前回は、第五正規形の例として、履修登録を示しましたが、表に分割はできるものの、更新処理が複雑怪奇になりそうということで、本当にそういう表分割をするのかどうかという根源的な問題が出てきてしまいました。例えば、商品マスターを分離するというのは、そのメリットはわかりやすいと思われます。あっちこっちにある商品単価が、一元的に管理されているので、単価が変わったら1箇所の修正で、あちらこちらの商品単価が自動的に更新されるというあたりです。ところが、履修登録を3つの表に分離したら、ちょっと様子が変わりました。まず、こんな履修登録があるとします。教員と科目は多対多の関係にあり、1人の教員が複数の科目を持つこともあれば、1科目を複数の教員が担当することもあります。
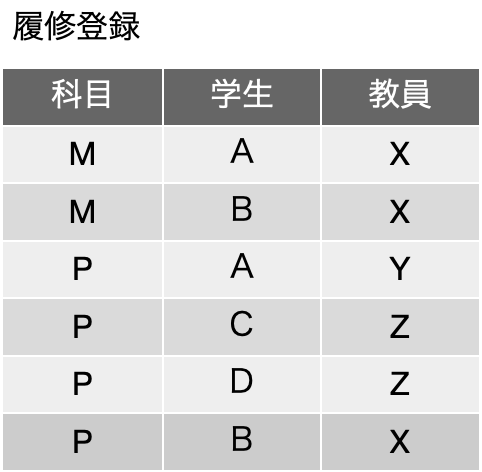
ここで、データそのものと、関係性を分離して考えるために、教員、科目、学生は、まずそれぞれ単独の表に記載します。そして、ID番号をここでは重複しないように適当に降ります。いずれもID以外にフィールドは1つだけですが、実際のデータベースでは、それぞれ、たくさんのフィールドを持つことになるのではないかと思われます。そして、その関係性を表に分離したのが後半の3つです。前回に、第五正規形の例として示した表と根本的には同じですが、実際の運用に近い感じにして見ました。つまり、合計6つの表で、履修登録の管理をしようということになります。
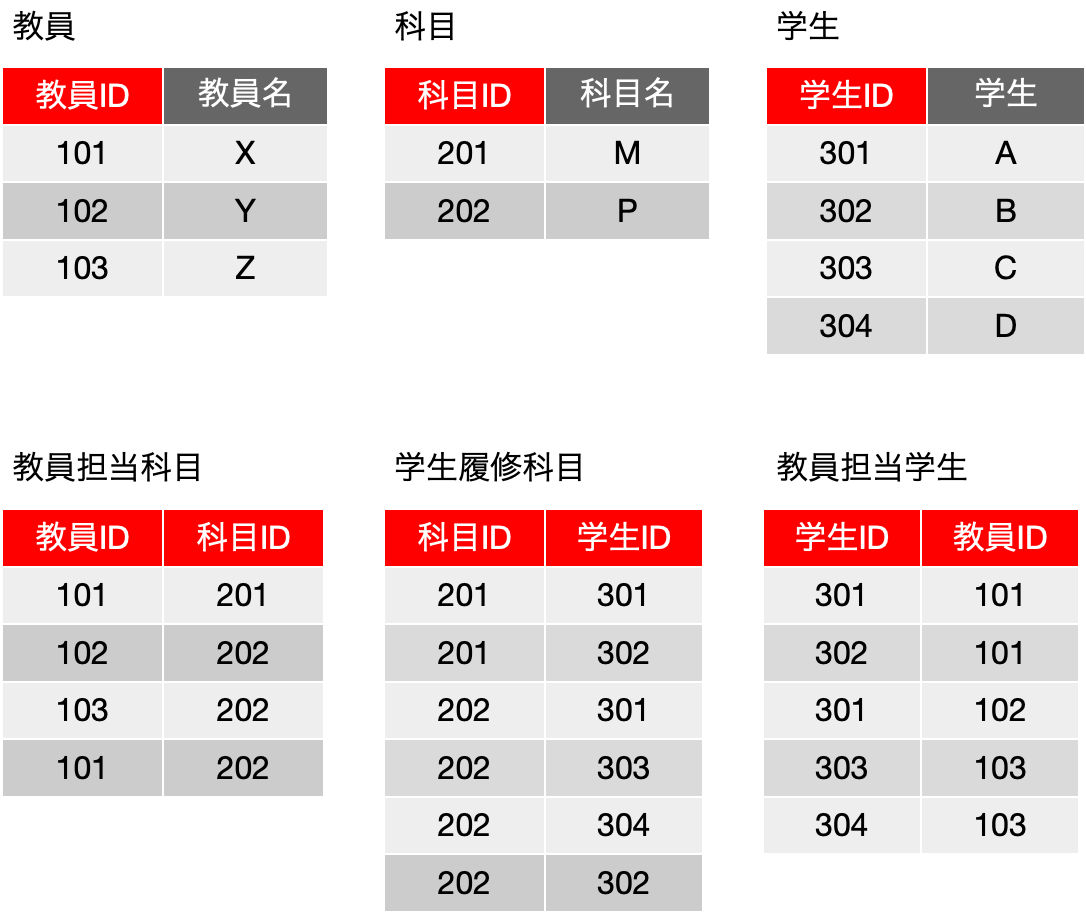
ここで、新たに新規登録がどんどん進む場面は、そんなにややこしくないでしょう。学生がある科目を履修したいとしたら、「学生履修科目」にまずは追加し、そして教務の担当者が、教員担当科目を参照しながら担当教員を適当に割り当てて、教員担当学生に行を追加します。おっと、ここで、「担当教員を適当に割り当てて」という人手が入ってしまっていますが、そういうワークフローにしましょう。
そして、たくさんの学生の履修登録が終わった後、教員の割り当てに変化が発生したとします。例えば、教員担当科目の4行目、X先生の科目Pの担当がなくなったとします。しかし、それは学生の履修がなくなるのならまだしも、通常は無くならないと思うので、X先生のクラスで科目Pを取ろうとしていた学生をZ先生など別のクラスに振り分けないといけません。教員担当学生はどう処理しましょう? これは元の「履修登録」の表に戻って考えないといけません。