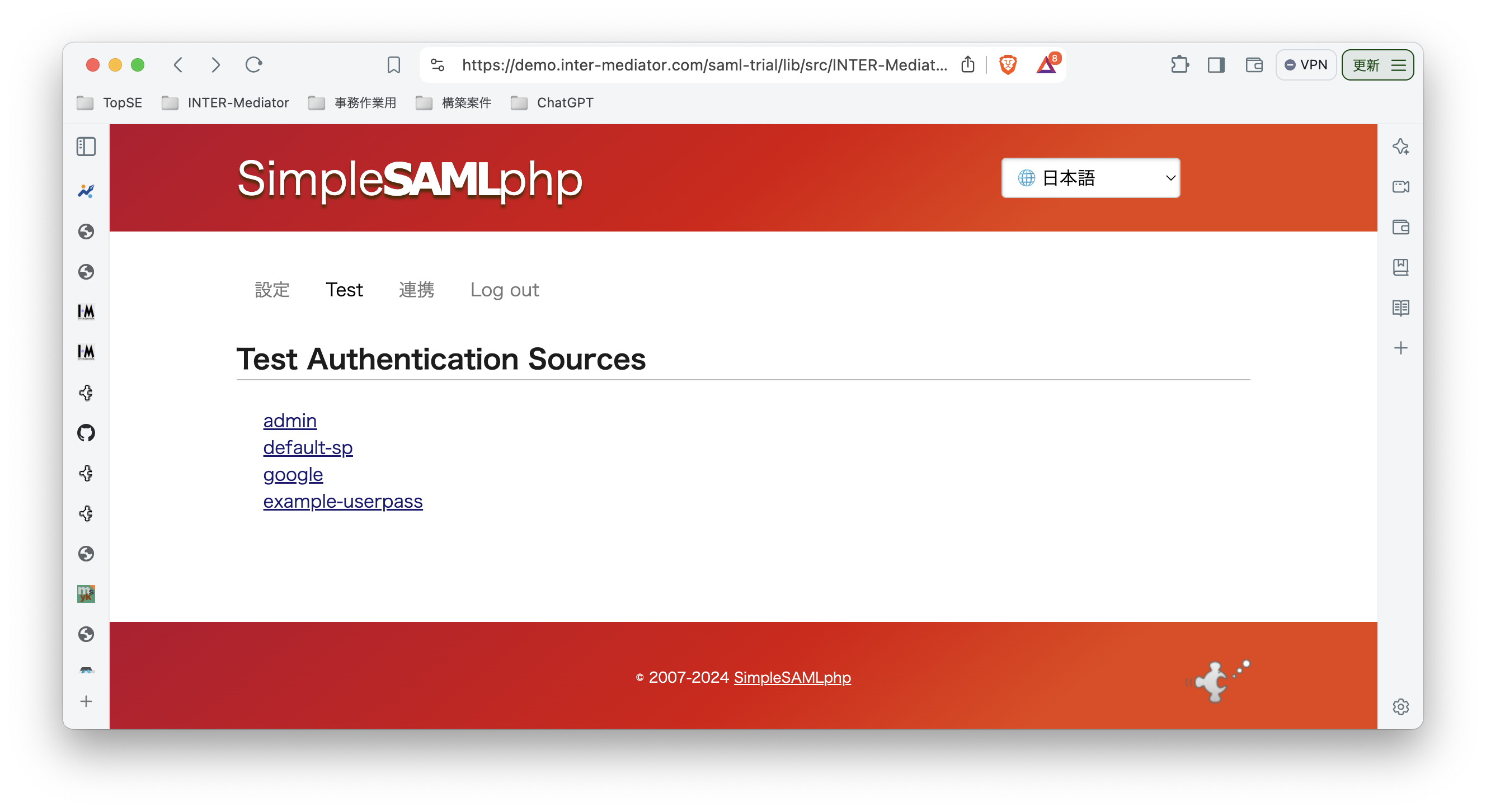
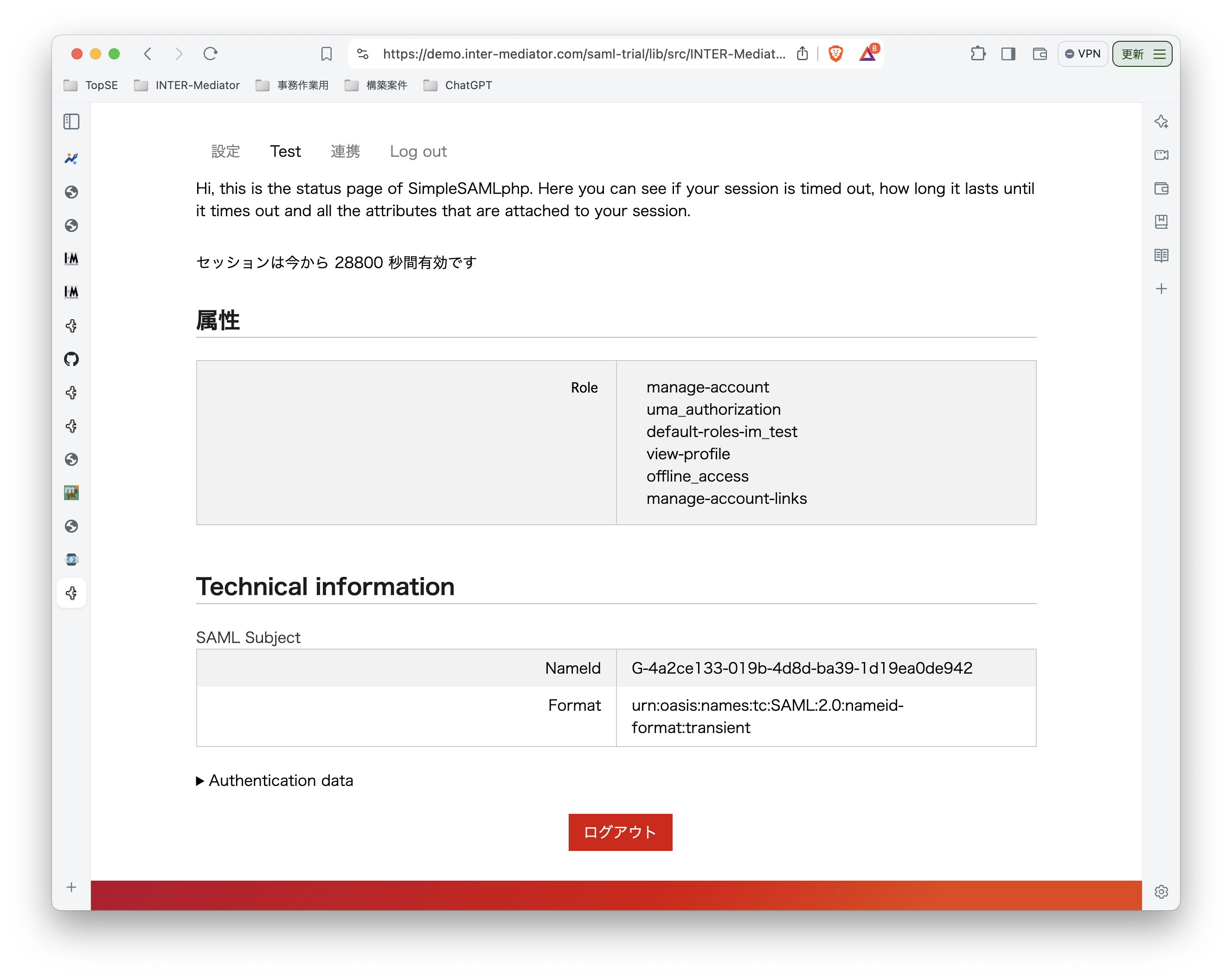
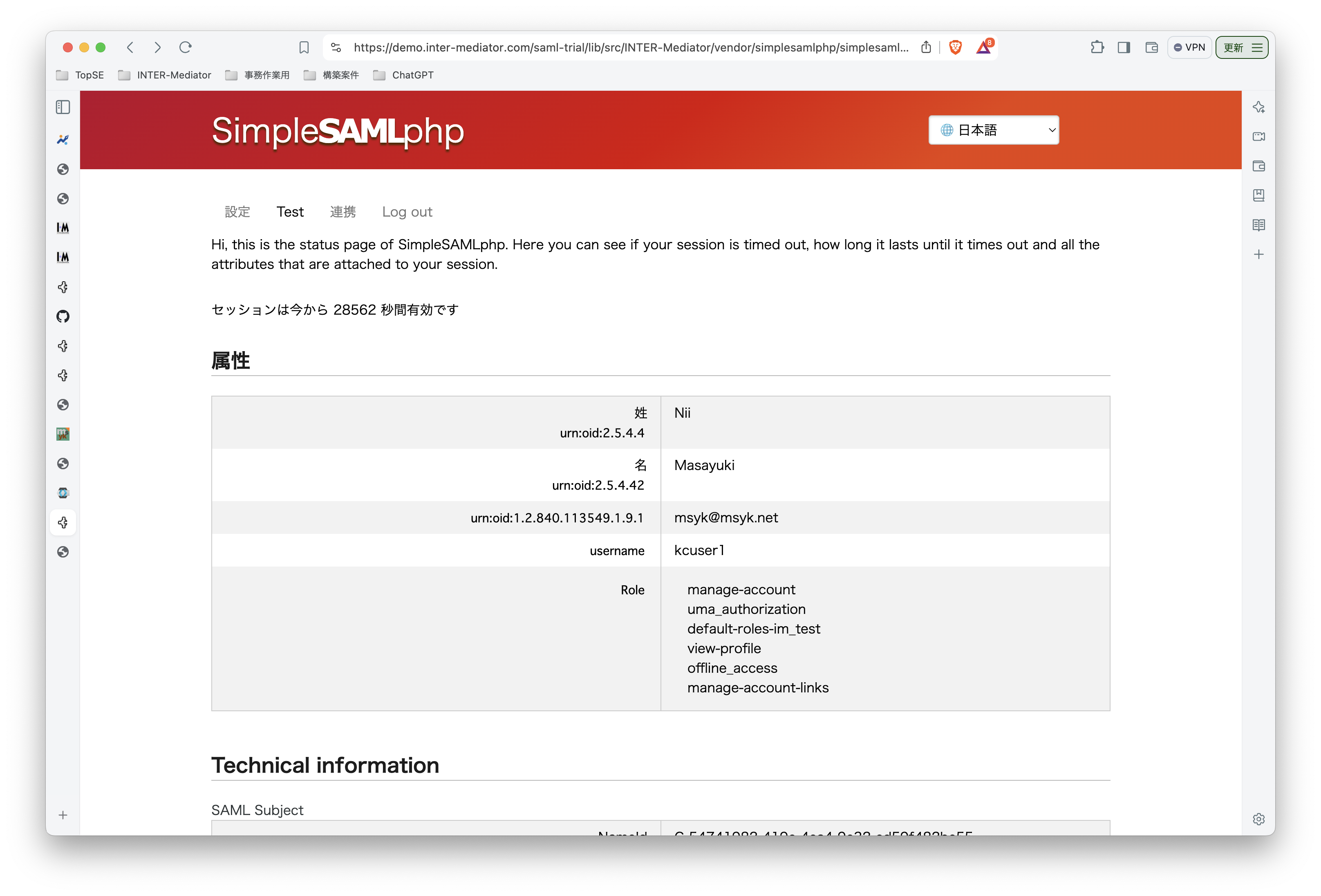
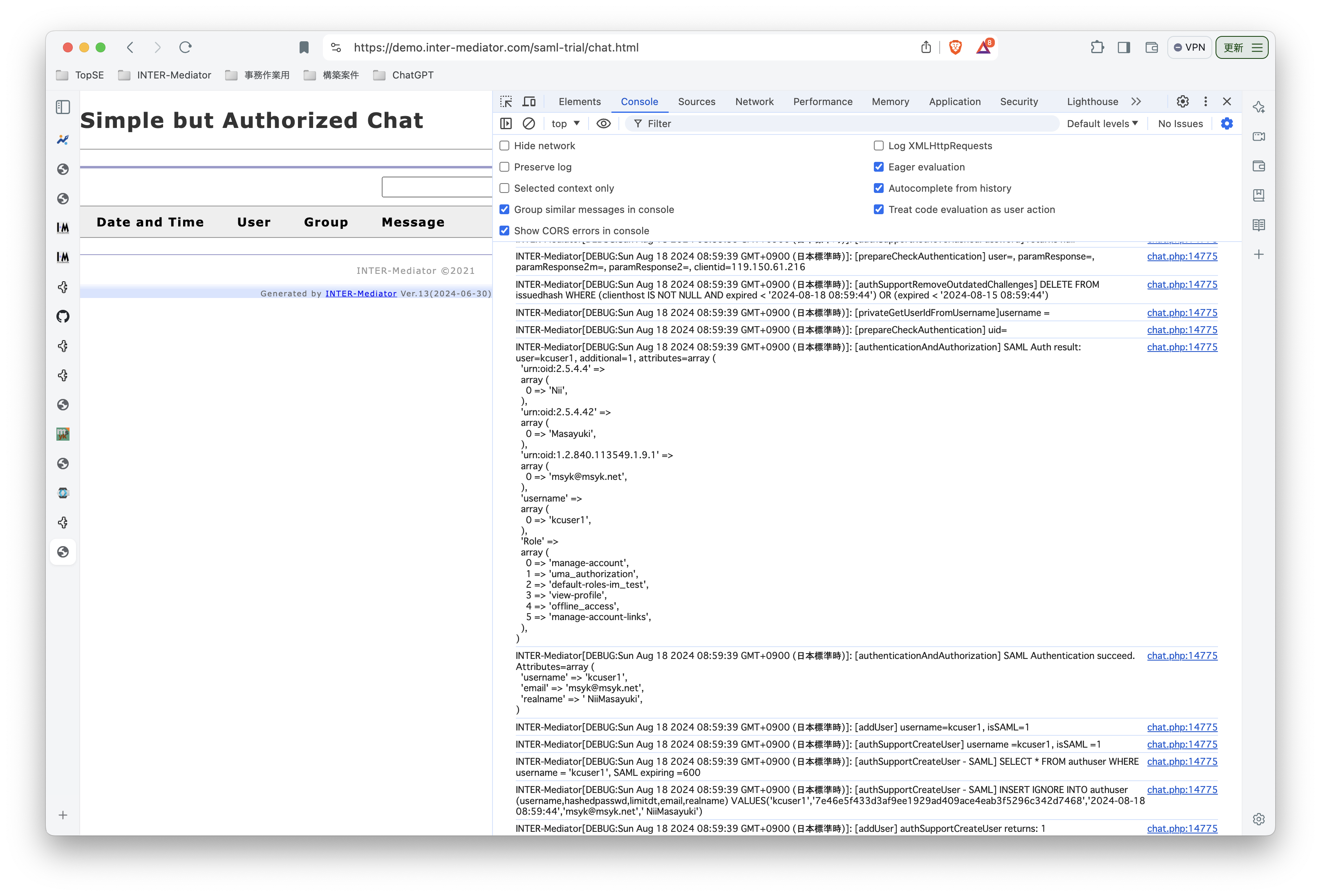
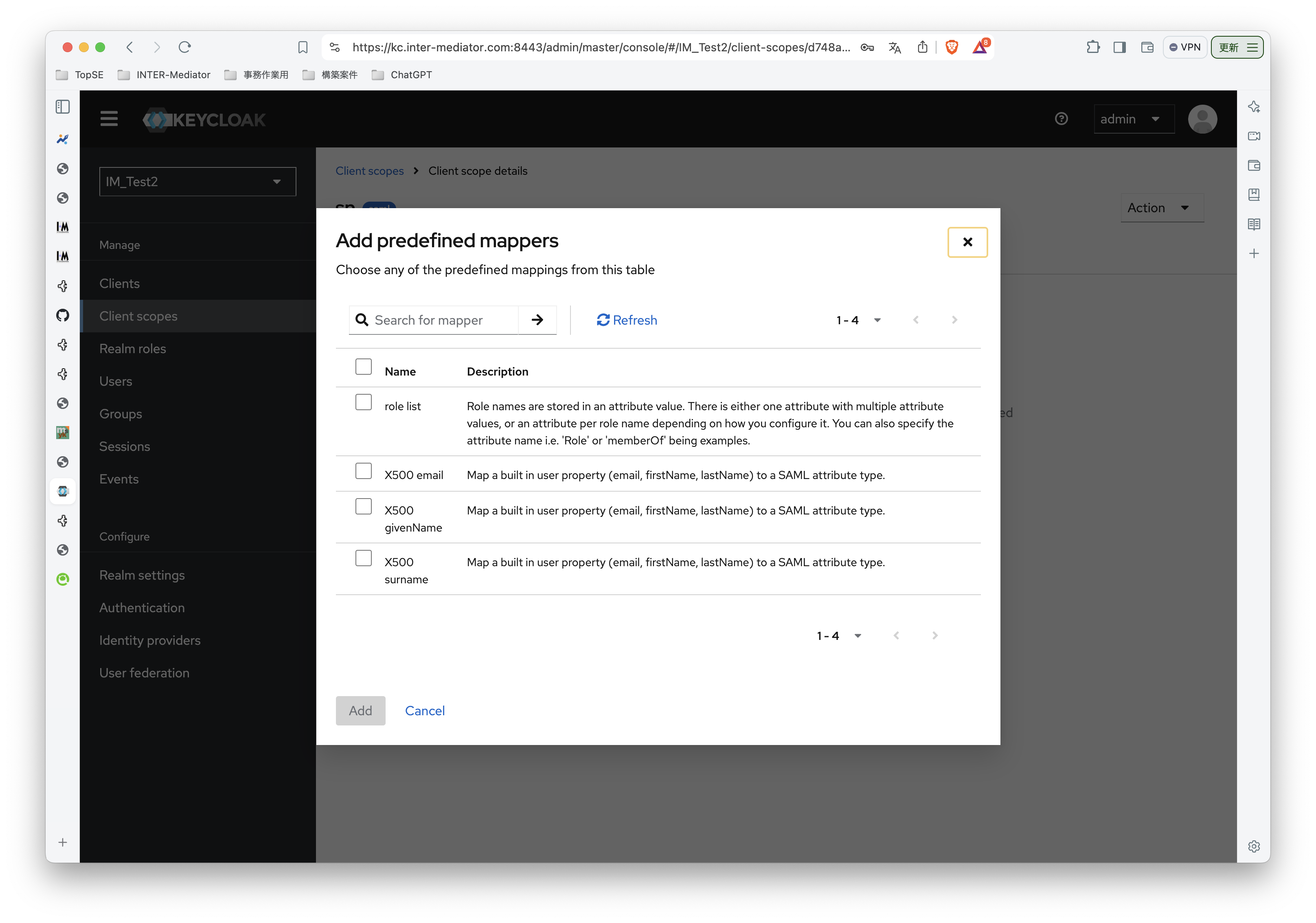
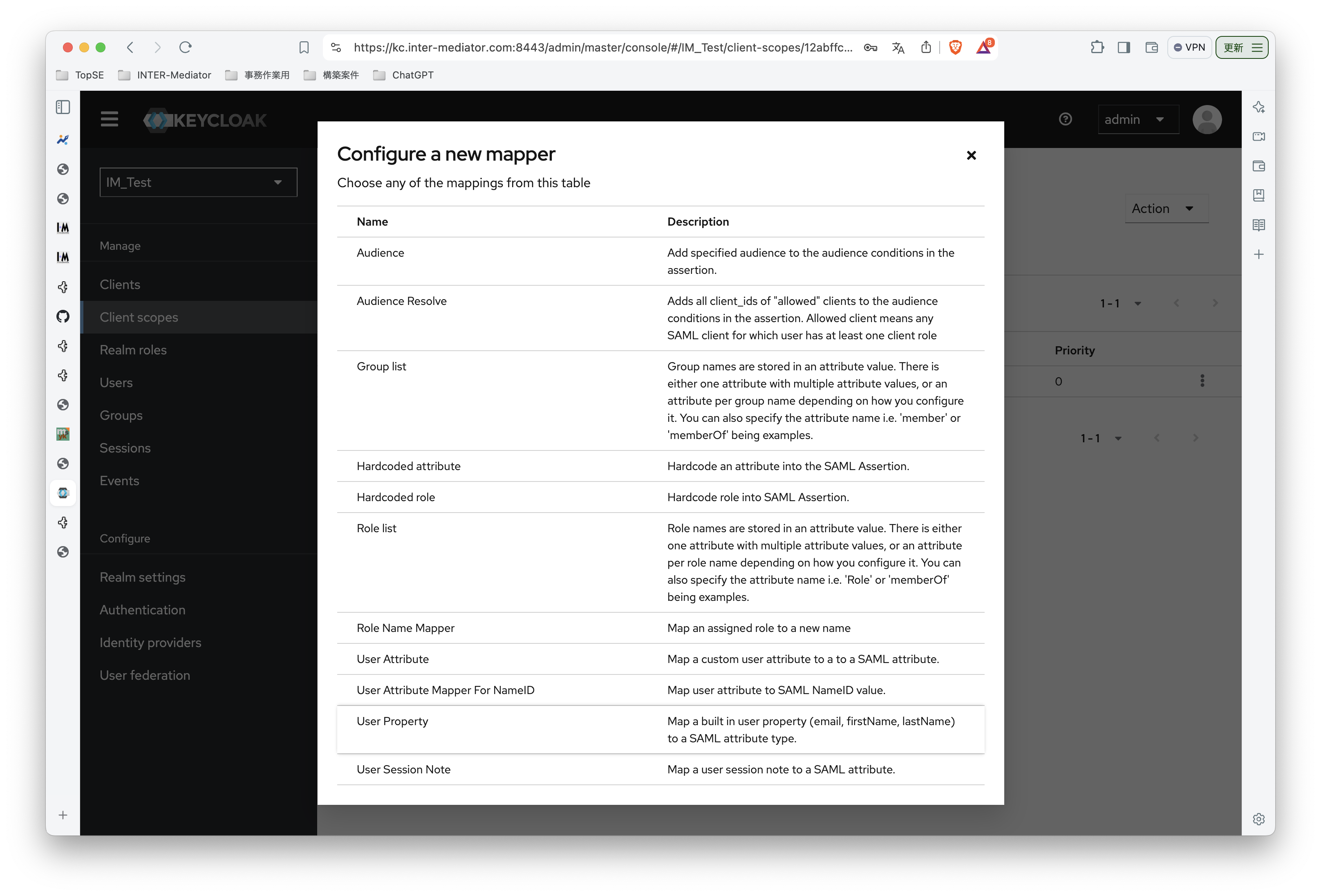
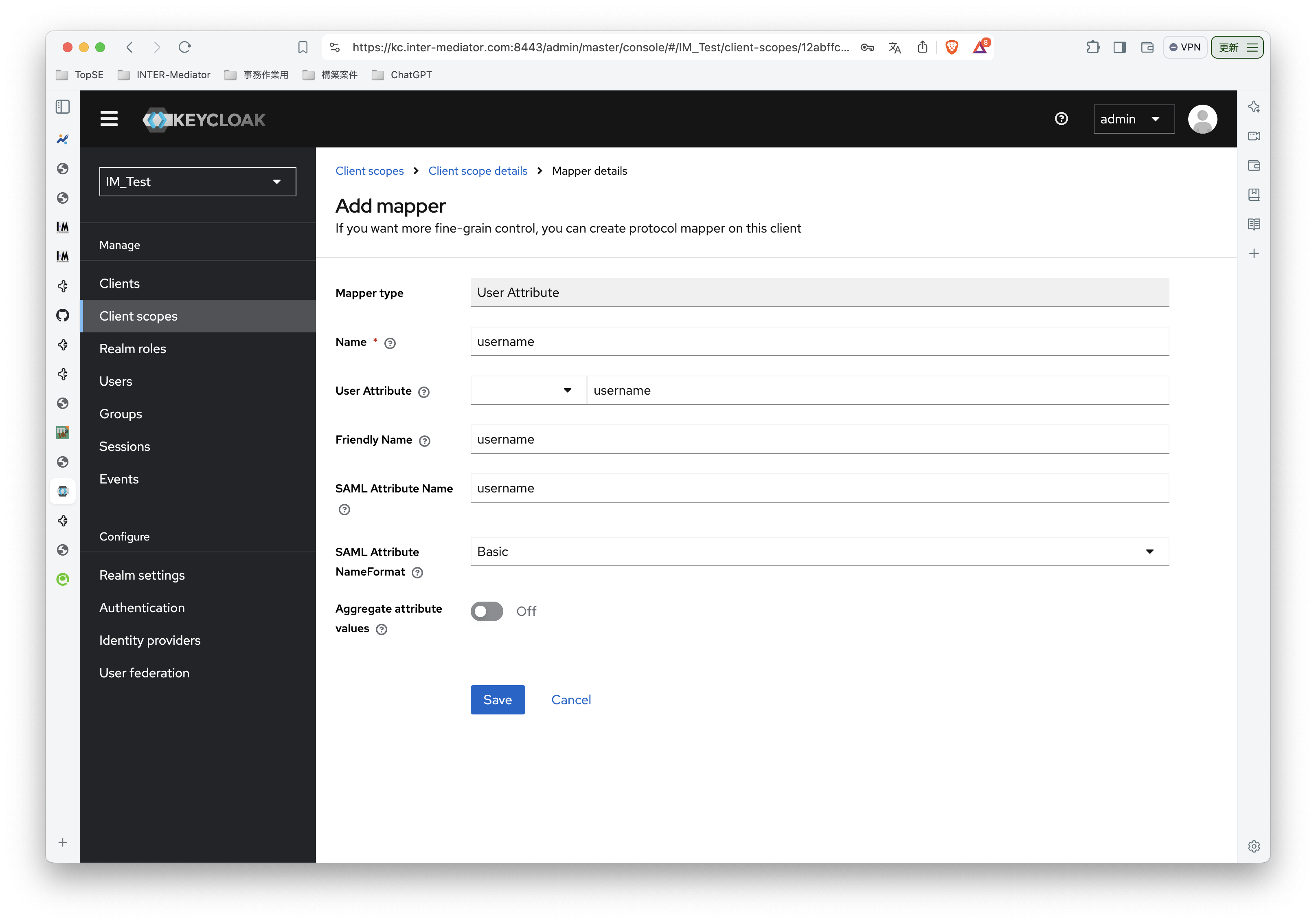
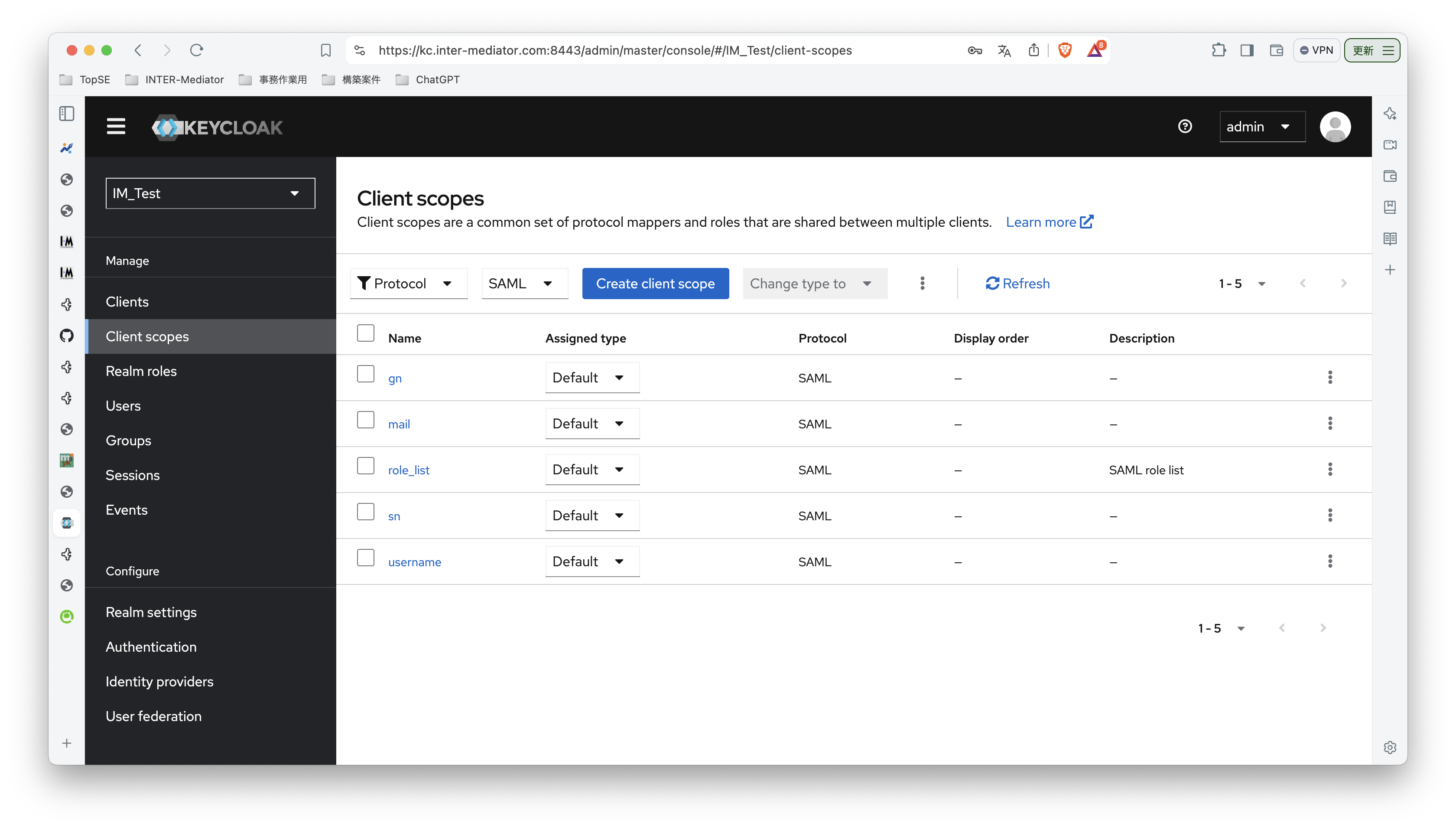
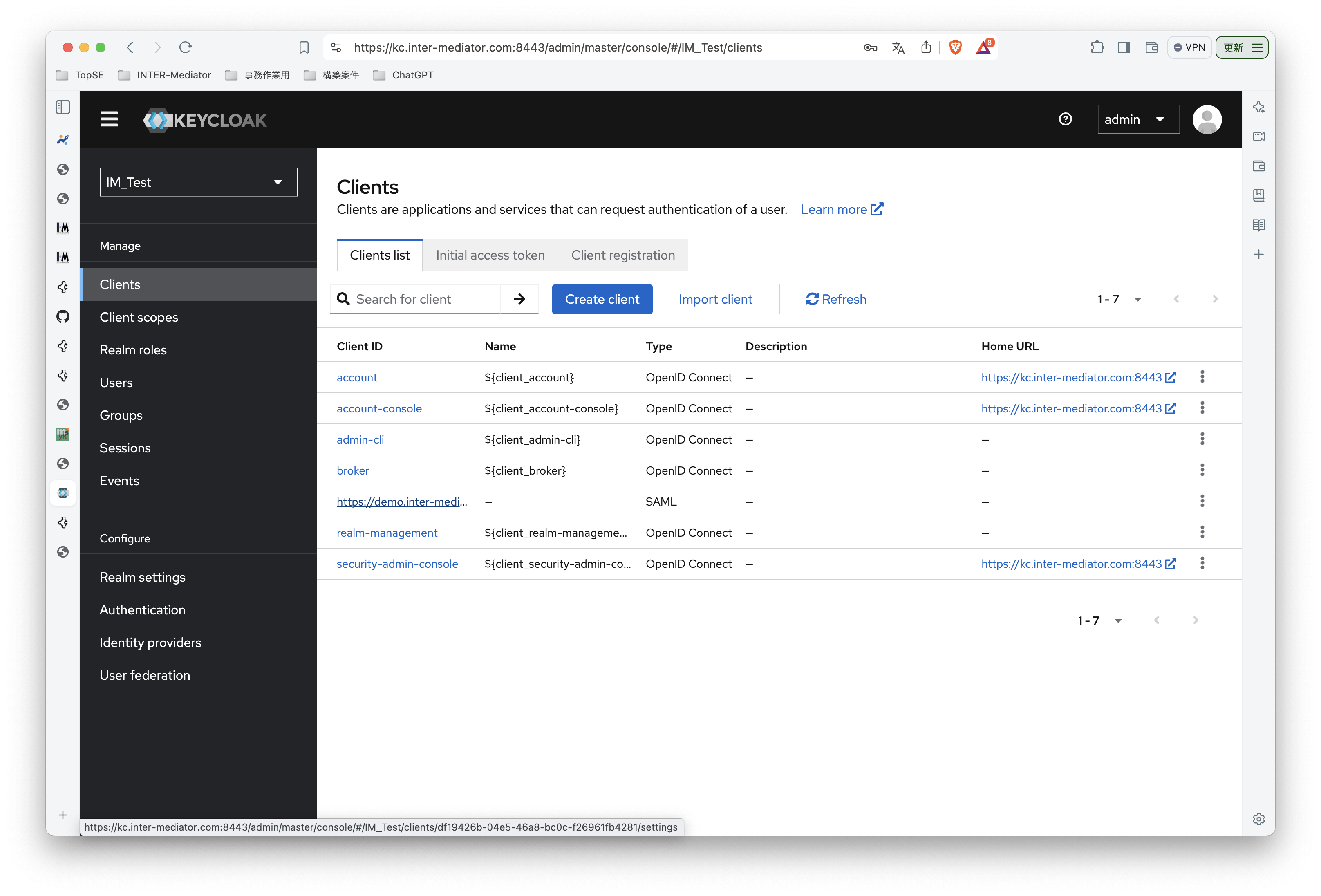
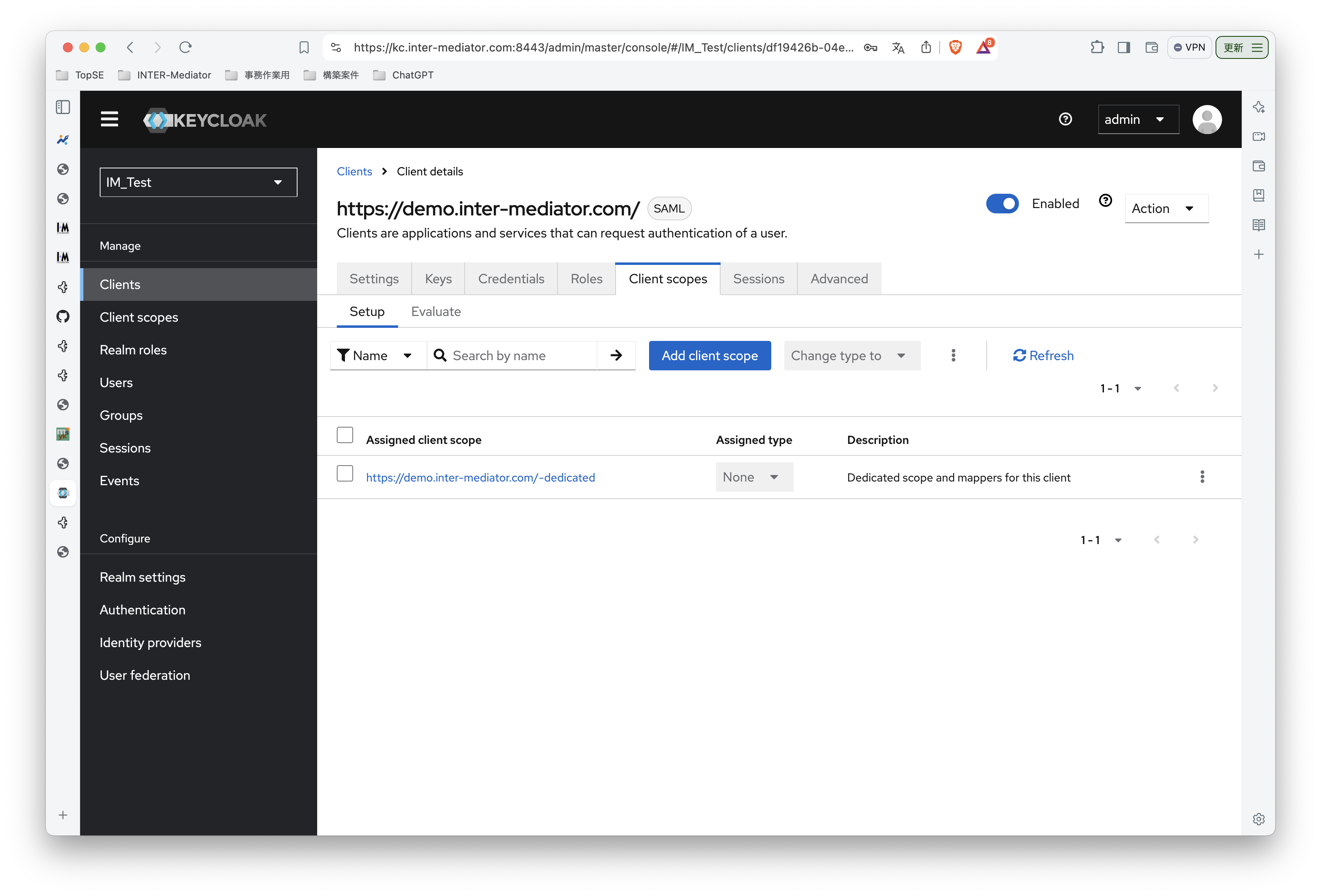
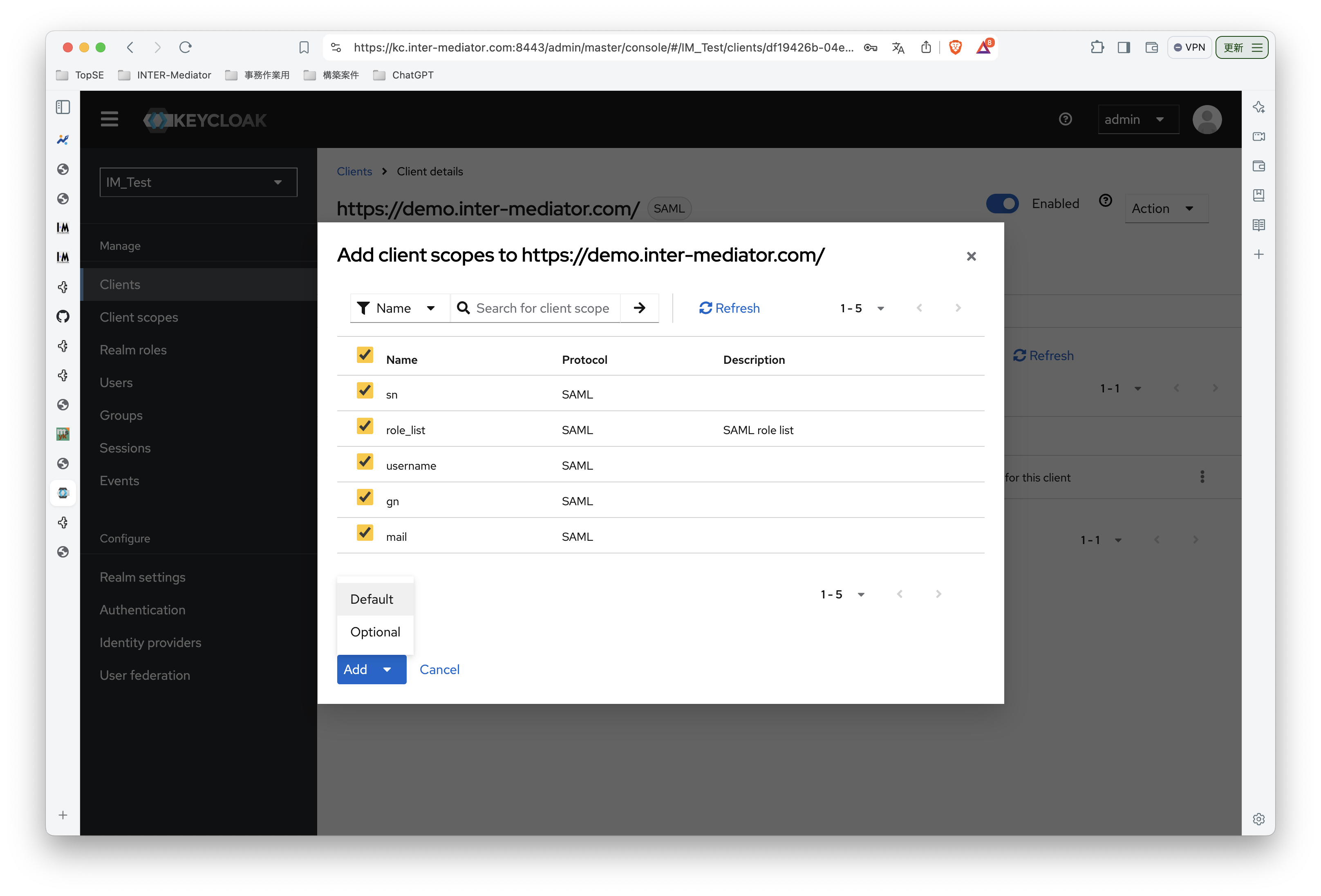
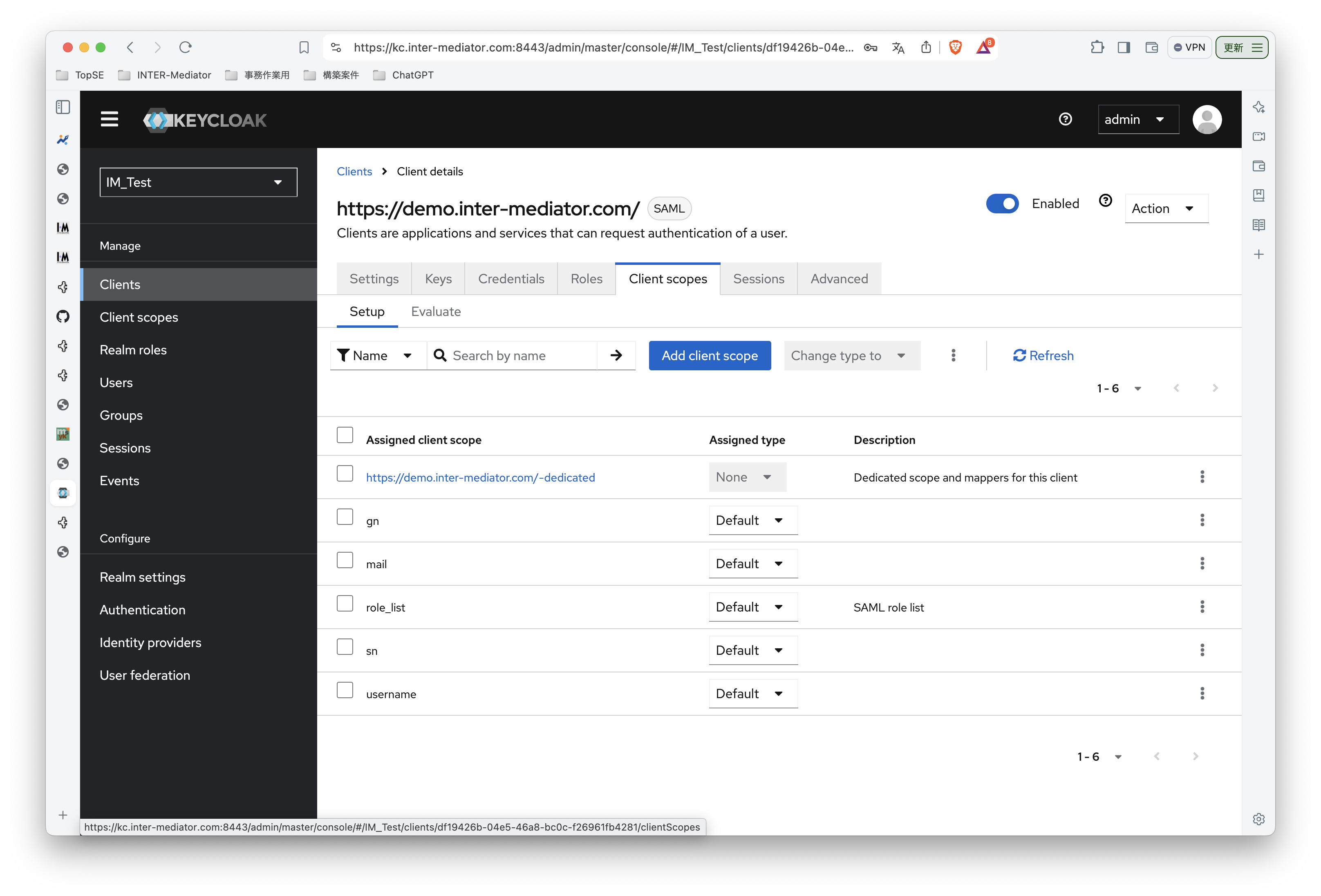
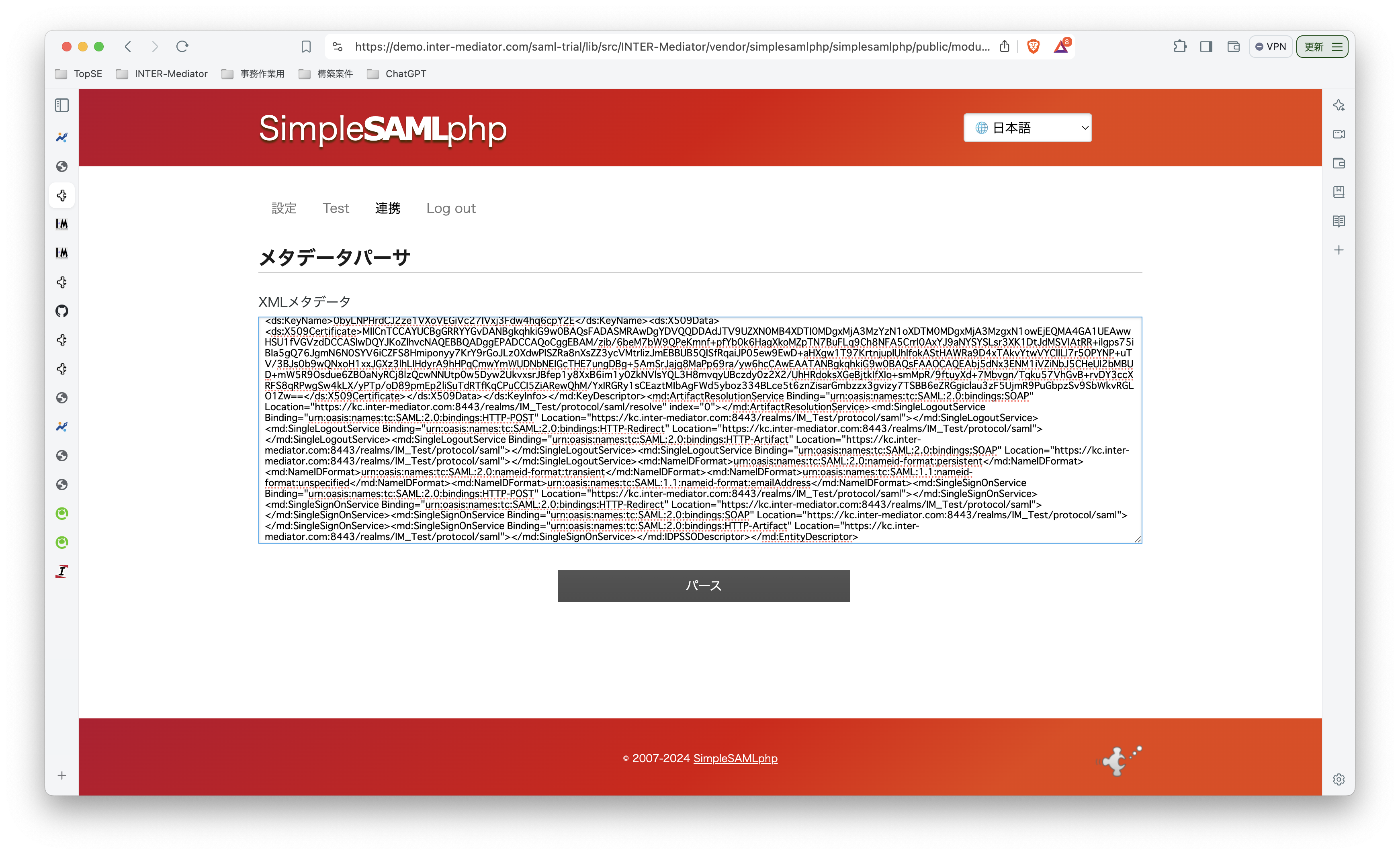
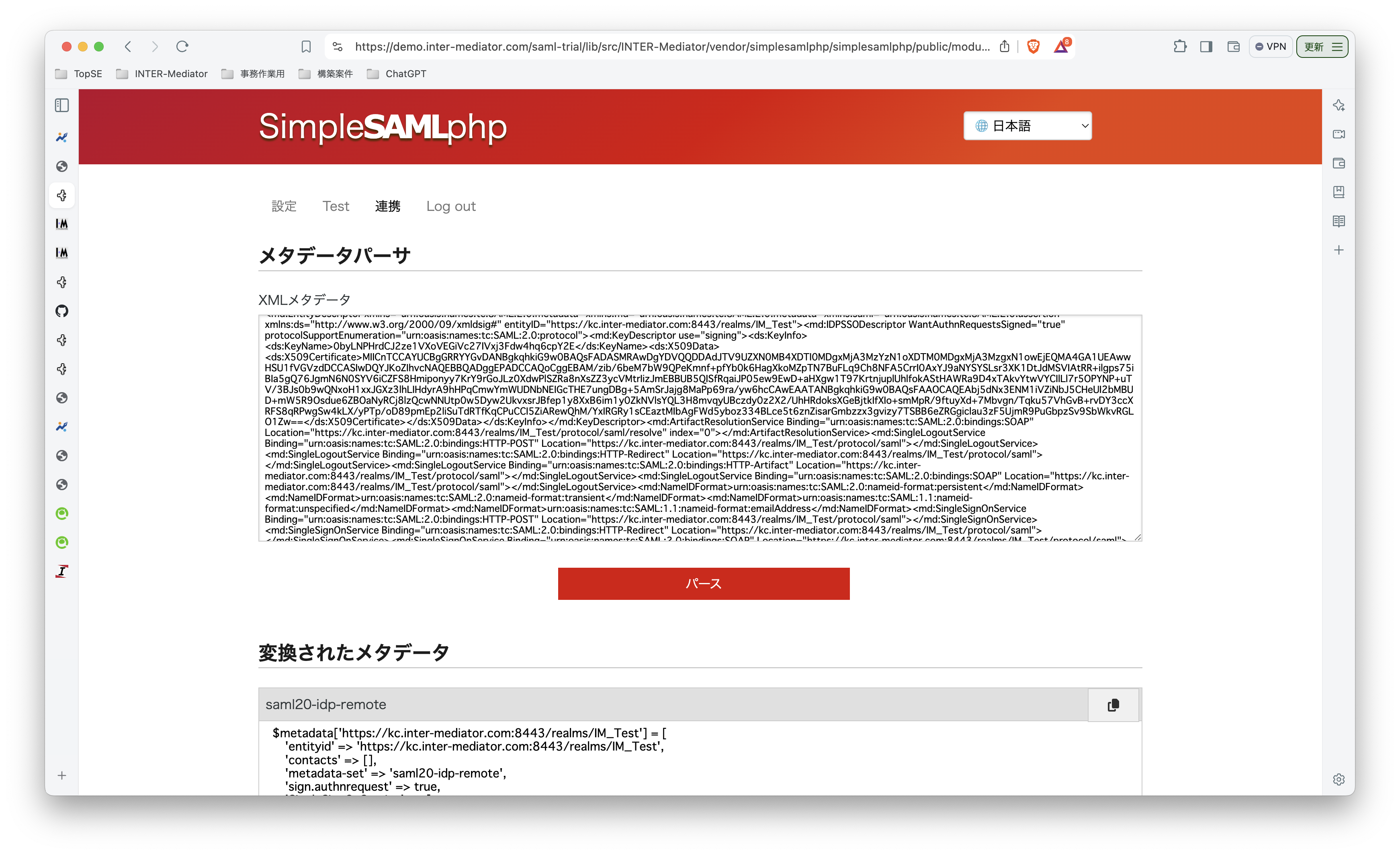
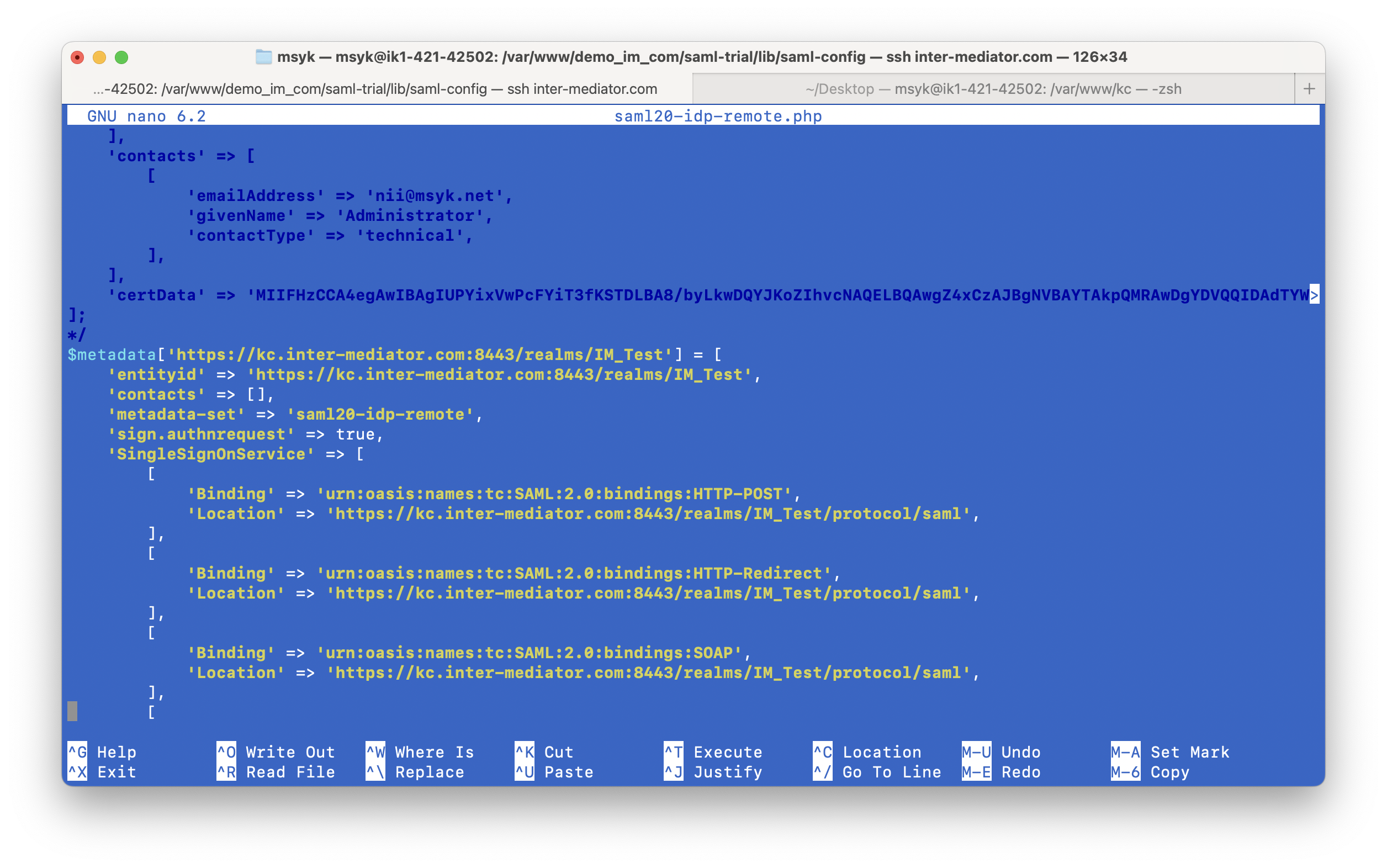
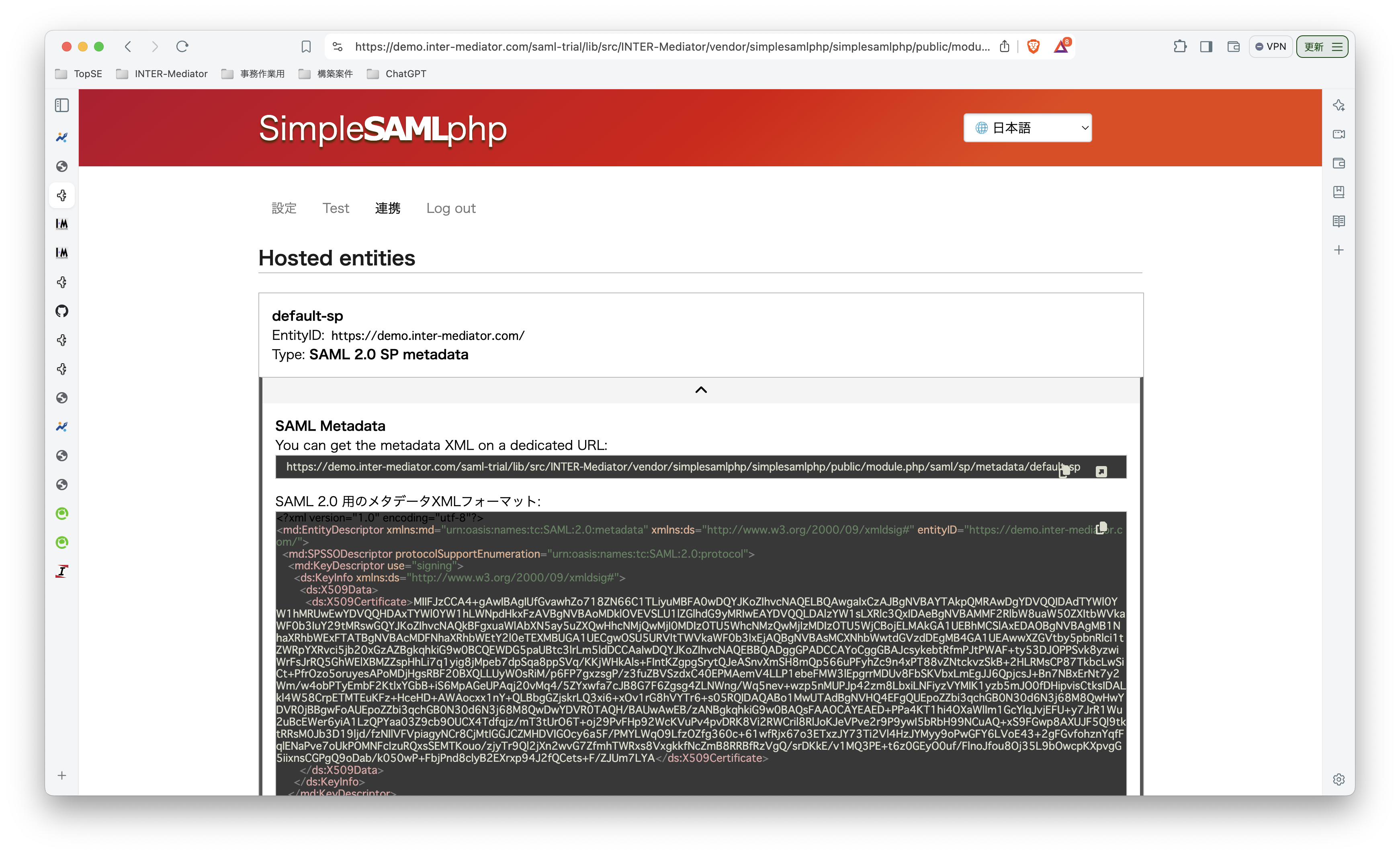
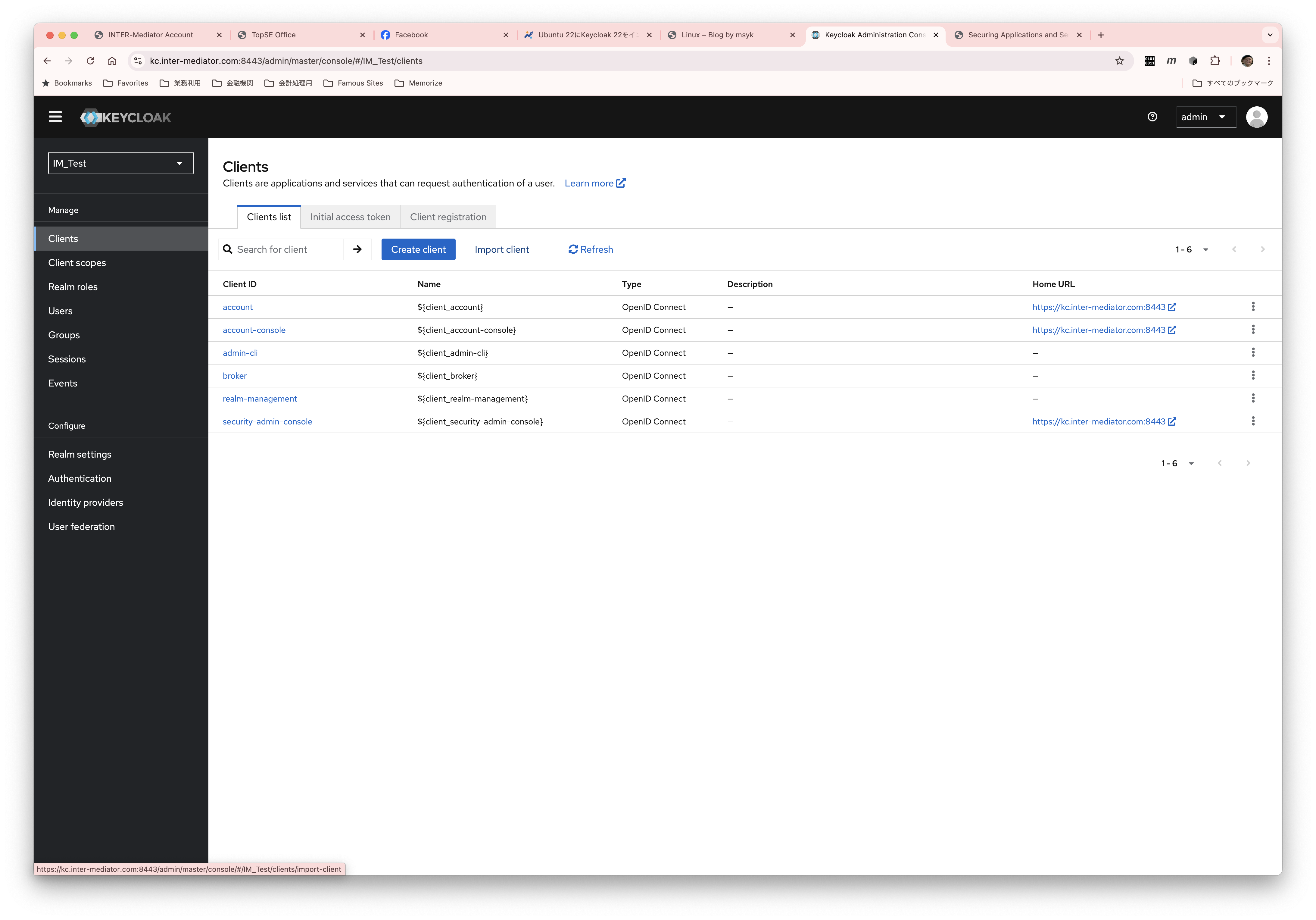
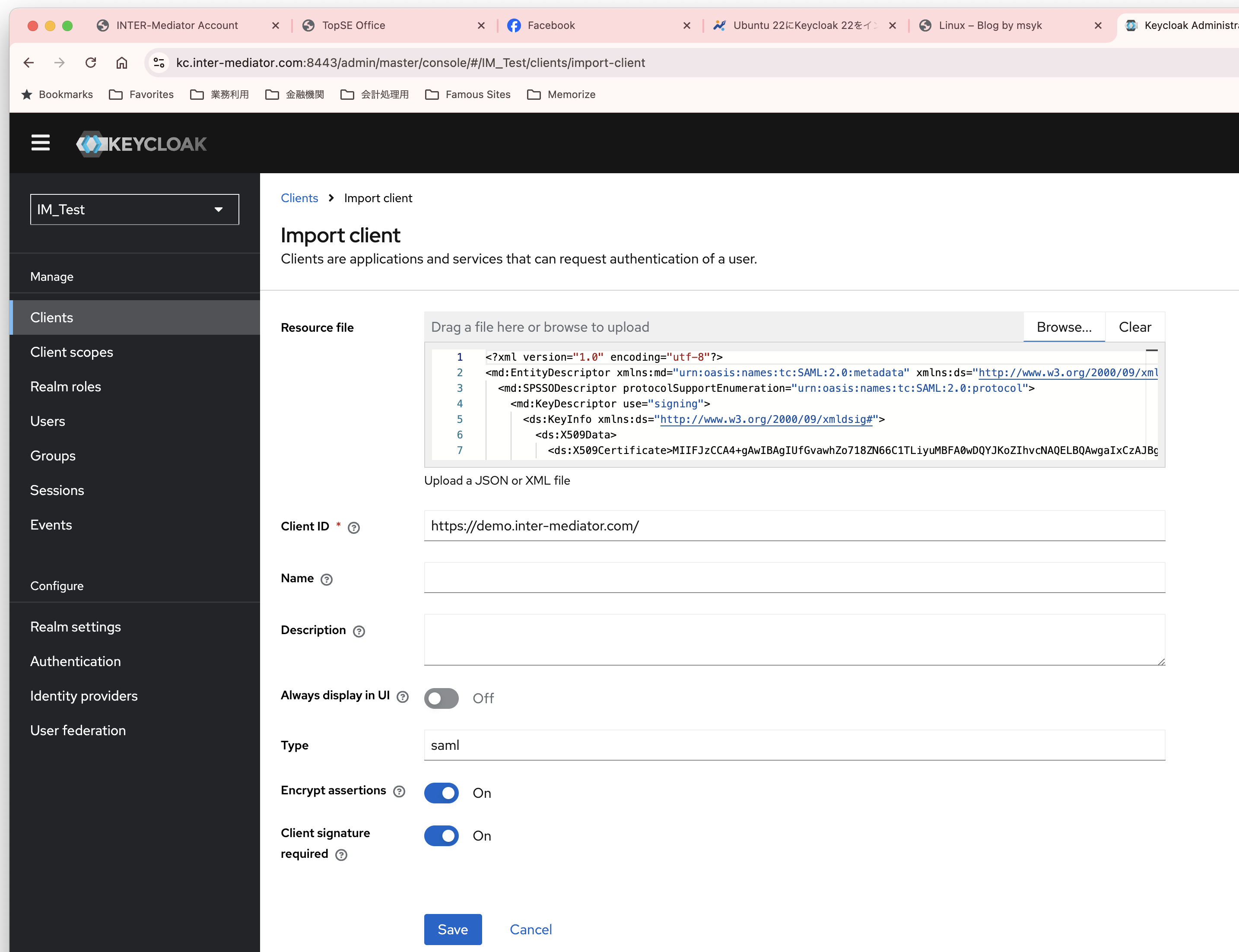
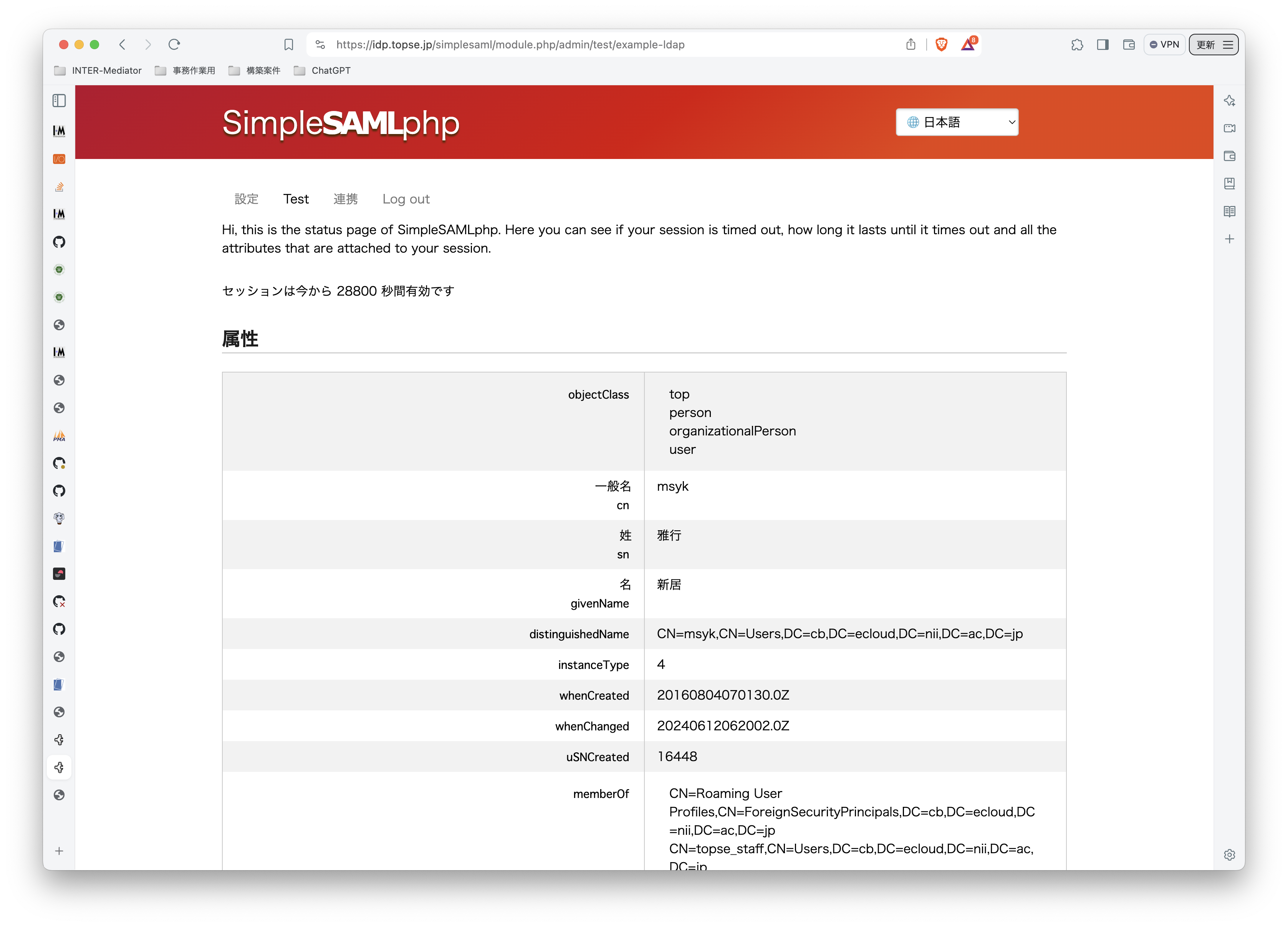
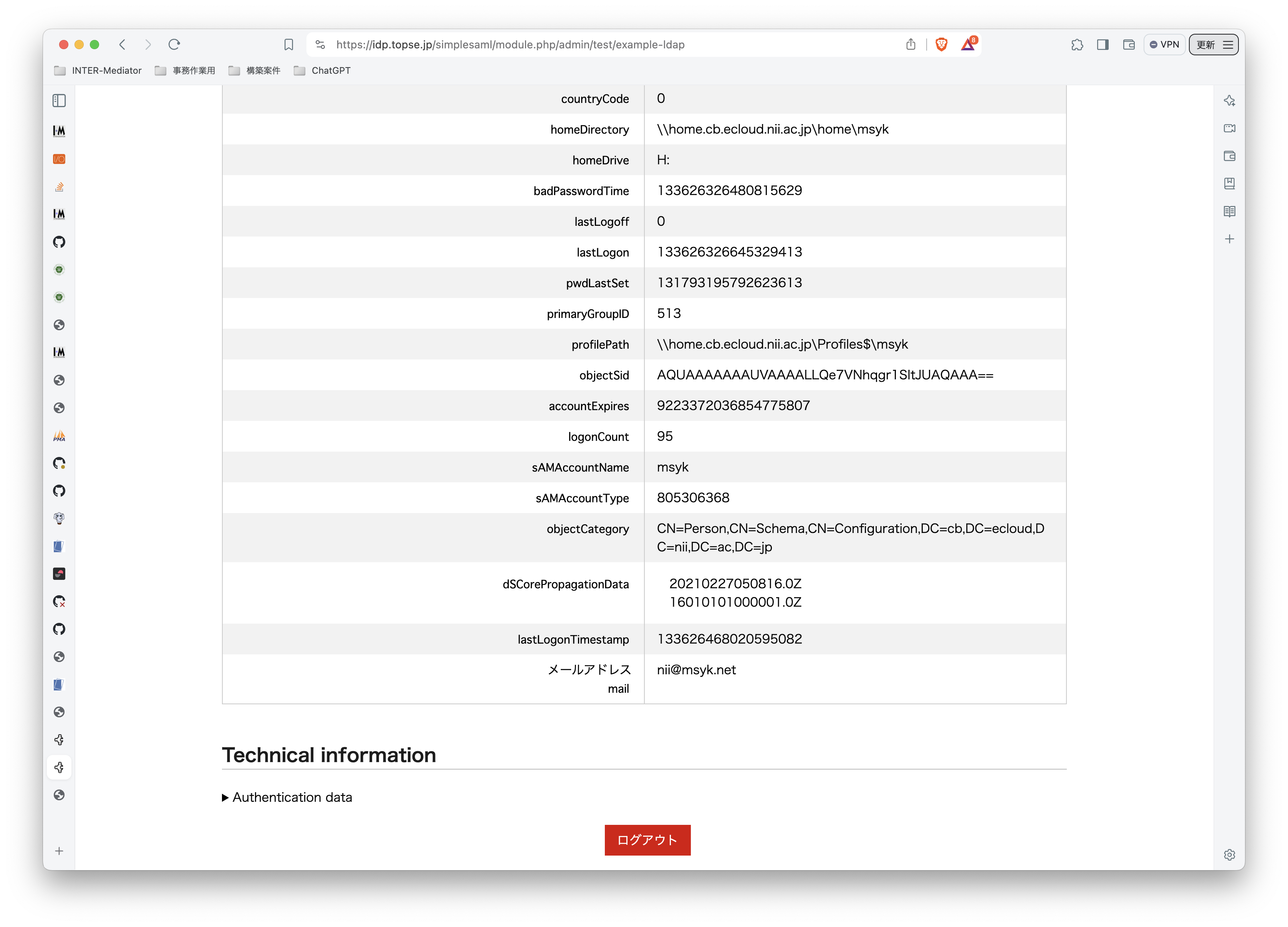
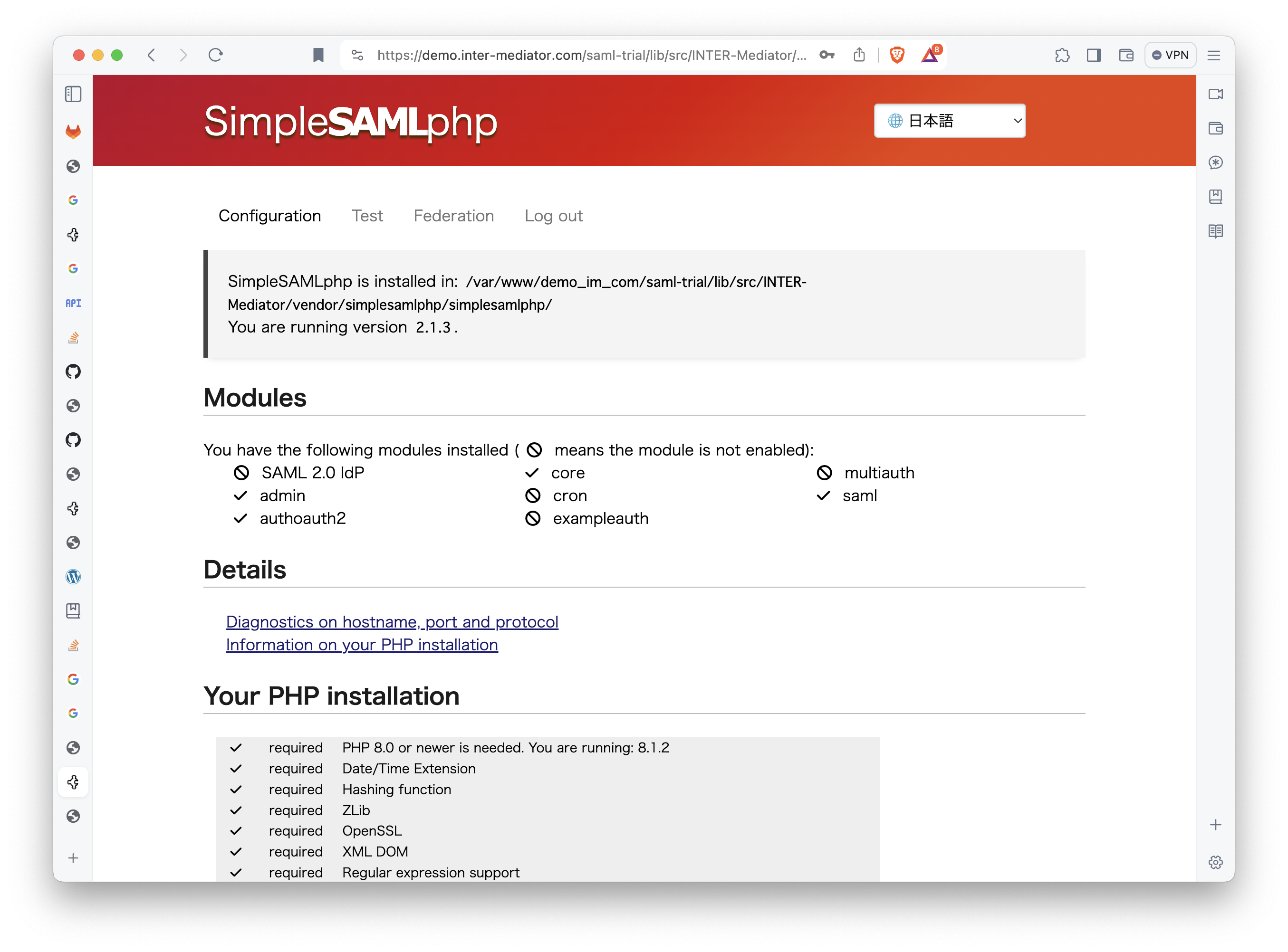
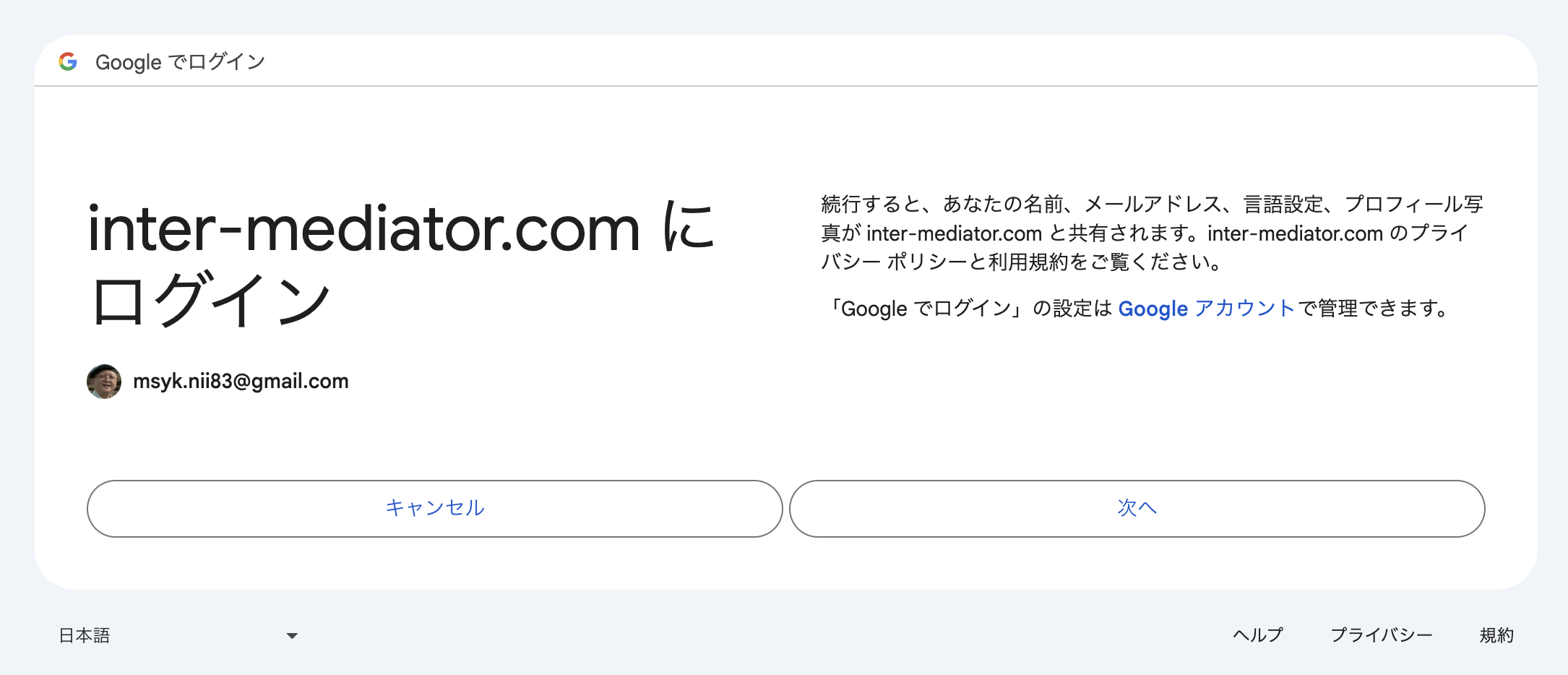
