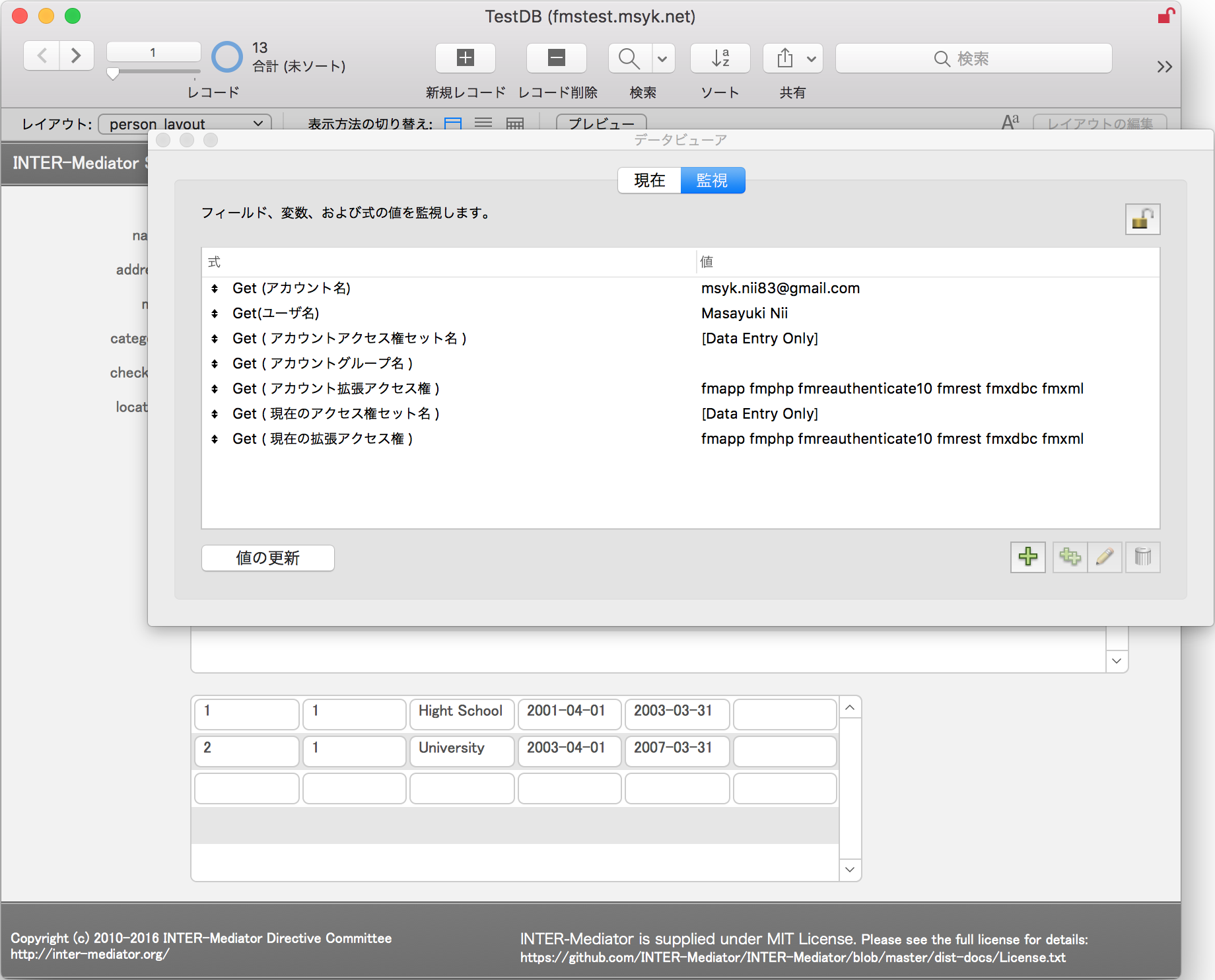
以上のように全てがうまく設定された状態だと、ログインパネルで、Googleボタンをクリックすることで、パスワードをその場では入力することなく、自動的にデータベースを開き、データベースではGoogleアカウントで誰が使っているのかを識別できる状態になる。あらかじめGoogleアカウントでログインしていれば、何も追加作業は必要ないか、あるいはアカウントの選択の作業が必要になる。 ログインしていなければ、Webブラウザでログイン作業を行う。
OAuthで利用するためのデータベース
FileMakerのデータベースは、ProないしはAdvancedで管理者でログインをして、「ファイル」メニューの「管理」にある「セキュリティ」を選択する。認証を行なったのちに、アカウントの追加をまずは行う。「アカウントの認証方法」の部分には、「Amazon」「Google」「Microsoft Asure AD」の3つの選択肢が増えている。利用するOAuthサービスを選択した上で、ユーザー名は、そのサービスのユーザー名をそのまま指定する。このように、Googleであれば、Googleのユーザー名を指定したアカウントを作っておかなければならない。もし、作っていない場合は、たとえGoogle側のログインが成功していてもデータベースの利用はできなくなっている。一見すると、他のこの種のサービスのように自由にログインできないのは不便と思われるかもしれないが、登録しないと利用できないようにするのがセキュリティ確保の基本である。誰でもログインできる状態というのは、多くのFileMakerデータベースには望まれていない。
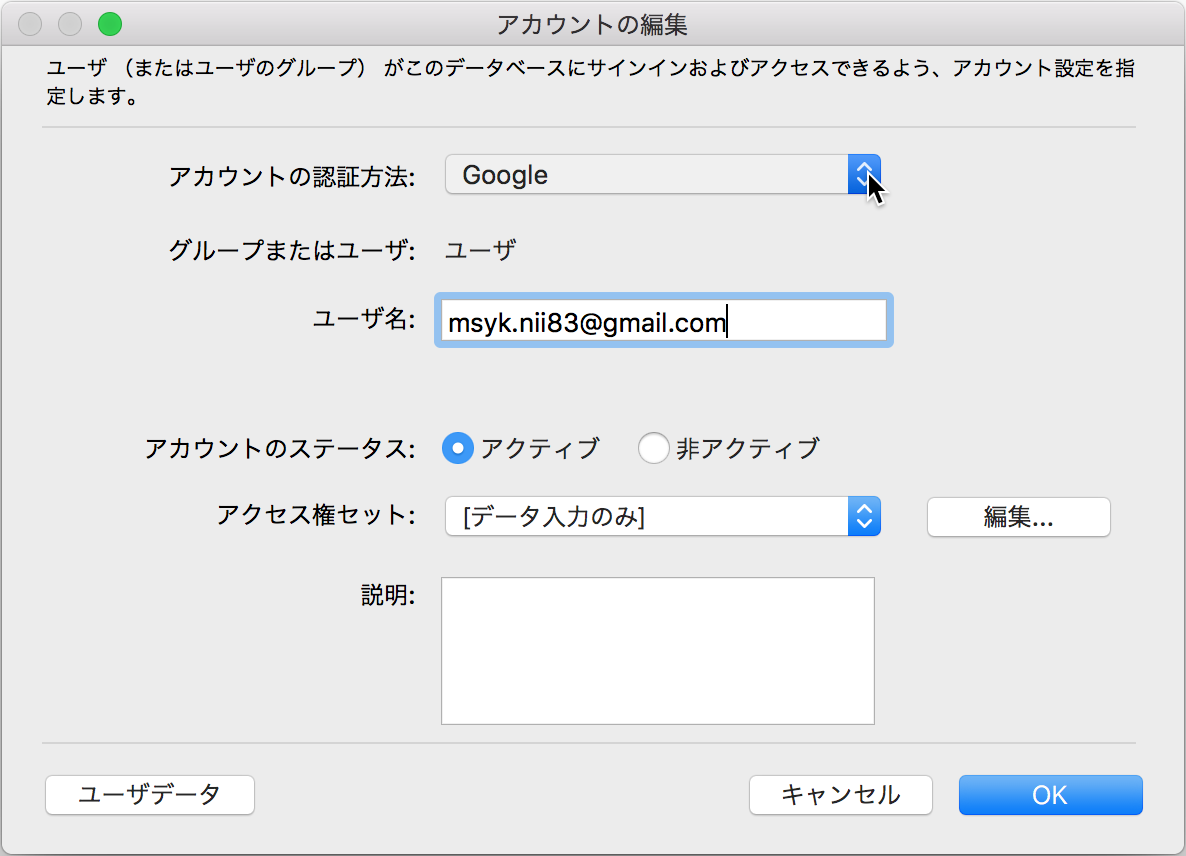
