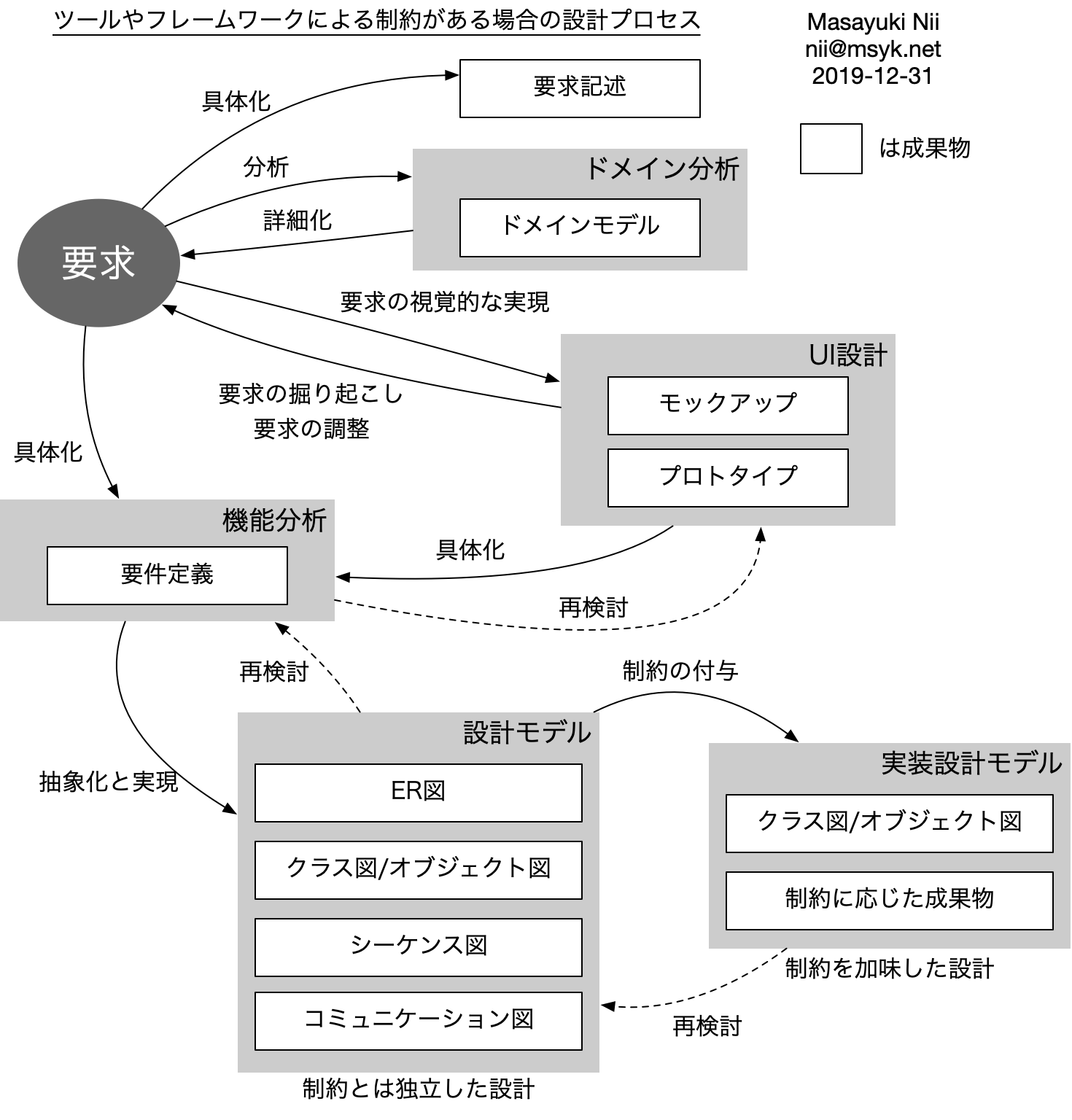
これまでの流れで、要求から設計を進めてきました。先にデータベースのスキーマを考える点では、SQLデータベースを使う的なことが早めに決まっているような流れになっていますが、GUIのモックアップから必要な機能を出して設計としてまとめるということをやってきました。ただし、原則としては開発環境の制約に関係なく、要求を元にした必要かつ実現可能性があるような汎用的な設計までができました。ここから、実際に実装が可能な設計を検討します。まず、このような例の場合一番わかりやすい、MVCあるいはMVC2パターンを検討します。
MVCパターンでの制約は、まずは文字通り、モデルとビューを分離して、コントローラーでそれらを統合するという構成にするということがあります。これは制約というより、一種の設計方針として認識されてており、制約という何かできなくなるような「縛り」というよりも、設計を進めやすくする「方針」のような捉え方をされている方も多いと思います。
そして、多くの場合は、HTMLのテンプレートをベースに、クライアントに送り出すHTMLコードを生成します。HTMLがビューであるという見方と、ビューによって生成されたものという見方があり、フレームワークによってその辺りの位置付けは微妙に違っているかと思います。また、テンプレート処理を行うのがサーバー側かクライアント側なのかという点も制約は異なると思われます。ここでは、サーバーサイドで完結するタイプのフレームワークを使っているとしましょう。