INTER-Mediatorで作るアプリケーションの認証基盤として、KeycloakをSAMLのIdPとして利用した場合の動作を検証する必要が出てきたので、実際に動かしてのチェックを進めてみる。SPはもちろんSimpleSAMLphpであり、これはINTER-Mediatorではcomposerでインストールできている状態になっている。ということで、まずは、Keycloakをきちんと動くようにしたい。(1)は、Keycloakを動かすまでである。
稼働するサーバは、INTER-Mediatorの公開サーバーで、Ubuntu 22で稼働している。そこに、kc.inter-mediator.comというドメイン名を割り当てて、Keycloakを利用することにする。ただ、Keycloak自体はJavaのアプリケーションであり、Apache2と連携しなくても連動するので、ともかく連携しない方法での稼働を目指すが、Let’s Encryptで、kc.inter-mediator.comの証明書を作るので、Apache2側も幾らかの設定を行うことにした。
なお、インストール方法は、ITC Enginnering Blog:Ubuntu 22にKeycloak 22をインストールして、Identity providers=Azure ADでSAML を参考にさせていただいた。基本、概ね同じである。
利用するドメインの証明書を取得するまで
INTER-Mediatorの公開サーバーは、Sakura VPSである。すでにWeb等が稼働しているため、当然ながらのポートは開いているが、Keycloak用に、TCP 8443とTCP 9000のポートを開いた。9000はとりあえずは使わない。サーバ側にFirewallを設定する方式ではなく、コントロールパネルから設定するパケットフィルタを設定しているので、そこで8443/9000ポートを開いておいた。