X先生に関するレコードは3つありますが、最初の二つは科目Mなので関係ありません。最後の科目Pのものについて担当をZ先生に切り替えたいわけです。ここで「教員担当科目」は単に、{101, 202} が消えるだけになります。「教員担当学生」はどうなるかといえば、{302, 101} を {302, 103} にしてしまうと、この学生が、X先生の科目Mを履修しているという情報がなくなります。結果的に、{302, 101}はそのままに{302, 103}を追加するという処理になります。ややこしいですね。自由に編集ができそうな気がしません。
このような問題がある場合は、現実のワークフローをよくチェックして、頻繁にあることは容易に進められるようにするのが、通常は考えることになります。そして、あり得ないことに対する対処は諦めます。滅多にないことは、何か対策を考えます。バッチ処理などということもあるかもしれません。
履修関係となると、一般にどの学校も、まずどんな科目があるかを決めて、それは履修登録開始時には確定していて、よほどのことがない限りその科目の存在は無くなったり増えたりはしないのが一般的です。同様に、担当する教員についても同様です。どんな科目があって、誰が担当するのか、つまり「教員担当科目」には、履修登録が開始されると変更はないという仮定があると考えられます。その上で、次のような表で構成することを考えました。履修登録は元の通りですが、履修登録前はレコードがないので、すでに決まっている科目と担当教員の情報を記録するために「教員担当科目」は必要になります。冗長ではあるかと思いますが、ユーザインタフェースを考えると、このような構成が良いと考えられます。
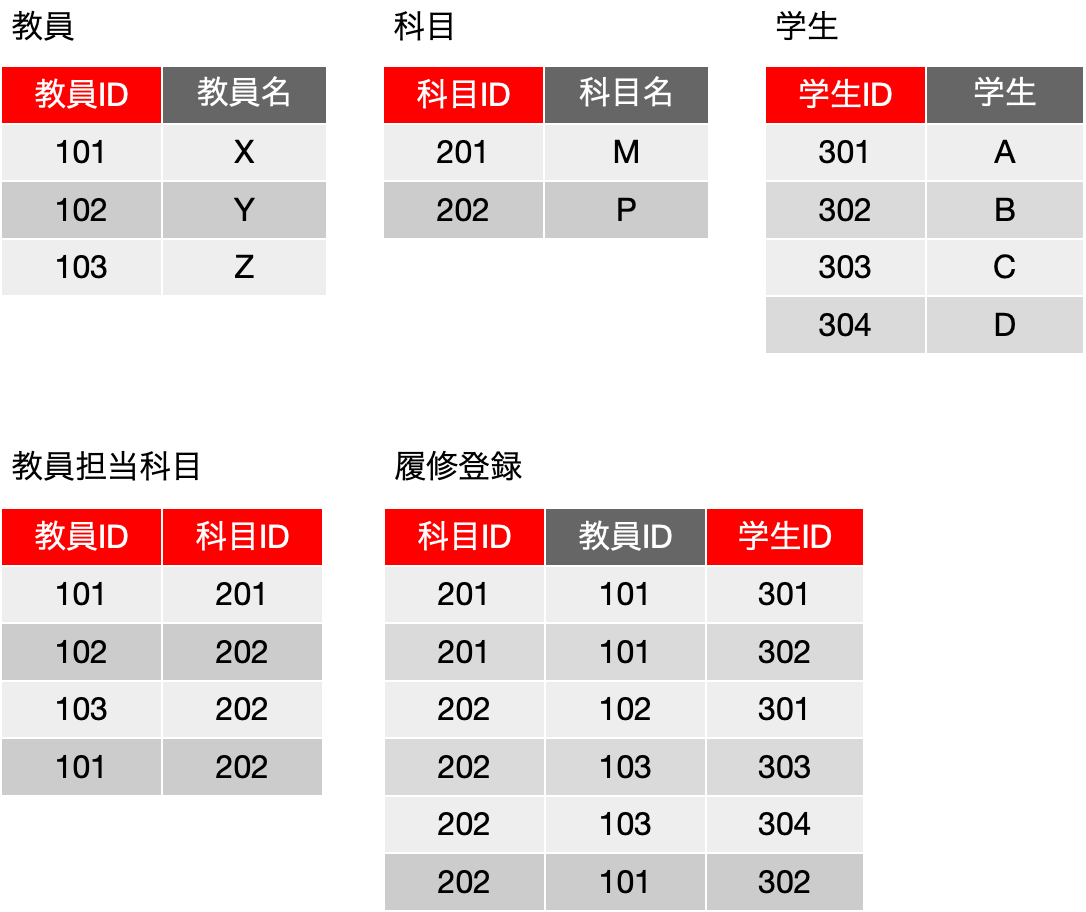
ある学生Aが科目Mを登録したいと希望があった場合、まず、履修登録に{201, 101, null} を追加します。締め切り後にCSVファイルを読み込むなどの方法だとそのような状態になると思われます。そして、教員IDについては、ポップアップメニュー等で、選択できるようにすれば、1人1人は手作業での指定になりますが、確定はできます。ポップアップメニューは「教員担当科目」の情報を利用することで、科目が、MならX、PならX, Y, Zが選択肢として登場するようにすればいいでしょう。また、履修登録と「教員」の表を結合して「教員名」を参照すると、決まっていない履修登録は、教員名がnullのものという判断ができるので、「履修登録一覧表_教員未選択」はこうしたルールを利用すれば作成が可能です。「履修登録」を直接作ってしまう方が、データの変更などの処理がやりやすくなるのであれば、もちろんワークフローの確認は必要だとしても、テーブルを分けない方法も選択肢としては有力だということです。