主要な制約としてはこのくらいではないかと考えられます。それ以外は、通常は開発言語で記述をするので、自由度は高くなります。巨大なクラスを作っても、小さなクラスに分けても、動くと言えば動きます。
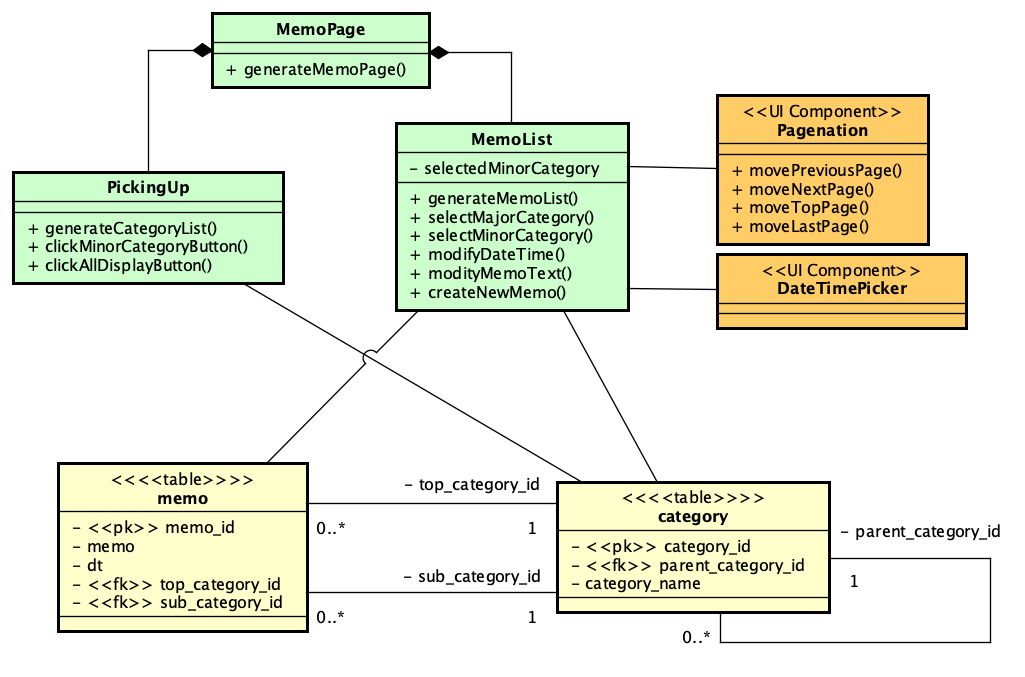
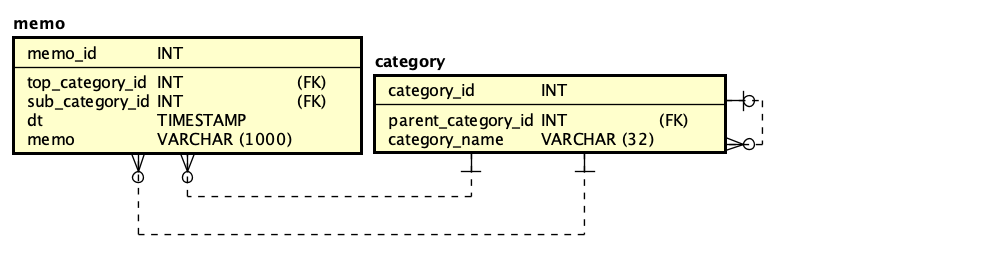
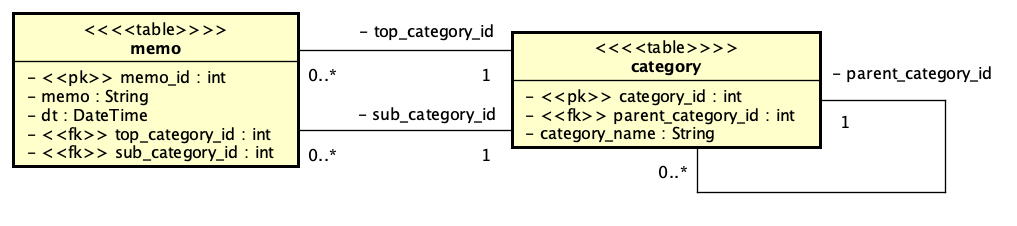
まずは、モデルの抽出です。本質的には、MemoList、PickingUpのクラスで必要な機能が抽出されているので、それを受け付けるという処理を考慮し、テーブルとして用意するmemoとcategoryにそれぞれモデルを割り当てるのが素直な方法と考えられます。CategoryModelの最後の2つのメソッドは、ポップアップメニューの選択肢を構築するためのデータ取得のメソッドになります。
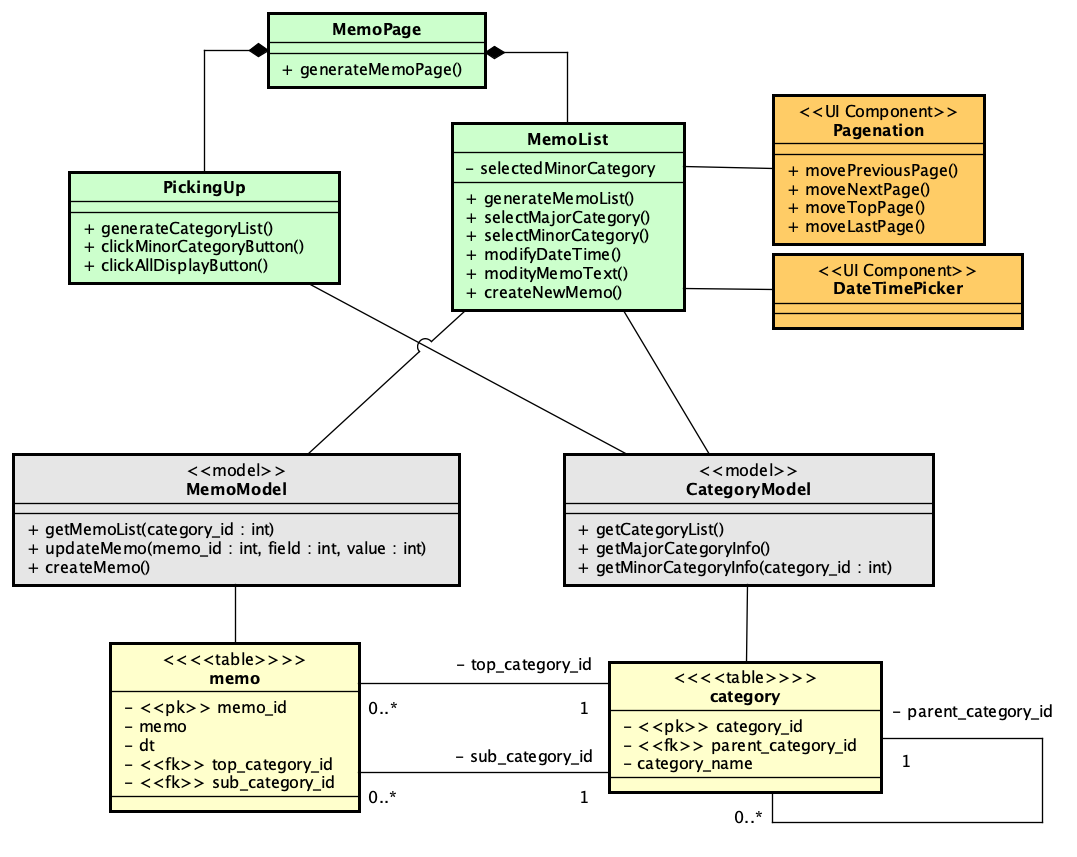
続いてコントローラーとして、MemoListController、CategoryListControllerを導入します。ここで、レイヤー構造となるような大きな区分をパッケージで分類しておきました。UI側の要求をコントローラーで捌き、データベースとのやりとりをモデルによって処理しやすい形式に整えるといった典型的な設計になります。ですが、これは、単にクライアントからの処理が関係しそうな箇所を繋いだだけであって、意図が正しいかを検討しなければなりません。
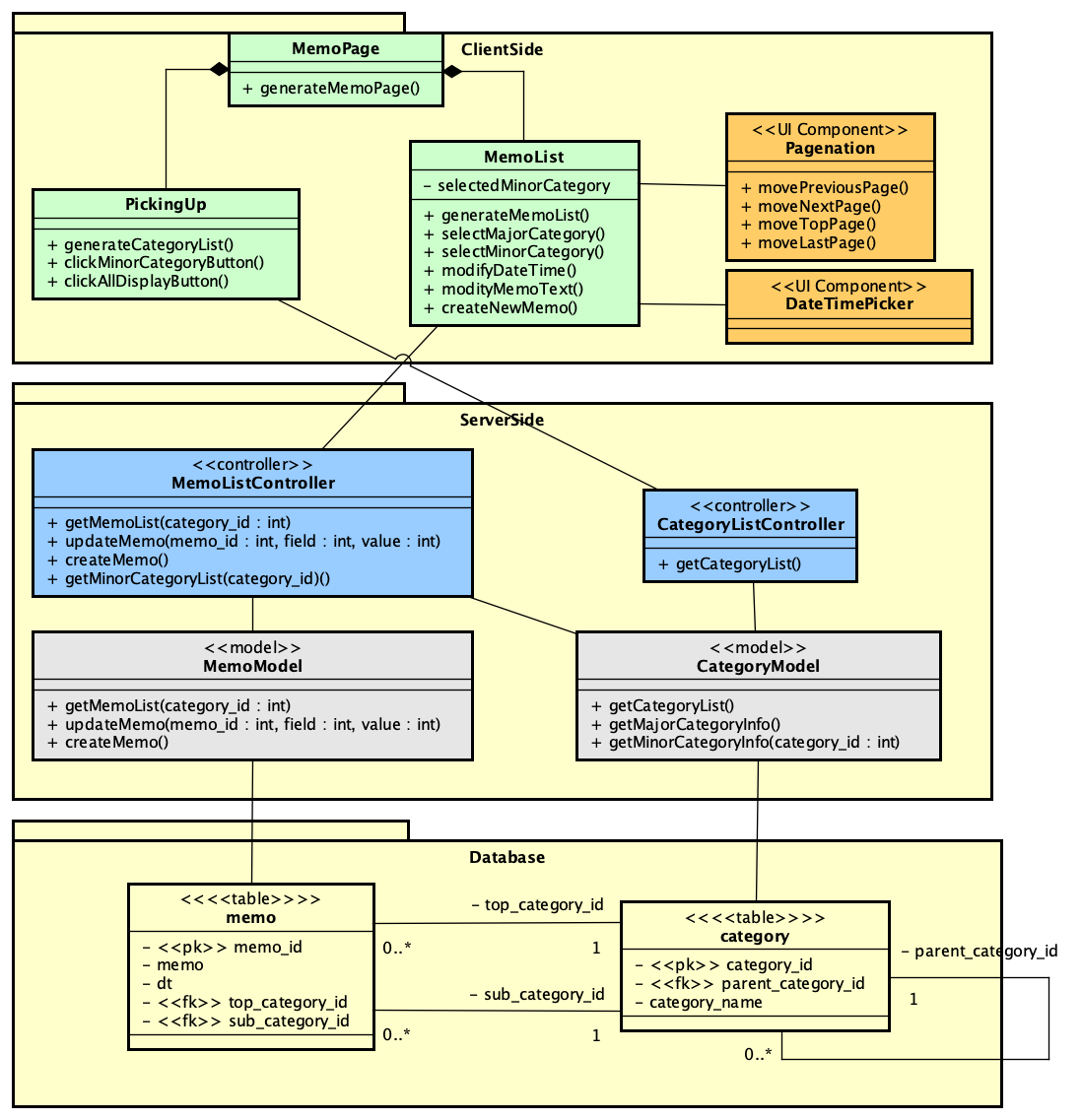