そして、まずは、OSのアップデートを行い、kc.inter-mediator.comサイトを作る。サイトのルートは、/var/www/kcとした。そして、Apache2の設定ファイルをsites-availableディレクトリに作る。80番ポートと433番ポートは同じディレクトリを公開するように設定しているが、80側にはリダイレクトの設定があり、httpでアクセスがあると自動的にhttpsにしている。なお、certbotが成功するまでは、SSLCertificateFileとSSLCertificateKeyFileの設定は頭に#を入れてコメントにしておく必要がある。ここまで準備できれば、a2ensiteでサイトの設定ファイルをアクティブにして、systemctlでApache2を再起動し、certbotコマンドで証明書を作成する。証明書が正しく作成できれば、006-kc.confファイルのSSLCertificateFileとSSLCertificateKeyFileの前にある#を消しておき、改めてApache2をsystemctlで再起動する。もちろん、http://kc.inter-mediator.comにブラウザで接続して、証明書が正しく存在することは確認しよう。ここまでは、Keycloakとは関係のない、単にサーバ証明書を取得するための手順である。
sudo apt update
sudo apt upgrade
cd /var/www
mkdir kc
sudo chown www-data kc
sudo nano /etc/apache2/sites-available/006-kc.conf
# 006-kc.conf ファイルの内容をここで修正(証明書読み込み部分はコメント)
sudo a2ensite 006-kcsudo
systemctl restart apache2
sudo certbot certonly --webroot -w /var/www/kc -d kc.inter-mediator.com
sudo nano /etc/apache2/sites-available/006-kc.conf
# 006-kc.conf ファイルの内容をここで修正(証明書の読み込み部分を活かす)
systemctl restart apache2以下は最終的な006-kc.confファイルの内容である。もちろん、これは一例であって、皆さんはご自分のスタイルがあるだろうから、それに従って作ろう。ともかく、Let’s Encryptで証明書を作ってもらうためだけのサイトなのである。