アカウントが実際に利用できるようになるには、「アクセス権セット」を選択する必要がある。ここでは既定の「データ入力のみ」を選択しているが、もちろん、このアクセス権セットに、fmappつまり「FileMakerネットワークによるデータベースアクセス」の拡張アクセス権が設定されている必要がある。これは従来からと同様で、FileMaker Serverで公開するデータベースでは必須の設定である。なお、INTER-Mediatorのサンプルデータベースでは、「データ入力のみ」のアクセス権セットには、fmappはチェックが入っていないので、サンプルをそのまま使う場合には注意していただきたい。
アカウントの一覧には、Googleがタイプの項目が増えており、アカウントの列ではGoogleのユーザー名がそのまま見えている。
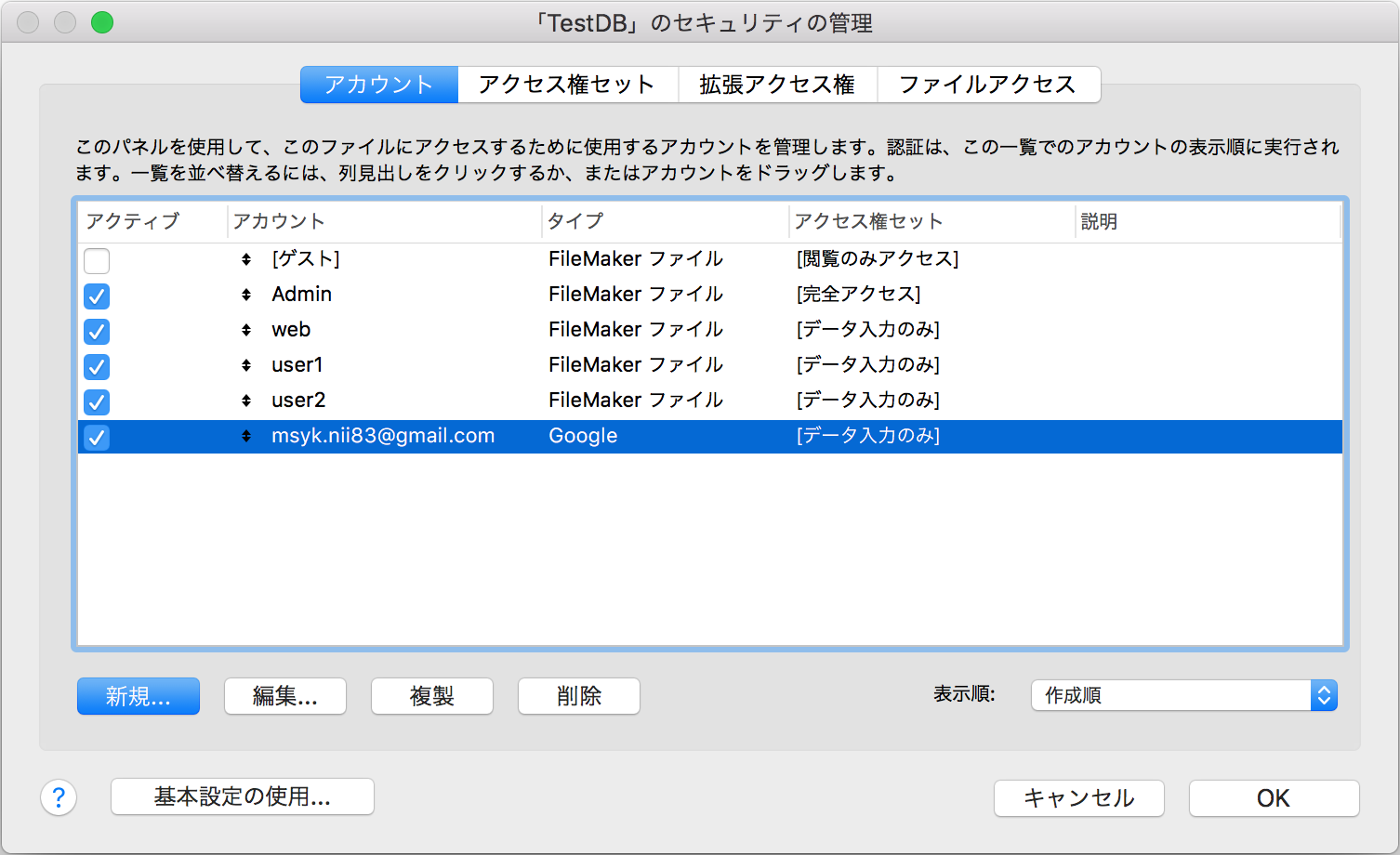
FileMaker Serverでの設定
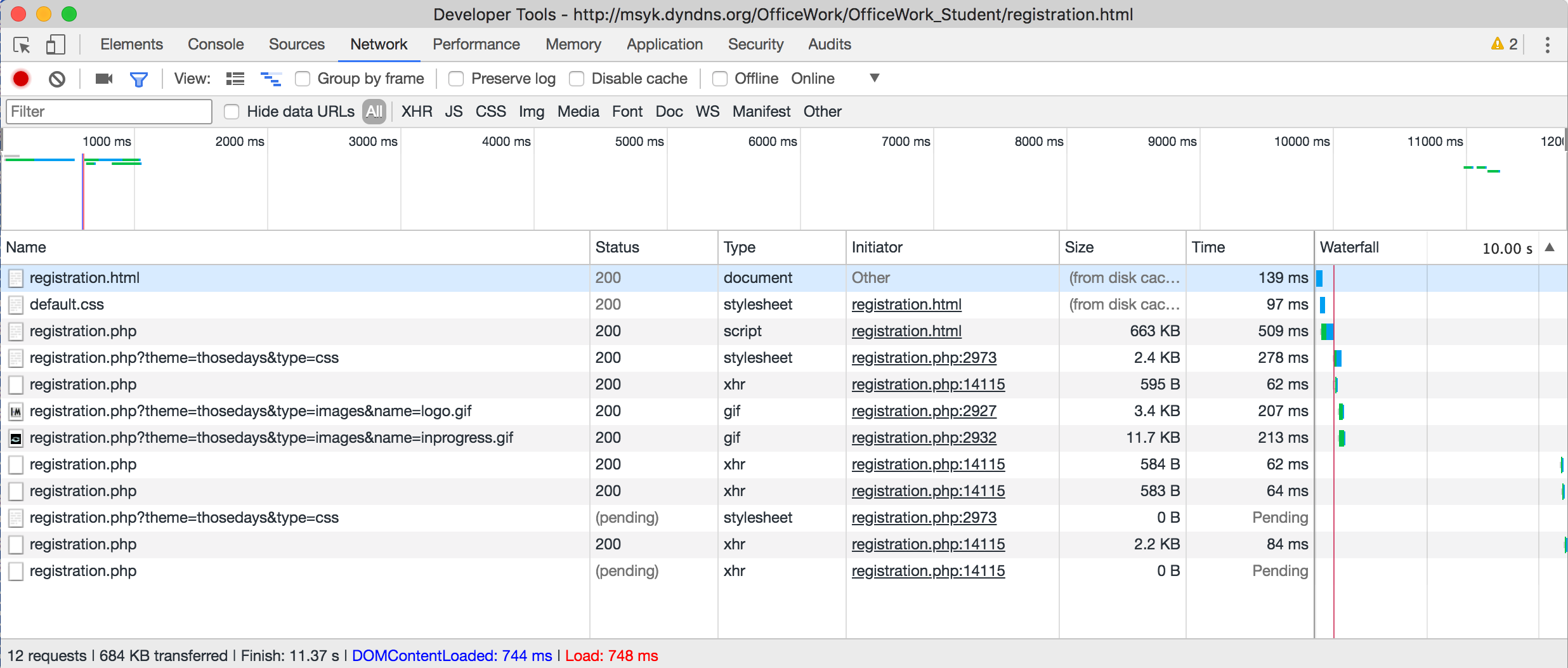
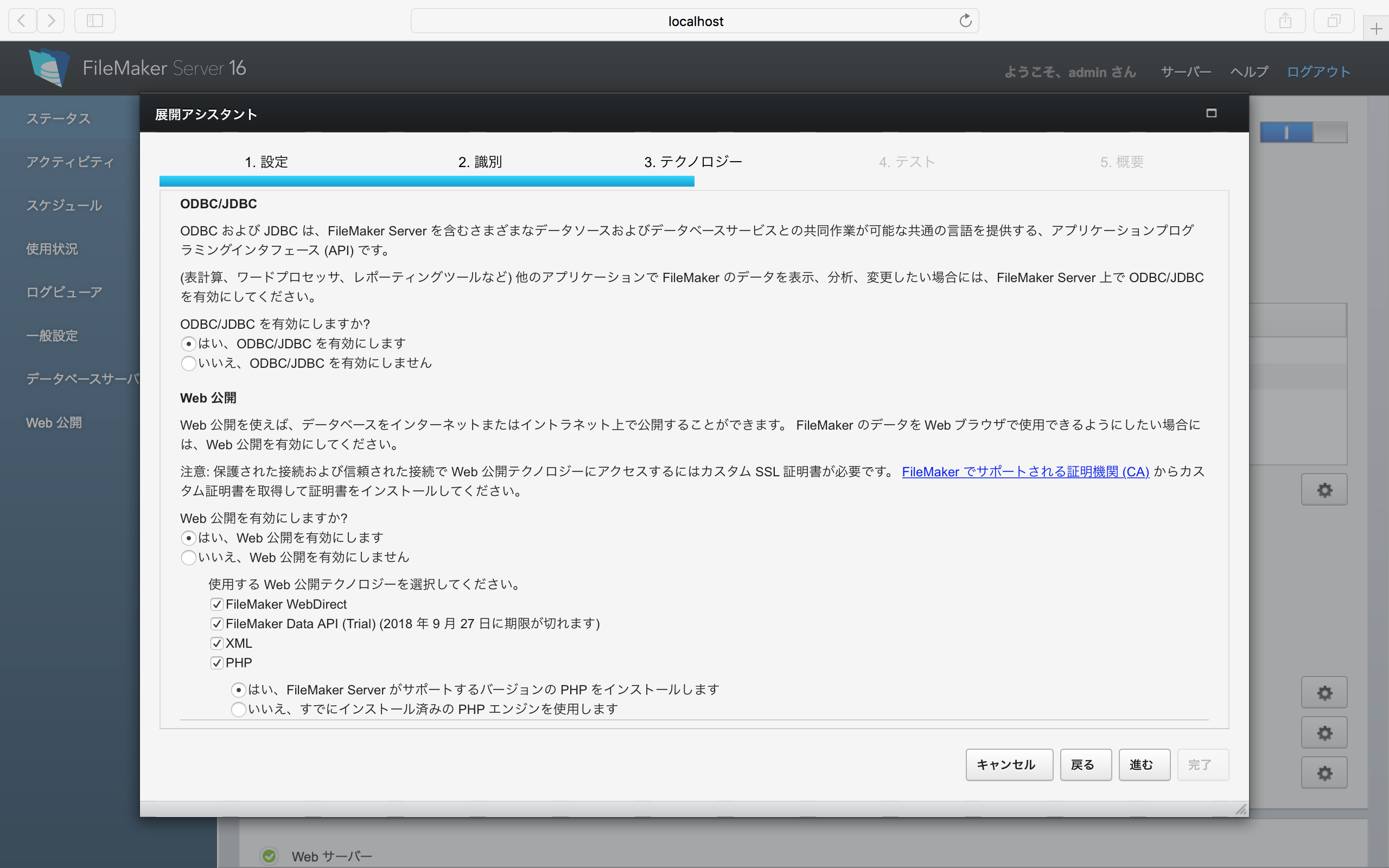
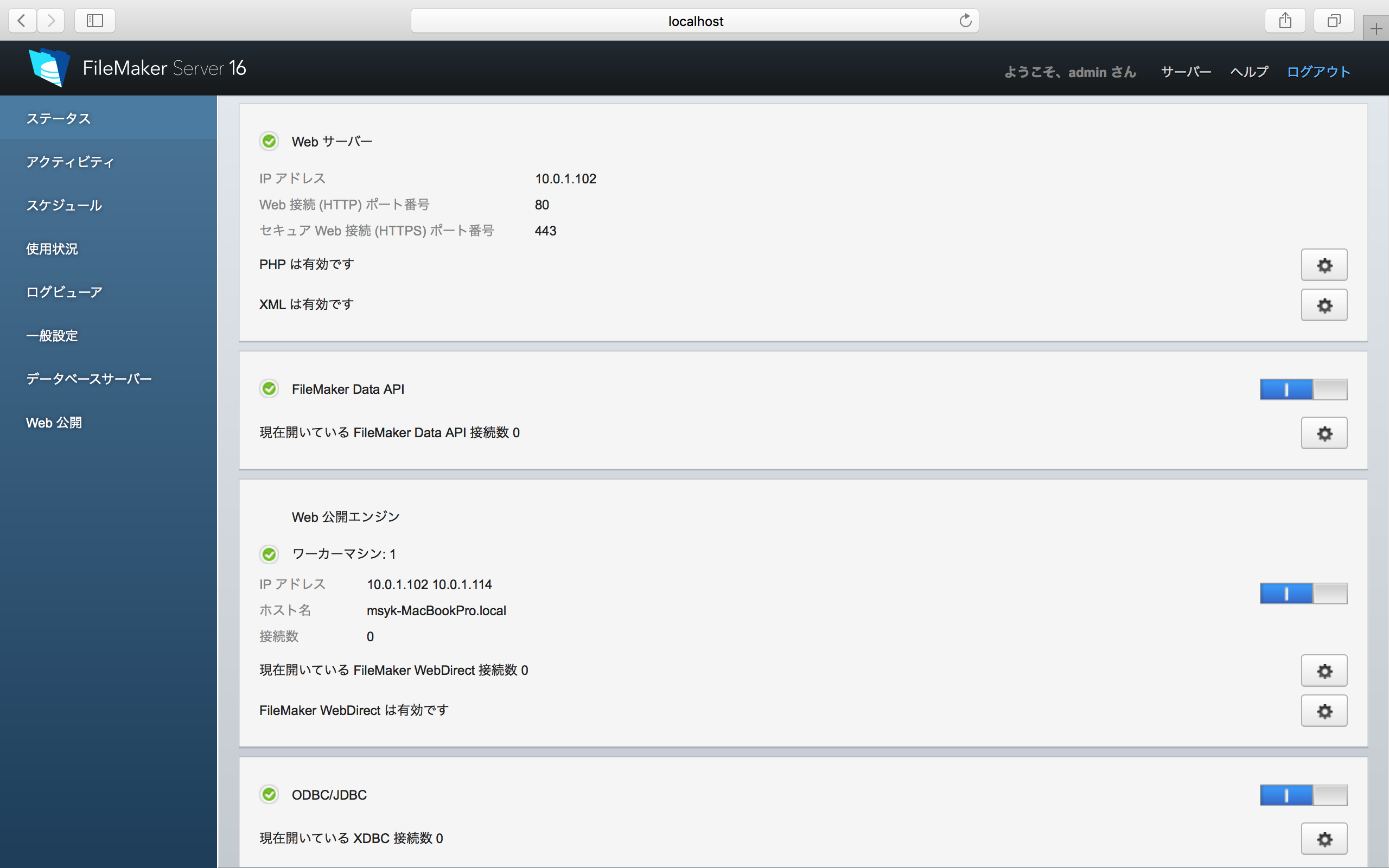
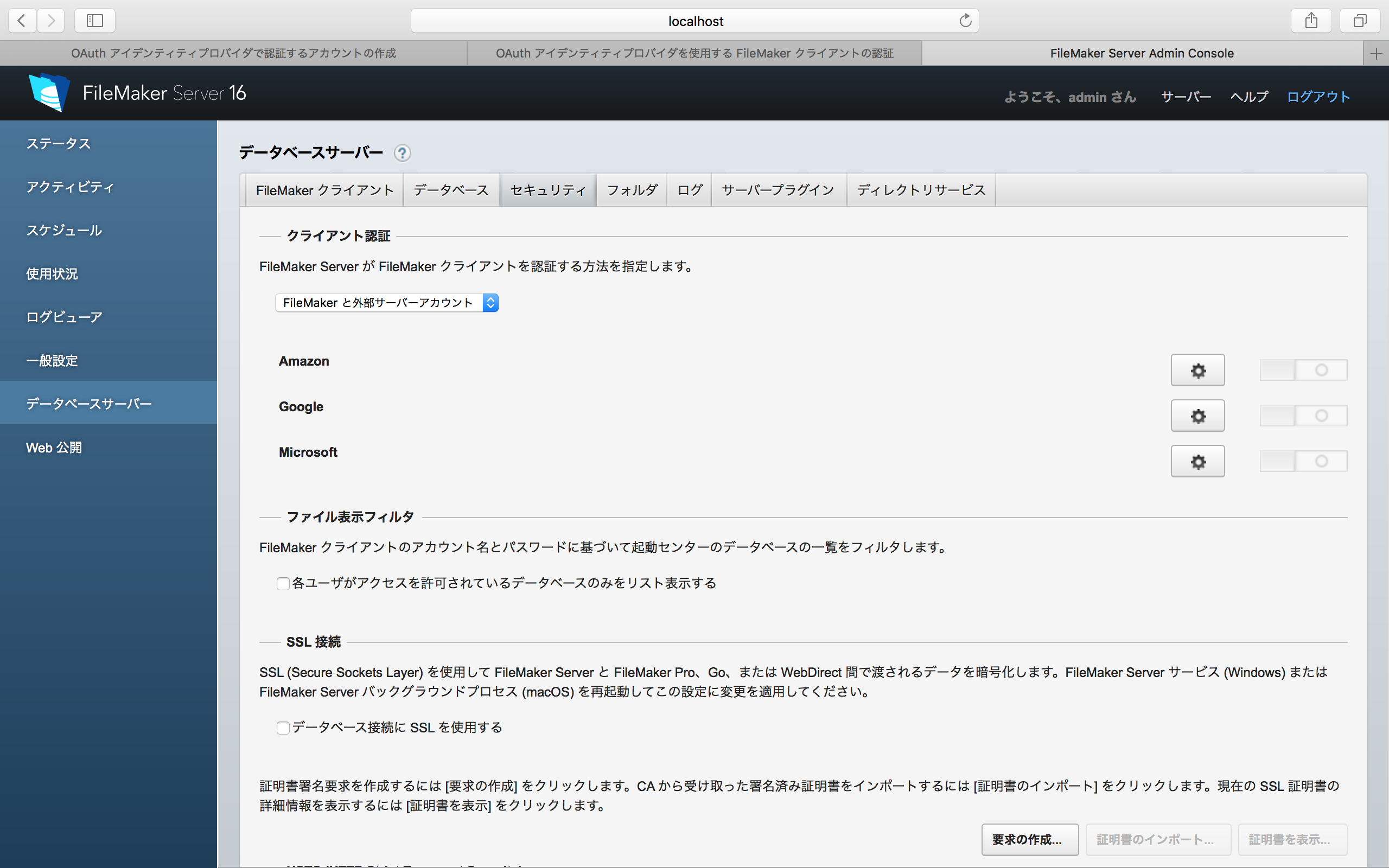
FileMakerのAdmin Consoleで作業をする。ログイン後、左側で「データベースサーバー」を選択し、右側で「セキュリティ」のタブを選択する。そこにあるポップアップメニューで「FileMakerと外部サーバーアカウント」を選択する。すると、Amazon、Google、Microsoftの3つの項目が表示されるので、右側のギアのアイコンをクリックして、作業を進める。ここでは、Googleを例にとって説明する。
