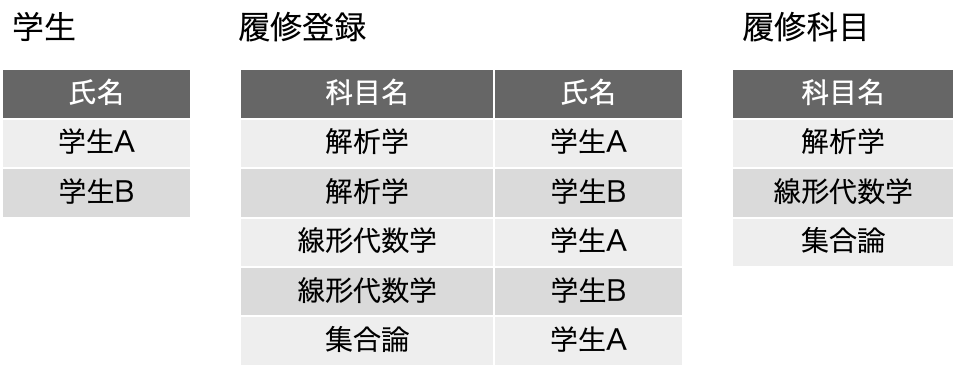
これまでに書いてきた内容の1つのまとめは、データの関連性を見つけて、複数の表に分けるということです。特に、1対多の関係を見つけて表に分割するということで、リレーショナルデータベースの設計につながることを説明しました。一方、それでは何を1レコードにするのかということも問題です。この関係を見つけるという問題と、何を1つの要素として見做すのかという問題は表裏一体のものでもあります。1レコードを見つける、そして、そのレコードの中の1つのフィールドを見つける、さらには1つの表は何かを見つけるといった問題を「素なデータを見つける」と示すことにします。
素とは、なんらかのルールで分割できないものです。有名なものは素数で、1とその数以外に、割り切れる整数がないような整数を示します。整数は、整数の掛け算で表現できます。12なら2 x 6 = 2 x 2 x 3 のようになりますが、11は、2から10までの数を考えれば、いずれも余りが出てしまうので割り切れる数はありません。ちなみに、2と3から5(つまり、11➗2 = 5…1なので)の奇数の整数でそれぞれ余りがないことを判定すれば11は素数であることは示すことが可能です。もっと一般的には、素数の列で順番にチェックするということになります。
この考え方をデータに割り当てて考えます。都道府県をともかく記録したいとします。正しくは {北海道, 青森県, 秋田県, …, 鹿児島県, 沖縄県} といった47種類の文字列のどれかが、どこかの都道府県を示しているとします。人間が都道府県を扱うと、「埼玉県」だけでなく、「埼玉」や場合によっては「さいたま」など、同一の都道府県名を示すと判断されそうなさまざまな表現が可能ですが(「さいたま市」があるのも知ってますよ、そこに住んでいるので)、ある世界(つまりはシステムの中の世界)では、都道府県の集合の要素でないものは、都道府県ではないと見做すとします。このとき、「北海道」や「埼玉県」を、素なデータと考えます。つまり、「埼」「玉」のように分割したものは存在せず、「埼玉県なる都道府県」のような余分な文字が増えたものも存在しない、あるいは「埼玉」のようになんとなくわかるとは言え、想定したデータと異なるものはないと考えます。
つまり、とり得るデータの集合を想定して、その中の1つの要素と同一のデータが素なデータと考えます。そして、表のフィールドには、素なデータが、1つだけあるか、場合によっては何もない(null=ナルと呼ぶ)かのどちらかになります。nullについては別の機会に説明しますが、要するに、「都道府県」というフィールドには、「埼玉県」というデータがあるなど、47都道府県の正式名があるということを期待し、「埼玉」や「滋賀」といった文字列はないことを期待します。この考え方はデータベースの世界では「ドメイン」と呼ばれたりしますが、つまりは、実用上のルールがフィールドに入るべきデータに宿っているのです。そういう意味で、データベースの理論はきちんと現実に起こることということを数学の理屈に組み込んでいます。ただ、数式を追うのではなく、要求をもとにしたシステムのあるべき姿を数学で記述をしているということになります。
都道府県はまだ有限なので考えやすいかもしれませんが、人間の名前はどうでしょう。姓でも名でも、都道府県の47要素の集合のような「全要素」を書き出すのはかなり難しいでしょう。また、それが全ての素な名前のデータを持った集合であるということの証明も難しいでしょう。都道府県名の場合は政府の資料等で定義はされているので、厳密に証明は可能だと思います。ただ、名前のように全要素が書き出すことは難しいものであっても、そのような全要素が仮想的にどこかに定義があって、フィールドに登場する値はそのどれかの要素であるような考え方をします。
もちろん、要素がわかっている場合、あるいは合理的に判定が可能な場合、その定義をもとにしてフィールドの値が正しいかどうかの判定もできます。よくある入力値の検査(バリデーション)はこの事実に基づいて行われているということです。