<VirtualHost *:80>
ServerName kc.inter-mediator.com
ServerAdmin info@inter-mediator.org
DocumentRoot /var/www/kc
ErrorLog ${APACHE_LOG_DIR}/kc-error.log
CustomLog ${APACHE_LOG_DIR}/kc-access.log combined
RewriteEngine on
RewriteCond %{SERVER_NAME} =kc.inter-mediator.com
RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [END,NE,R=permanent]
</VirtualHost>
<VirtualHost *:443>
ServerName kc.inter-mediator.com
ServerAdmin info@inter-mediator.org
DocumentRoot /var/www/kc
ErrorLog ${APACHE_LOG_DIR}/kc-error.log
CustomLog ${APACHE_LOG_DIR}/kc-access.log combined
SSLCertificateFile /etc/letsencrypt/live/kc.inter-mediator.com/fullchain.pem
SSLCertificateKeyFile /etc/letsencrypt/live/kc.inter-mediator.com/privkey.pem
</VirtualHost>PostgreSQLのインストールと準備
KeyCloakは、データをPostgreSQLに溜め込むので、そのための準備が必要である。PostgreSQLをセットアップして、さらにデータベース側のユーザとデータベースを定義しておく必要がある。インストールは特に難しくはなく、aptで行う。その後に、システムに作られたpostgresユーザへのログインができるように、そのユーザにパスワードを設定する。ここでは書かないが、自分のパスワードはどこかにメモると良いだろう。その後、suでpostgresユーザに切り替わり、そしてpsqlコマンドでデータベースへのコマンド入力ができる状態にする。そして、CREATE USERとCREATE DATABASEのコマンドを入れる。PostgreSQLユーザのPASSWORDももちろん、独自に設定して自分で管理してもらいたい。
sudo apt install postgresql postgresql-contrib
sudo systemctl enable postgresql
sudo passwd postgres
# パスワードはきちんと把握しておく
su - postgres
psql
CREATE USER keycloak WITH PASSWORD 'PASSWORD' CREATEDB;
CREATE DATABASE keycloak OWNER keycloak;Keycloakのインストール
やっと、Keycloakをインストールする段階にきた。インストールは簡単だが、aptでインストールはできない。そして、まずはJavaのインストールも必要である。コンポーネントとしては若干複雑な構成のようだが、JavaとKeycloakのインストールがともかく必要になる。
sudo apt install openjdk-21-jdk
java -version
cd /var/www
wget https://github.com/keycloak/keycloak/releases/download/25.0.2/keycloak-25.0.2.tar.gz
tar zfxv keycloak-25.0.2.tar.gz
