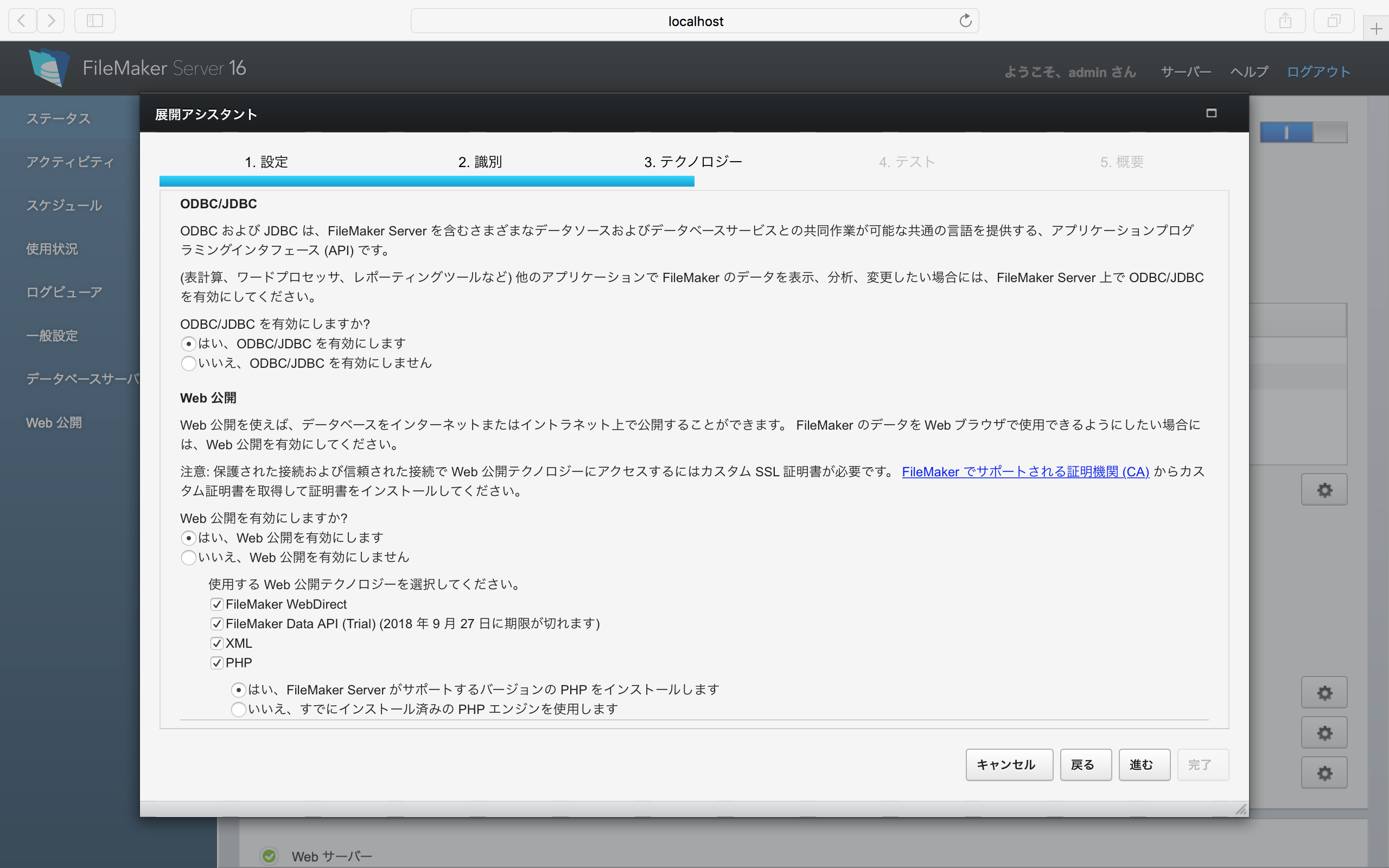
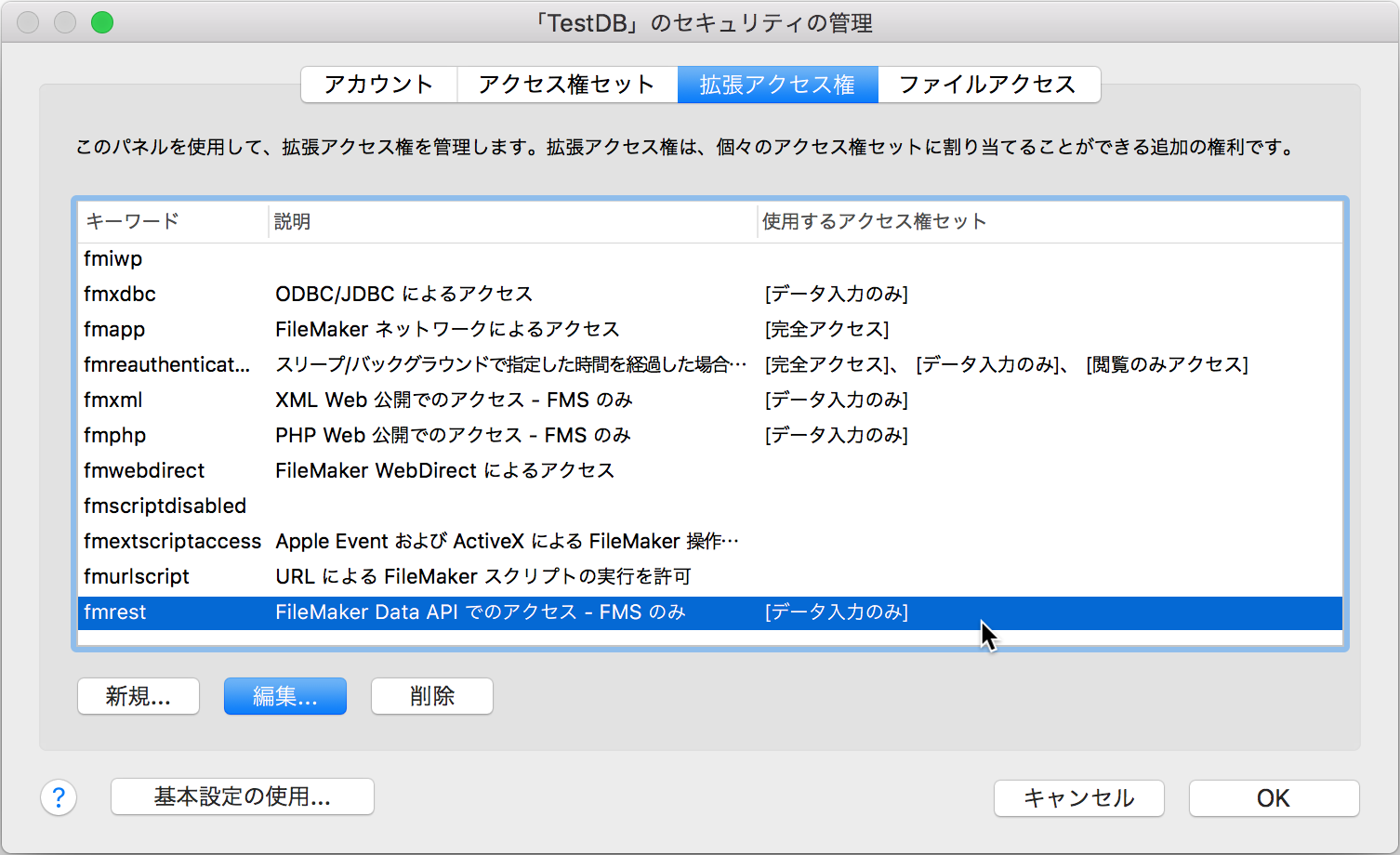
FileMaker Server 16をまずは手元のMacにインストールして使ってみようという方も多いだろう。ここで、FileMaker Data API(REST API)を使用する場合にPHPのcurlライブラリを使うと、「SSL: CA certificate set, but certificate verification is disabled」というエラーメッセージが返ってくる。httpsでの通信が推奨され、証明書が検証できないと通信をしないということが当然となって来ているが、とはいえ、試用なので自己署名証明書で運用できないかとPHPの様々なパラメータを触ってみたところで、上記のエラーないしは別のエラーが出る。ということで、色々調べてみると、macOSに入っているopensslのバグで、サーバー検証をしないという設定ができないということらしい。homebrewから入れ直す方法など、色々紹介されているが、何をとっても大事になってしまう。
というところで、早速、FileMakerホスティングで有名なエミックの松尾さんが、ルータとなるスクリプトを公開された(一部、修正したい箇所があったので、筆者がフォークしたものもある)。FileMaker ServerのREST APIは、httpで接続してもhttpsにリダイレクトされるが、その背後のNode.jsが開いている3000ポートを目指して接続することで、httpでも処理が進められる。ただ、ヘッダをうまく使って同じホストからの接続しかできないような仕掛けがあるため、「直接3000番ポートに接続する」よりも、ルータスクリプトを使う方が楽である。
ルータは、WebアプリケーションとFileMaker Serverの中間に位置しており、WebアプリケーションがFileMaker ServerへのRESTコールを行う代わりに、ルーターに対して呼び出しを行う。ルーターはhttpsを使わずにFileMaker Serverを呼び出し結果を得て、それをWebアプリケーションに返す。動作としては「プロキシ」であるが、名前がrouterなので、ルーターと呼ぶことにする。
ルーターを利用できるようにするには、ダウンロードしたファイルrouter.phpを、以下のようなコマンドで起動する。ファイルがある場所をカレントディレクトリにして、コマンドを入力する。
php -S 127.0.0.1:8090 router.php
