前回は、データはラベルか測定値だろうという話をしましたが、これはあるセミナーでここで説明しているような設計の話をしたとき、受講された方の一番の疑問だったらしく、細かく説明できなかったところなのです。こうしてブログに書く機会ができて個人的にはなんとなく一段落です。今回から、データの集まりである表についての話です。フィールドには名前が付いているので、その名前を手がかりにデータを取り出せますが、レコードにはそうした識別のための材料が、あるのかないのか?そこがポイントです。言い換えれば、レコードを特定する、あるいは一定の条件のレコードに絞り込むなどのいわゆる検索ができる状態の表でなければなりません。今回はとりあえず、架空の会社の例で出てきたこの表からスタートしましょう。営業部門が販売した明細を記録しているという想定です。
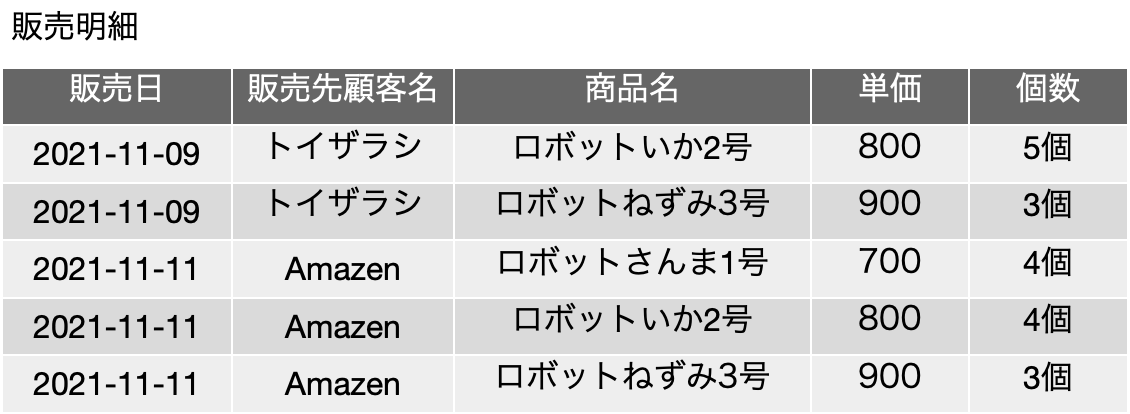
もちろん、いろんな意味で省略は多いのですが、この表では5つのフィールドがあってそれでこの会社の販売データが記録されているとします。今、たまたま、5つのフィールドが全て同一のレコードは存在しませんが、さらに3行目と同じレコードが6行目に追加されるという状況はあるでしょうか? あるいかないかは、結果的にその会社の状況によると思います。つまり、前提条件次第で変わります。ロボットさんま1号が非常によく売れて、Amazonは11月11日に何回も注文したとしましょう。個数は毎回違うかもしれませんが、同じかもしれません。個数まで同じなら、行の区別がつかなくなります。ちなみに、そういう状況にしますか? しないでしょう。それを手入力しているとしたら、完全に同じレコードが発生する状況で、「さっきの注文入れたっけ? まだだっけ?」という確認ができません。もちろん、その日の発注を頭からチェックするということもあるかもしれませんが、かえって効率を落とします。現実にはどうしましょう? 多分、販売日と同じかあるいは「入力日時」などのタイムスタンプのフィールドを増やすなど、同じ内容のレコードが発生しないような工夫をすると思います。ID番号を登場させるのは反則かもしれませんが、例えば、納品書IDがあれば、おそらくは区別できるでしょう。ただ、これも、同一の納品書で同じ商品に対する明細は2つ以上存在する事はない、つまり、単一の納品書では、明細には1つの商品は1回登場するか、全く登場しないかのいずれかになるという前提もあります。
まず、こうした表では完全に重複したレコードがないことを前提にします。その結果、表はレコードの集合であると考えることができるわけです。集合は重複した要素を持たないというのは定義です。ただ、センサー記録などでは、タイムスタンプを落としたとしたらそういうこともあるかもしれませんが、これは、センサー入力が重複しないことを前提としているからです。つまり、データ収集が重複がないということがほぼ保証できるような自動化プログラムで行われているような場合には、後から集計した結果が重要であり、元データに重複はあるかもしれませんが、現実は正しく記録されているとも言えます。今回はそのような状況は特殊事例として除外してください。もっとも、そのような場合でもタイムスタンプなどを記録することで完全な重複がないようにするのはおそらく一般的であると思います。
ここで「関数従属性」という考え方を導入します。あるフィールドXの値が決まると、別のフィールドYの値が決まるという考え方です。Wikipediaに倣って、「FD: X → Y 」と記述しましょう。X、Yはいずれも属性の集合です。前の販売明細の表で言えば、商品名に対する単価は、商品名が決まれば単価がどうやら確定するようなので、「FD1: {商品名} → {単価}」とみなします。あるフィールドの値が別のフィールドの値で決まってしまうという特徴が、表全体に渡って成り立つかどうかを検討します。では、販売先顧客名と単価はどうでしょう? たまたまある顧客が同一の商品しか注文しないと表の中では関数従属性があるように見えるかもしれませんが、顧客は複数の商品から選択するという前提があれば、単価は顧客では決まらず商品によってのみ決まるので、一般には関数従属性はないとみなすのが自然です。「関数従属性」と言うと名前が難しそうで、かつ数学的に記述するとさらに難しそうですが、「現実はどうなっている」ということが前提にある概念です。関数だから、その内部の計算方法は?などと疑問に持つかもしれませんが、ここでの関数は「入力を与えれば値が返る」という意味の抽象的な関数で、一般にはプログラムや数式では書けなくはないものの完全には書きにくいものです。データの集合がそういう性質を持つという議論です。
