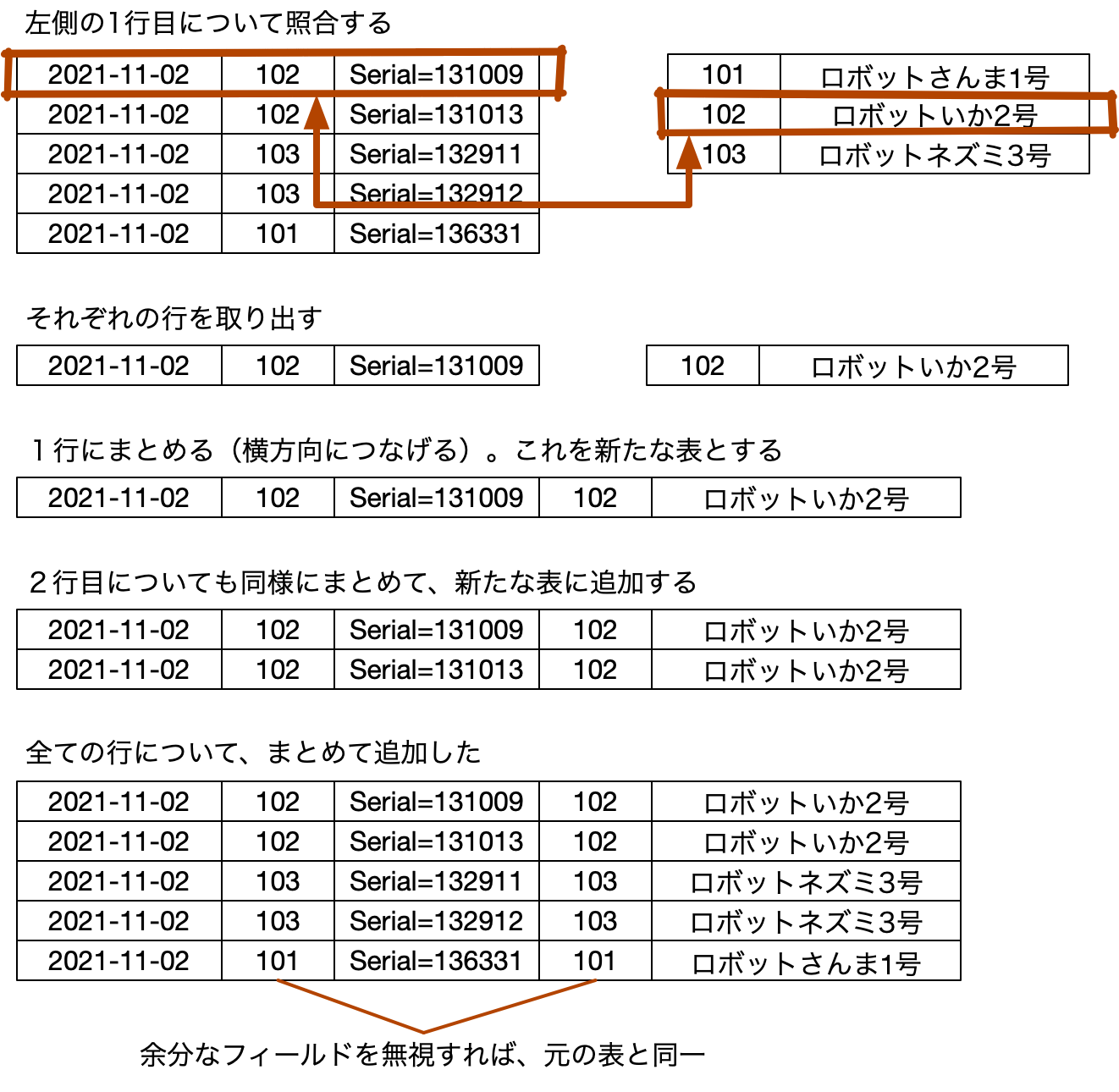
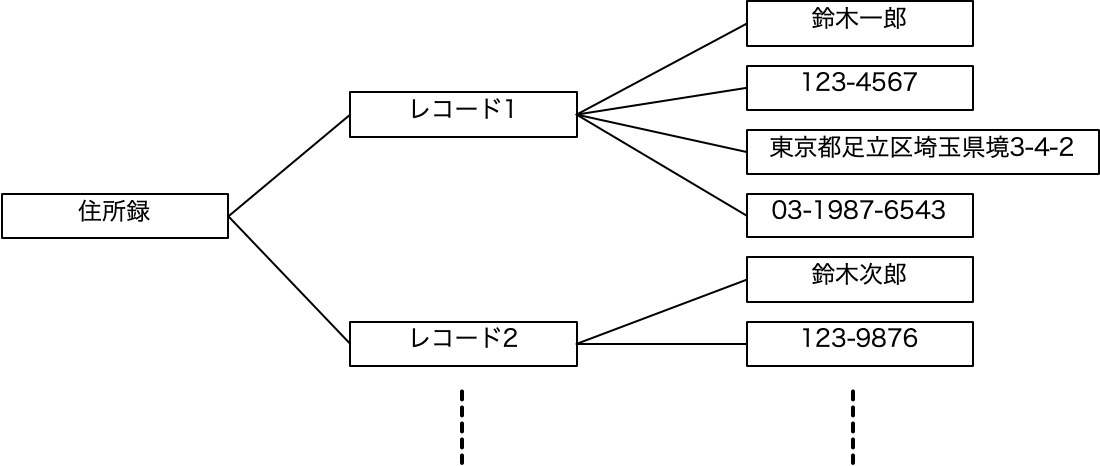
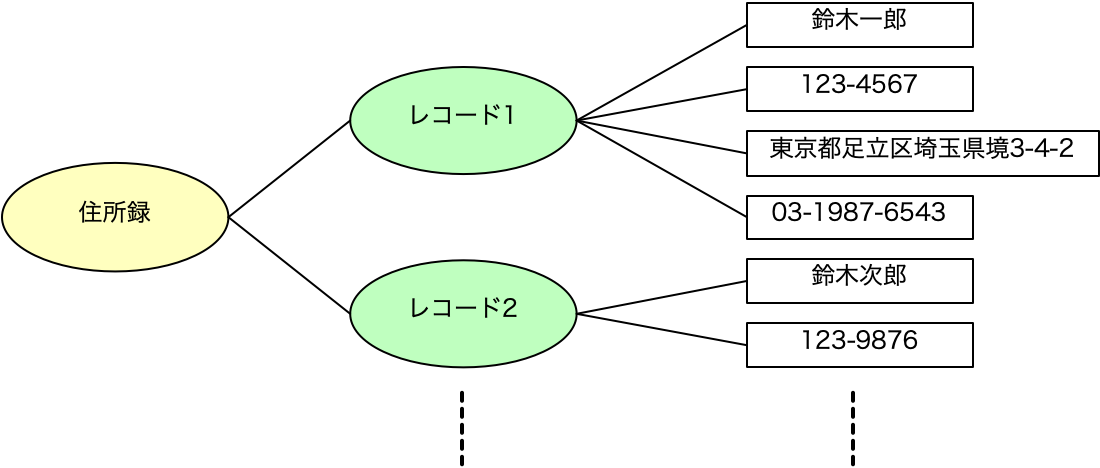
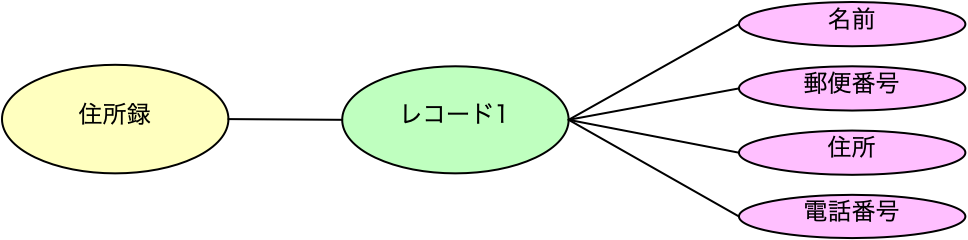
ちょっと、閑話休題的な話にしましょう。データベースの教科書では、集合論の話から入るいわば数学的な議論を土台にした解説が進められます。しかしながら、実際にデータベースを使い、設計をする上で、そのデータベースの教科書に書かれていることと、実用的なノウハウとの間に隔たりが大きいことに気付く人も多いでしょう。隔たりというか、世界が違い過ぎるというイメージを持つと思います。また、第3正規形などの考え方を学ぶのですが、それらの知識だけでは設計をこなすには遠いと思う人も多いようです。データベースの理論や数学は不要なのでしょうか? もちろん、不要とは言い切れないのですが、その辺り考えていることをまとめてみましょう。
まず、数学をベースにした理論は、初心者向けの情報ではないことは確かです。データベースの理論が数学をベースに組み立てられていることで、さまざまなことが高度に客観的に検証したり、証明したりということができるのです。つまり、数学がベースにあることで、確固した結論が得られていると考えられるというところがポイントです。よって、数学ベースの理論は無視はできないのです。厳密すぎて、最初の定義、つまり集合やドメインという話からリレーションの成り立ちまでの話はいきなり理解ができません。それはいきなりは理解できないのは当然だと思います。