sudo nano keycloak-25.0.2/conf/keycloak.confJavaのインストールは良いとして、Keycloak自体は/var/wwwにインストールした。もちろん、好みの場所で良いだろうが、使っているサーバはインストールしたものが概ね/var/wwwにあるのでこのようにした。wgetの後のURLは、KeyCloakのWebサイトのDownloadのページにあるtar.gzファイルのリンクをそのまま利用した。そして、そのまま展開している。よって、KeyCloak本体は、/var/www/keycloak-25.0.2というディレクトリに展開された。
続いて、KeyCloakの設定ファイル「conf/keycloak.conf」を編集する。実際のファイルにはコメントが丁寧に細かく書かれているので、それを読みながら作業するのが良いと思われる。以下コメントとともにファイルの内容を記載する。
# Basic settings for running in production. Change accordingly before deploying the server.
# Database
# The database vendor.
db=postgres
# The username of the database user.
db-username=keycloak
# The password of the database user.
db-password=PASSWORD
# The full database JDBC URL. If not provided, a default URL is set based on the selected database vendor.
db-url=jdbc:postgresql://localhost/keycloak
# Observability
# If the server should expose healthcheck endpoints.
health-enabled=true
# If the server should expose metrics endpoints.
metrics-enabled=true
# HTTP
# The file path to a server certificate or certificate chain in PEM format.
https-certificate-file=${kc.home.dir}/conf/fullchain.pem
