INTER-Mediator Ver.0.5まで来たところで、見直しを始めました。現状、それなりに動いているのですが、「選択入力」の実現を考えていたときにちょっと壁があることが分かりました。選択入力は簡単ですが、「状況に依存して選択肢が変化する」までを視野に入れると、今のままではスマートな解決方法はありません。もちろん、いかにも取って付けたような対応は可能ですが、それだと美しくありません。加えて、現状では、リスト形式の画面のとき、リストの1行1行からのリレーションがあるような場合にうまく対応できません。これらを考えて、いろいろな状況に対応できるように、データベース処理をより汎用化することを考えました。
Ver.0.5までのアーキテクチャだと、「リレーションのリレーション」ができません。一方、リレーションをいくつも定義できれば、「状況に依存して選択肢が変化する」ができるのです。つまり、選択肢は、リレーションして絞り込まれた結果であるからです。常に同じ選択肢のものは、そのテーブルとのデカルト積で考えれば良いので、この手法で、選択肢の件は解決するはずです。
Ver.0.5までは、InitializePage関数の引数で、テーブル名/キーフィールド名/外部キーフィールド名、を指定していますが、外部キーフィールドが、どのテーブルのどのキーに対応するものなのかを指定する必要があります。1つ目のテーブルの場合や、相手のテーブルのキーフィールドに対応する場合には省略可能とすると、シンプルなものであれば現状と変わらないと言えるでしょう。
そこで、InitializePage関数の第一引数で、’foreign-key’ というキーに対してテーブル名を記述していたのを、以下のキーと値を持つ配列で定義することにします。
- ‘field-name’:外部キーフィールド名
- ‘table’:対応するテーブル名
- ‘key’:対応するテーブルのキーフィールド名
一方、現在は繰り返しは1つのTRタグの繰り返しです。テーブルのデザインによっては、複数のTRで1つのレコードを表現し、それを繰り返したいこともあります。また、UL/OLもあるし、SELECT/OPTIONもある意味繰り返しです。DIVを繰り返したいと思う事もあります。そこで、汎用的な繰り返しを実現するために、リピーターとエンクロージャーを定義します。HTMLページは要素の繰り返しですし、要素に要素が含まれることになります。ここで、1つのノードを「エンクロージャー」とし、その中にあるあるノード以下の全てのノードを「リピーター」とします。元のドキュメントで、エンクロージャーとリピーターが認識できれば、リピーターを繰り返しデータベースのデータに置き換えることで、繰り返すレコードをドキュメント内に展開できることになります。右側はノードとして見たときの関係を示した図です。
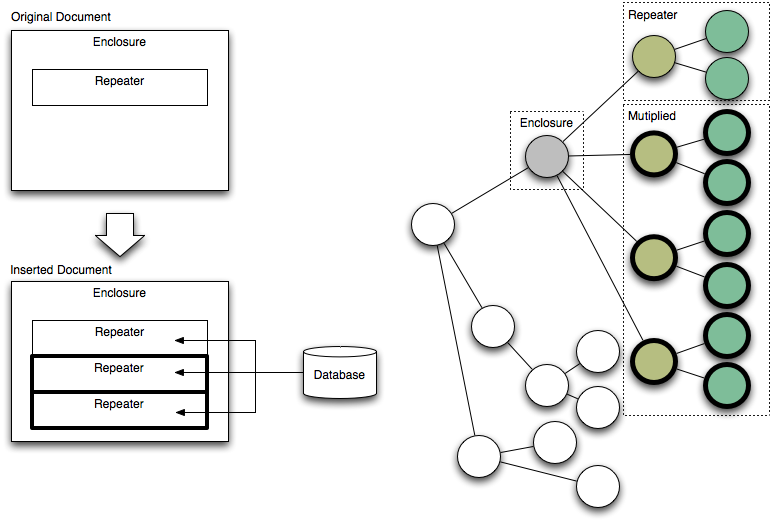
リピーターとエンクロージャーとして、以下のようなものをサポートする事にします。テーブル、項目リストはもちろんですが、SELECTも同様な仕組みです。また、汎用的にDIV要素と既定儀のクラス名で、リピーター/エンクロージャーのセットを定義できるものとします。DIV以外は、リピーターとエンクロージャーはノードの階層関係の上では親子関係になっていることになります。リピーターとエンクロージャーの間にノードがあっても良いということになると、今度は繰り返しをつなぐポイントを定義しないといけないことになるので、DIV要素の場合も直接の親子関係にあるものとします。ただし、そうなれば、DIV要素の双方にクラスを付けることは不要であるとも考えられますが、これは後からの検討課題とします。
リピーターとエンクロージャーとして、以下のようなものをサポートする事にします。テーブル、項目リストはもちろんですが、SELECTも同様な仕組みです。また、汎用的にDIV要素と既定儀のクラス名で、リピーター/エンクロージャーのセットを定義できるものとします。DIV以外は、リピーターとエンクロージャーはノードの階層関係の上では親子関係になっていることになります。リピーターとエンクロージャーの間にノードがあっても良いということになると、今度は繰り返しをつなぐポイントを定義しないといけないことになるので、DIV要素の場合も直接の親子関係にあるものとします。ただし、そうなれば、DIV要素の双方にクラスを付けることは不要であるとも考えられますが、これは後からの検討課題とします。
| リピーター | エンクロージャー |
|---|---|
| TR要素、TR要素の配列 | TBODY要素 |
| LI要素、LI要素の配列 | OL要素、UL要素 |
| OPTION要素 | SELECT要素 |
| DIV.im_repeater要素 | DIV.im_enclosure要素 |
Ver.0.5までは、リピーターとエンクロージャーは明確に識別はされていませんでした。というのは、TABLE要素にある1つのTR要素を繰り返すというルールだけだったからです。ドキュメント内のINPUTタグの要素を検索し、それを含むTRを探し、さらにTRを含むTABLEを探すということを行っていたのです。従って、INPUTタグに何らかの識別マーク(具体的にはNAME属性)を付けることで、そこからリピーターとエンクロージャーを自動的に探す事ができます。また、リレーションも2段階までだったので、見つけたエンクロージャーに対してデータベースからの読み込み結果を適用すれば済みます。
アーキテクチャを変更した後はどうなるでしょうか? ここにはいろいろな問題が発生します。リレーションも多段階であることも考慮すると、ドキュメントからエンクロージャーを見つけて処理するとう方法は限界があります。たとえば、リピーターとして繰り返した要素のさらに下位にエンクロージャーがあった場合はどうなるでしょうか? このことを考えれば、結果的にはドキュメントの要素を順次調べて、リピーターとエンクロージャーを識別し、その都度データベースの差し込みをする必要があります。以後は、Ver.0.5までと同様に、INPUTタグの要素などデータベースのデータと実際に置き換えが行われる要素に「テーブル名」「フィールド名」などの情報を埋め込み、そこからエンクロージャーやリピータを識別することにします。アルゴリズムを考えるときに、リピーターの中にあるエンクロージャーをどう識別するのかということがポイントになると考えられます。