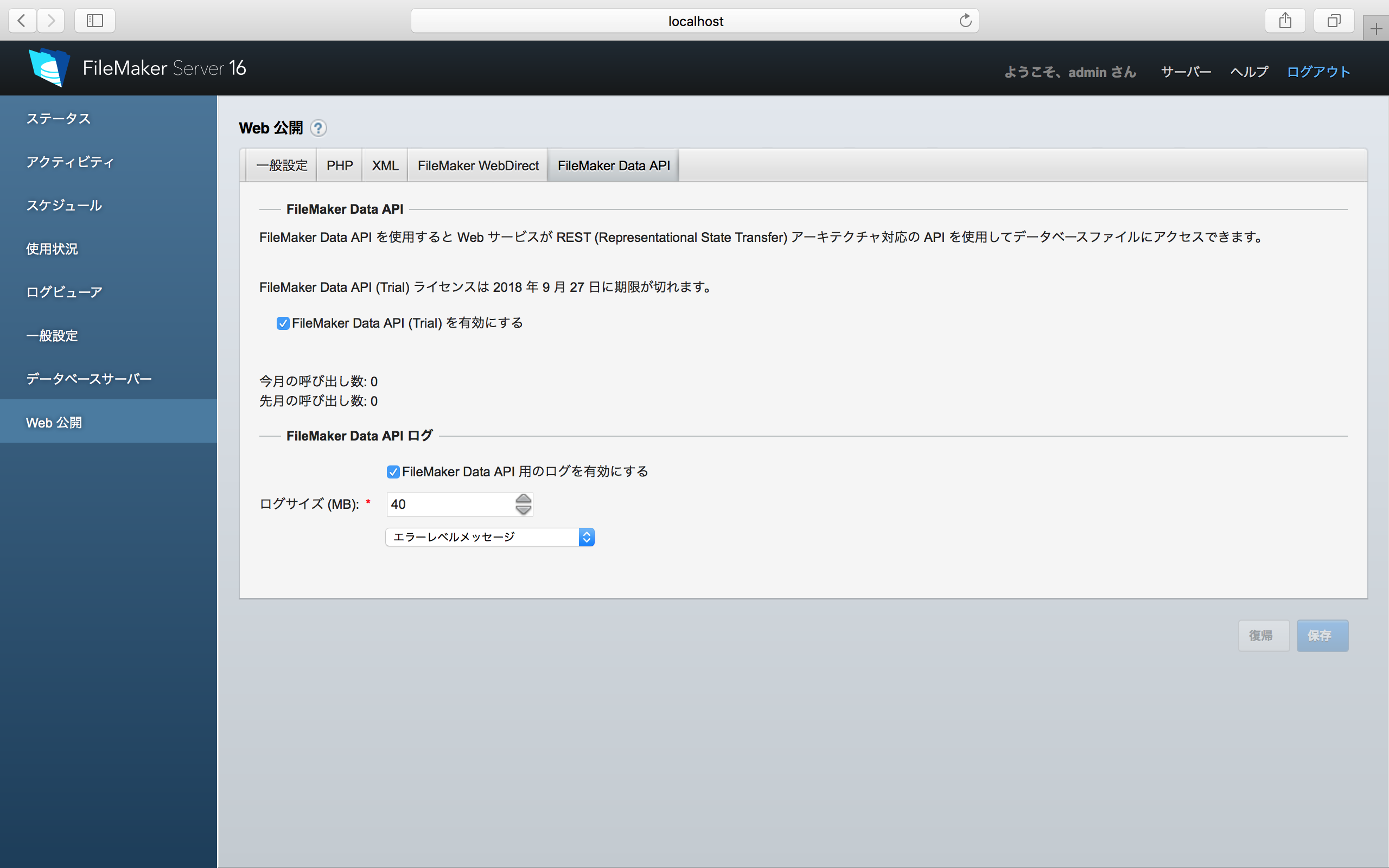
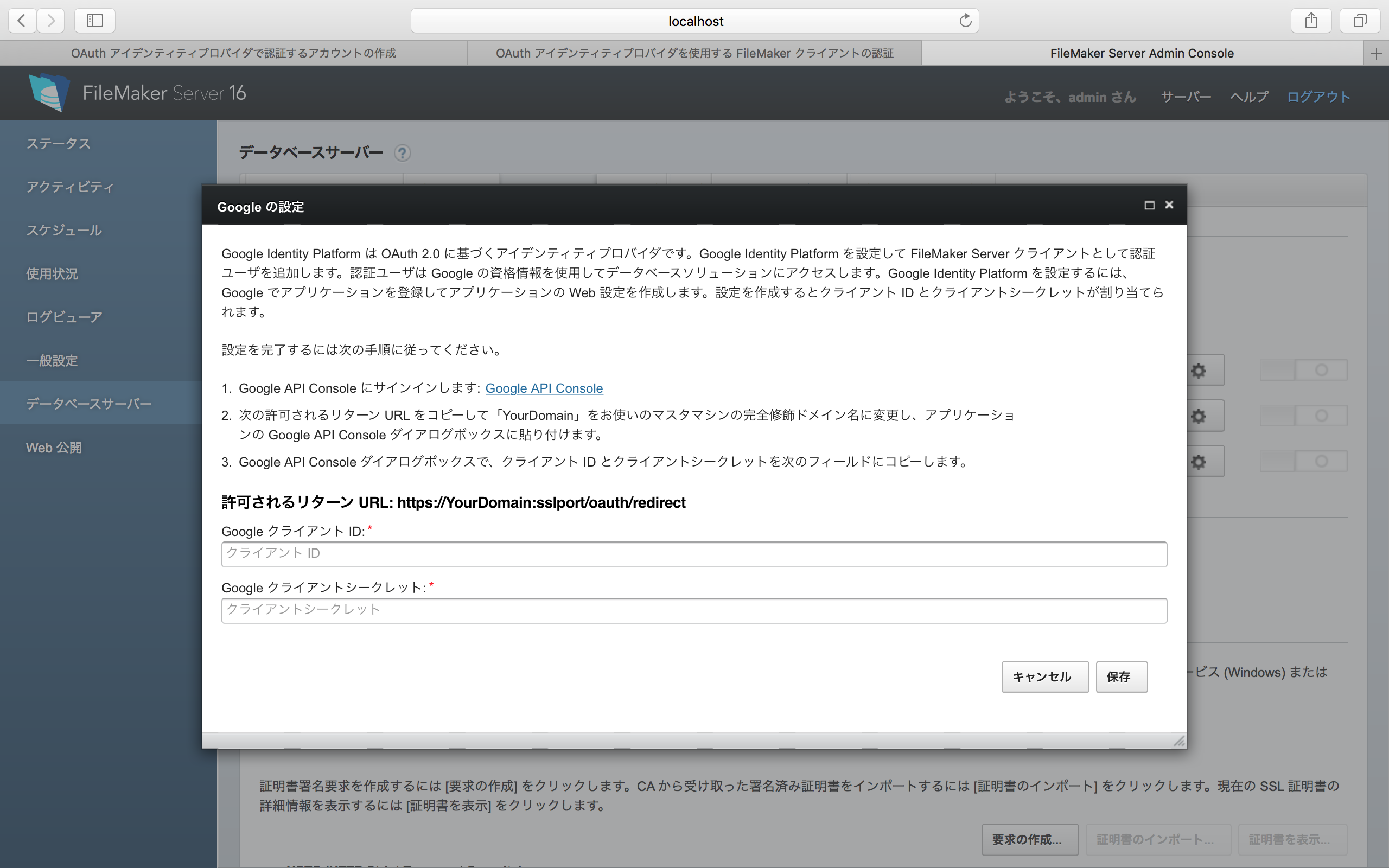
Googleのギアアイコンをクリックすると、次のようなパネルが表示される。結果的には、ここでGoogle側で得られた2つのコードを入力することになるが、それは、この後に説明する。簡単なようで難しい問題もあるので、それも併せてこの後に説明する。ともかく、2つのコードが得られたら、「保存」ボタンをクリックする。
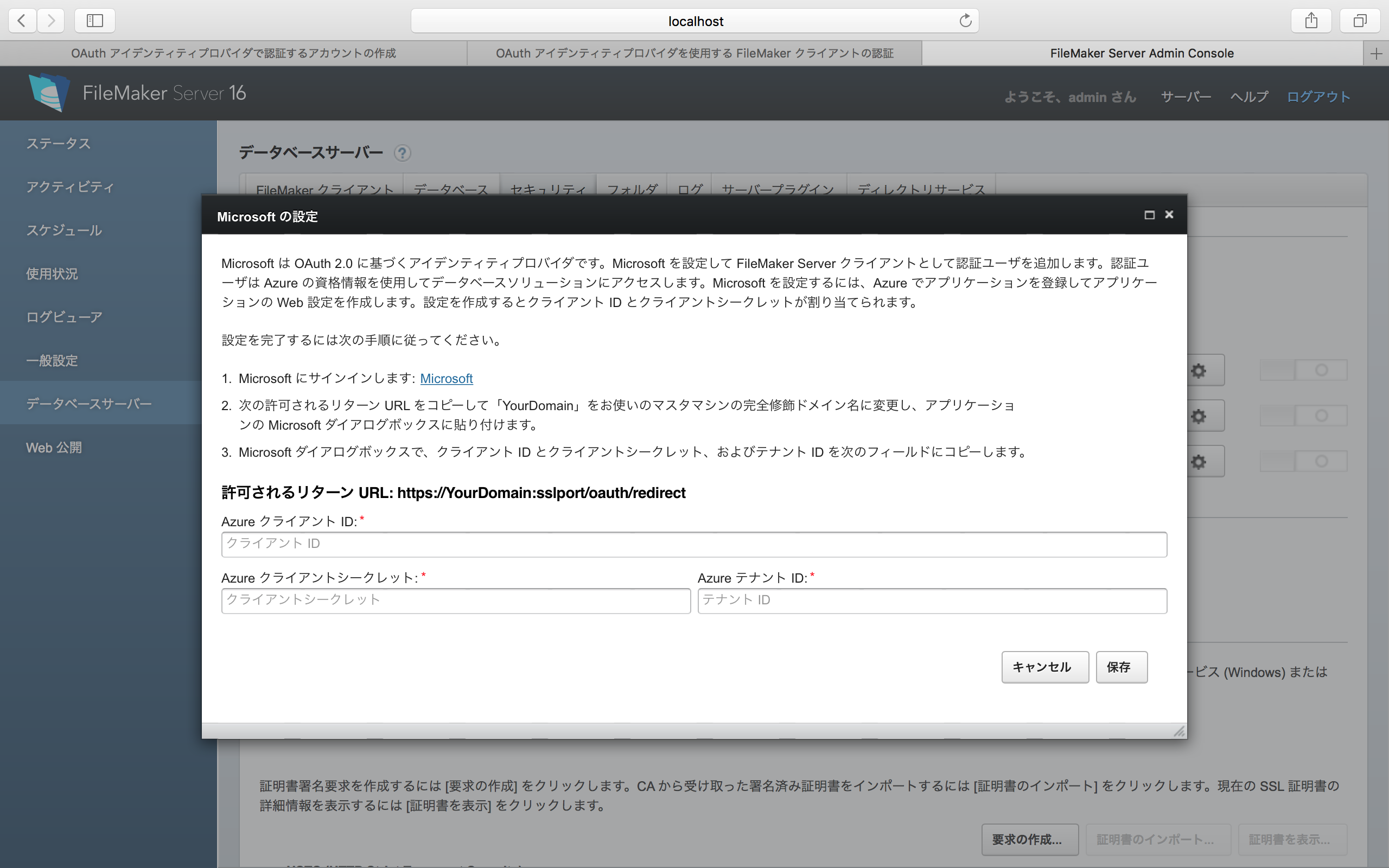
ちなみに、Microsoftを選択すると、少し違うダイアログボックスが表示される。これらはサービスごとに得られるデータが少しずつ違うと言うことだ。なお、これら3つ以外のサービスはプラグインとして追加は可能となっているが、基本的にはメジャーなサービスの場合はFileMaker社による機能追加を待つことになるだろう。自社でOAuthサーバーを立てているなら、プラグインの開発をしたくなるところだろうが、こちらはFileMaker社による情報待ちの状態だ。
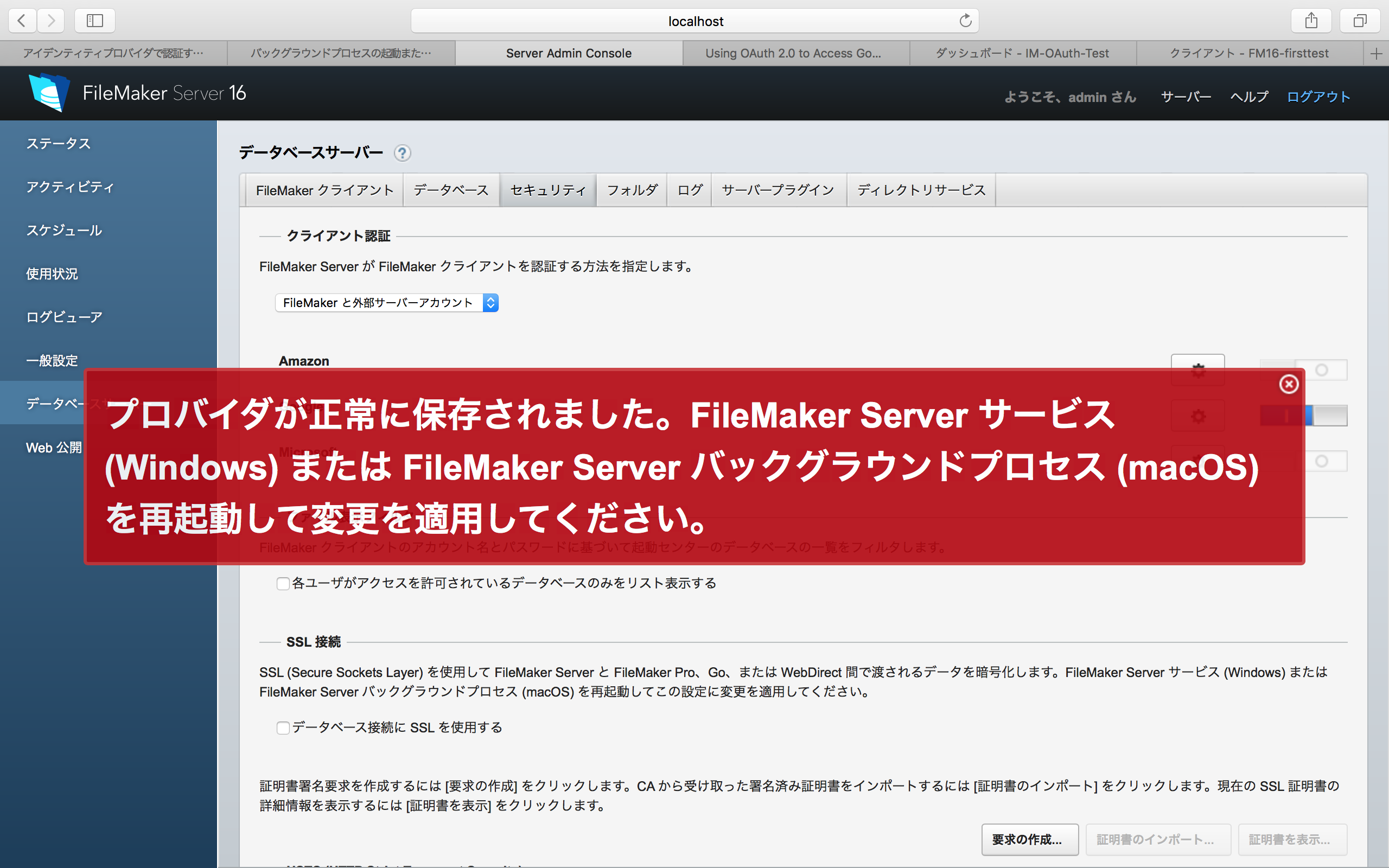
設定終了後、次のようなメッセージがでかでかと表示される。つまり、FileMaker Serverのサービスを再起動すると言うことだ。もちろん、コンピューター自体を再起動してもいいが、macOS、Windowsでの作業方法が、こちらのページに記載されている。
Googleのコードの取得
