K-OFのイベントの1つとして、INTER-Mediatorのワークショップを2015年11月7日に開きました。ワークショップとなると、参加者の皆さんに手をうごしてもらって…というのが一般的ですが、その場で参加される方々もいらっしゃったので、手を動かすのはプレゼンターだけでやりました。
今回のワークショップでの開発目標は、イベントの参加申し込みです。別の勉強会での事後アンケートで、「こういうのを作りたい」と希望があり、それを題材にさせていただきました。グループカウンセリングを実施している赤石さんは、現在、フォームズというサービスで参加受付を行い、メールで送られてくる参加依頼の内容を1項目ずつコピー&ペースとしているそうです。当初は「コピペをしないで一発でExcelに入れる」という要望だったのですが、いっそのこと、受付フォームと一覧表示をINTER-Mediatorで作成するのはどうかということで了承していただき、それをワークショップの題材としました。なお、実際の運用サイトでは、以下のコード内にあるパスワードや一部の名称はもちろん変更しています。

設計内容とスキーマ
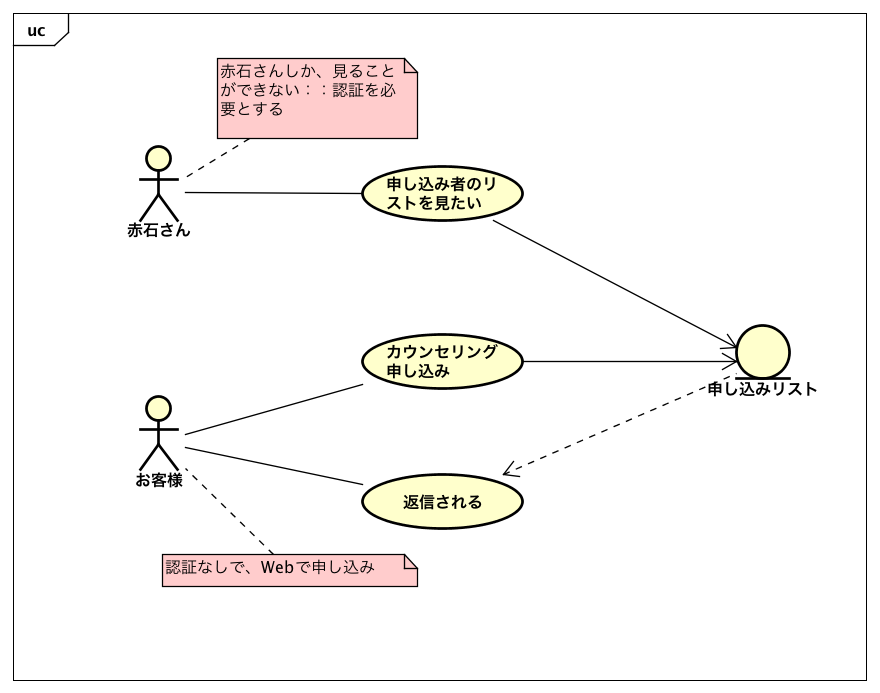
ざっくり書いたユーズケース図は次の通りです。アクターは、赤石さんと、グループカウンセリングに参加される「お客様」の2つです。お客様はブラウザで申し込みをして、その結果をメールで受け取ることになります。その申し込み結果を「申し込みリスト」に蓄積して、それを赤石さんは随時チェックするという流れになります。この時、お客様は認証等なく申し込みを行えるようにしますが、一方で赤石さんしかリストが見れないようにします。ここで、データベースへの新規レコードは認証なし、その他の処理は認証を行わないとできないようにするという基本設計もできてしまいます。また、システムとアクターの接点は2か所あり、それぞれ1ページだけで実現しそうなので、合計2つのWebページの作成で済みそうです。
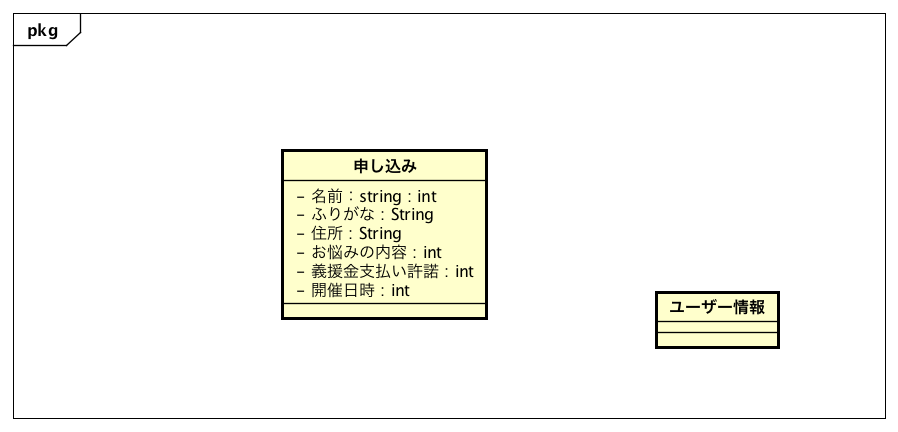
