第三正規形までやってきました。よく、「第三正規形まではともかくやっておけばいい」みたいな、一つの到達点のように言われています。つまり、それ以上の正規形が難しい、あるいは実用上は滅多にお目にかかれないということがあって、必須の知識は第三くらいかなという意図もあるかもしれません。と言うことで、なんだか重要そうです。
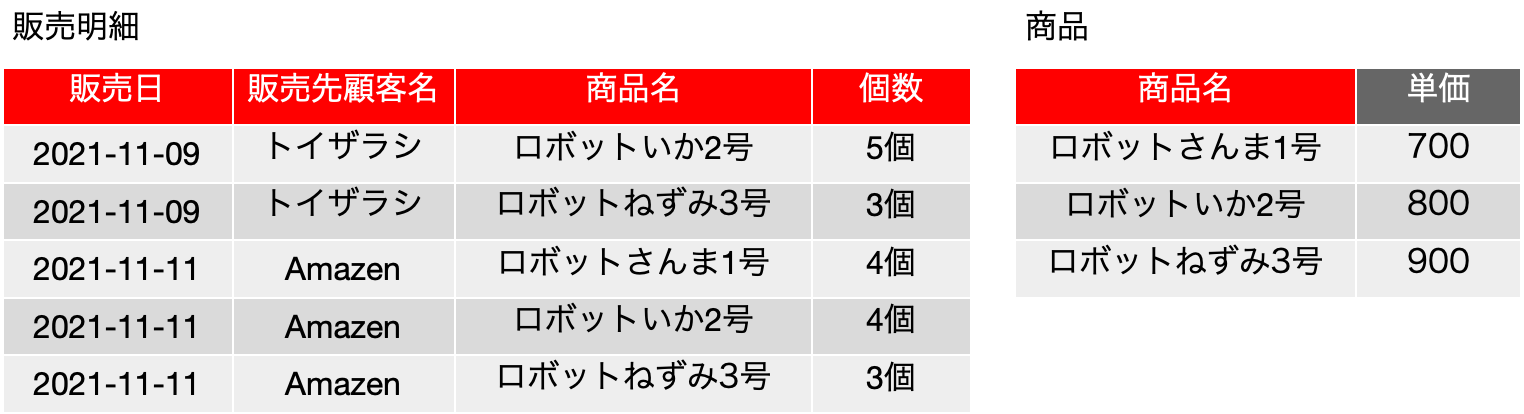
ここで、第二正規形の説明をしたときに示した表をもう一度示します。2つあったのですが、一応説明した順に示します。まず、この表は、もともと1つだった表を2つに分けたもので、第二正規形を満たしているという状態になっています。販売明細の候補キーそして主キーは{販売日, 販売先顧客名, 商品名, 個数} で、要するに全てのフィールドです。一方、商品は候補キー、主キーともに {商品名} です。元の表には2つの異なる関数従属性がありました。つまり、レコードを特定する主キー以外に、FD: {商品名} → {単価} という関数従属性を切り離したのです。こちらを「サンプル1」と呼びます。
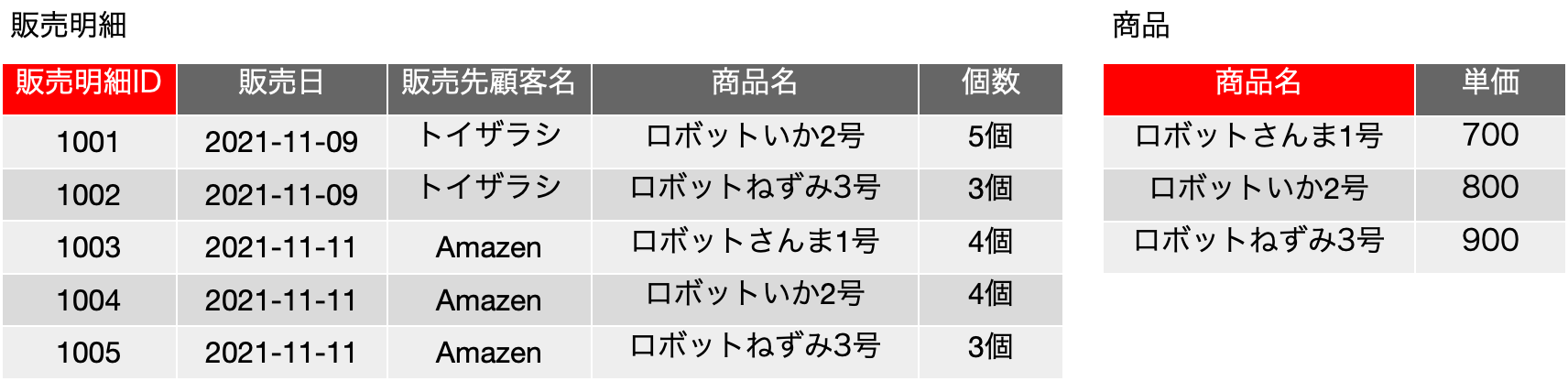
第二正規形の説明の時には、連番フィールドを増やしてみるた次の表も示しました。こちらを「サンプル2」としますが、サンプル2においては、サンプル1の主キーだった4つのフィールドが同一のレコードも保存をするというように状況が変わったとしています。したがって、販売明細の候補キー及び主キーは {販売明細ID} となります。サンプル1で主キーだった {販売日, 販売先顧客名, 商品名, 個数} は、もはや、キーとは関係ないフィールドであるとみなします。

サンプル2で存在する感数十属性は、まず主キーに絡めた FD1: {販売明細ID} →{販売日, 販売先顧客名, 商品名, 個数} がありますが、やはり、FD2: {商品名} → {単価} という関数従属性が存在します。しかし、第二正規形は、関数従属の手がかり(→の左側)が、候補キーに含まれているフィールドの部分集合からの別の関数従属が存在する場合には満たさないと定義されています。よって、商品名は候補キーの{販売明細ID}の部分集合ではないので、第二正規形は満たしていると言えます。しかし、サンプル1とサンプル2は基本、同一の表なので、更新整合性の問題は残ります。
ここで、FD1が成り立つ場合は、→の右側は、その部分集合についても成り立つことが言えます。つまり、FD1′: {販売明細ID} →{販売日}や、FD1”: {販売明細ID} →{商品名, 個数}と言う関数従属も存在するはずです。→の右側の1つ1つのフィールドについて、矢印の左側のフィールドが決まれば確定するという意味が関数従属だからです。
ここで、サンプル2について、FD1からFD3: {販売明細ID} →{商品名} と言う関数従属があると考えれば、FD3の→の右側と、FD2の→の左側が同じ集合になっています。したがって、{販売明細ID} → {商品名} → {単価} といった関数従属性の連鎖がこの表では発生しています。このような関数従属は推移的に関数従属すると呼ばれます。
そして、第三正規形は、第二正規形である場合において、推移的な関数従属がない状態のことです。つまり、サンプル2では第二正規形の評価では表の分離は行わなかったものの、第三正規形で、推移的な関数従属がある部分を別の表にすることで、無事にサンプル1と同様、いわゆる「商品マスター」が分離できました。
第二、第三正規形、いずれも、結果的には異なる関数従属が1つの表にまとまっていると言うことを嫌っているのです。言い換えれば、主キーによる関数従属以外は排除したいと言うことでもあります。しかしながら、それを段階的に追うと、主キー以外の関数従属におけるキーフィールドは、主キーの部分集合か、主キー以外にあると言うことになります。それらをフォーマルな形で表現したのがそれぞれ、第二と第三正規形になると言うことです。