この関数従属性を手がかりにして、「レコードを一意に特定できるフィールドの集合」を考えます。この「レコードを」というところがまずポイントで、この性質を見極めておかないと、実用上支障が出そうです。そして、「一意に」というのも重要です。何か特定のデータに特定できるということです。販売明細は5つのフィールドがあるので、つまりはそれら全てのフィールドを決定可能なフィールドの集合Xとして、「FD2: X → {販売日, 販売先顧客, 商品名, 単価, 個数}」を満たすXを認識する必要があります。この概念を一般に「キー」と呼びます。例えば、Xには矢印の先そのもの、つまり全部のフィールドは多分含まれるでしょう。つまり、Xの1つは「A1 = {販売日, 販売先顧客, 商品名, 単価, 個数}」になります。
販売日がこれ、販売先顧客はこれ、商品名はこれ、単価はこれ、個数はこれ、と列挙すれば、その値を持つレコードを探してきて1つのレコードが特定できると言うことです。販売日がなかったらどうでしょう。同一顧客に同一商品を同一個数、別の日に販売した場合、どっちのレコードなのかが区別がつかなくなり、キーの役割を果たしません。ここですでにFD1が見つかっているとすれば、単価は商品名から求められるため、キーの構成要素としてなくてもいいということになります。つまり、単価を知らなくても、どのレコードかは特定可能なので、「FD2: {販売日, 販売先顧客, 商品名, 個数} → {販売日, 販売先顧客, 商品名, 単価, 個数}」となり、「A2 = {販売日, 販売先顧客, 商品名, 個数}」もFD2のXとして成り立ちます。
このように、キーは複数のフィールドの組み合わせも取り得ます。考えられるありとあらゆるキーを集めたものは「スーパーキー」と呼ばれます。ここまでの議論だと、{A1, A2}がスーパーキーです。その中で、余分なものがないもの、つまりなるべく要素数を少なくとしたものが「候補キー」と呼ばれます。つまり、候補キーとしては「{A2}」となります。さらに、候補キーの中で、実際にシステムの中でレコードの特定に使うものが「主キー」と呼ばれます。ここではA2しかないので、A2を主キーとすることになりますが、現実にはフィールドが増えた時などにもう少し候補キーを探すことになるでしょう。4つのフィールドで常に検索するというのはちょっと面倒ですね。
ここで、IDフィールドを販売明細に加えてみます。現実にやっていることの説明が必要ですね。「販売明細ID」フィールドを追加して、一意な数値をつけてみました。

ここで新たに、A3 = {販売明細ID}が、スーパーキー、候補キーの仲間に入りました。スーパーキーを全部挙げるのは実は大変です。A4 = {販売明細ID, 販売日}、A5 = {販売明細ID, 販売先顧客名} … などと、結果的には販売明細IDとの他のフィールドとのあらゆる組み合わせが、レコードの特定が可能です。全部列挙大会をやってもいいのですが、疲れるのでやめます。販売明細ID単体でレコードの特定が可能なので、冗長性を無視して「可能である」と言う点だけに注目すれば、そうなります。候補キーは冗長なものが全部排除されるとしたら、{A2, A3}となるでしょう。そして主キーはより単純なA3になると言うのが一般的な考え方の1つになります。それがいいかどうかは、結果的にどんなシステムを作るかと言うことと擦り合わせは必要ですが、キーの定義はこのようになります。スーパーキーに関して、一度は手で全部書くのが学習になるかもしれませんが、実用的にはスーパーキーを全部列挙するような仕様書は誰も読みません。場合によっては候補キーを挙げて、2つのうちどちらを選んだかと言う理由を記述する場合もあるかもしれませんが、設計者は候補キーが頭の中でサッと浮かび、サクッと主キーをどうするかという議論に入ります。今回の場合A3のように決まったことしか仕様書に書いてないとしても、A2のような実データフィールドの主キーはあるものの、番号振ってあって一意だからこっちでいいよね的なフィーリングは行間にしか書かれてないことが普通です。
キーの中でも3種類もあってややこしいと思われるかもしれませんが、設計上は主キーを特定できればそれでOKです。しかしながら、なぜ、主キーが存在する意味があるのかと言うことを定義するために、関数従属性という考え方、あらゆるキーから意味のあるキーの選択といったことを経て、主キーの考え方に至ります。スーパーキーのように一度「全て」を考えて絞る、ここでは冗長性のないもの、そして実用性を考えるということに分解して仕組みが成り立っているということは、結構重要なのではないでしょうか。