昨日は1対多について説明をしました。1対多の関係を見つけることが非常に重要で、リレーショナルデータベースはそうした複数の表に分割してデータを記録することで、多彩なデータ構造を実現しているのがポイントです。では、1対1の関係というのはどういうものでしょうか?
ここで、次のように、「商品」と、「商品在庫数」というエンティティを考えてみますが、ここで1つの商品について、1つの数値で在庫数が管理されているとします。倉庫や拠点が複数あるような会社ではこれも1対多になりそうですが、ここではこの関係が1対1であるとします。そうすると、2つ目の図にあるように、ある商品に対して、その在庫数が1本の線で結ばれます。線は必ず1本であって、商品あるいは商品在庫数の側から複数の線が引かれることはないと考えます。1対多は、「多になる可能性があれば、関係は多とみなす」と説明しましたが、1対1の場合は「常に1つのものと関係する」という意味で使われます。1つ目の図はER図とも言えますが、2つ目の図はレコードを1つのボックスとして模して考えたオブジェクト図的なものです。この時、やはり具体的に表で考えれば、それぞれに商品IDフィールドを備えた2つの表にすることが考えられます。同一の商品IDを持つレコードが対応関係にあります。
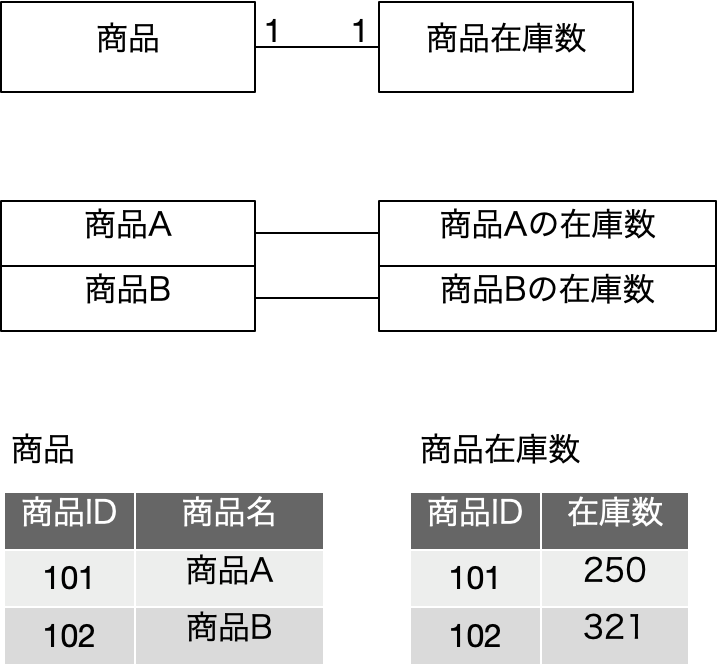
表を作るには、まず、商品があって、商品にそれぞれ一意な商品IDの番号を振ります。そして、商品在庫数は、すでに存在する商品IDの値を商品IDに入れて、在庫数をさらに別のフィールドで管理します。商品の側の商品IDに重複がないのは当然ですが、商品在庫数の側でも商品IDは複数存在することは問題が発生します。仮に、101に対するレコードが商品在庫数に複数あれば、「どちらが正しいのか?」という問題が発生するので、なんらかの方法で、商品IDの重複がないようにしなければなりません。システム上ではもちろんバグがないように作ると同時に、重複があればエラーになるような仕組みを使うのかもしれません。
ちなみに、商品IDを重複させていいのかということも気になるかもしません。一方の表の商品IDフィールドがないものとして考えるとどうでしょう?そちらの表の各行のレコードは、その値がどの商品のものなのか特定できなくなります。なので、商品IDが必要になるのです。
しかし、この2つの表をみていて思うことは、次のような表にまとめてしまえるのではないかということです。ちょうど、商品IDが同じような並びをしているので、2つの表を左右に並べてくっつけたような感じになります。前の2つの表でも管理はできそうですが、次のような表でもデータは問題なく管理できそうです。つまり、機能的にはほぼ同一と言えませんでしょうか?