ER図と同じ用途のクラス図は次のようになります。ちょっとシンプルですが、「申し込み」という1つのテーブルで作ります。本来、グループカウンセリングの実施が1つのエンティティになり、カウンセリングのテーブルを作成して、申し込みとイベントが多対1の関係を作ります。現状では1種類のイベントを、シーケンシャルに、つまり同時に複数のイベントの募集をしているといった事情もないので、1テーブルで運用します。言い換えれば、イベントには「開催日時」というフィールドしかないので、別テーブルにする必要性は薄いということです。「義援金支払い許諾」はチェックボックスで、受講条件の1つを許諾するかどうかを明確にするものです。「ユーザー情報」は、INTER-Mediatorで認証を実施するために必要なテーブル群です。
これらを実現するMySQL用スキーマとして、以下の記述を作成しました。実はワークショップでは、これに失敗して悩んでしまったのですが、今後のワークショップはこれを雛形にしましょう(苦笑。ユーザーやデータベースを定義してアクセス権を設定し、applyテーブル(クラス図での「申し込み」)を定義します。その後の、authuser、authgroup、authcor、issuedhashのテーブルは認証で必要とするものです。リスト表示の時に使用するuser1ユーザーのみ定義しています。
SET NAMES 'utf8mb4';
#DROP USER 'web'@'localhost';
CREATE USER 'web'@'localhost' IDENTIFIED BY 'password';
DROP DATABASE IF EXISTS akaishi;
CREATE DATABASE akaishi CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE akaishi;
GRANT SELECT, INSERT, DELETE, UPDATE ON TABLE akaishi.* TO 'web'@'localhost';
CREATE TABLE apply (
apply_id INT AUTO_INCREMENT,
name VARCHAR(100),
yomi VARCHAR(100),
email VARCHAR(100),
address VARCHAR(255),
content TEXT,
agreement INT,
startdt DATETIME,
PRIMARY KEY(apply_id)
) CHARACTER SET=utf8mb4, COLLATE=utf8mb4_unicode_ci, ENGINE=InnoDB;
CREATE TABLE authuser (
id INT AUTO_INCREMENT,