抽象度が高過ぎです。今時はデータベースシステムを手軽に組んで利用できる世界なので、むしろ、現実のデータをいじりながら理解し、一定のところまで理解したところで理論を勉強するというのが効率的な方法ではないかと思います。実際、私も、理論の書籍を最初に読んだ時には面食らいましたが、実際にいろんな製品を触って作ったりしている上で改めて理論の書籍を読むと、非常に頭に素直に入ってきたという経験があります。
データベースの設計におけるノウハウは、実はこうした理論に裏打ちされていると言ってもいいのですが、理論の世界で定義されていることは抽象度が高いために、打てば響く的なノウハウではないのは確かです。常に抽象度の高い世界で過ごすのは、さすがに専門家でも辛いですし、実システムは利用者あるいは発注者という存在がいるので、現実の世界に沿った説明をする必要も出てきます。その上で、いろいろな理解しやすくアレンジされたナレッジを多くの人は発案し、あるいは獲得するということをおこなってきたわけです。
そうしたナレッジが、理論の世界のどれと対応しているのかというのは、ある意味面白い話題です。表を分離するというのは第1正規形を適用しているとも言えます。しかし、直接関係してなさそうだけど、重要なナレッジもあると思うかもしれません。いずれ説明しますが、多対多の関係は中間テーブルを確保するという有名なノウハウがありますが、これは実際にそういう実装をせざるを得ないという工夫のノウハウでもあります。ただ、この手法自体は結果的に第3正規形になっているとも言えるわけで、要するに理論上での重要な結論は、必ずしも設計のナレッジのコアであるとは限らないのです。