今回は、ある意味、分割しない方が良さそうな表のサンプルを見てみることにしましょう。その表は、ボイス-コッド正規形ではありますが、分割する方が更新不整合が起きるというか、分割することでかえってデータのメンテナンスが大変になりそうな事例です。なお、今回の事例は、完全に自分で考えたもので、どこかにあるものをアレンジしたものではないため、もしかしたら、間違いがどこかに潜んでいるかも知れません。間違っていたら、遠慮なく教えてください。
以下、「会議室予約」という表があります。前提として、ある組織で、会議室が101〜103まで3室あります。利用部門はA, B, C, 外部の4つになっています。時間枠は原則として1時間としてありますが、現実的な制限として、1日あたり7:00〜18:00までの12枠あるとしましょう。まず、会議室を利用したい場合には、この表にレコードを作るということが原則です。皆さんの会社のように、予約せずに使うわ、予約したのに使ってないわ、一覧表は更新されてないわ、ということはないということでお願いします。
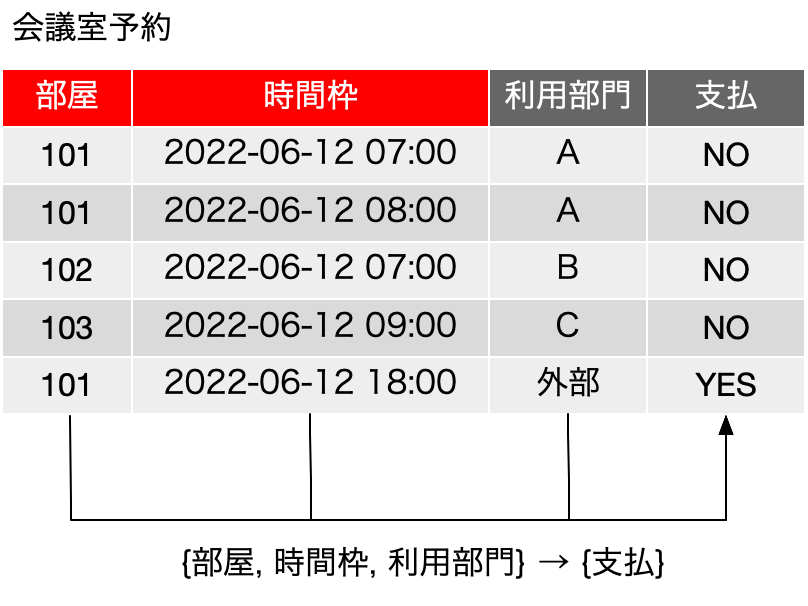
ここで、当たり前の制限として、同一の部屋、同一の時間枠で、複数の部門が使うことはないという前提にします。つまり、部屋と時間枠が決まれば、利用部門が決まるということです。すなわち、{部屋, 時間枠} → {利用部門}という関数従属があるというのがビジネスルールから決まっているということです。ここにレコードのない時間枠は誰も予約していません。また、言い換えれば、部屋と時間枠がいずれも同一の2つのレコードは存在していないという意味です。
一方、支払はさらに厄介です。支払に関しては、なぜかこの会社が不思議なルールを持っていて、利用部門が外部の場合、101と102室に関して、17:00以降の時間枠であれば、お金を取るということが決まっています。支払はYESないしはNOで示していますが、実質的には論理値です。つまり、支払がYESかNOかを決めるには、部屋、時間枠、利用部門の情報が必要です。1つでも欠ければ、判定できません。ということで、{部屋, 時間枠, 利用部門} → {支払} という関数従属があるという考え方ができます。
利用部門と支払に関する関数従属があり、以下それぞれを(1)と(2)としてここからアームストロングの公理系を適用すると、以下のような結論が出てきます。
{部屋, 時間枠} → {利用部門} (1)
{部屋, 時間枠, 利用部門} → {支払} (2)
(1)に増加律を適用すると、次が成り立つ
{部屋, 時間枠}⋃{利用部門} → {利用部門}⋃{利用部門}
すなわち次の通りまとめられる。
{部屋, 時間枠, 利用部門} → {利用部門} (3)
合併律を(2)と(3)に適用することで、
{部屋, 時間枠, 利用部門} → {利用部門, 支払} (4)
(1)に増加律を適用すると、次が成り立つ。
{部屋, 時間枠}⋃{部屋, 時間枠} → {利用部門}⋃{部屋, 時間枠}
すなわち次のようにまとめられる。
{部屋, 時間枠} → {利用部門, 部屋, 時間枠} (5)
(4)と(5)を推移律に適用することで、次の結果が得られる。
{部屋, 時間枠} → {利用部門, 支払}
全てのフィールドが関数従属の定義に登場しており、{部屋, 時間枠}が候補キーであることを示している。つまり、{部屋, 時間枠} が残りのフィールドの値を確定できるので、候補キーはこれになり、当然ながら、主キーも同一のものとなります。(2)の関数従属も、よくみると、全部のフィールドが登場しているので、候補キーの1つとして{部屋, 時間枠, 利用部門}が言えるということになりそうですが、{部屋, 時間枠} は {部屋, 時間枠, 利用部門} の部分集合なので、「最小構成のフィールドのセット」という考え方を使うと、{部屋, 時間枠, 利用部門}の3つのフィールドのセットには冗長なものがあるということになり、候補キーからは外れることになります。ということで、主キーも候補キーも、{部屋, 時間枠}という集合だけということになります。もちろん、{部屋, 時間枠, 利用部門}は、候補キーにフィールドを追加したものと見ればスーパーキーになります。
