前回は第二正規化を説明しました。定義を抽象的に言えば難しそうで敬遠しがちかもしれませんが、本質は、関数従属性が1つのテーブルに複数存在しているということにより、何かが問題であるということがあります。今日はその問題とされる「何か」を説明したいのですが、その問題の総称は「更新不整合」あるいは「更新時異状」と呼ばれます。英語ではupdate anomalyですが、日本語の記述は書籍によって異なります。更新、つまり、修正、追加、削除の時に問題があるということになります。
改めて、第二正規化前の表を示すと次のとおりです。この表の名前とともに、どんなフィールドがあるかということを記述する方法として、「販売明細(販売日, 販売先顧客, 商品名, 単価, 個数)」といった表記もされます。一連の記事ではわかりやすく表にしているのですが、より簡潔にはこういう書き方もあります。販売明細は、結果的に、いつ誰に何をどれだけ売ったのかの記録なので、単価を除く {販売日, 販売先顧客, 商品名, 個数} という4つのフィールドが候補キーであり、主キーになるというのが#27の時に説明した内容です。なお、スーパーキーとしては他に、全フィールドを示す{販売日, 販売先顧客, 商品名, 単価, 個数}もあります。
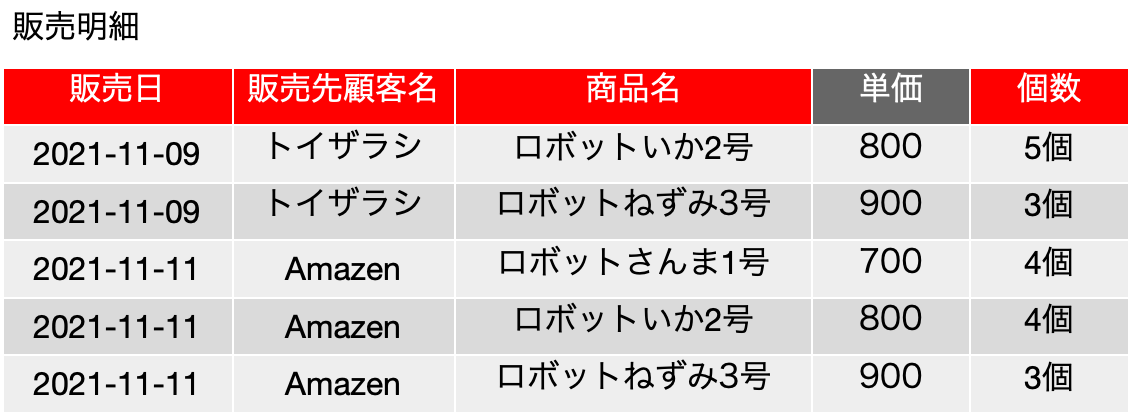
ここで、前の表のレコードに対する主キーは、関数従属の1つの表現であります。この表には、主キーに対するレコードへの関数従属とは少し異なる FD: {商品名} → {単価}、つまり、商品名が決まれば単価は自動的に決まるという関数従属がありました。こちらの関数従属は、主キーによる関数従属とは別の関数従属であり、このデータ持つ性質です。
第二正規化した結果は次のとおりでした。新しくできた「商品」の表は、候補キーとしては{商品名}の1つになり、これを主キーとします。そうすると、元は販売明細に存在した FD: {商品名} → {単価} という関数従属性は無くなっています。当然ながら、単価フィールドを無くしたからです。この関数従属性は「商品」の表に移動しており(あるいは分離した)、それぞれの表は1つの関数従属性を保持するデータとなっています。以下の分割した表から元の表は、「商品名」で照合して、商品の「単価」をくっ付ければOKということは何度も説明しています。このようなことができる特徴を「無損失結合分解」や「情報無損失分解」と呼ばれ、これも数学的に定義されています。ここでは、実体を表で見ながら考えてみて納得感は得られるのではないかと思うので、詳細な数学的な議論は説明しませんが、興味ある方はその辺りもガッツリ勉強しましょう。
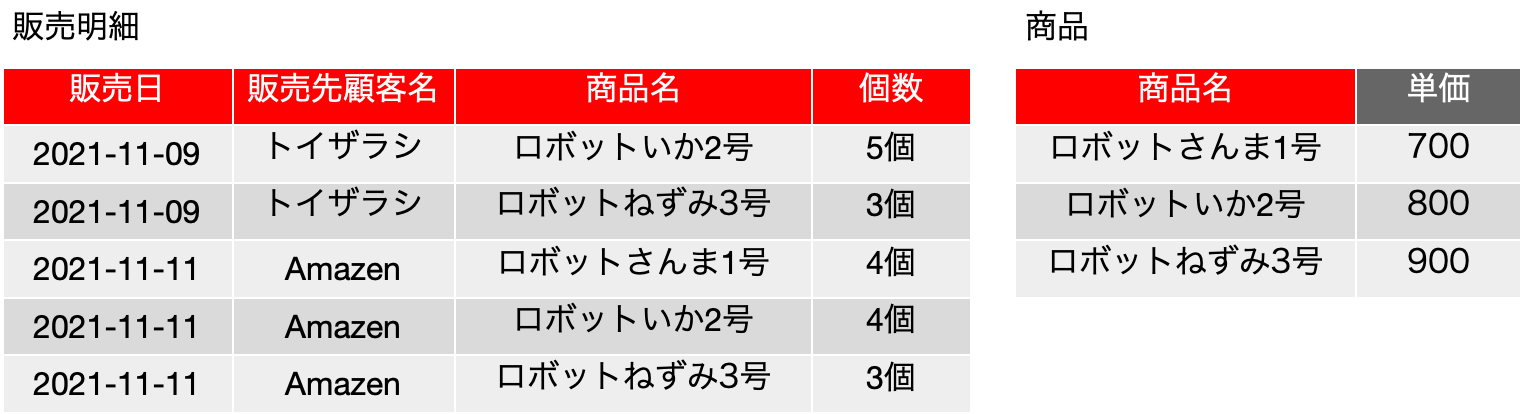
正規化前の表で、データの変更を行いたいということが発生したとします。いくつかパターンはあると思いますが、まず、単価が間違っていたとかあるいは発売前に他社製品よりも安くしたいので値下げといけないということがあったとします。例としては「ロボットねずみ3号」を900から850にするといったような事情です。もちろん、正規化前の表の単価のフィールドを変えればいいのですが、おそらくは複数のたくさんのレコードにわたってフィールド修正を行うことになります。これが、正規化後であればどうでしょうか? いずれの変更処理も、商品の表の1レコードを変更するだけでOKです。