username VARCHAR(48),
hashedpasswd VARCHAR(48),
email VARCHAR(100),
limitdt DATETIME,
PRIMARY KEY(id)
) CHARACTER SET=utf8mb4, COLLATE=utf8mb4_unicode_ci, ENGINE=InnoDB;
INSERT authuser SET id=1,username='user1',hashedpasswd='d83eefa0a9bd7190c94e7911688503737a99db0154455354';
CREATE TABLE authgroup (
id INT AUTO_INCREMENT,
groupname VARCHAR(48),
PRIMARY KEY(id)
) CHARACTER SET=utf8mb4, COLLATE=utf8mb4_unicode_ci, ENGINE=InnoDB;
CREATE TABLE authcor (
id INT AUTO_INCREMENT,
user_id INT,
group_id INT,
dest_group_id INT,
privname VARCHAR(48),
PRIMARY KEY(id)
) CHARACTER SET=utf8mb4, COLLATE=utf8mb4_unicode_ci, ENGINE=InnoDB;
CREATE TABLE issuedhash (
id INT AUTO_INCREMENT,
user_id INT,
clienthost VARCHAR(48),
hash VARCHAR(48),
expired DateTime,
PRIMARY KEY(id)
) CHARACTER SET=utf8mb4, COLLATE=utf8mb4_unicode_ci, ENGINE=InnoDB;
申し込みページの作成
まず、お客様がイベントの申し込みを行うページを作ります。コンテキストの定義を含む定義ファイル(apply.php)は以下のようなものです。ポストオンリーモードでのページを作成すればいいので、コンテキストは1つだけです。また、新規レコードは認証なしで、その他のデータベース処理はできないようにしたいので、存在しないユーザー(nobodyknows)に対してのみ読み出し、更新、削除ができるようにして、事実上、これらの3つの処理は行えないようにします。authenticationキーにcreateキーの値がないので、createに関しては認証なく実施できます。オプション指定はなく、データベース指定のところに、dsn、user、passwordのキーで、データベースへの接続についての記述を行っています。