ここまでの正規化の部分については、いろんなサイトでも参照されている増永先生の「データベース入門」(サイエンス社)をもとにしています。書籍には正確な記述がなされているのですが、一連の記事ではそのエッセンスをいただいているという大変失礼な使い方になってしまっています。ごめんなさい。ただ、多くのサイトや書籍を見ても、大体、第三正規形までは同じことが記載されています。表現が違うだけとは言いませんが、流れは同じです。ところがその先に出てくるボイス-コッド標準形は、書籍やサイトでかなり言っていることが違います。それでも、示していることは同じなのですが、このことは次回に説明しましょう。また、第二、第三、ボイス-コッド標準形は、それぞれ後のものが前のものの性質を保持していることもあって、そこで色々な考え方が出てきます。番号がついていれば、順番に理解しないといけないだろうと思うのは普通かと思いますし、飛ばして理解するのはなんかチートっぽいので、一連の記事でも順番に説明をしています。ところが、北川先生の「データベースシステム」(昭晃堂)だと、順序があることは説明がありますが、第一の次はいきなり第三を説明し、その時に中間として第二があると言うことを説明しています。つまり、ここでのサンプル1においては、第二正規化する前は、{販売日, 販売先顧客名, 商品名, 個数} → {商品名} → {単価} といった推移的な関数従属性があると見ることもできるので、第二と第三はセットにして考えても良いと言うことです。ちなみに北川先生の書籍では第三正規形の定義では推移的関数従属というキーワードでの説明をしているわけではありません。→の左側がスーパーキーか、→の右側が候補キーの要素であるような場合を第三正規形であると定義しています。上記はサンプル1を第二正規形を経ずに解釈するとしたらどうなるかという私の見解です。
すごく昔に、データベースに興味を持ち、早くからFileMakerなんかを使っていたのですが、4Dの登場もあってリレーショナルデータベースの勉強を始めたのでした。最初に買ったのが北川先生の書籍だったのですが、正直なところ全く理解ができず、他の書籍を読み漁り、いろんな角度で理解ができた上で、北川先生の本がやっと理解できるようになったということを思い出します。もちろん、先生の書籍の問題ではなく、私自身と私の勉強の仕方の問題です。若い頃に通った大学院でもデータベースの講義があったのですが、リレーショナルデータベースのことは書籍の最後にちょろっとだけ書いてあって「今後は出てくるかもしれないけど、講義ではざっくりね」みたいな時代でした。自分としてはそういう講義も受けていてそれなりに知識があったつもりだったのですが、数学の知識やあるいはデータベースシステムの実際など、書籍の理解の前提に至っていないところがあったわけです。古い言い方ですが、カード型のデータベースをいじっているだけの知識では相当狭かったのだと思います。それで、SQLのサンプルを含めて、詳細に書いている本でまずはSQLを理解し、システム構成上何が必要とされているのかと言うことを分かった上で、理論を追っていくことで、理解ができたと言うことがあります。インターネット前の時代だけに、気軽に使えるリレーショナルデータベースもなく、一方で使えるリレーショナルデータベースを標榜する製品が本当にリレーショナルデータベースと言えるのかという議論もされていたような時代で、結果的には書籍のサンプルを「動かさずに」必死に追うと言うのが最初に手がけたことでした。その頃に改めて数学の勉強もしましたが、情報むけの数学は電気科を出ている私にとってはカバー範囲の外だったりしたのでした。一連の記事では色々な学習のパスがつながって理解できるという体験を共有できればと考えて書いています。そして、自分なりのデータベース設計に対する理解を、数式を追わなくてもわかるような説明ができればと考えて続けています。
次回はボイス-コッド正規形に進みますが、ちょっと何日か開くと思います。ネタはほぼ調べきっているのですが、作図と別件の作業があります。お楽しみに。