# The file path to a private key in PEM format.
https-certificate-key-file=${kc.home.dir}/conf/privkey.pem
# The proxy address forwarding mode if the server is behind a reverse proxy.
#proxy=reencrypt
# Do not attach route to cookies and rely on the session affinity capabilities from reverse proxy
#spi-sticky-session-encoder-infinispan-should-attach-route=false
# Hostname for the Keycloak server.
hostname=kc.inter-mediator.com最初のdbはこのまま、次のdb-username、db-passwordは、psqlコマンドで打ち込んだCREATE USERの時の情報をここに記載する。db-urlはこのままでOKである。HTMLセクションの最初の2つは、サーバ証明書である。ここにLet’s Encriptのディレクトリをそのまま書きたいところだが、そこはrootしかアクセス権がなく、KeyCloak自体をそのためのユーザで稼働することを考えているためその方法は使えない。そこで、証明書をKeyCloakの配下に以下のようにコマンドを入れてコピーすることにした。3ヶ月後はどうするかはまた考えるとして、とにかくこのようにした。なお、privkey.pemはユーザしか読み出しできないので、グループや全員に読み出し許可を与えている。
cd /var/www/keycloak-25.0.2/conf
sudo cp /etc/letsencrypt/live/kc.inter-mediator.com/privkey.pem .