ここで、ボイス-コッド標準形の定義として、初期の頃の「候補キーからの関数従属しかない」という定義ではなく、のちに改められた「スパーキーからの関数従属ないしは自明な関数従属しかない」という定義があることを紹介します。自明な関数従属とは、X → Yにおいて、Y⊆Xの場合です。つまり、キーフィールドの一部がキーフィールドからの関数従属がある場合です。スーパーキーではなく、自明な関数従属であるという例を考え切れなかったので、今回は「全ての関数従属性はスパーキーをキーとするものである」という定義で進めてみます。
主キーや候補キーの拠り所として求めた {部屋, 時間枠} → {利用部門, 支払} 以外に、{部屋, 時間枠, 利用部門} → {支払} という関数従属もあります。これらは同一のものを指すという見方をするのか、別々のものを指すという見方をするのか、ここが迷うところなのですが、別々のものとみなします。なぜなら、仮に「メモ」みたいなフィールドがさらに増えるとしたら、それはビジネスルールに基づく{部屋, 時間枠, 利用部門} → {支払} という関数従属とは関係ないことになり、この関数従属は「レコード全体」を指さなくなります。つまり、これは部分的なフィールド間の関数従属をさしているものであって、候補キーによる関数従属とは別に、{部屋, 時間枠, 利用部門} → {支払} という関数従属が表には存在するということが言えます。
すると、前の表には、2つの関数従属がありますが、 {部屋, 時間枠}は候補キー、そして {部屋, 時間枠, 利用部門}は候補キーではなくスーパーキーになります。よって、前の表はボイス-コッドの正規形を満たしているので、分解する必要はないのでしょうか? 実は分解は可能ではありますが、おそらくこの先で説明する第四正規形による判断で分割は可能です。
ということで、利用部門と支払に関してのそれぞれの関数従属性を元に分解すると次のようになります。ここで、この2つの表について、部屋、時間枠、利用部門の3つのフィールドで照合すると、とりあえず見えている範囲では元の表に戻ってくれそうです。しかし、支払判定の表の最後の行には:つまり点々があって、もっとたくさんのフィールドがあることを示唆しています。
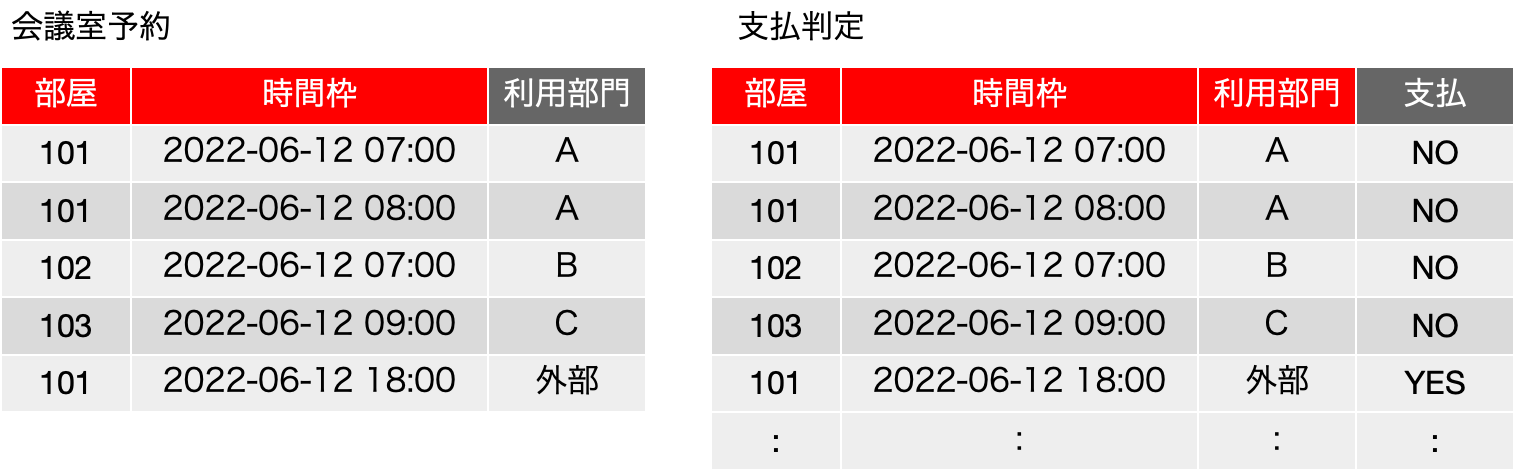
まず、このような表を作った場合に矛盾を感じる場面を考えてみます。例えば、会議室予約に新たな予約{102, 2022-06-12 08:00, B}を入れたとしましょう。すると、支払判定にも、{102, 2022-06-12 08:00, B, NO}というレコードを追加する必要があります。つまり、会議室予約をするのに2重にデータ入力をする必要が出てきます。言い換えれば、支払判定の部分集合が会議室予約のような構造になっていて、何か矛盾を感じます。予約に関するフィールドが増えれば分離している意味は見えてくるかも知れませんが、これだけのフィールドでは会議室予約や支払判定の完全な部分集合です。
本来は、「支払判定」は、支払うかどうかの事実を記録したものと見ることができます。であれば、{102, 2022-06-12, B, NO}というレコードは、もともと存在しなければならないということになります。すなわち「事実」が既に記録されている必要があるという見方ができます。であれば、頑張ってレコードを作るということになるかというと、ここでわざわざ時間枠という例を出したのは、論理的には無限大の数のレコードが必要になるということがまずわかります。今月からむこう1年のようなルールがないと有限になりません。