同様な考えで、2行目の販売が、実は「ロボットねずみ3号」ではなく、「ロボットさんま1号」だったとします。この場合、正規化していないと2つのフィールドの変更が発生しますが、正規化後は商品名だけを変えればよく、1つのフィールドの更新だけで済みます。このような性質を「修正不整合」などと呼ばれます。そして、第二正規化により、修正不整合は解消されたと言えます。
ただ、ここでツッコミどころはあると思います。「商品名」が変わったら、正規化後の表においても複数のレコードに渡って変更しなければならなくなります。これは後で説明します。また、もう一つツッコミどころがあって、「販売先顧客名」は変わってもいいのかということもあると思います。これも商品名と関連性がありますが、やはり後で説明をします。
次に正規化前の表に、レコードを追加したいと思います。もちろん、新たに販売明細が発生すると、それは追加できます。ここで、新しい商品「ロボットうさぎ4号」が、990円で発売されたとします。正規化前の表だと、発売日、販売先顧客名、個数が決まるまで、つまりは売れるまでその情報が登場できません。これら、主キーフィールドはnullではいけないというルールがあるからです。つまり、商品名と単価以外のフィールドが空欄のレコードは、登場しないという前提で話をしているのです。ですが、正規化後は、販売明細はそのままで、商品の方に「ロボットうさぎ4号」「990」というレコードを追加することができます。「販売明細」の方には「ロボットうさぎ4号」はまだ登場していないので、元の合成した表に戻した時には、商品にある「ロボットうさぎ4号」は消えてくれます。正規化前にレコード追加の問題があることを、「挿入不整合」などと呼びます。「新しい顧客が発生したら?」というツッコミは、やはり後で説明します。
さらに、正規化前の表からレコードを削除することを考えてみます。たまたま「ロボットさんま1号」は3行目に1つしかありませんが、これを削除したとします。すると、「ロボットさんま1号」が700円であるという情報が、表から欠け落ちます。しかしながら、正規化後の表で、販売明細の3行目を削除しても、商品の方に「ロボットさんま1号」が700円であるという情報が残ります。この問題は、「削除不整合」と呼ばれます。これも、「顧客だって削除したら残っていない」というツッコミがあると思いますが、やはりすぐ後に説明します。
次回から第三正規形以降に移るのですが、こうした正規形を求めるモチベーションは、修正不整合、挿入不整合、削除不整合を合わせた更新不整合の発生を抑えるというところにあります。
ここで、不整合の発生が、単独のフィールドではなく、ここでは商品と単価のように、フィールドの組み合わせに対して発生している点にまず注意をしてください。正規化理論は、あらゆる不整合に対処しようとしているのではありません。フィールドとフィールドの関係がある部分、ここでは理論の上では「リレーション」に対してと言えますし、ここまでの議論では関数従属性を持つフィールドに対してという言い方もできます。よって、ここでの「販売先顧客名」のフィールドに対しては、このフィールドは主キーフィールドの1つですが、このフィールド単独でキーとなるような関数従属はとりあえず見つかっていないので、正規化の理論の枠外と言ってしまっていいでしょう。