Admin Consoleで設定をするには、Google側から与えられるコードを取得しなければならない。そのコードは、Google APIのところで取得を行う。以下の手順で「利用規約の更新」が出てくる場合には、もちろん、そこで対応をして進める。
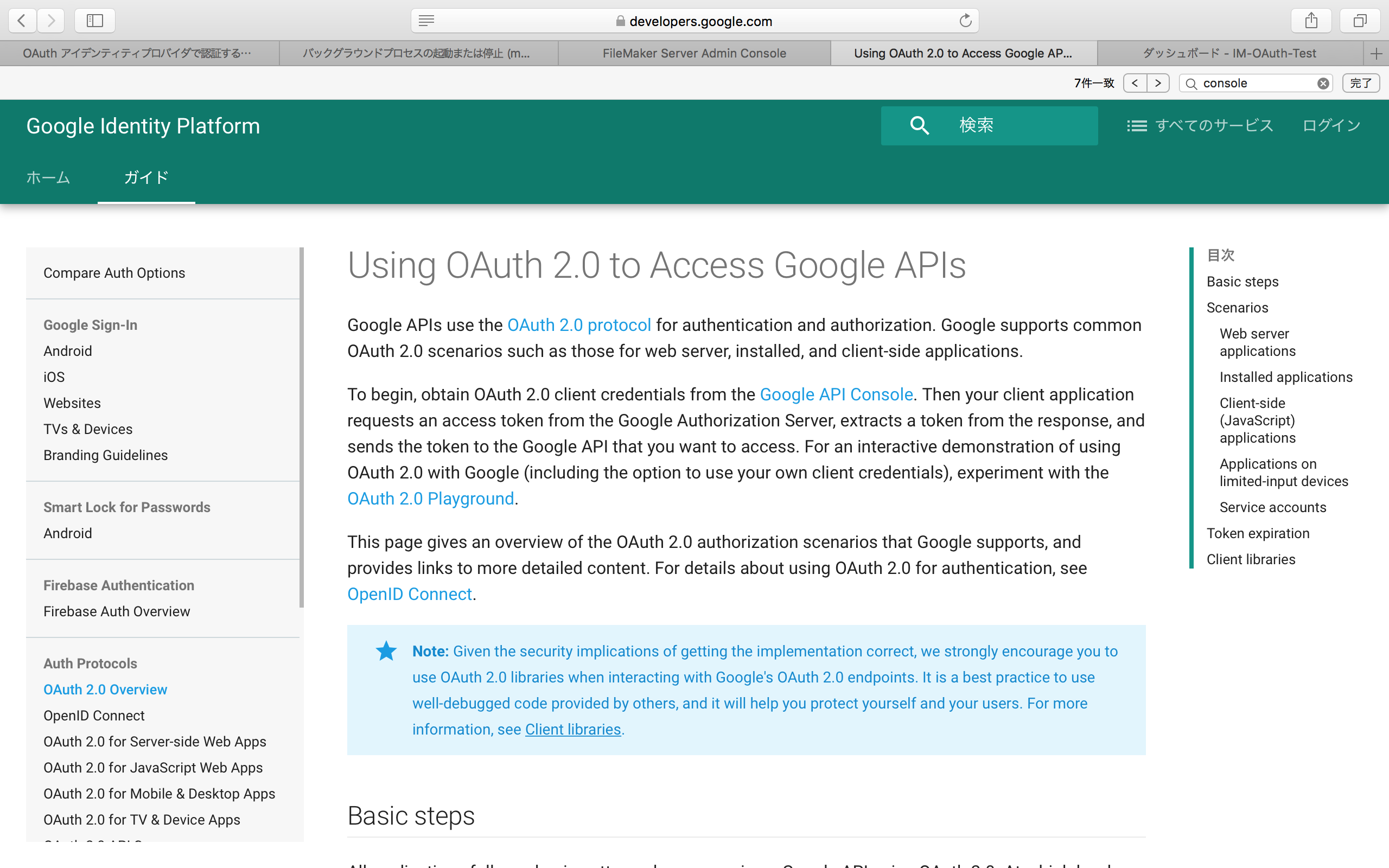
Googleの場合、Admin Consoleの「データベース」のセキュリティ設定のところで出てきた「Google API Console」をクリックすると、以下のような英語のOAuth 2.0のページが出てくる。実際作業は、このページの本文の2パラグラフ目にある「Google API Console」をクリックして進める。
Google API Consoleをクリックすると、以下のページに移動する。こちらを直接開くには、Google Developer Consoleのページにジャンプすれば良い。なお、このページ内容は、それまでにこの機能を使ったかどうかによって大きく違っている。全く初めて使う場合の作業手順も併せて説明しよう。ポイントは、上部に「Google APIs」というバーが出ている点である。
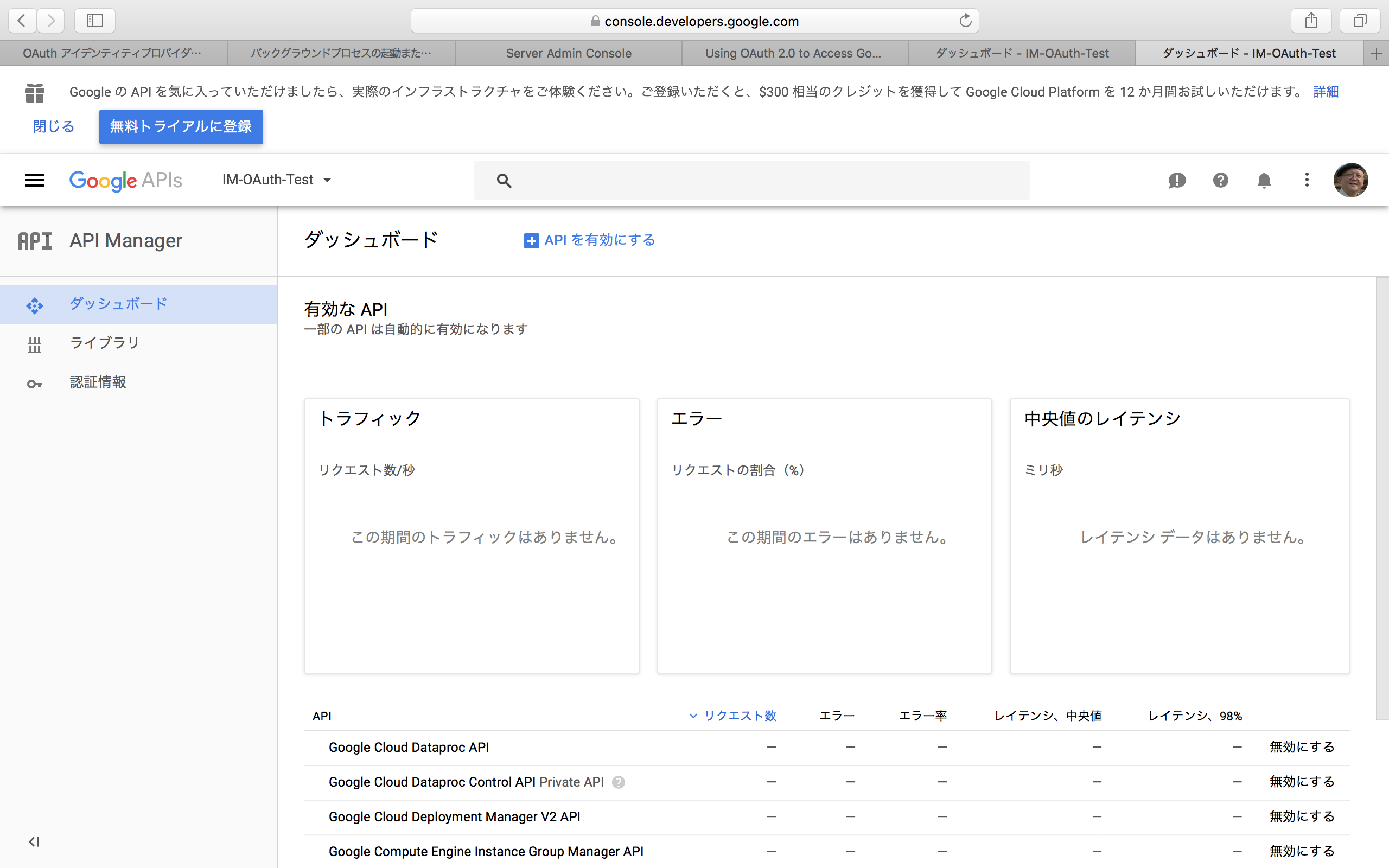
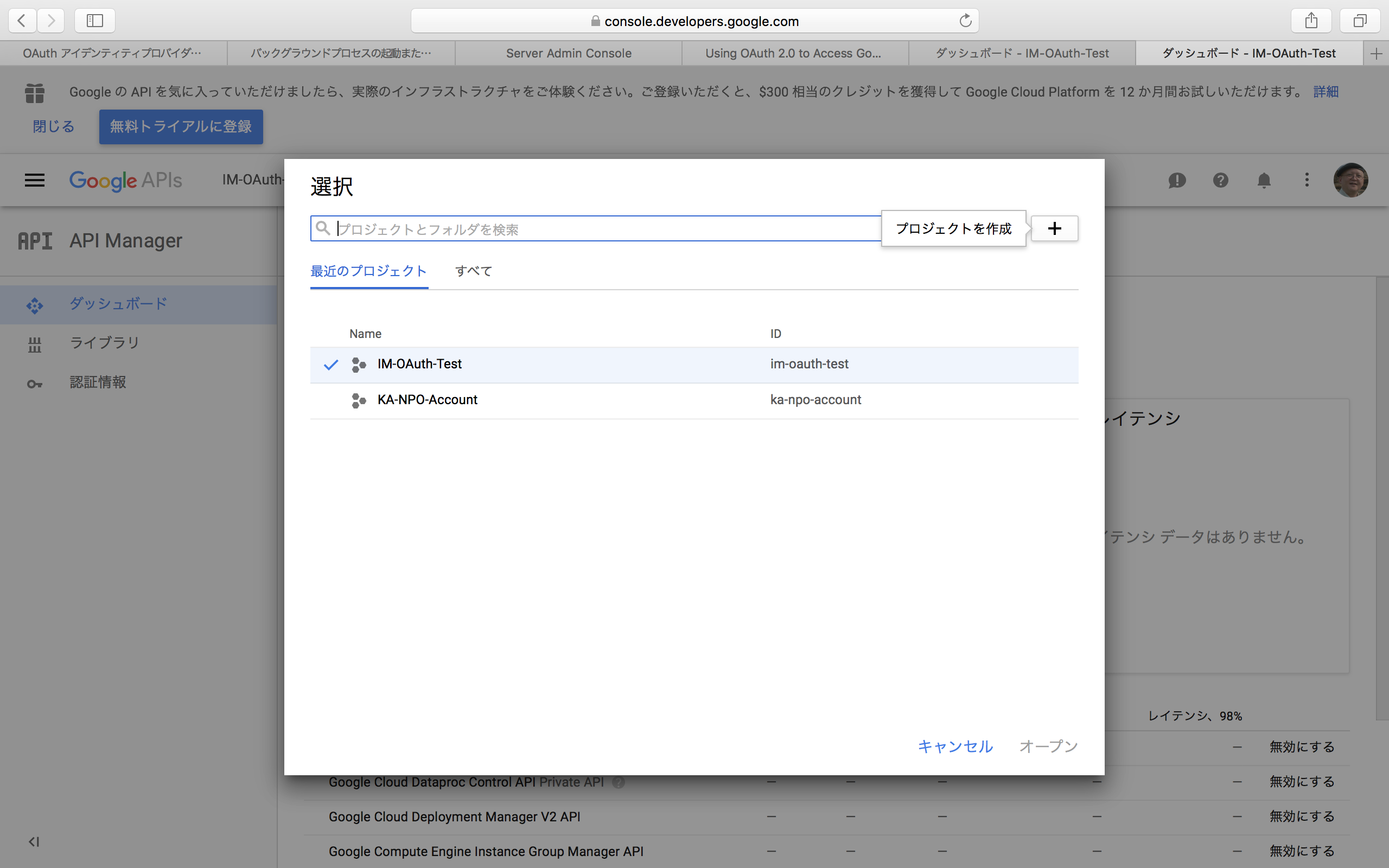
Google APIsと書かれた右側の部分では、初めて使う場合には「プロジェクトを選択」と表示されるので、それをクリックする。すでに何かで利用してプロジェクトが存在する場合には、とにかくプロジェクト名が見えているのでそれをクリックする。すると、以下のように、プロジェクトの一覧パネルが表示される。パネル右上の「+」をクリックすると、プロジェクトが新たに作成される。ここで、FileMaker Server向けにプロジェクトを1つ作っておく。