ただ、第4、第5正規形となると、これはちょっと狭い範囲の解決策ではないかとも思います。どんなデータベースでも、第5正規形の領域まで到達するということではありません。ただ、通常は第3正規形までは間違いなく到達していないと、どこかで矛盾が生じると思います。一方、マスターのデータをコピーして残しておくような処理、例えばFileMakerでのルックアップのような処理は、正規形による効率化とは逆行する面もあるものの、要求を満たすという意味で1つの選択肢になります。ただ、これも、逆に正規化が崩れている側面をどう評価するということを考えれば、やはり理論に基づいて考えを及ばせることができるとも言えるのではないでしょうか。この辺り、先々のネタで使います。
そういうわけで、私の一連のブログ記事は、プロの開発者でも、データベース設計となるとちょっと分からんという人や、あるいはそれなりに作れても自己流というか、持ち前の能力でうまくやってきたのが果たして正しい考え方なのかといった疑問を持っているような人に、設計時に何を考えればいいのかということを、理論とは異なる流れで説明をする試なのです。
ちなみに、理論や数学は学習する必要があるでしょうか? 真面目に設計をできるようになりたい方は、必ず勉強してください。よく分からなくても、ともかく頭に一度理論を流してください。忘れてもいいので、ともかく一度は勉強しましょう。そうすれば、ずっと先に、「あ、これはあのことか」というのがたまーに出てきます。それが基礎力というものではないかと思います。ただ、数学は若いうちに学習しましょう。中年以上になると、無理〜!と叫ぶことになります。私と同世代の老化著しい皆さんは、時間をかけて、そして欲張らずに勉強するしかないかと思います。