WebのMVCフレームワークの1つの大きな制約は、クライアントサイドではHTML/JSの世界であり、それがサーバー側でPHPなりJavaなり、異なる世界が展開されていることです。その橋渡しは、テンプレート処理ですが、テンプレート処理はページ構築時に全てを構築することにフォーカスしがちです。
しかしながら、ページを提示後の様々な処理にどう対応するかを、ページのテンプレートの段階で検討しておき、対処をしなければなりません。その後に、HTMLの部分的な要素をテンプレート処理して得ることもあるかもしれませんが、一方、単にJSONで送って返ってくるようなWeb API的な動作が欲しい場合もあるでしょう。
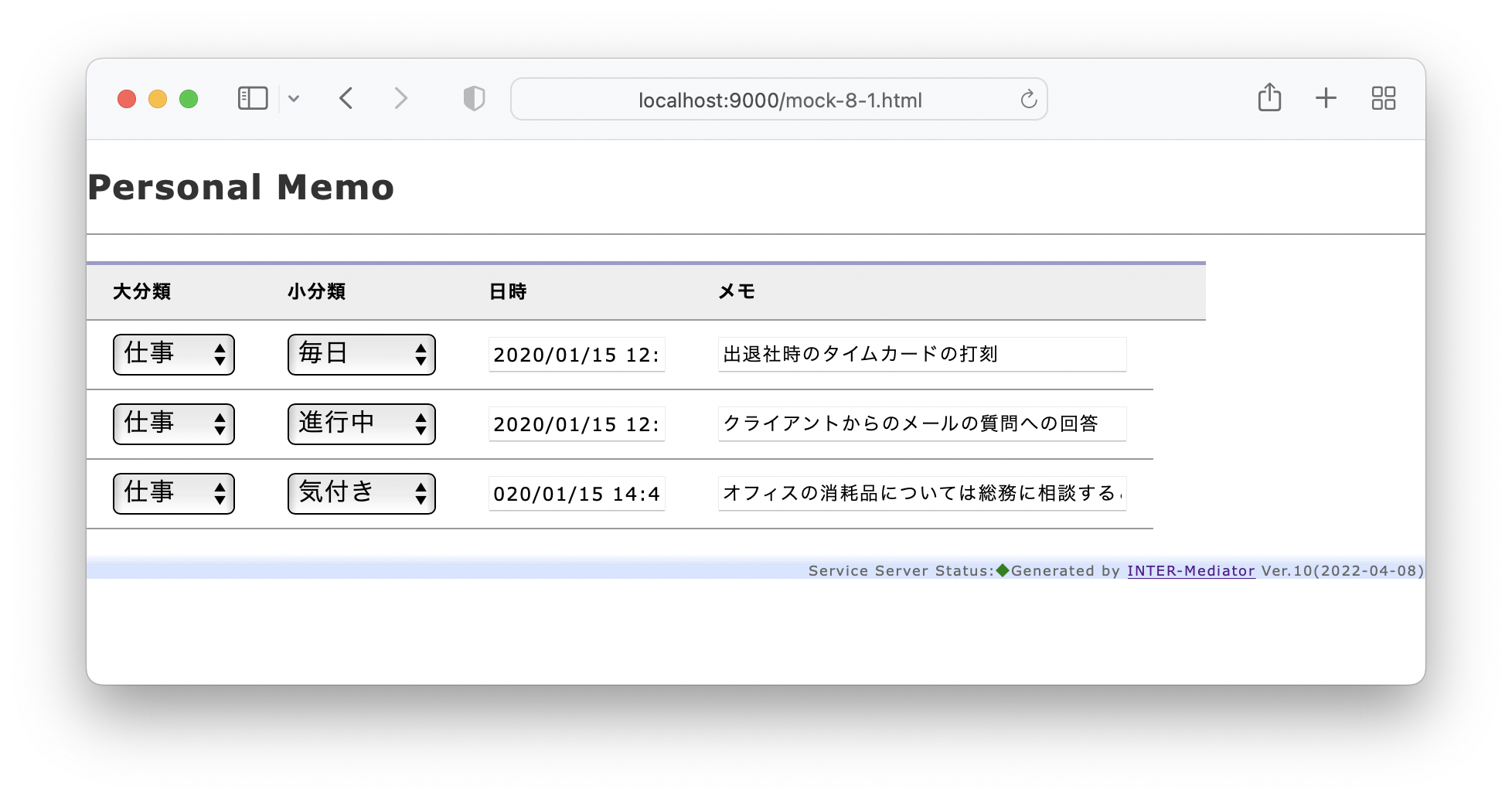
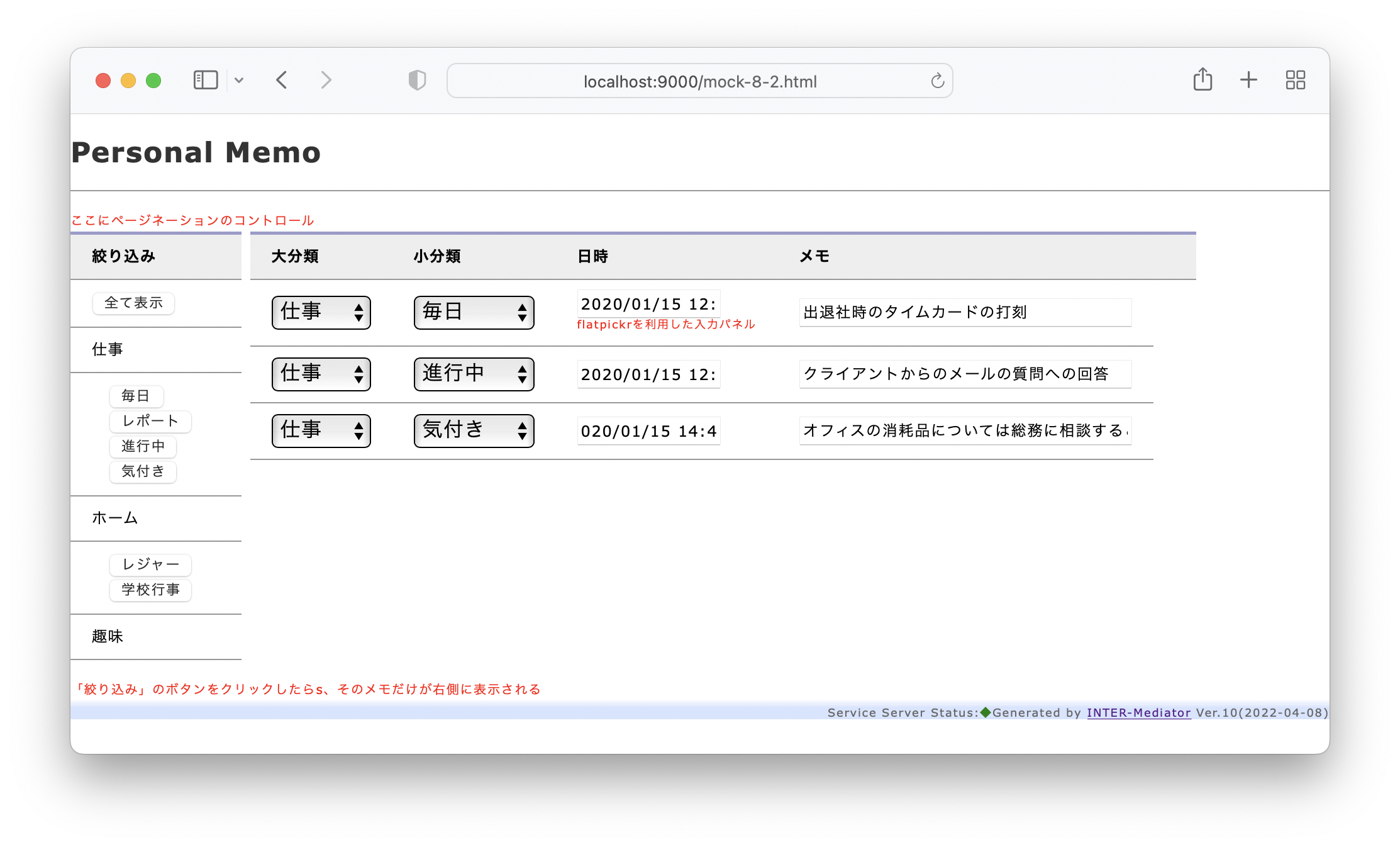
そこで、ここでまず、次の図のようにHTMLのテンプレートを設計します。ページ内の要素に適当に名前をつけてテンプレートそのものをモデルとして記述してみます。事実上、1つのクラスは1つのタグ要素に対応するものに近いレベルで記述しましたが、動作上必要な要素だけが抽出されています。なお、クラス名はタグ名でもいいような気もしますが、ここではそれらしい名前を記述しました。ルートはPageTemplateあり、これがbodyタグと考えても良いでしょう。モックアップの左側にあるカテゴリのボタンが並ぶ部分はCategoryBox、右側でメモの一覧が見えている領域はMemoListとしました。