プロジェクトの作成時に必要なことは、プロジェクトの名前を設定することである。名前は適当に設定する。なお、プロジェクトIDはこの後は特には使用しない。
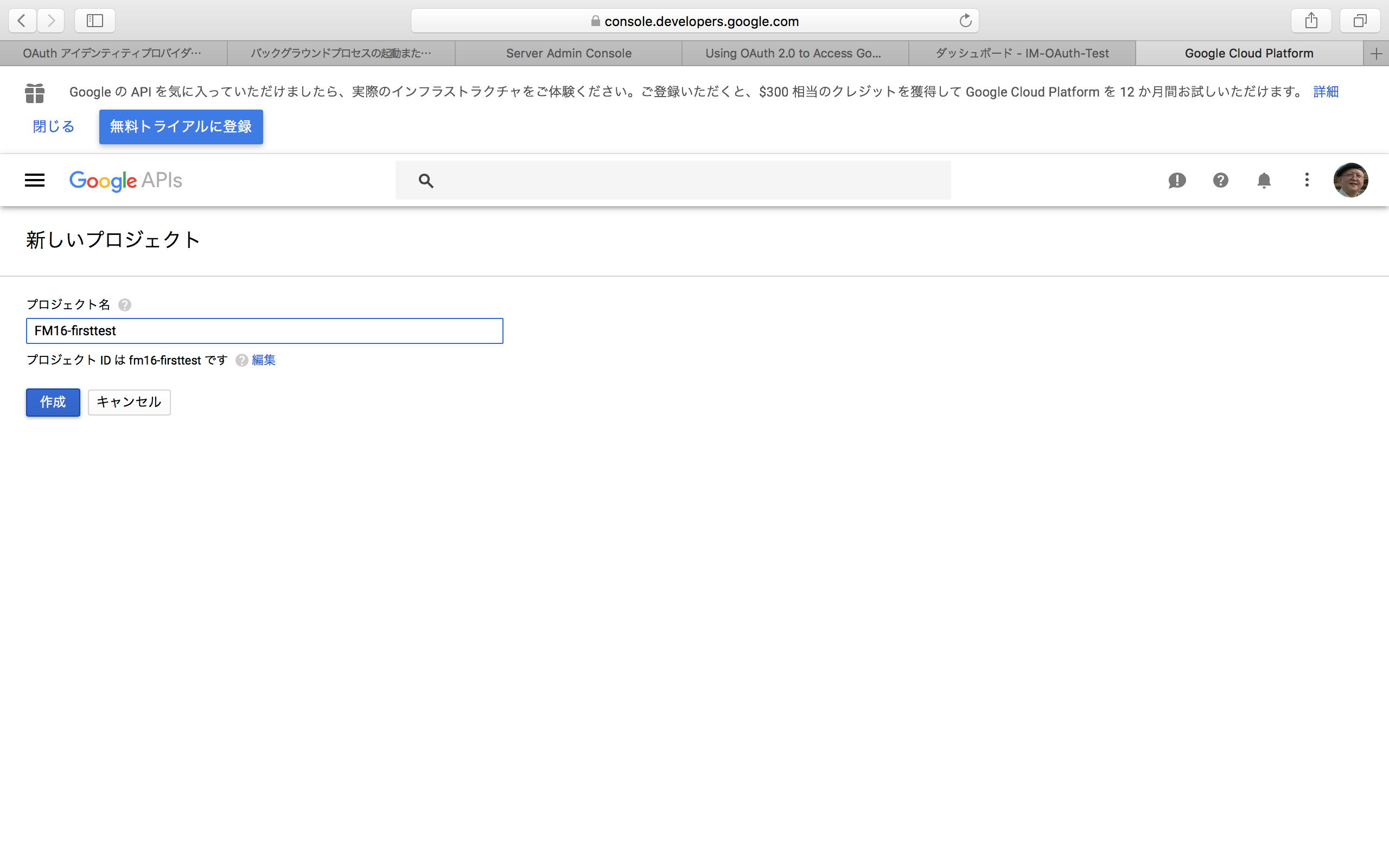
プロジェクトを作成すると、そのプロジェクト名がGoogle APIsの右に見えていることを確認して、左側で「認証情報」を選択する。すると、「認証情報を作成」というボタンが見える。ここで、ボタンをクリックして「OAuthクライアントID」という項目を選択する。
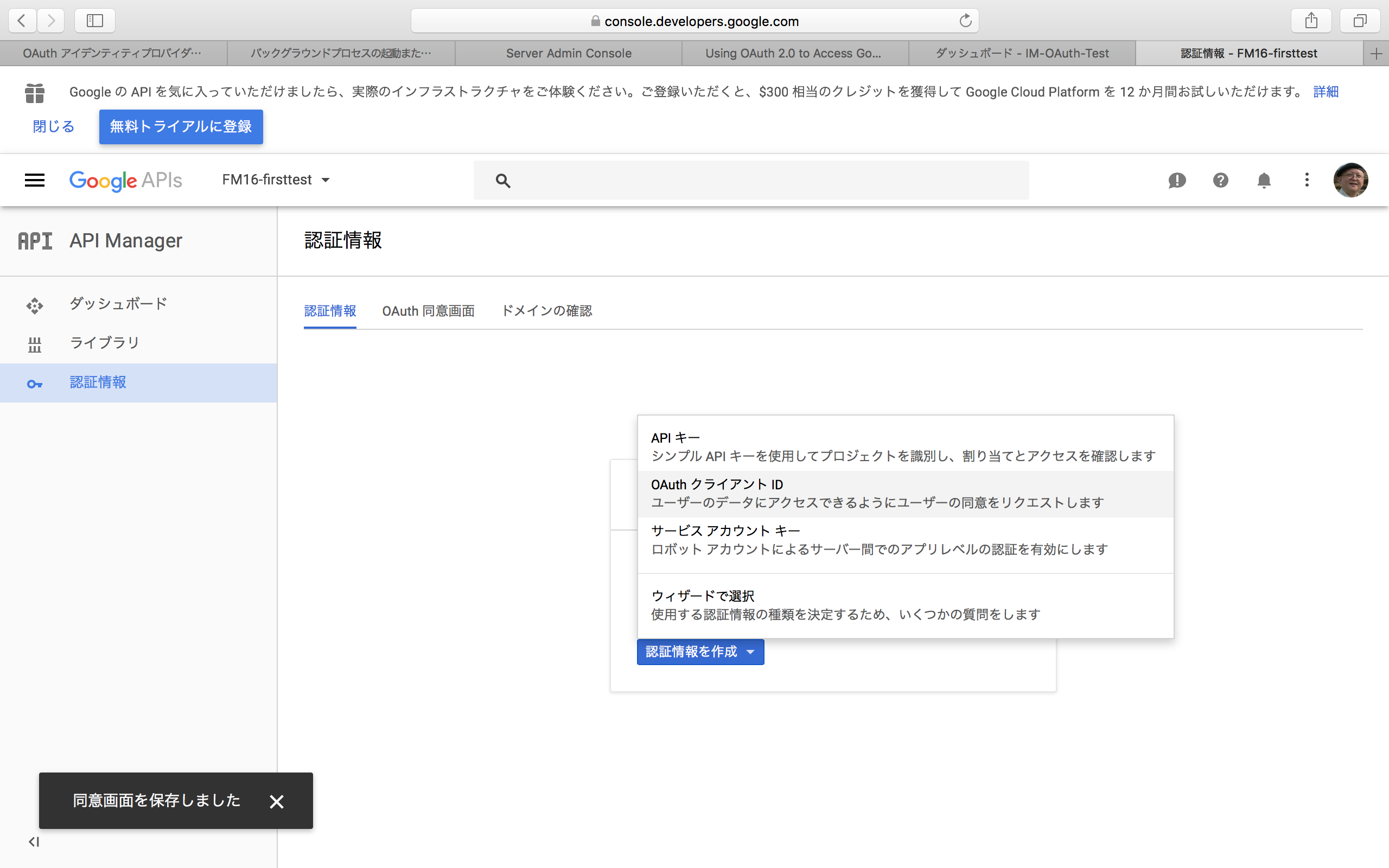
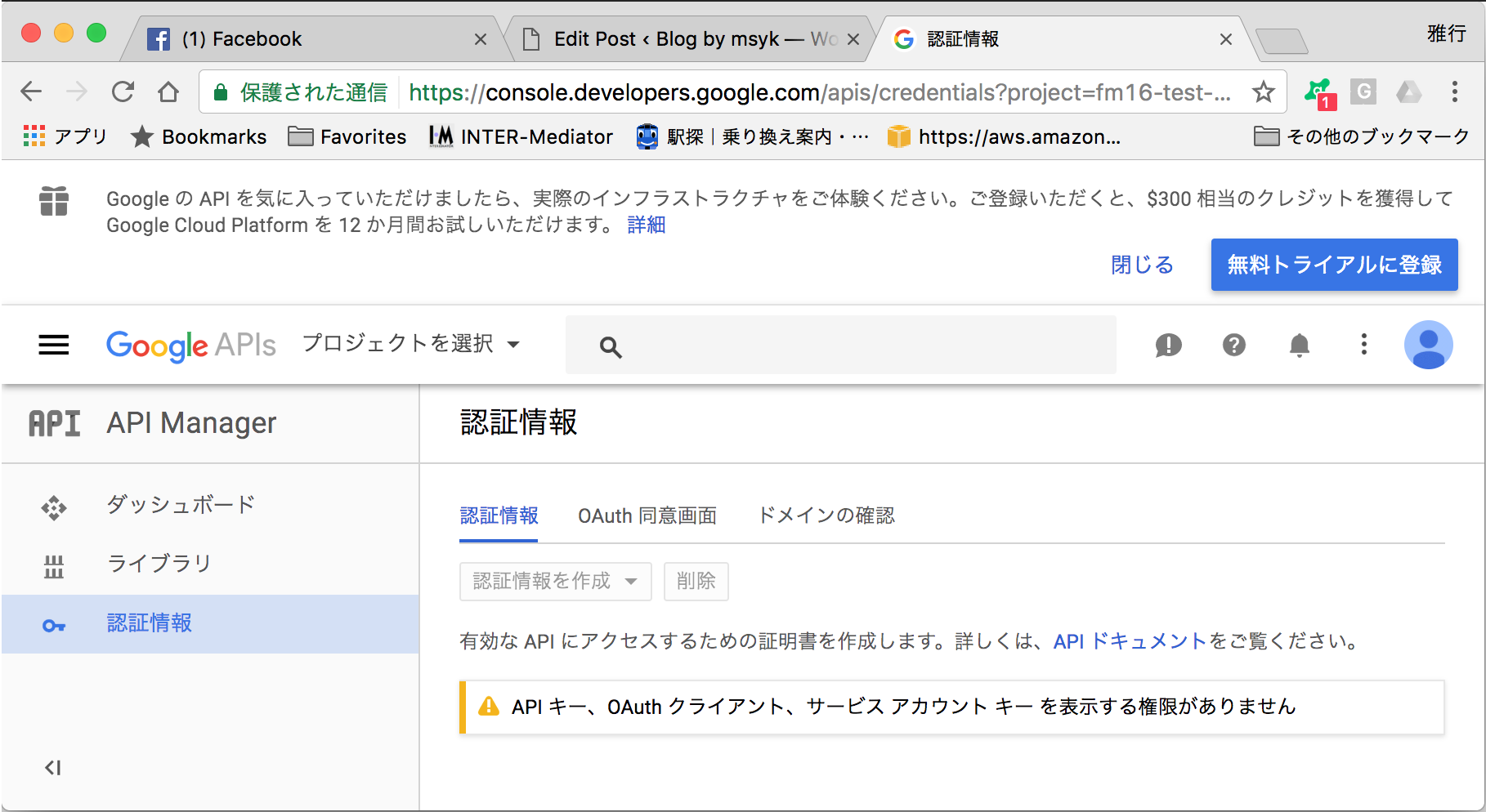
なお、ここで以下のようにメッセージが見えているGoogleアカウントでは、必要なコードを生成する権限が与えられていない。例えば、組織で作成されたアカウントではコード生成が許可されていない場合があるので、その場合は個人でアカウントをするなどして、コード発行を行う必要がある。組織のアカウントの場合は、その組織の管理者が、クライアントIDの発行を制限していることが一般的な原因だろう。
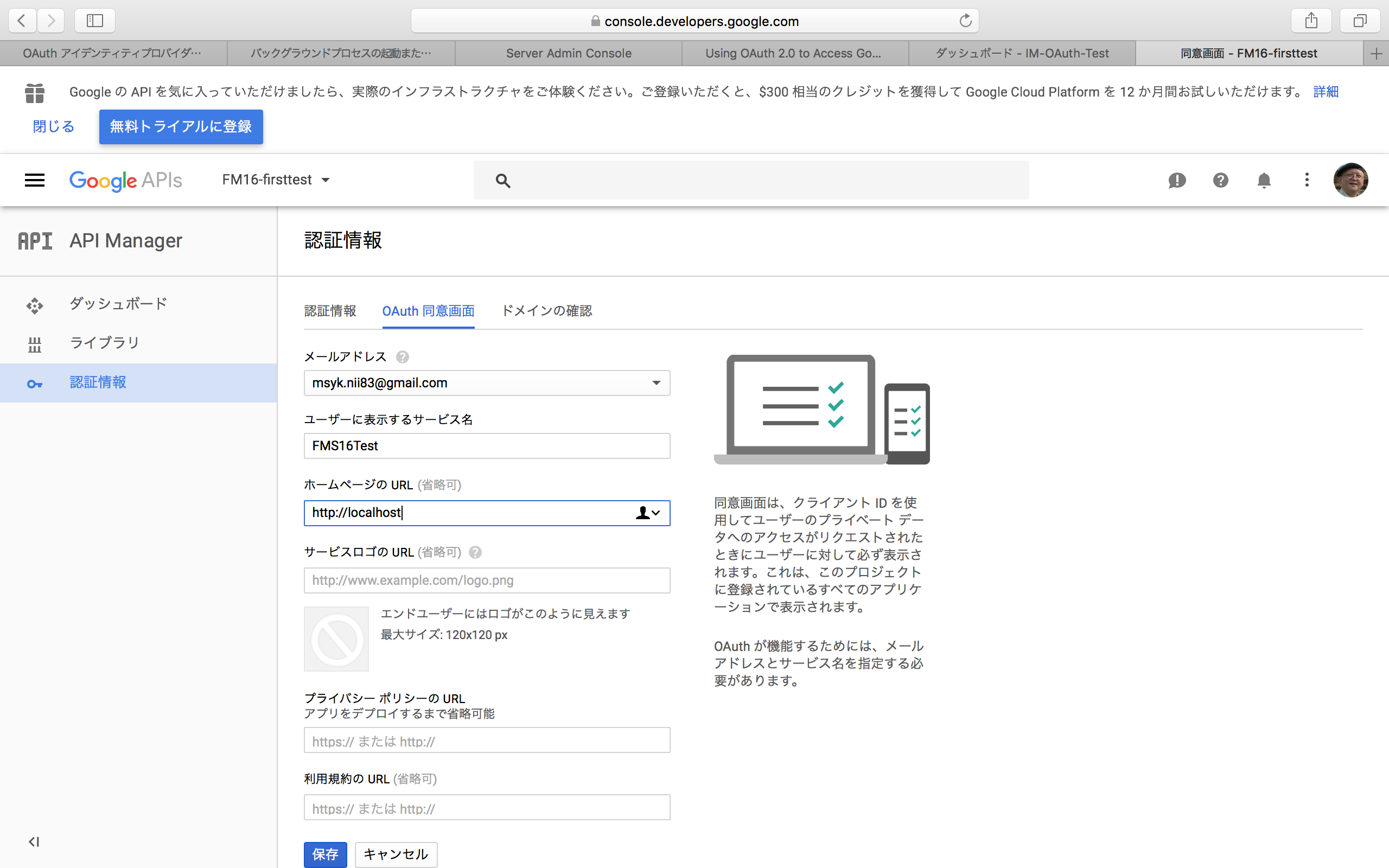
「OAuthクライアントID」を選択した後、同意画面の作成を促す表示が出てくれば、それに従って以下のページで必要な情報を入力する。本来はこの「同意画面」がユーザーに示されて、そしてサービスを利用できるようにするという流れをOAuthでは採用している。しかしながら、FileMakerではこの同意画面を利用していないようで、「ユーザーに表示するサービス名」だけを設定して「保存」ボタンで保存すれば良い。
