アクティビティモニタが少しすっきりした画面になっていますが、「エネルギー」というタブが追加されていて、エネルギー消費のインパクトになるものが分かります。簡単に言えば「電池を食うアプリケーション」を燻り出すツールでしょうか。
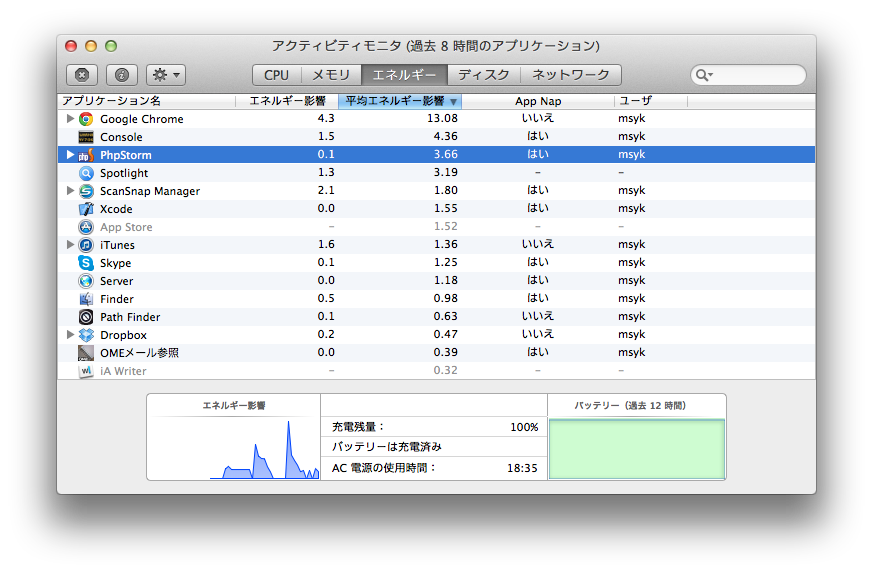
ここでApp Napの列を見ると、App Napの状態に入っているかどうかを確認できるようです。刻一刻と変化するので、「対応しているか」ということではなく、App Napの状態かどうかを示していることになります。
App NapはAppleのサイトよると、バックグランドにあるアプリケーションのCPU使用をぐっと減らしてバッテリーの消費を伸ばすという仕組みです。パフォーマンスも少しは向上するかもしれませねんが、背後で作業をする場合には普通に作業するので、パフォーマンスの向上はわずかになるでしょう。
Appleのサイトでも唱われているSafariの効率化で、背後に回ったタブもApp Napの対象になるとなっています。つまり、Safariのタブは1つ1つ別のプロセスになっているので、事実上、タブ1つが1つのアプリケーションのようなものと思ってもいいでしょう。それらが、別々のプロセスで見えていて、表示していないページの一部はApp Napが機能します。ただし、全部ではないようです。
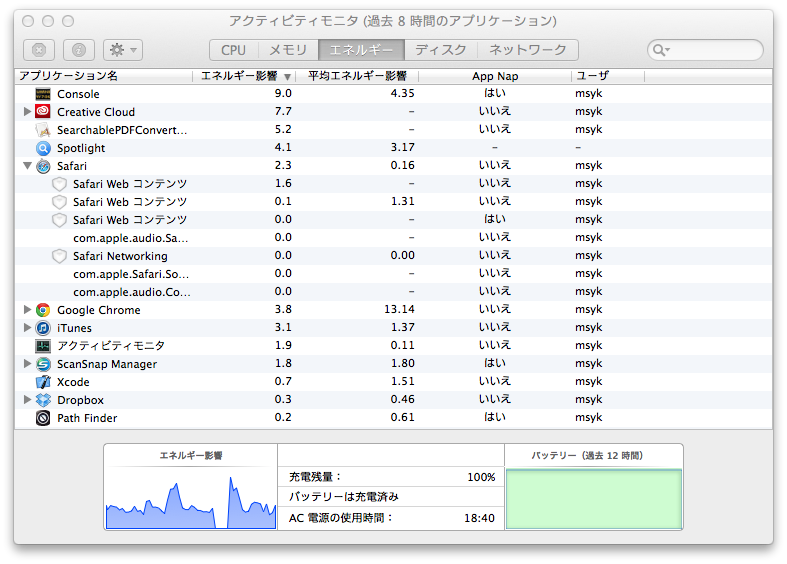
一方、ChromeもGoogle Chrome Rendererというプロセスがアプリケーションの子プロセスになっているので、ページごとに別々のプロセスが描画を担っているようです。しかし、ChromeのRendererは単独でApp Napには入らず、アプリケーション自体だけが背後に回ったときにApp Napに入るのみです。アプリケーションがApp Napに入り、子プロセスがそうでない場合、子プロセスも省電力動作をするかどうかは判断できないところですが、実行機会はすべてのプロセスが持つのですから、親がApp Napだと子供もApp Napということではないと思います。
となると、やはりSafariの方がChromeよりもエネルギー効率は高いのかもしれませんが、よく考えると、ブラウザの種類に限らず、バッテリーを長持ちさせたいのならブラザの余分なウインドウを閉じる方が効果は高いということでしょう。また、使わないアプリケーションも落とすというのが基本ですね。
アクティビティモニタを見ていると、末尾にグレーのアプリケーションがあります。起動しているものもありますが、起動していないものもあります。App Storeアプリケーションがそうなのですが、これはもしかすると、アプリケーション自体が監視のためのデーモンを動かしていることの印なのかもしれません。また、この一覧には原則としてアプリケーションとその子プロセスが見えています。つまり、デーモンはApp Napとは関係ないという事でしょうか(だからAppか!)。
ヘルプを見ると、「高性能 GPU 必要」という項目もアプリケーションごとに出るようで、複数のグラフィックカードがある場合に、高パフォーマンスGPUを使用する必要があるかどうかを示すようですが、私のMacBook Air 2012ではこの列は出せないようです。「表示」メニューの「表示項目」では選択できません。
開発関連の情報を見る限りは、「App Napを有効にする」みたいなフラグがアプリケーションにあるわけではなく、Cocoa Frameworkを使ったアプリケーションには適用されるようなシステム機能と言えます。バックグランドでなるべく何もしないとか、タイマー処理の間隔を広めに取るなどの対策をすることで、よりApp Napに入りやすくなるということのようです。ただ、手元にある比較的古いアプリほど、グレーになっていたりするので、単にCocoaということではなく、一定以上あたしいフレームワークでビルドしないと、App Nap適用されないのではないでしょうか。