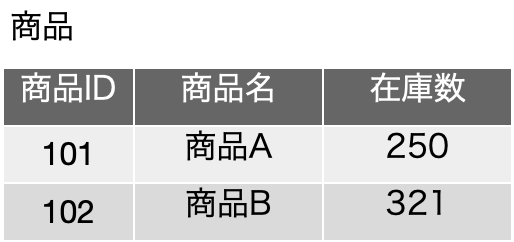
多くの場合は1対1の関係は、同一の表にまとめてしまえることが一般的であったりします。つまり、商品と在庫数の関係は、1対1ですが、この場合、商品という抽象概念、つまり表の1行として構成されている存在に対して、在庫数はその商品の属性になります。ここでは、「商品」「商品ID」「商品名」「在庫数」が、商品に関して登場する概念ですが、「商品」以外はみんな「値を持つ」ことがまず挙げられます。「商品」はこれら値を持つものの集合のように思えないでしょうか?つまり、IDや名前、在庫数をひっくるめて商品なのです。そして、これら、「商品」「商品ID」「商品名」「在庫数」については、2つの要素の組み合わせ全てについて1対1の関係になっています。であれば、値のある「商品ID」「商品名」「在庫数」がフィールドになり、それらを総称的に表現している「商品」が表の名前になるという考え方ができるのです。
そうなると、設計の上で、1対1の関係は、全部同一の表、つまりER図的には1つのボックスにまとめてしまうのかというと、必ずしもそうではありません。設計の段階に応じていろいろな考え方が適用されます。例えば、要求段階で作成されるようなビジネスモデルのクラス図などでは、商品に対して在庫の管理が必要であることを明示するために、あえて別のボックスで示す場合もあります。おそらく、在庫が何に対しての在庫なのかが明白でないような場合、「近々、関係性を正しく定義して、どこかに収める」ということを意図したメモのような感じで1対1の存在を記載する場合もあります。実際、それは属性なのか、それとも表なのかが明白でないような場合も時々発生します。その場合、とりあえず1対1の関係が図に出てきます。ただ、完全に仕様が把握した上でのデータベース設計では1対1は不要とも考えられますが、システムの構成やあるいはロジックの構成によっては1対1の表、つまり、1つの表を分割することもあり得ます。例えば、それぞれが異なるサーバで発生するデータである場合は、別々の表で管理する方が、後から統合する手間がおそらく減るのではないでしょうか? こうした実装上の工夫という点では1対1の表の存在も無視できないでしょう。また、対応する1対1のテーブルの一方の存在そのものが、何か処理をしたフラグ的な使い方もあるかもしれません。ワークフローが進んで行く時に、順次フィールドを更新するよりも、それぞれ別々の表で管理して、1対1のレコードが増えていくような作り方をする方が整理される感じがする場合もあると思われます。
なお、フィールドが多数になると1対1の表に分割というのはあるかもしれませんが、分割基準が雑だったりするとかえってどっちにあるのかわからんということになります。あまり多数だから減らすためというのはモチベーションとしは弱いと思われます。ちなみに、フィールドが数万個にもなるというのは、設計そのものをまずは疑います。通常、横に展開、つまりフィールドの定義が必要と思っても、あまりに多くなるのなら、それは縦に展開、つまりレコードを増やして記録する方法を考え、その手法で設計を考えることになるでしょう。ただ、縦に展開するのが必ずしも良いとは限らず、最終的には要求との擦り合わせが必要ですが、第一正規形を満たすという意味でも、多数のフィールドは「同質のものの繰り返し」があるのかもしれません。ここで何が言いたいかというと、病院の検査結果のデータベースを例に出すとわかりやすいのですが、これはまた別の機会にしましょう。
ということで、残るは多対多ですが、これは次回に説明します。