その後にアプリケーションの種類を選択するページが表示される。ここでは、「ウェブアプリケーション」を選択する。すると、名前などを入力する項目が表示される。ここで、名前は適当に設定するとして、もう1つは「承認済みのリダイレクトURI」を入力しなければならない。このURLは、例えば、FileMaker Serverに接続するためのホスト名が「fmstest.msyk.net」ならば、「https://fmstest.msyk.net/oauth/redirect」を指定する。ホスト名の部分だけがサーバーによって違い、他の部分はどのサーバーでも同様だ。なお、:443はあってもなくても良い。ちなみに、ここにmacOSの共有名(Macintosh.local)や、IPアドレスではうまく動作しない。ドメインを含む利用可能なホスト名をきちんと設定し、そのホスト名でサーバーに接続できる環境になっていなければならない。
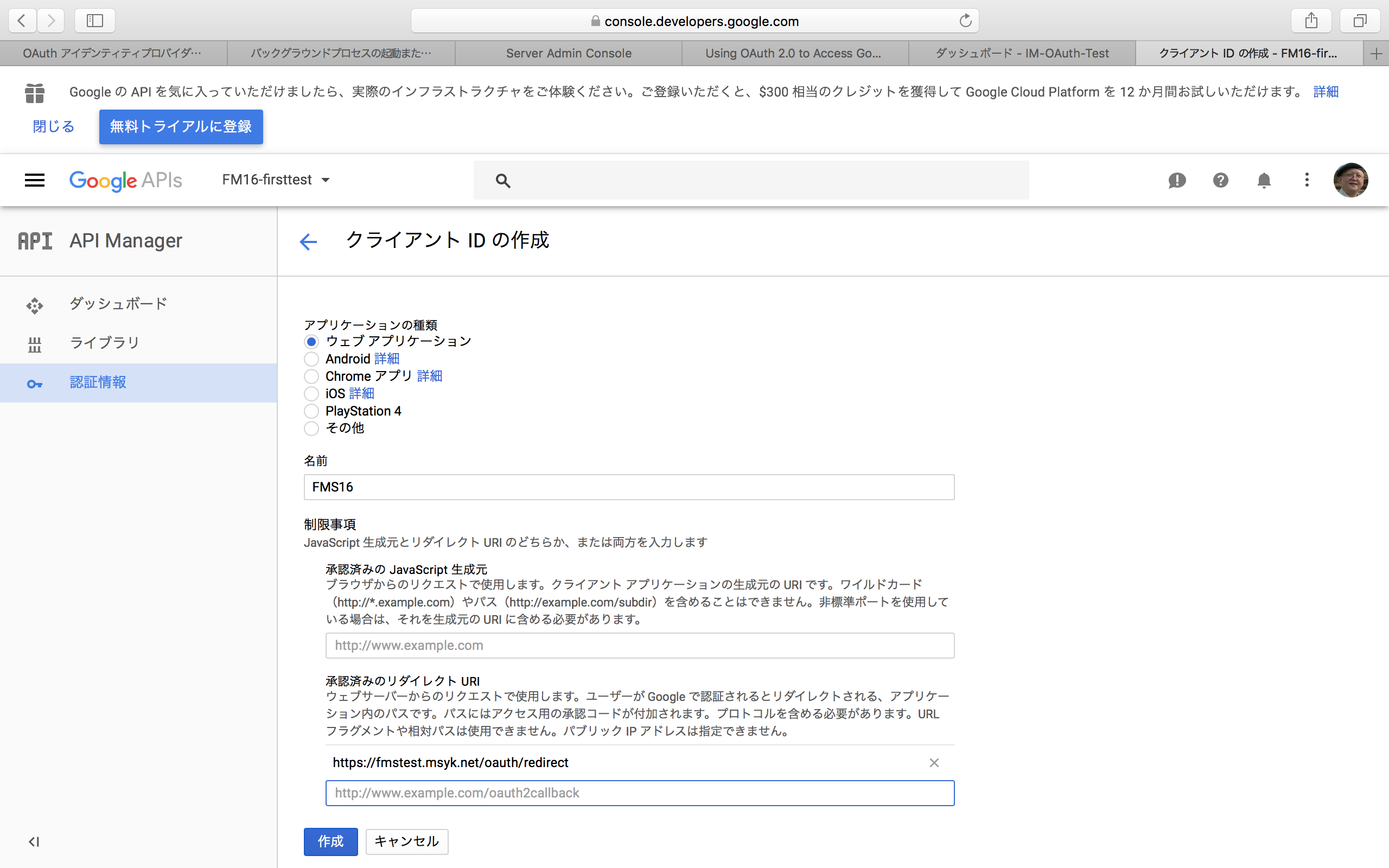
「作成」ボタンをクリックすると、生成されたコードがパネルに表示される。こちらからコピーして、Admin Consoleの該当するフィールドにペーストすれば良い。なお、コードは後からでも参照は可能である。
うまくいかない場合の対処
手順は以上の通りだが、FileMakerのドキュメントにも書いてある通り、FileMaker Serverを、きちんとしたドメイン名のURLのホストで公開する必要がある。macOSの共有名の場合、ブラウザからのアクセスが正しくできない場合もある。IPアドレスだけではhttpsでアクセスしているはずはないので、Googleの側で登録が進まない。自分でドメインを持っている方は、何らかのテスト項目を作るなどしてともかくドメイン名を含むホスト名を用意する。