Memoの1行ごとにMemoLineがあり、メモの文字列はMemoTextです。このモデリングは、比較的細かく考えた方が良いでしょう。とは言え、これを書くのは結構面倒なのは確かです。できるエンジニアはこれを頭の中でさっさとやってしまうわけですが、今は開発プロセスの検討をしているので、あえて書いてみました。メモの文字列を表示するinputタグはMemoTextクラスに相当しますが、入力された文字列はvalue属性で得られます。これはブラウザ側の標準機能であるので、ここではprivateの記号で記述しましたが、スコープの意味ではなく、ここでは既定義されているという意味合いでマイナス記号を使いました。
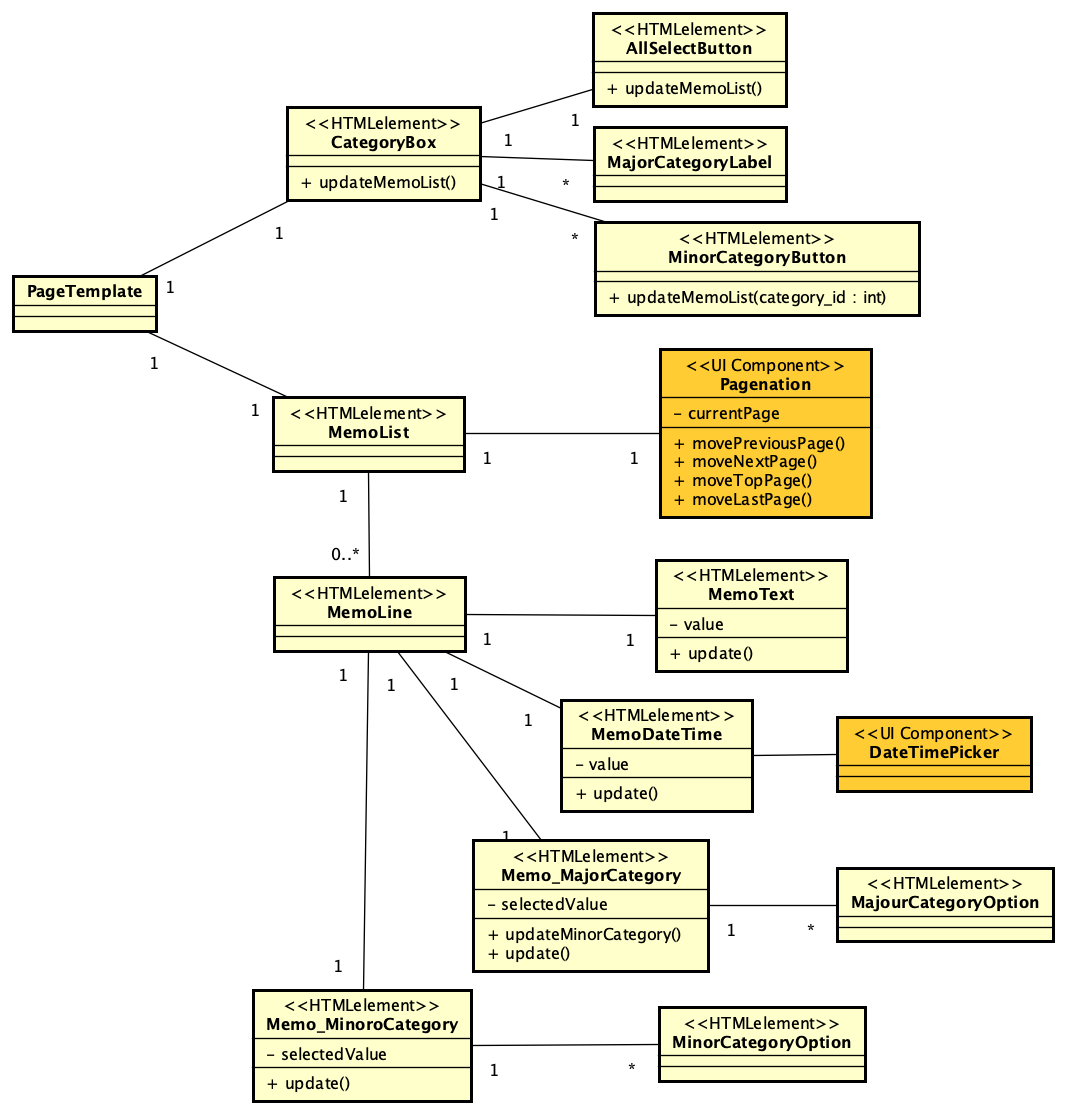
テンプレートの要素をよく見て、その要素が何らかの応答をしなければならない場合には、HTMLelementステレオタイプのクラスはメソッドを記述することにしました。前の図のように、MemoListは書き換えればデータベースへ反映しなければなりません。そういうことで、MemoLineの子要素は全て、update()メソッドを持つ必要があります。update()メソッドのスペックとしては、書き直したら、どこかのタイミングでサーバーに修正データを送り、データベースを更新する必要があるということです。一方、CategoryBox以下のボタンでは、ボタンをクリックすることで、メモ一覧を新たにする必要があり、その意味で、updateMemoList()メソッドの定義があります。