商品については{商品名} → {単価}という関数従属性が一連のデータにはあるという見方をしているので、そこに対しての更新不整合を問いたいというのが基本にあります。では、単独のフィールドの整合性は関係ないのかというと、もちろん、設計上は大いに関係があります。ですが、理屈の上では、フィールドにあるデータは元々は取り得る値の集合があって、そのどれかの要素がフィールドに来るという考え方がありました。記述しているかどうかはさておいて、少なくとも概念的には元になる集合を考えている「はずである」というこれも前提になります。現実のデータベースにその値を外さないようにする手法はいろいろ組み込まれているので、それを使って不正な値を入らないようにするなどは可能なのです。そこは正規化の理論とは関連は大いにありますが、前提部分の話であったりします。単独の値の保持ではなく、関係性の保持が、更新不整合での注目点となっています。
一方、もう1つ検討すべきこととして「主キーに使われている値は変更しない」という前提もあります。いや、前提かどうかは若干微妙ですが、まず、そう考えるとまさに整合するということがあります。ここでの「販売先顧客名」のフィールドにある「Amazen」などの名前は、そんな前提は無理ですが、ここで間違えることはないという前提がある、つまり、そのフィールドに入るべき集合から取り出すなどするので、間違えるはずはないという前提があるとすればどうでしょう? 「販売先顧客名」のフィールドの変更は、要するにこの世界にはないと言い切ってしまうわけです。もちろん、『そのフィールドに入るべき集合から取り出す』というあたりで、すでに別のテーブルへの分割が示唆されているものの、更新不整合の問題ではどうやら目を瞑るようです。
ということで、更新不整合はリレーションシップつまり、関数従属の枠内での主キーフィールドでないフィールドの更新に限られるとしたら、修正不整合のところでのツッコミの1つ「商品名の変更はどうよ」ということに答えられていると思います(単に封じているだけと言いたいかもしれません)。また、「顧客」については、フィールドが1つだけなので、関係性は論じられていないので、もう1つのツッコミにも答えていると思います。そして、後の理由は、挿入不整合、削除不整合のツッコミにも答えているでしょう。つまり、削除をおこなって「Amazen」がなくなったとしてAmazenが顧客である情報がなくなったということを問題視するのか、いや、売上無くなったのだし顧客じゃないよとドライにバイバイするのかということになると、後者の考え方を取ります。もし、そのうちAmazenにまた販売があれば、また、「Amazen」と1つのフィールドに1つの書き込み、つまり通常の(不整合とは言えない)編集処理の範囲内で付け加えることができるので、顧客については挿入不整合や削除不整合とは考えないということになります。
現実のデータベース設計ではどうでしょうか? 「顧客」の名前だけを管理するなんてことは皆無だと思われます。顧客の住所や担当者、電話番号などなど顧客に対する様々な属性をフィールドとして追加しないと、実務は回りません。そもそも、同一名義の会社は存在するので、会社名自体を主キーにするのは実用上はあり得ません。同一名や、同一会社で異なる販売先などといろんなバリエーションがあり、結果的に「顧客番号」みたいなIDとなる値を振ることになります。ということで、顧客も商品も、たくさんの主キーでないフィールドを持つことになるので、そこで顧客に関わる関数従属が発生して、「顧客」が独立した表になるかと思われます。