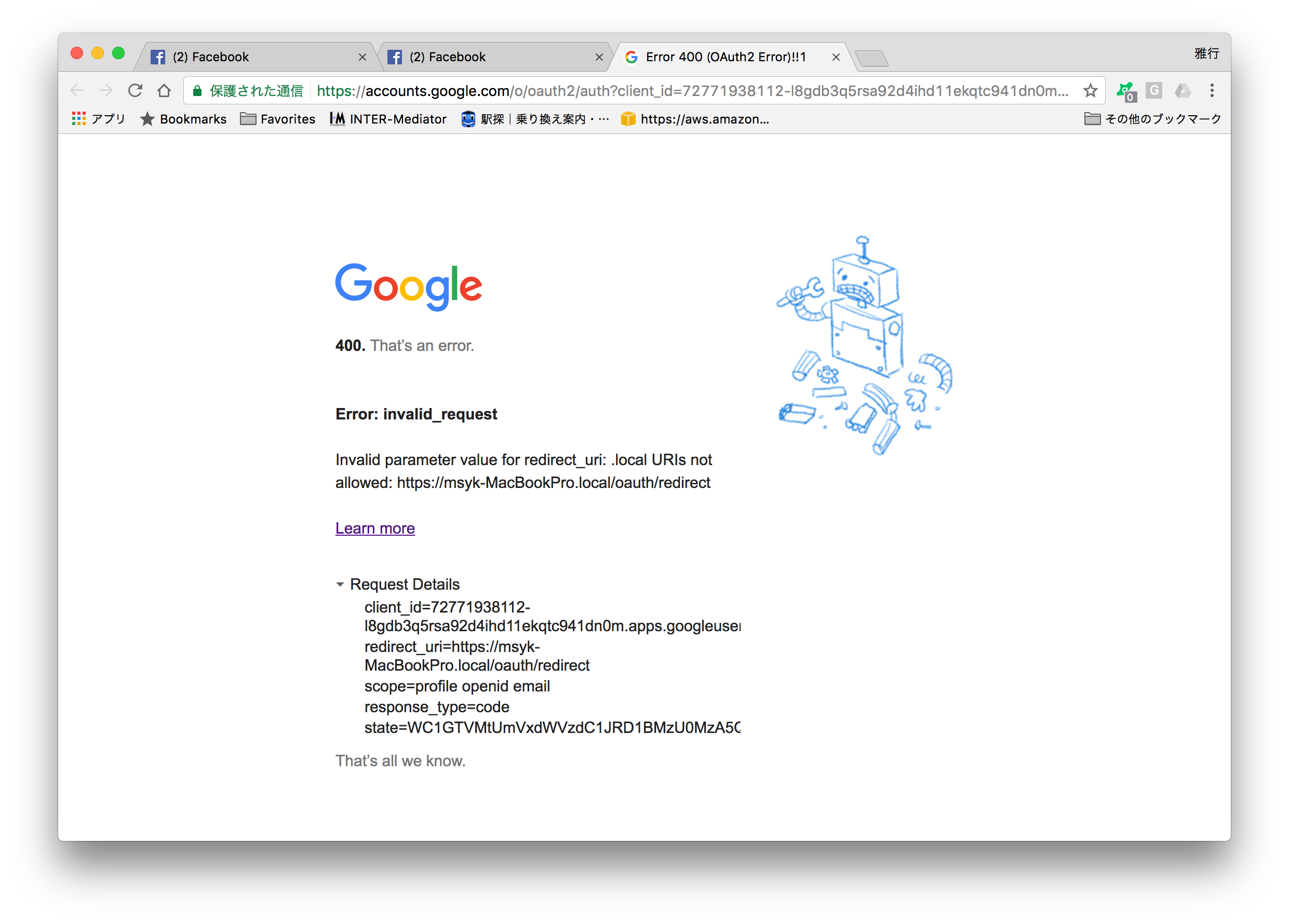
例えば、サインインのダイアログボックスで、Googleボタンをクリックした場合に次のようなページが出たとする。ここで詳細を表示すると、redirect_uriに見えるように、https://MacBookPro.localというホストにアクセスしようとしている。もちろん、この名前は共有名である。ブラウザでは共有名でもOKのはずなのにと思うかもしれないが、単にそのURLにブラウザからアクセスするのではなく、裏ではもっと色々複雑なことを行なっている。筆者の場合には、msyk.netというドメインを所有しているので、fmstest.msyk.netが利用できるようして、検証を行なった。IPアドレスは、実は10.0.1.102というプライベートアドレスだが、自宅環境ではそれで運用可能なので問題はない。
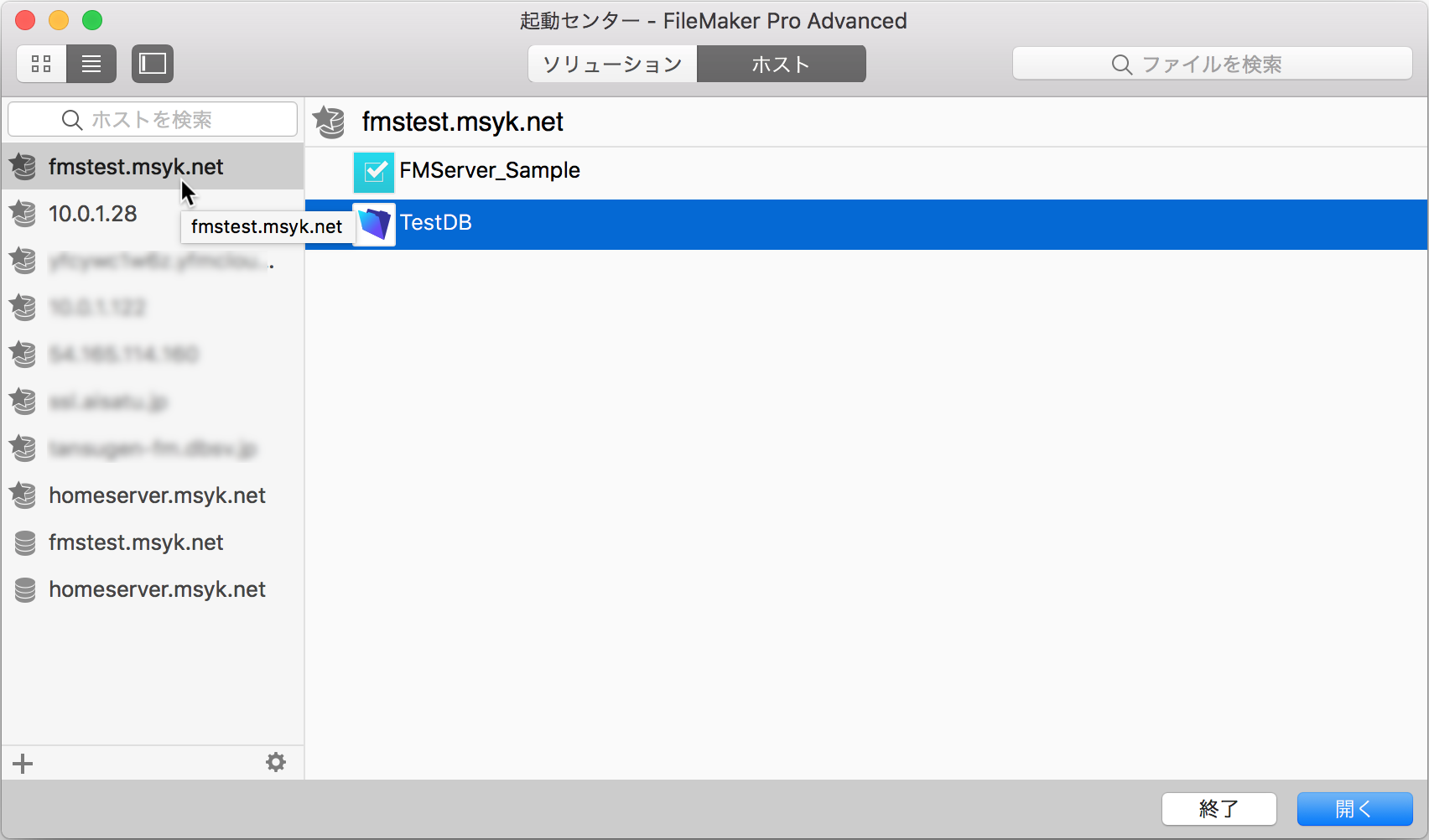
ここで、上記のrequest_uriのURIがどのように自動生成されるのか分からず、対処がなかなかできなかった。実際には、FileMaker Pro/Advancedがrequest_uriを「サーバーへ接続した時に使うホスト名」から生成しているようだ。macOSの場合、自動的にBonjour名が左側に出てきてアクセスをしがちであるが、それだと、上記のrequest_uriには共有名が含まれてしまう。サーバーのドメイン名(つまりFQDN)で接続するサーバーを選択できるように、例えば、お気に入りのホストにドメイン名を登録して、そこからデータベースを選択して開くようにすれば良い。以下の図のように、fmstest.msyk.netでデータベース選択ができるように、お気に入りのホストの登録を行なった。もちろん、自動的に識別される名前がホスト名であれば、それを選択すればOKである。