教員担当科目のレコードが1つなくなるような事態になった場合でも、履修登録をいじらなければ、その学生がその科目を履修しているという情報は保持されます。しかしながら、教員IDは対応する科目IDがないままになります。この場合、「教員担当科目」と「履修登録」のテーブル結合を、教員IDと科目IDの両方のフィールドを照合して行います。その時、「履修登録」のレコードは必ず残る照合を行います。その時、「履修登録」「教員担当科目」の順に記述し、前の方だけを残すので、「左結合」と呼ばれています。そして、右側の表にあるフィールドを参照すると、nullになっているものが、「教員ID」を正しく選択していないレコードというように判定が可能です。この方法で、教員IDを選択していないフィールドの判定も可能です。そうすれば、X先生が科目Pの担当を外れた後、教員IDを振り直す履修登録のレコードが絞り込まれるので、それらについて、地道にポップアップメニューを選択してもらうというワークフローが確立します。
どちらの設計が良いのかは、なかなか議論は収束しないかもしれませんが、結果的には、ユーザの要求が全ての出発点であり、実現しなければならないワークフローをきちんと考えて、そのワークフローが無理なく進められる設計に収束させる必要があるということです。開発作業自体が大変なのは仕方ないとしても、よりシンプルに開発できる選択肢があるのなら、常にそちらを目指すのが基本です。複雑なものよりシンプルなものの方が、ソフトウエアの品質が高くなる可能性が高いからです。もちろん、シンプルにするとワークフローが成り立たないとなれば、複雑化は免れないのですが、ワークフローを変えられないのかをユーザと折衝するなどして、開発は進むことになります。折り合いをつけるのは難しいですし、結局、何かこれから検討すべきことのコミットを求められるなど、厳しい局面もあるかもしれませんが、現在のソフトウェア技術とビジネス環境では、完成品を見ないと判断できないユーザが多いのも事実で、仕方ない面もあります。結果的に、プロジェクトをうまく進めるという能力に高いお金が払われるということにもなっています。
正規化の話は一旦ここで区切りとします。補足したいこともあれこれあるのですが、この先は少しランダムな感じでいくつか話題を振りたいと思います。