ここで、127.0.0.1は自分自身に接続するIPアドレスであり、コロンに続いてサーバーが利用するポート番号を指定する。他のプロセスが使っていない番号を使う必要がある。なお、使用を止めたい場合は、Terminalの画面でcontrol+Cキーを押す。
筆者が作ったAPIを利用するためのクラスFMDataAPIでルーターを利用したい場合、利用方法のサンプルを示したFMDataAPI_Sample.phpであれば、最初の方にあるインスタンス化している部分を記載のように修正する。パラメータを2つ追加して、8090ポートを使うことと、httpプロトコルを使うように設定すれば良い。他は変更が必要ない。もちろん、8090はルーターを起動する時に指定したポート番号を使う。IPアドレスも、基本的に起動時に設定したものを指定する。
修正前:
$fmdb = new FMDataAPI("TestDB", "web", "password", "127.0.0.1");
修正後:
$fmdb = new FMDataAPI("TestDB", "web", "password", "127.0.0.1", 8090, "http");
一方、FMDataAPITrialにあるスクリプトは、まず、lib.phpファイルにある以下の関数の返り値に、ルータ側のポート番号を指定する。
function targetHost()
{
return "127.0.0.1:8090";
}
そして、Test2.php以降、プログラムの中のhttpsの記述をhttpに切り替える。callAPI関数の最初の引数が全てhttpsになっているので、httpに書き換える。
$host = targetHost();
$result = callAPI(
"http://{$host}/fmi/rest/api/auth/TestDB",
null,
json_encode(array(
"user" => "web",
"password" => "password",
"layout" => "person_layout",
)),
"POST");
resultOutput($result);
なお、phpコマンドで、router.phpを起動する時、127.0.0.1ではなく、localhostで指定した場合、上記の修正箇所のIPアドレスは、全てlocalhostで記述する。127.0.0.1では稼働しないので注意する必要がある。phpコマンドで起動する時に127.0.0.1を指定すると、Webアプリケーション側の設定は、127.0.0.1でもlocalhostでもどちらでも良いようだ。FileMaker Serverはかなり以前からIPv6ベースで動いているのだが、localhostとした場合、どこかで127.0.0.1ではないIPv6のアドレスとして識別しているのではないかと想像できるのだが、詳細は分からない。