フィールド1つのリレーションというのは全くないわけではないものの、どちらかといえば滅多に出ません。これは1つの話題としては面白いので、覚えていたらまた書いてみたいと思います。ただ、ここで、無理やり、顧客マスターが登場する理屈を考えるとしたら、自分自身への関数従属があるでしょう。つまり、FD: {販売先顧客名} → {販売先顧客名} という関数従属です。当然、1対1に対応するので関数従属性はあると言えばあるのですが、これを言い出すと、実は全てのフィールドについて言えてしまうのですが、ともかく販売先顧客名だけを考えて、自分自身に関数従属しているとしたら、顧客(販売先顧客名, 販売先顧客名) という表を作ることができます。しかし、2つのフィールドの内容は同一なので、表としては顧客(販売先顧客名)であれば十分である、すなわち表として持ち得る情報は等価であると言えるので、これにより顧客マスターの分離は可能です。明細の最初の2行を削除しても、顧客に「トイザラシ」が存在することは残り、挿入不整合、削除不整合は防げそうです。ただし、この場合だと、販売先顧客名は主キーフィールドなので、修正不整合の問題は残ります。この考えを一般的に適用すると、「個数」には「個数マスター」に登録しないと明細に登録できないというようなことになります。もっとも「個数」の場合は、整数というプリミティブな型なので、他に日付も加えてそれを別の表で一旦定義して使うというのは、結果的にかえって処理手間が増えるだけになるので、もちろん現実的ではありません。数値や付随情報があるということは一般には考えにくいです。日付は隠れた関係性を持つことがあって要注意なのですが、日付もやはり単独の値です。いずれにいしても、このように、一般化しすぎると明白におかしな方向に行くので、元々関数従属性の定義では、R(X, Y, Z)において、XによってYが決定するということで、XとYが最初から分離しているということを示唆しているあたりで、自身への関数従属については除外されているとも考えられます。ただし、Y⊆Xの場合は「自明な関数従属性」と呼ばれ、Y = Xの場合も含まれるので、関数従属という考え方は可能です。つまり、選択的に自分自身への関数従属性を考えれば、現状での「販売明細」でも「顧客」テーブルの分離はできるとも言えるかもしれません。そうなると、今度は「選択基準」が欲しくなりますが、現状では、要求があるから、あるいは問題が出る可能性があるから、ということでしか言えないでしょう。以前にフィールドの値はラベルか測定値だと結論づけていますが、ラベルには付帯する属性はあることが多いのですが、測定値はその値が単独で意味を持つとも言えます。であれば、「ラベルを値に持つフィールドは自身への関数従属とみなして良い」みたいなルールを与えれば、第二正規形の段階で、顧客は別の表に分離できそうですが、もちろん、直感で言っていて、それが体系の中で問題ないかは全然検証していませんのでご理解ください。
理論には必ず前提があります。データベースの理論は一度数学の世界に入っているところで完全な理論体系が確立されているのですが、その考え方を現実のシステムに適用するあたりで、前提は忘れがちになります。しかしながら、その前提が重要であることは言うまでもありません。