さらにこれだけで十分ということではなく、カテゴリが階層化されていて、大分類を変更したら小分類の選択肢が変化するという仕組みが必要になります。つまり、大分類のポップアップメニューを選択すると、小分類のリストをどこかから取ってきて、選択肢を入れ替える必要があります。実装方法はいろいろありますが、この小分類の更新を行うためにMemo_MajourCategoryクラスに、updateMinorCategory()メソッドを定義します。こうして、ページの初期状態をテンプレートとして記述するのはもちろんですが、それがページとして展開された結果を想定して、表示後に必要とする機能をモデルに組み込むことを行います。なお、UI Componentステレオタイプのものは、ここでは詳細設計対象外とします。
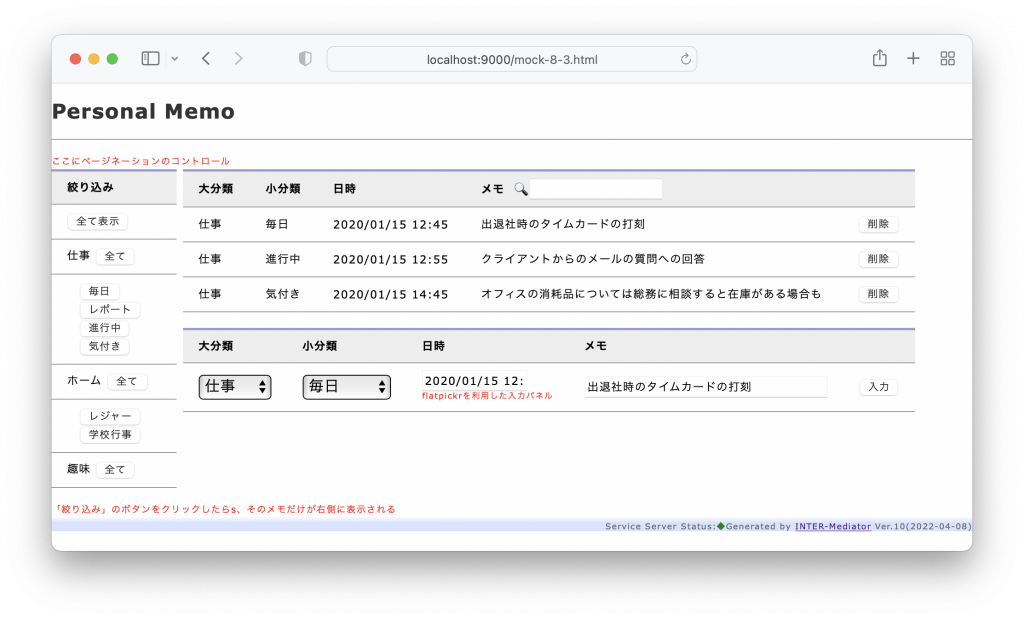
テンプレートから元のクラスを検討しましょう。次の図は、テンプレート処理した結果をクライアント側に展開しました。ここで、Webアプリケーションとしての制約があります。クライアントとサーバーの間はHTTP通信によってのみコミュニケーションを取ることができるということは実は大きな制約です。MVC系フレームワークを使う場合、もちろん通信はURLによって柔軟に作り分けることができるのですが、機能を組み込むときに最初に考えることは、それぞれの通信処理でテンプレートを使うかどうかです。ページ全体を生成するときにはテンプレートを利用するのは当然ですが、一方、修正したデータをデータベースに反映する作業はテンプレートを使わなくても良いでしょう。以前だと、サーバーの通信後に常にページ更新をしていたので、それは常にテンプレートを使っていたということになりますが、AJAXを出すまでもなく、現在の仕組みでは単にWeb API的な通信の実装はそれほど難しいことではありません。