OAuth対応をどう考えるか
以上のように、Google側の使いこなしが必要になるものの、OAuth対応は確かに便利だろう。アカウントそのものの管理を外部に任せることができるのである。ただし、社員全員がGoogle Appsなどでアカウントを持っていれば便利は便利なのだが、データベース個別にそれぞれのアカウントを登録しなければならない。これは、テキストファイルで読み込みはできないため、自動化のスクリプトなどを使用することになると思われる。ともかく、Googleにアカウントを作ればデータベース側を変更しなくても新しいアカウントから使えるようになる…と言う状況は作れない。機能としては素晴らしいが、運用を考えた時に、手間になる部分も見えてくる。ログインしたアカウントのドメイン名がある名前であれば、自動的に登録されて定義されたアクセス権セットを利用するような仕組みがあることで、管理負荷を軽減できると考えられる。
FileMaker Data APIもOAuth対応している。その意味ではWeb対応しているのだが、WebDirect経由ではOAuth対応はなされていない。これは先のバージョンを待つしかないだろう。WebDirectについては当初は対応していないと記載していたが、GOからのアクセスも含めて対応はしている。エミックの松尾さんに指摘をいただいたが、恐らく正しい証明書であればHTTPSであればOAuth認証ができ、自己署名の証明書であればできないということではないかと思われる。なお、http://…だと、Googleで登録ができなかった。この件、簡単に検証ができないのではあるが、手元で検証した時の違いとなると署名書の違いしか考えられない。