<?php
require_once('../INTER-Mediator/INTER-Mediator.php');
IM_Entry(
array(
array(
'name' => 'apply',
'table' => 'apply',
'view' => 'dummy',
'key' => 'apply_id',
'post-reconstruct'=>true,
'authentication' => array(
'read' => array('user' => 'nobodyknows'),
'update' => array('user' => 'nobodyknows'),
'delete' => array('user' => 'nobodyknows'),
),
'send-mail' => array(
'create' => array(
'from-constant' => "msyk@msyk.net",
'cc-constant' => "msyk@msyk.net",
'subject-constant' => "申し込みを受け付けました",
'to' => "email",
'body-template' => "confirm.txt",
'body-fields' => "name,yomi,email,address,content,startdt",
),
),
),
),
array(),
array(
'db-class' => 'PDO',
'dsn' => 'mysql:host=localhost;dbname=akaishi;charset=utf8mb4',
'user' => 'web',
'password' => 'password',
),
false
);
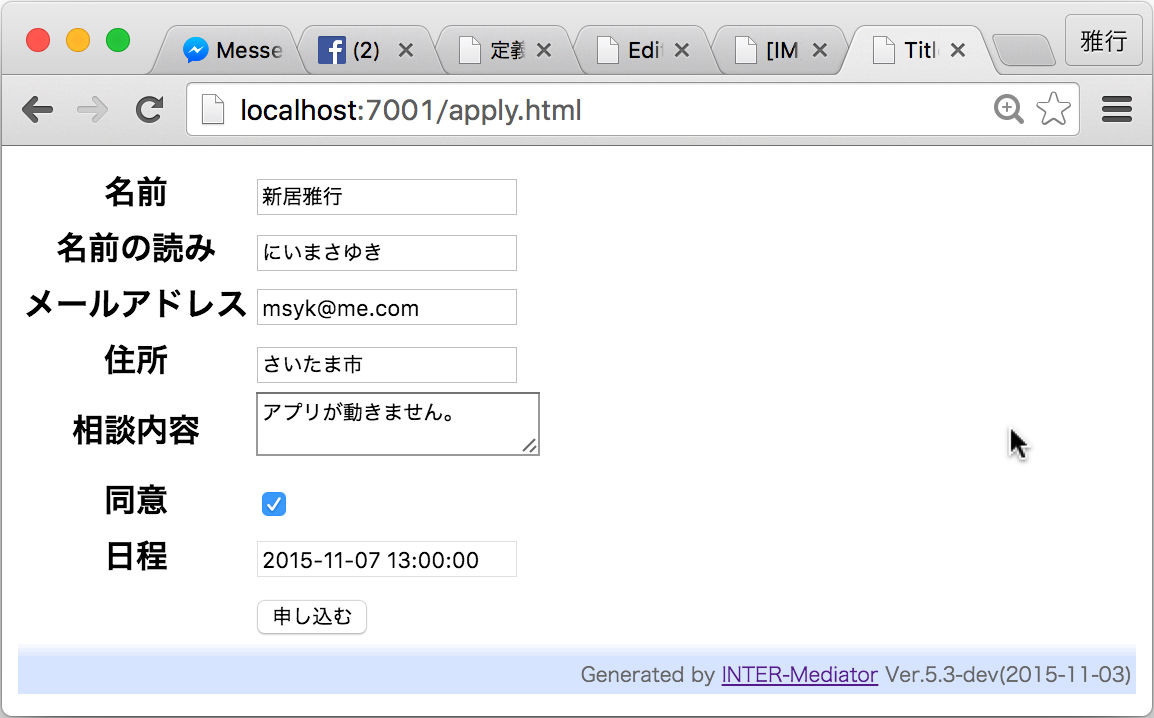