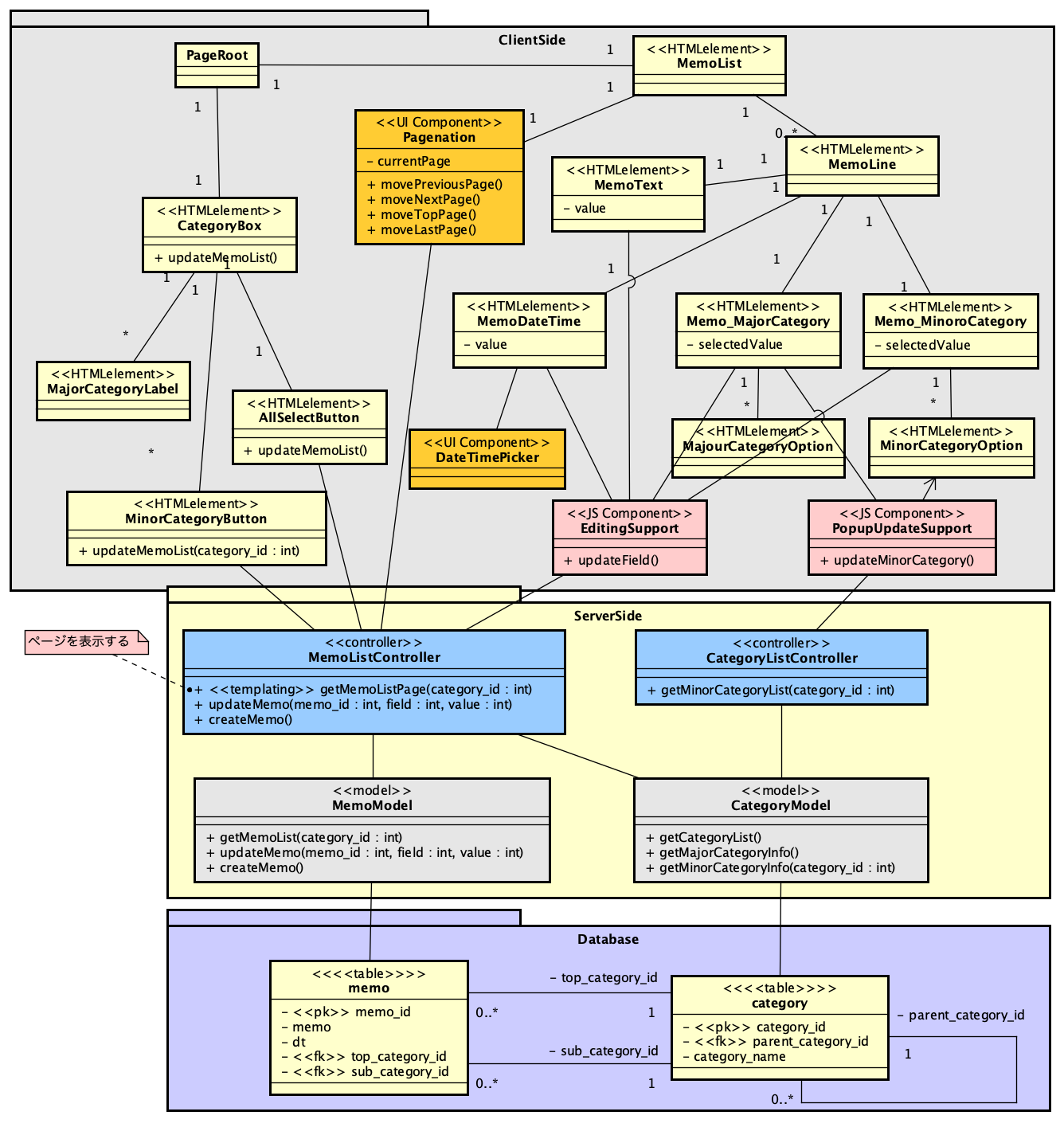
ここで、まず、ページを表示するときには、テンプレートをベースに、初期的なメモの表示ルールを適用して、ページ全体を表示します。そのためのメソッドを、MemoListControllerにgetMemoListPage()メソッドとして定義するとします。テンプレートを利用したHTML生成を行って返すことを示すためにTemplatingというステレオタイプをつけておきました。そして、このメモリストでは左側の小分類を押して表示するボタンや、全部のメモを表示するボタンは、同じようにgetMemoListPage()メソッドを使ってページを書き直すのが効率的な設計ではないかと考えられます。この「ページを全部書き直す」作業は、基本的にはHTML上のリンクであり、そのリンクがサーバー側のメソッドを呼び出すので、コントローラーに直接つないでしまっています。ページネーションはコンポーネントとして利用すことにしていましたが、このページネーションも、getMemoListPage()メソッドを使ってページ全体を書き換えるのが1つの方法です(できればリスト部分だけを更新したいですが)。ここの実装はこの設計では細かくは追いませんが、方針としてはMemoListControllerにつながることで進めることにします。