また、仮に部屋=101、時間枠=2022-06-12 07:00というレコードが会議室予約にありますが、支払判定を機能させるには、{101, 2022-06-12 07:00, A, NO}だけでなく、{101, 2022-06-12 07:00, B, NO}{101, 2022-06-12 07:00, C, NO}{101, 2022-06-12 07:00, 外部, NO}という4つのレコード、つまり、利用部門として取りえる全てのパターンを用意しておく必要が出てきます。すると、1日あたり、3 x 12 x4 = 144レコードを確保しないといけません。全く予約のない日でも、144レコードは存在します。そうしないと、未来にどの部門が利用するか分からないので、会議室予約にレコードを追加した段階で支払を確定させるということはできません。また、{101, 2022-06-12 07:00}である4つのレコードのうち、予約が入った後はそのうちの1つのレコードだけがあれば事は足りるのに、会議室予約に存在しない組み合わせのレコードも保持することになります。つまり、支払判定の全てのレコードが使われるわけではないということも気になります。
支払判定と会議室予約は、フィールド構成については部分集合だけど、レコードの集合として見た時にも、部分集合になっています。つまり、将来に会議室予約に登場しそうなレコードが、既に支払判定の表に存在しているという状況でもあります。それはなんとかなるとしたら冗長です。しかも、本来必要なものは会議室予約なわけで、謎なビジネスルールを実現させるものの性能や保守の問題が出そうなでっかい表を使うのかどうかという問題は設計時には頭を悩ませる問題です。すなわち更新整合性を確保するために、大きな犠牲を払う可能性があるということです。
ちなみに、支払を論理値として見るのであれば、YESになるものだけのレコードを作っておくという効率化は可能です。レコードがないものは照合したときにnullになるので、nullはfalseという判断ができていれば、1日あたり、3 x 2 x 4 =24レコードで済みそうです。いずれにしても、あらかじめレコードを作っておくというメンテナンス作業が発生します。
現実にこのようなことが発生するとどうしているでしょうか? おそらく、表に分けるという人はほぼいないと思います。もちろん、もっと複雑怪奇で、かつ気まぐれなルールだと表に分離する意味があるかも知れませんが、これ以上奇抜なのは「支払は上長が決済する」みたいな感じでしょうか。そうなると、支払フィールドに関する関数従属性はすっかり消えて単なるフィールドになってしまいます。
現状のルールをどのように実装するのが良いでしょうか? それは、SQLデータベースではビューを定義して、支払フィールドの値を、新たに生成すれば良いのです。支払フィールドの値は、同一レコードの他のフィールドから数式で生成可能ですので、単にビューを作ればOKです。利用部門の値が変われば、改めてビューの値を持ってくれば、支払フィールドの値も更新されます。FileMakerでは計算フィールドとして「支払」を定義すれば良いでしょう。文字列比較が入る面倒な式ですが、開発を生業としている人にとっては楽勝な範囲ではないでしょうか。ただ、UIが絡むとさらに作業は増えそうです。例えば、部門等を選択したら、即座に支払が判定されているような画面を作りたいような場合です。
候補キーではなく、スーパーキーが絡むような例を作ってみたら、思わぬ結果となりました。ちなみに、ビューや計算フィールドはいずれも計算式を利用した導出フィールドの追加ということになります。これらの機能を使うと、意味的には、{部屋, 時間枠, 利用部門} → {支払} という関数従属を、計算式で実現したことになります。つまり、2つの表に分けた場合の「支払判定」は、データベースソフトウェアが持つ多彩な機能をうまく利用すれば、表である必要はないということになります。そうしたビジネスルールをどこで定義するのが望ましいのかということは、開発や保守作業を効率的に進めるための問題として提起出来そうです。いずれにしても、正規化の考え方は重要であり、抽象的な議論ができるとは言え、ビューや計算フィールドを利用するという結論までは導いてくれません。だから正規化は不要ということではなく、考え方としては非常に役立っています。ここでの支払も別の関数従属であるということから、「対処の必要性がある」ということが示されているのです。