お客様が申し込みを行うページのぺージファイル(apply.html)は次のように定義しました。見出しの文字列は最低限にしていますが、実運用の時には書き直して利用していただくとして、INTER-Mediatorの動作に関わる部分だけを作ってあります。ヘッダ部での定義ファイルの読み込み、BODYタグのonload属性でのフレームワーク呼び出し、そしてボディ部での記述がポイントになります。ボディ部では、TABLEタグによるテーブルが定義されていますが、data-im-control属性により、ポストオンリーモードであることが指定されています。あとは、コンテキストとフィールド名のセットをdata-imに記述します。同意の項目はチェックボックスですが、value=1の指定があり、チェックがあれば1をフィールドに設定します。カウンセリングの日付はstartdtフィールドにしますが、ここの部分はお客様が入力するのではなく、募集するときに日時が決定しているので、その日時を初期値として規定し、INPUTタグ自体はreadonly属性を設定して、表示だけをするようにします。最後のBUTTONもdata-im-control属性を指定して、書き込みボタンにします。なお、定義ファイルのコンテキストにはpost-reconstructキーのみがあり、この場合は書き込みを行うとこのページの再ロードを行うので、そこで入力した結果が消えます。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script type="text/javascript" src="apply.php"></script>
</head>
<body onload="INTERMediator.construct();">
<table>
<tbody data-im-control="post">
<tr>
<th>名前</th>
<td><input type="text" data-im="apply@name"/></td>
</tr>
<tr>
<th>名前の読み</th>
<td><input type="text" data-im="apply@yomi"/></td>
</tr>
<tr>
<th>メールアドレス</th>
<td><input type="text" data-im="apply@email"/></td>
</tr>
<tr>
<th>住所</th>
<td><input type="text" data-im="apply@address"/></td>
</tr>
<tr>
<th>相談内容</th>