一方、メモの文字列や日付時刻、そして分類の選択肢は、変更をすると、その結果をデータベースに書き直したいわけです。ただし、その作業は、自動的には行えず、要素上で発生したイベントに応じてクライアント側のプログラムを呼び出し、そしてサーバーに要求を伝える必要があります。そのために、クライアントサイドにEditingSupportというクラスを用意しました。もちろん、inputタグ要素の種類に応じて適切なイベントによってこのクラスのメソッドが呼び出されるように、実現可能性を加味した設計にしなければなりません。そして、EditingSupportでは、サーバー側のMemoListControllerにあるupdateMemo()メソッドを適切なパラメータで呼び出すように作ります。こうして、要素の変更からそれがデータベースまで更新される流れがクラス図上で明確に現れてきました。大分類のポップアップメニューを選択した場合、小分類の選択肢を更新するという作業には、ここではPopupUpdateSupportクラスを用意しました。
大分類を示すMemo_MajourCategoryからコールされるのですが、一方でMemo_MinorCategoryのポップアップメニューの選択肢をコントロールできないといけません。select側あるいはoption側のどちらでもいいので適切な参照が必要になり、あらかじめ参照を配列等に記録するか、呼び出し時に更新する要素を指定するなどの方策が必要になります。詳細はここでは省きますが、いずれにしても、JavaScriptで実装すべき内容が、独立したクラスで明確になりました。クラス図なのでクラスで書きましたが、実装じは単に関数でも大きな違いはないと思われます。