sudo chmod a+r privkey.pem
sudo cp /etc/letsencrypt/live/kc.inter-mediator.com/fullchain.pem .KeyCloakを動かす
KeyCloakの起動スクリプトは、ディレクトリのbinにあるkc.shである。これをまずは起動してみる。とりあえず、サブコマンドにbuildを与えて、そしてサブコマンドstartで実際に起動する。出力結果を見ていてERRORがなければ大丈夫。そして、最後の方に、8443と9000ポートが開くメッセージがあるのでわかる。
cd /var/www/keycloak-25.0.2/bin
./kc.sh build
./kc.sh startそして、 https://kc.inter-mediator.com:8443 を開いてみる。すると以下のようなメッセージが見える。現状では管理者としてログインができないということを示している。
ここで、Ctrl+Cで一度止める。そして、記載の通り、環境変数に管理者のユーザ名、パスワードを指定して再度起動する。コマンドとしては次の通り。PASSWORDはもちろん、何か適当なパスワードを指定して、自分で記録管理しておく。
cd /var/www/keycloak-25.0.2/bin #カレントはKeyCloakの中のbinとする
export KEYCLOAK_ADMIN=admin
export KEYCLOAK_ADMIN_PASSWORD=PASSWORD
printenv|grep KEY #一応確認
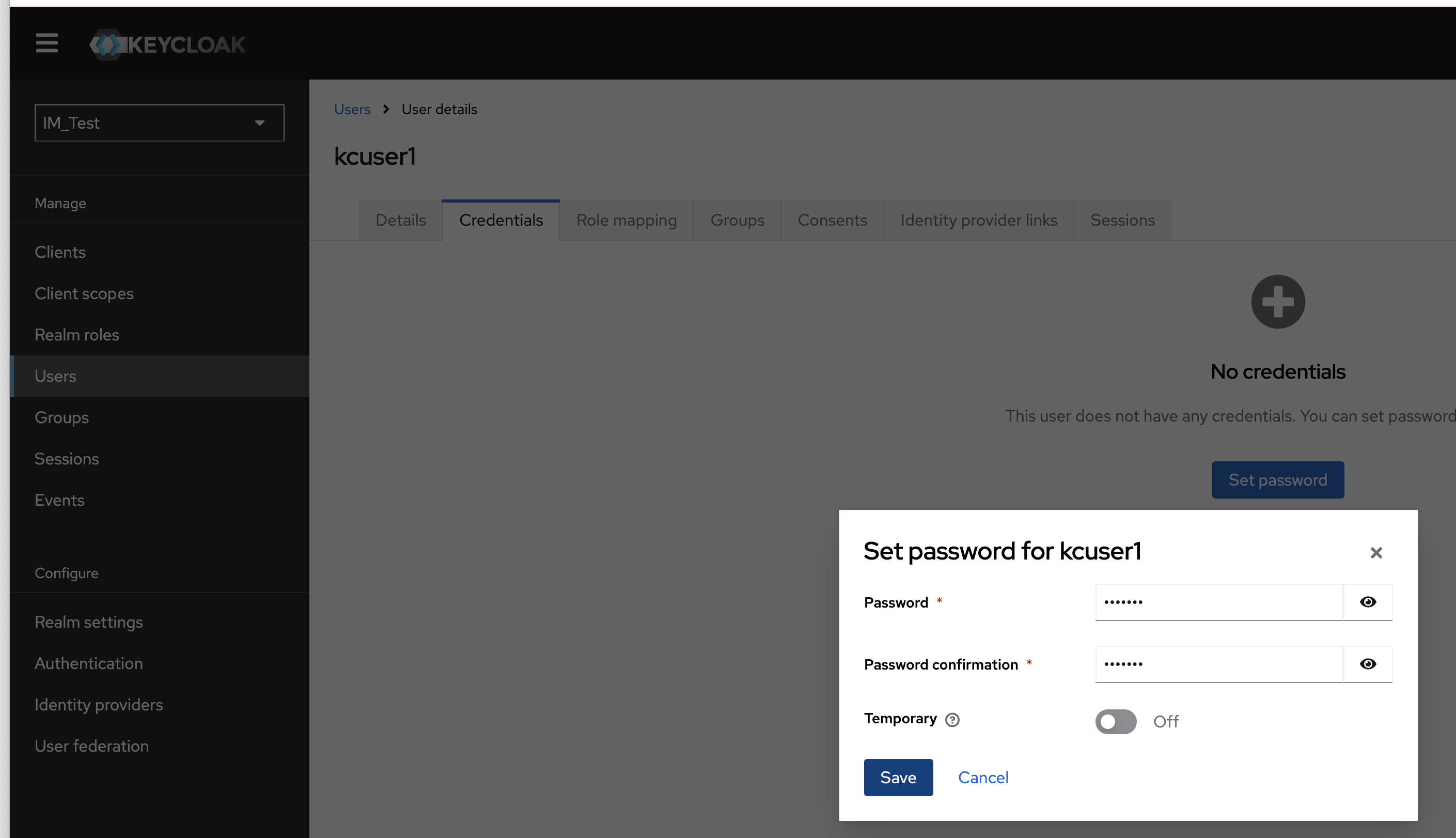
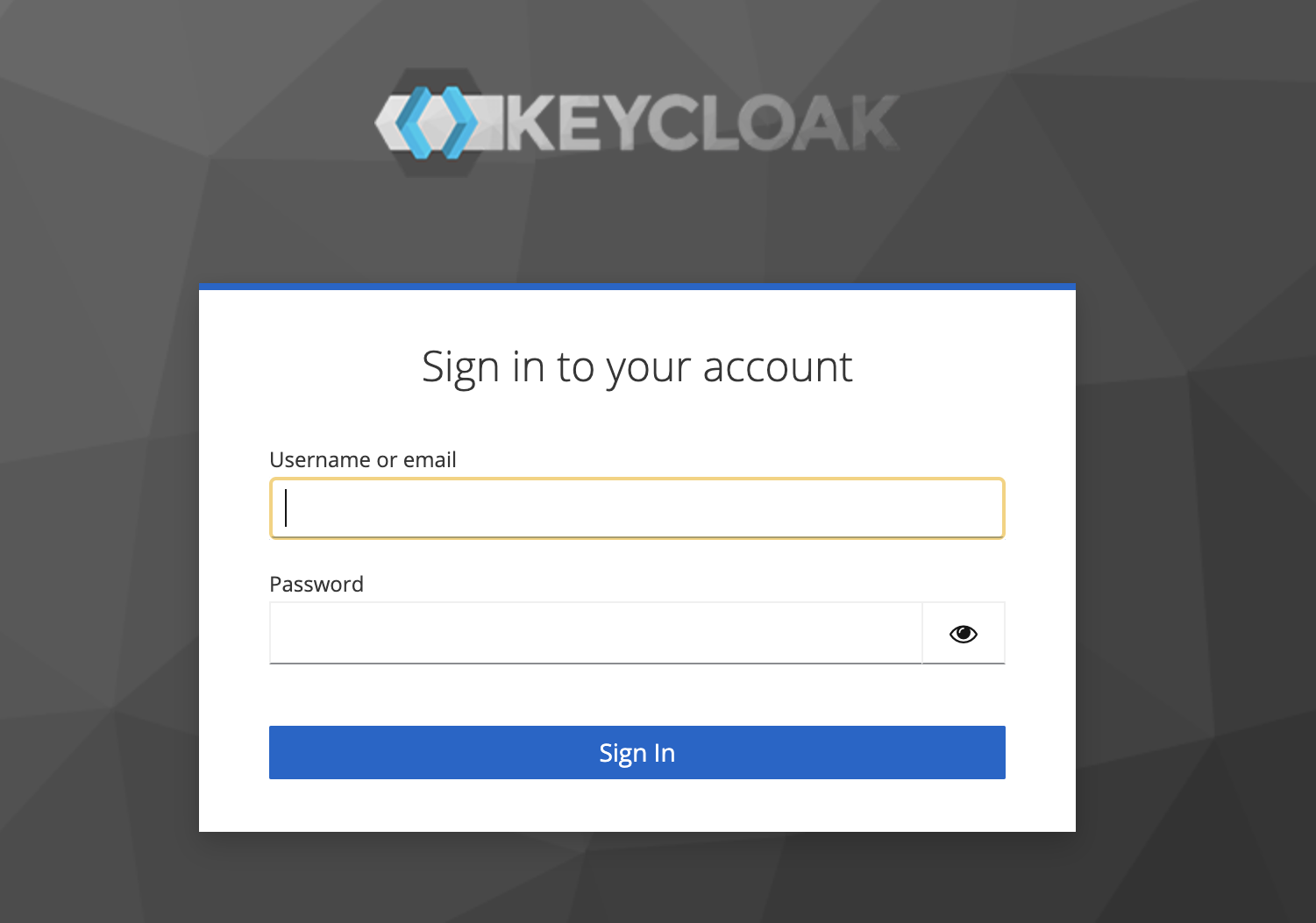
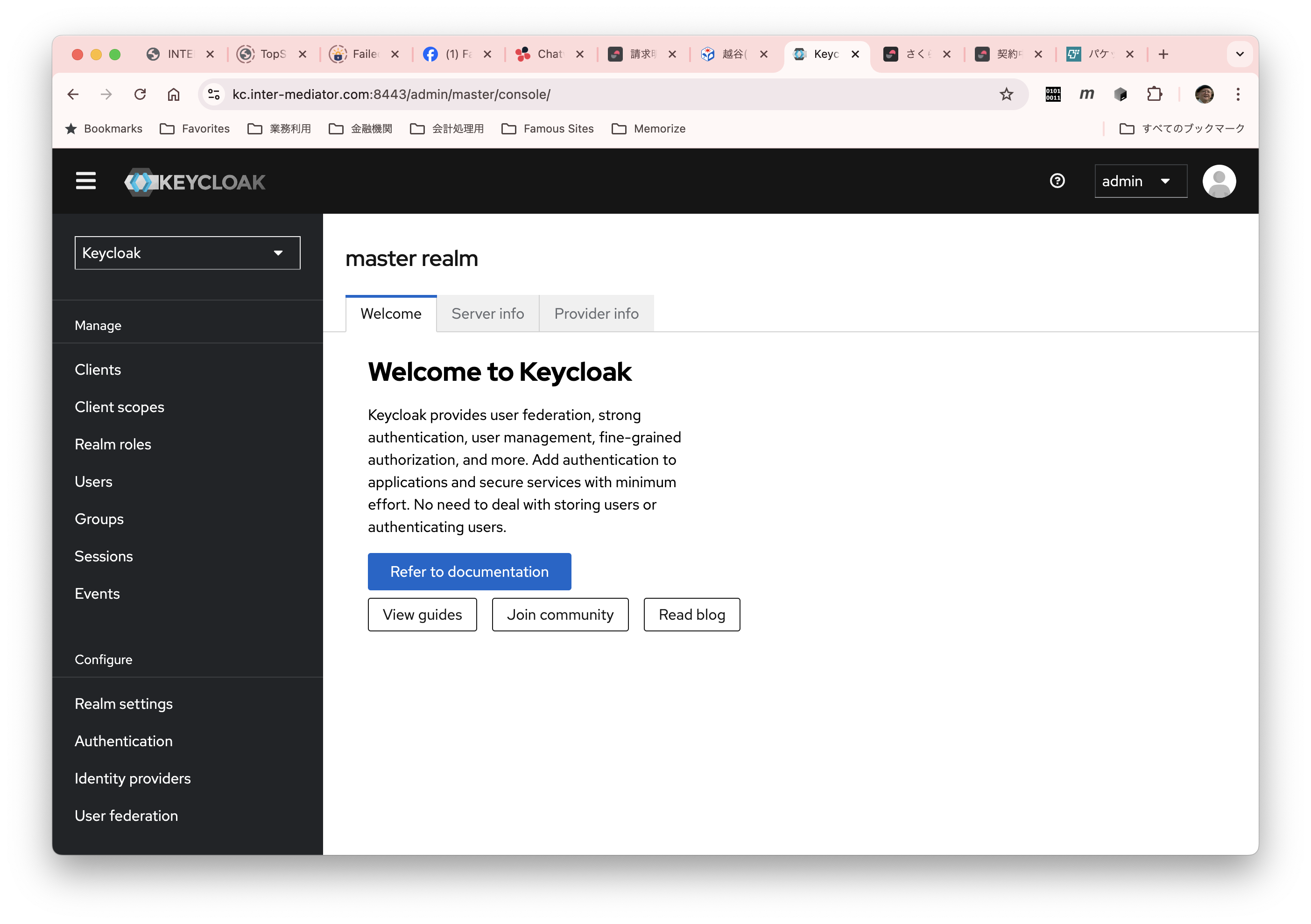
./kc.sh --verbose startすると、次のように、ログインパネルが表示され、ここで、admin/PASSWORDでログインができるはずである。ここまでで、基本的な動作確認ができた。
なお、環境変数にパスワードがある状態になるが、おそらくこの後にサービス化するので、再起動して後付けの環境変数は消えるはずである。このKEYCLOAK_*という2つの環境変数がある状態で、まだ管理者がない状態であれば、この環境変数の値を使って管理者ユーザを作成する。つまり、その瞬間にだけ環境変数があれば良いようで、その後は環境変数になくても管理者は存在し、ログインができるのである。
KeyCloakのサービス化
コマンドラインで起動した状態で使うというのはちょっと現実的ではないので、SystemCTL配下のサービスとして、バックグランドで自動起動するようにしたい。そのために、以下のようにコマンドを入れた(ほとんど前述のブログ記事の通り)。
sudo groupadd -r keycloak
sudo useradd -m -d /var/lib/keycloak -s /sbin/nologin \
-r -g keycloak keycloak
sudo nano /etc/systemd/system/keycloak.service
# ここで、新しいファイルが作られるので、以下のように記述する
sudo chown -R keycloak /var/www/keycloak-25.0.2
sudo systemctl enable keycloak.service
sudo systemctl start keycloak.service
systemctl status keycloak.serviceファイル「keycloak.service」については、以下のように作成した。おそらく調整ポイントは、WorkingDirectoryとExecStartのパスだけだろう。
[Unit]
Description=Keycloak Application Server
After=syslog.target network.target
[Service]
Type=simple
TimeoutStopSec=0
KillSignal=SIGTERM
KillMode=process
SuccessExitStatus=143
LimitMEMLOCK=infinity
SendSIGKILL=no
WorkingDirectory=/var/www/keycloak-25.0.2/
User=keycloak
Group=keycloak
LimitNOFILE=102642
ExecStart=/var/www/keycloak-25.0.2/bin/kc.sh start --log=console,file
[Install]
WantedBy=multi-user.targetコマンド入力について説明しておく。最初のgroupaddとuseraddコマンドでは、ユーザkeycloak、グループkeycloakを作成している。もちろん、keycloakユーザはkeycloakグループに所属させる。このユーザで、デーモンを動かすということである。ここでのKeyCloakが存在するディレクトリ/var/www/keycloak-25.0.2以下についても、keycloakユーザが所有者となるように、chownコマンドで設定している。useraddについては、-dでホームディレクトリを設定しているが、ここに何かを仕掛ける予定は特にない-mによりホームは自動的に作られる。シェルをnologinにしてあるので、ログインをしないことを想定している。-rはシステムアカウントとしてkeycloakを作る。実際にはIDは997で作られた。
実際のログファイルは、/var/www/keycloak-25.0.2/data/log/keycloak.logとなる。つまり、KeyCloakのディレクトリ以下、data/logの場所に作られる。この内容は、kc.shで起動した時に画面で見えるのと同じである。なお、systemctlコマンドではログの一部はアクセス権がないということで出てこないが、ログの場所がわかっていれば問題ないだろう。
ということで、無事にKeyCloakが起動した。
(1)はここまでとする。