<td><textarea data-im="apply@content"></textarea></td>
</tr>
<tr>
<th>同意</th>
<td><input type="checkbox" value="1" data-im="apply@agreement"/></td>
</tr>
<tr>
<th>日程</th>
<td><input type="text" data-im="apply@startdt"
value="2015-11-07 13:00:00" readonly/></td>
</tr>
<tr>
<th></th>
<td><button data-im-control="post">申し込む</button> </td>
</tr>
</tbody>
</table>
</body>
</html>
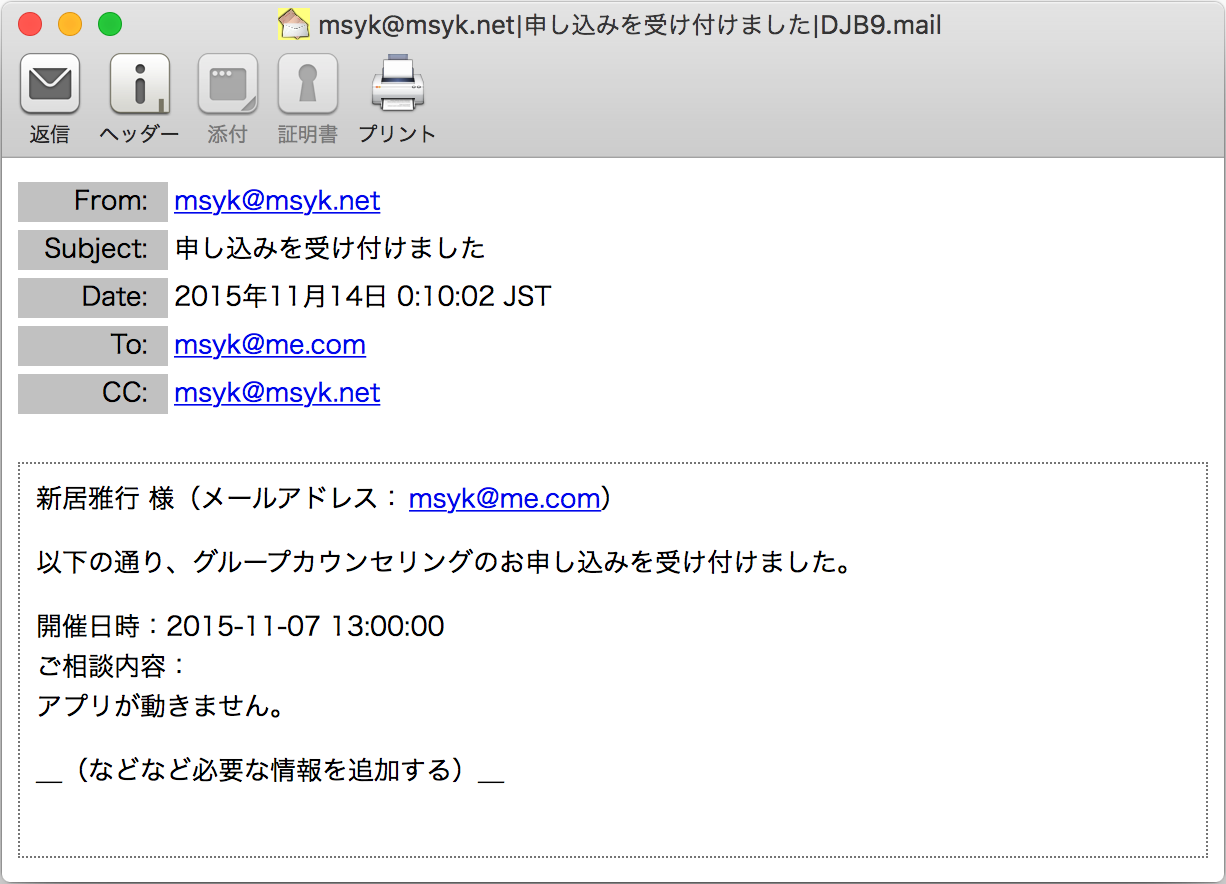
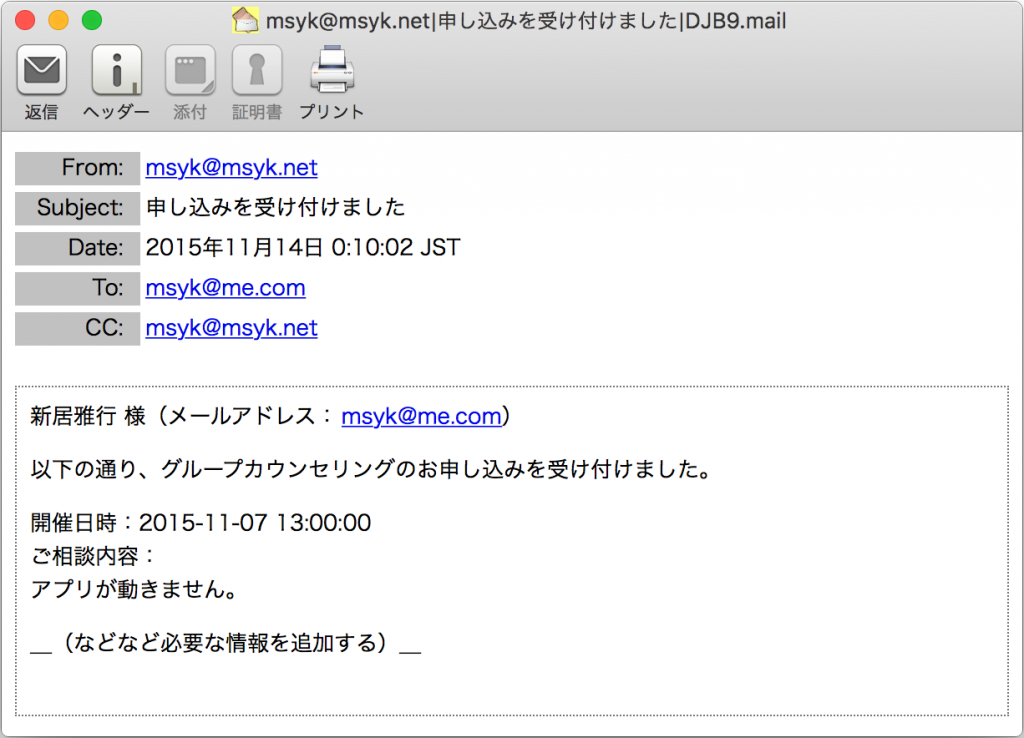
定義ファイルapply.phpのコンテキストには、レコードを作成した時にメールを送信する設定が組み込まれています。そのためのメールの文面は、confirm.txtファイルに以下のように用意します。メールについては、定義ファイルでの定義通り、差出人、CC、件名は決められたものを設定し、送り先は作成されたレコードのemailフィールドを指定します。本文は、以下のconfirm.txtの中の@@1@@などの部分が新規に作成されたレコードの値に置き換わります。body-fieldsキーの値に列挙されたフィールドとその順番より、@@1@@が名前、@@3@@がメールアドレス、@@5@@が相談内容、@@6@@が開催日時を示します。
@@1@@ 様(メールアドレス:@@3@@)
以下の通り、グループカウンセリングのお申し込みを受け付けました。
開催日時:@@6@@
ご相談内容:
@@5@@
_(などなど必要な情報を追加する)_
作成したページは次のようなものです。
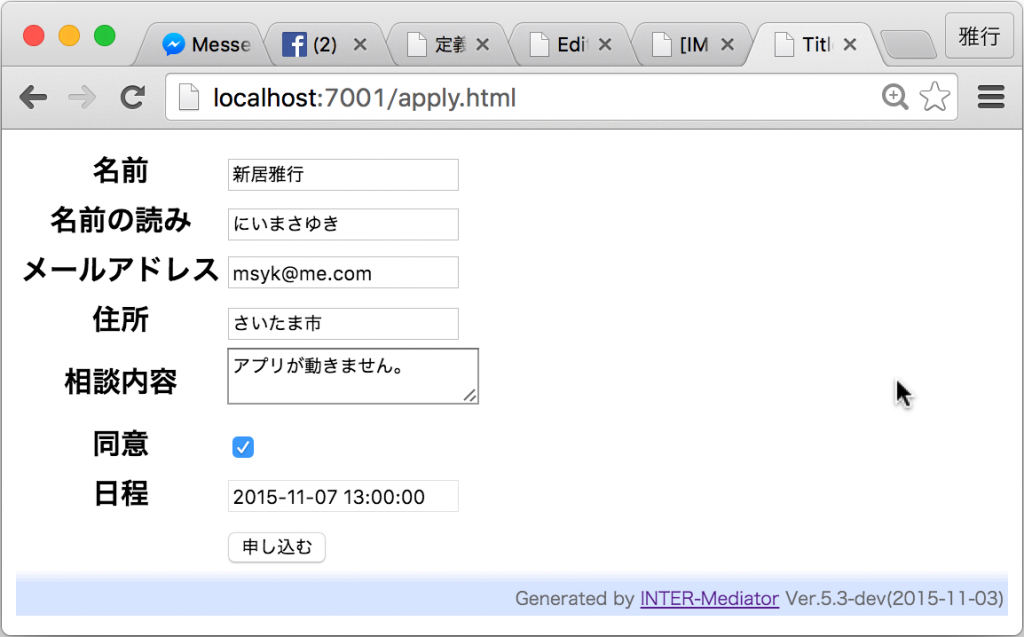
申し込みを行うと、入力したメールアドレスに、確認のメールが送られます。
一覧ページの作成
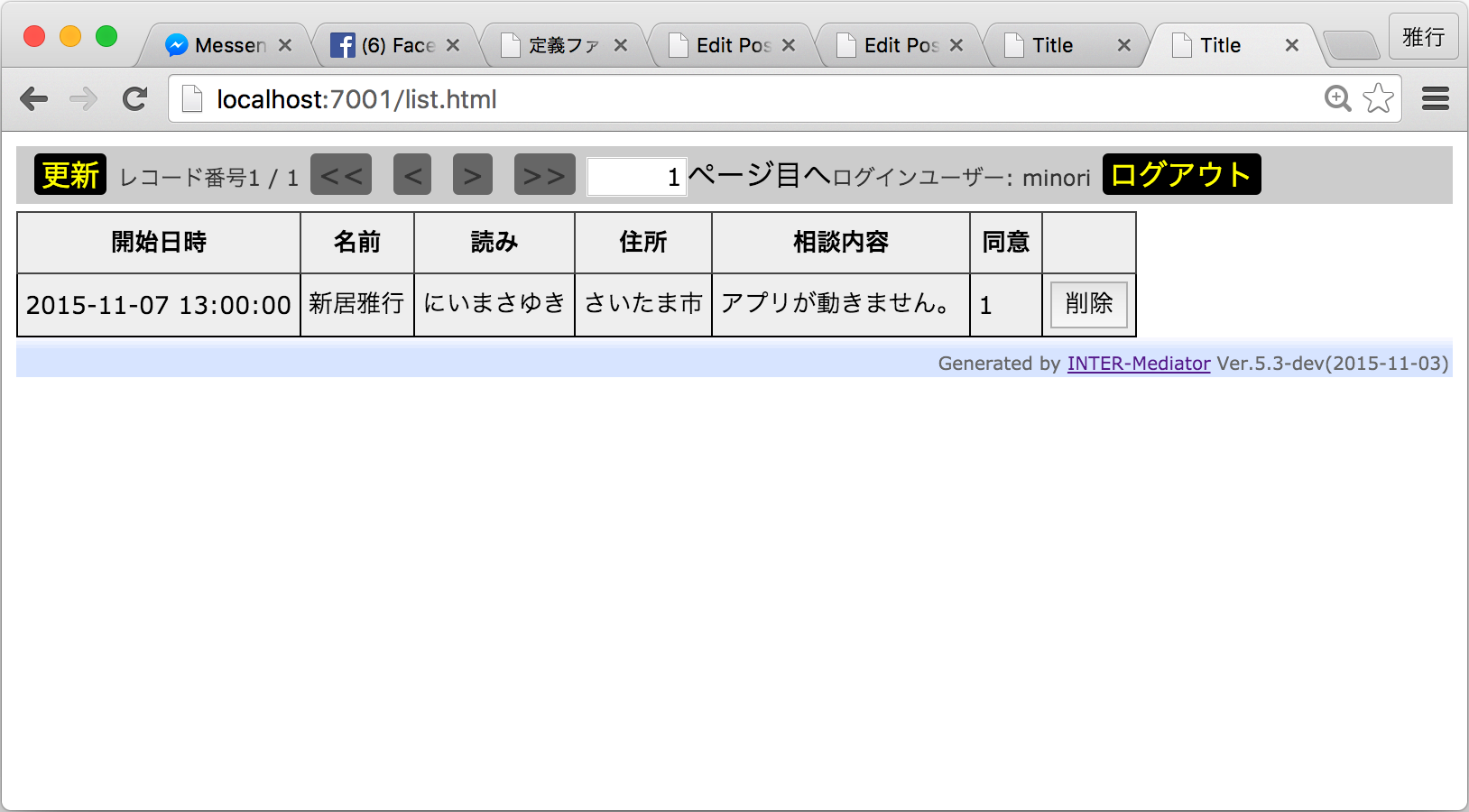