都道府県のフィールドについて、「埼玉県」はOKとして、そこに全要素からの2つ以上の要素がなんらかの方法で入力されていたとします。文字列として合成したということでもいいでしょう。例えば、「埼玉県<改行>千葉県」です。これらは全都道府県の集合から、2つの要素を持ち込んで、改行でつなげたものとなります。これを「都道府県」のフィールドに存在することは、おそらくどんなデータベースでも仕組み上は可能でしょう。文字列を記録できないデータベースはないからです。例えば、「会社」という表があって、都道府県フィールドに拠点のある都道府県を記録するとすれば、ある会社は本社は埼玉県、支社が千葉県ということもあります。
このような複数の都道府県が入っている場合、「都道府県」がドメインとすれば、重複があることで第一正規形を満たしていないとみなします。リレーショナルデータベースにおいては、第一正規形を満たす必要があるというのが根本的な考え方ですが、「記録さえできていればよく、このままでも問題ない」と判断されるのであれば、それはそれで正解な設計であるとも言えます。実は、第一正規形を満たしていないと何が悪いのかということが一般的に言えるかというと、それがかなり難しいです。よく言われている理由は「そうしないとデータベースに格納できない」ということがありますが、文字列処理を強引にやればなんでもできますし、また、FileMakerの繰り返しフィールドのような、第一正規形破りっぽく見える(実はそうだとも言えるし、そうでないとも言える)機能も、ある一定の範囲内では便利に使えます。
いずれにしても、ドメインの要素が複合的に存在する場合、少なくとも、その修正のためのアルゴリズムが複雑化しそうです。つまり、「埼玉県、千葉県」を「埼玉県、茨城県」に変えるという場合の処理が複雑になります。単一の要素だけなら「千葉を茨城に変える」というのは「茨城県」と上書きするだけです。ですが、複合的に存在する場合、現状のデータを読み出し、その中の消したい千葉県の範囲を識別して削除し、一方で、どこかに茨城県というデータを追加するという作業になります。また、「埼玉県」に拠点がある会社だけに絞るというのは、検索ロジックも複雑になります。都道府県では問題にならないかもしれませんが、ある要素は別の要素の一部分と同じというような場合(市区町村名で言えば、山陽小野田市と野田市のような関係)に一方だけを検索させるための「工夫」や「配慮」が必要になります。つまり、「野田市を含む」で検索すると、山陽小野田市も検索されそうです。市区町村が重複のないフィールドに入っていると「野田市であるデータ」と検索する、つまり完全一致で検索できるので、山陽小野田市は自ずと排除されるということになります。このように複合フィールドがあると、何かとデータ処理が面倒になりそうというのが大まかな言い方となるでしょうか。ただ、これらの問題も、頑張ってちゃんとプログラムを書けば大丈夫とも言えます。それに対して、複雑さは品質の低下を招く可能性がある!とこの辺りでほぼ喧嘩状態になりますね。
第一正規形はダメなのかどうかとういうと、その状態で、要求を満たしているのであれば、ダメとは言い難いと言っていいかと思います。むしろ、重要なのは第二、第三正規形への変換が、繰り返しのあるフィールドのデータについてはかなりやりにくくなるという点が第一正規形の意義なのではないかと思います。つまり、第一正規形は、素なデータに分解することで、テーブルの分離をスムーズに進めるというルールなのではないかと考えるのが妥当でしょう。
ちなみに、要求を満たせばなんでもいいのかというと、そこは微妙で、後々に変化する要求への対応が容易になるという点では、第一正規形への変換は必須と考えます。例えば、都道府県ごとの集計はしないと思っていても、後々したくなるかもしれません。大量のデータが集まった後に、フィールドに「埼玉県、千葉県」のような合成データがあったらどうでしょう? しばらく頭抱えるかと思います。もちろん、頑張れば対応できるのでしょうけど、同じような議論の繰り返しになります。フィールドに素なデータだけがある場合に比べて、そうした場合の対処が大きく違ってきます。リレーショナルデータベースの設計として正しいものは、その後のメンテナンス性に大きく影響するのです。このことをシステム開発の中で経験した方も多いでしょう。
今日は図がありませんでした。このままFacebookの近況に書き込むと、広告の画像が取り込まれるので、前回の図の1つを貼っておきます。