ちなみに、FMDataAPIを使ったシステムを運用する時、原則としては正しい証明書でhttpsで運用することが原則だ。もちろん、盗聴されないためというのが大きな理由であるが、ホストを偽ってデータを収集されたり嘘の情報を流されることも防ぐ必要がある。httpsでの運用は、Let’s Encryptで無償で利用できるなど、年々手軽になってきているので、面倒がらずに対応すべきだというのが1つの結論である。
では、PHPを稼働させるWebサーバーとFileMaker Serverが同一のホストであれば、盗聴の心配はないのではないかと言うことになる。Firewallでポートを塞げば、それでいいのではないかと言う話もなくはない。ただ、FileMaker Data APIだけにWebサーバーを使うと言うことはあまりないと思われるので、Firewallの設定はちょっと面倒ではないだろうか。絶対に外部からFileMaker Data APIは利用しないで、サーバー内部に限るのであれば、httpでの運用でも問題はないかもしれないが、必ずサーバーの内部からの利用しかしないと言うことを管理者が人手で保証しないといけなくなる。通常、httpsで運用する手順を踏む方が楽なのではないだろうか。
自己署名証明書の問題も同様だ。サーバー内部に限るのなら、詐称のしようもないと考えることができる。これも、「絶対にサーバーの内部からの利用しかしないと言うことを管理者が人手で保証する」と言うモデルであり、むしろ、そういった人的な縛りよりもhttpsでの運用をする方が問題が発生しにく状況であると言えなくないだろうか?
そう言うことで、httpや自己署名証明書での運用は自己責任が大きいので、FileMaker Data APIでアプリケーションを開発したら、本番はhttpsでの運用を目指すようにすべきである。
なお、筆者の作ったFMDataAPIクラスは、デフォルトは証明書の検証をしない状態で稼働するので、そちらは開発中での利用を想定している。実際に正しい証明書が用意できれば、以下のメソッドを呼び出す。そうすれば、証明書の検証を行うようになる。自己署名でないこと、期限、アクセスしているサーバ名と同一なのかが検証される。
$fm->setCertValidating(true);
すなわち、FMDataAPIクラスは、証明書の検証もメソッドでコントロールできるようになっている。