ここまで設計を進めれば、MVCフレームワークだと概ねどのフレームワークでも、似たような作業で実装を進めることができるでしょう。フレームワーク特有の事情がある場合は、もちろん、それも考慮して設計を進めます。通常はオブジェクト指向プログラミング環境ですので、クラス図で作った設計との親和性が高いのは当然のことと思われます。
現実の設計では、ここでのコントローラのように、テンプレート処理をしたりしなかったり、あるいは更新処理を受付たり、部分的なHTMLを生成したりと、メソッドによって様々な動作を設計することになります。ここではコントローラーにまとめて書きましたが、むしろメソッドごとに1つのエンティティとして記述した方がわかりやすいかもしれません。フレームワークを利用する場合には、テンプレート処理でスマートにページ生成ができることが強調されますが、ページ表示後の動作についてはそれ以上にたくさんの解決すべき問題を生み出します。フレームワークを使うことで簡素化される面はいろいろあるかとは思いますが、テンプレート処理後の動作を詳細に検討するという作業を、試行錯誤でやっている人は多いのではないかと思います。このように、モデルベースで考えてみれば、どんな仕組みをクライアントとサーバーに持たせるかは全体を見ながら検討できるわけで、より良い側面は多々あります。特に、うまく設計できないで悩んでいるなら、まずはモデルとして設計することは強くお勧めできます。
次回は、同じ設計を別の環境に適用することを考えてみます。