一覧ページを構成するために、以下のような定義ファイル(list.php)を作成しました。こちらは、applyテーブルの内容を参照したり、場合によっては変更や削除等があるので、すべてのデータベース操作に対して、user1で認証したユーザーだけが許可されるようにしました。また、開催日の逆順で一覧されることで、最近の開催日に対する参加者がリストの上部にまとまるようにしました。コンテキストには、削除ボタンの追加の指示はありますが、挿入ボタンはありません。挿入ボタンは、必要ならapply.htmlから自分で申し込みを入れてそれを修正すればいいと考えました。
<?php
require_once('../INTER-Mediator/INTER-Mediator.php');
IM_Entry(
array(
array(
'name' => 'apply',
'table' => 'apply',
'view' => 'apply',
'key' => 'apply_id',
'paging' => true,
'records' => '20',
'repeat-control' => 'confirm-delete',
'sort' => array(
array('field' => 'startdt', 'direction' => 'desc'),
),
'authentication' => array(
'all' => array('user' => 'user1'),
),
),
),
array(),
array(
'db-class' => 'PDO',
'dsn' => 'mysql:host=localhost;dbname=akaishi;charset=utf8mb4',
'user' => 'web',
'password' => 'password',
),
false
);
一覧のページファイル(list.html)は以下の通りです。特に変わったところはなく、applyコンテキストの内容をページネーションとともに表示をしています。コンテキスト定義にあるように、20レコードずつ表示をします。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<link rel="stylesheet" href="INTER-Mediator/Samples/sample.css" />
<title>Title</title>
<script type="text/javascript" src="list.php"></script>
<style>
td{
border: solid 1px black;
}
</style>
</head>
<body onload="INTERMediator.construct();">
<div id="IM_NAVIGATOR"></div>
<table>
<thead>
<tr><th>開始日時</th><th>名前</th><th>読み</th>
<th>住所</th><th>相談内容</th><th>同意</th><th></th></tr>
</thead>
<tbody>
<tr>
<td data-im="apply@startdt"></td>
<td data-im="apply@name"></td>
<td data-im="apply@yomi"></td>
<td data-im="apply@address"></td>
<td data-im="apply@content"></td>
<td data-im="apply@agreement"></td>
<td></td>
</tr>
</tbody>
</table>
</body>
</html>
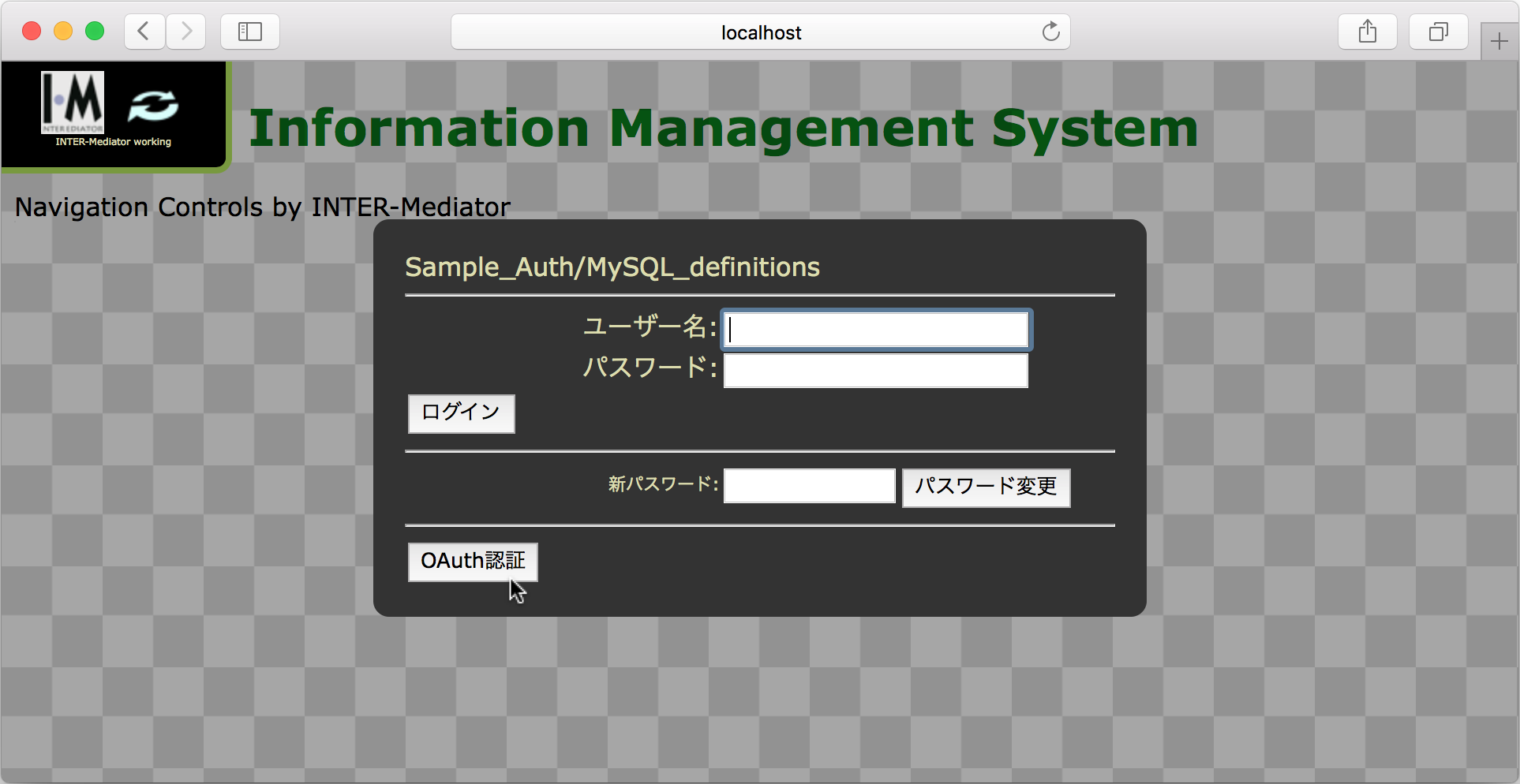
ページを表示すると、ログインパネルが表示されます。
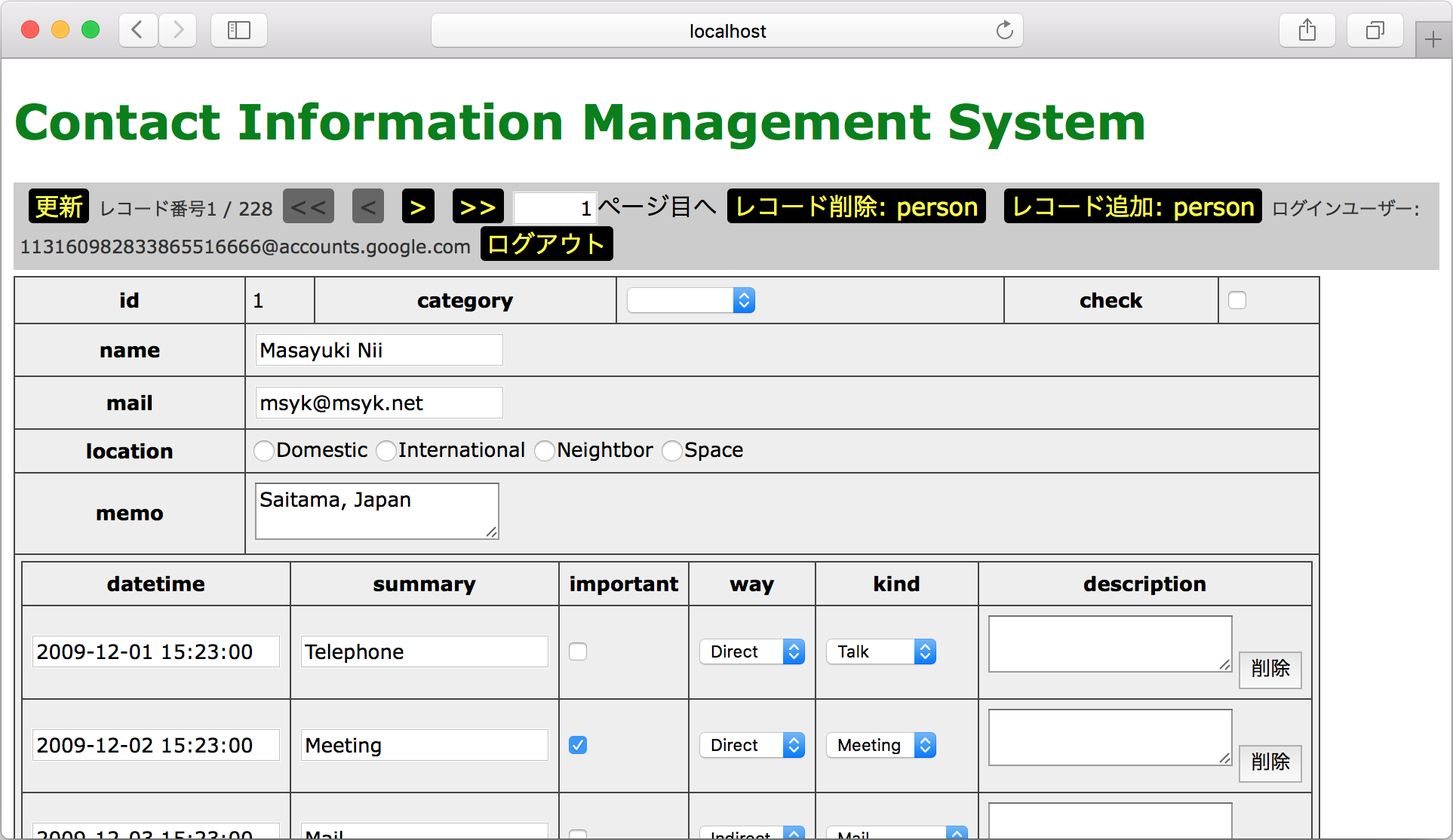
正しいユーザー名とパスワードを入力してログインすれば、リスト形式で、申込者の一覧を見ることができます。
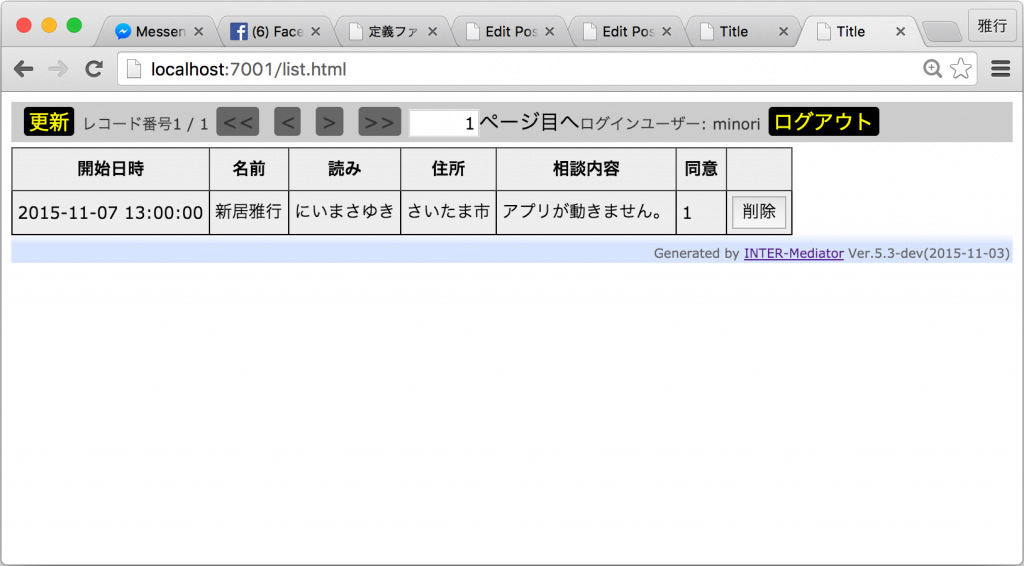
ワークショップを終えて
結果的にワークショップでは、入力専用(ポストオンリーモード)のページと、その入力した結果を表示するための2つのページを作成しました。実際のワークショップでは凡ミスに気づかずちょっと時間を無駄しにしてしまって申し訳なかったのですが、通常ではこれくらいであれば1時間程度の作業で行えるということが示せたかと思います。また、典型的なシステム開発の流れも見ていただけるサンプルになったかと思います。
なお、こうして作ったシステムも、作ってから新たなニーズが発生するかと思います。そうした追加の要求や変化する要求についても追跡させてもらって、可能な限り、アフター・ワークショップとしてお伝えできればと考えています。