前回までで、バウンダリーを詳細化するところまでを記述したが、またまた時間が空いてしまった。サーバーが起動しなかったり、開発の作業に集中したりなどしていた。
さて、続いて、コントロールの中を詳細化する。実際に詳細化できるのかを検討する前に、なぜ詳細化しなければならないのかを改めて検討しておく。多くのフレームワークは、コントローラーという1つのクラスを作ることからチュートリアルが始まる結果、1つのクラスで作るものだと思い込んでいたり、あるいはクラスを複数用意するとしても、連携する手法は特にフレームワークで用意されていないなど、「巨大な1つのコントローラー」を用意する素地が、意図しなかったとしてもフレームワークがお膳立てしているという状況であるとも言えるだろう。一方、最近、ある仕事で、ethnamというグリーが当初開発したethnaの後継というPHPのフレームワークを使う機会があった。このフレームワークは改めて、フレームワークの機能との対比を考えるときの題材の1つにする。このフレームワークの特徴は、コントローラーというクラスを作るのではなく、中心的なコントローラーに対応する決められた名前のメソッドがあるという点である。決められていることは、prepare、perform、preforwardという3つのメソッドが順番に呼び出されるということだ。prepareは結果次第でのちの作業をキャンセルできることから、バウンダリに近いところにあってデータの検証などを行う入力用ビューコントローラーと言える。一方、最後のpreforwardは、出力の直前に呼び出されることから、出力用のビューコントローラーと言える。中間のperfomは、まさに、コントローラーとしての役割を持ち、ここでモデルへ働きかけるなどのビジネスロジックとのやりとりを記述することになる。これらのメソッドが保持されるクラスは決められた場所に作成するようになっているため、コントローラーの粒度はクラスよりもメソッドの方が適切だと言えるフレームワークである。コントローラーというクラスを作る話と、コントローラー相当のメソッドがあるという話は、設計の上では極めて大きな違いがある。抽象的な記述から、フレームワークにあった実装を行うという方針でもいいのだが、この方針だと属人的な実装テクニックや、あるいは「言わずもがな」なルールを読み解かないといけない場面が多そうだ。結果的に、大きな単位で何をすべきかは考えるのがモデルの1つの目的ではあるもの、コードの段階ではもっとも粒度の低い1つのステートメントを記述しなければならない。ならば、コントロールの中の粒度をより細かくして一度考えてみる必要があると思われる。また、フレームワークの機能との対比をする上では、やはり一度は細かな処理に分ける必要があると考える。
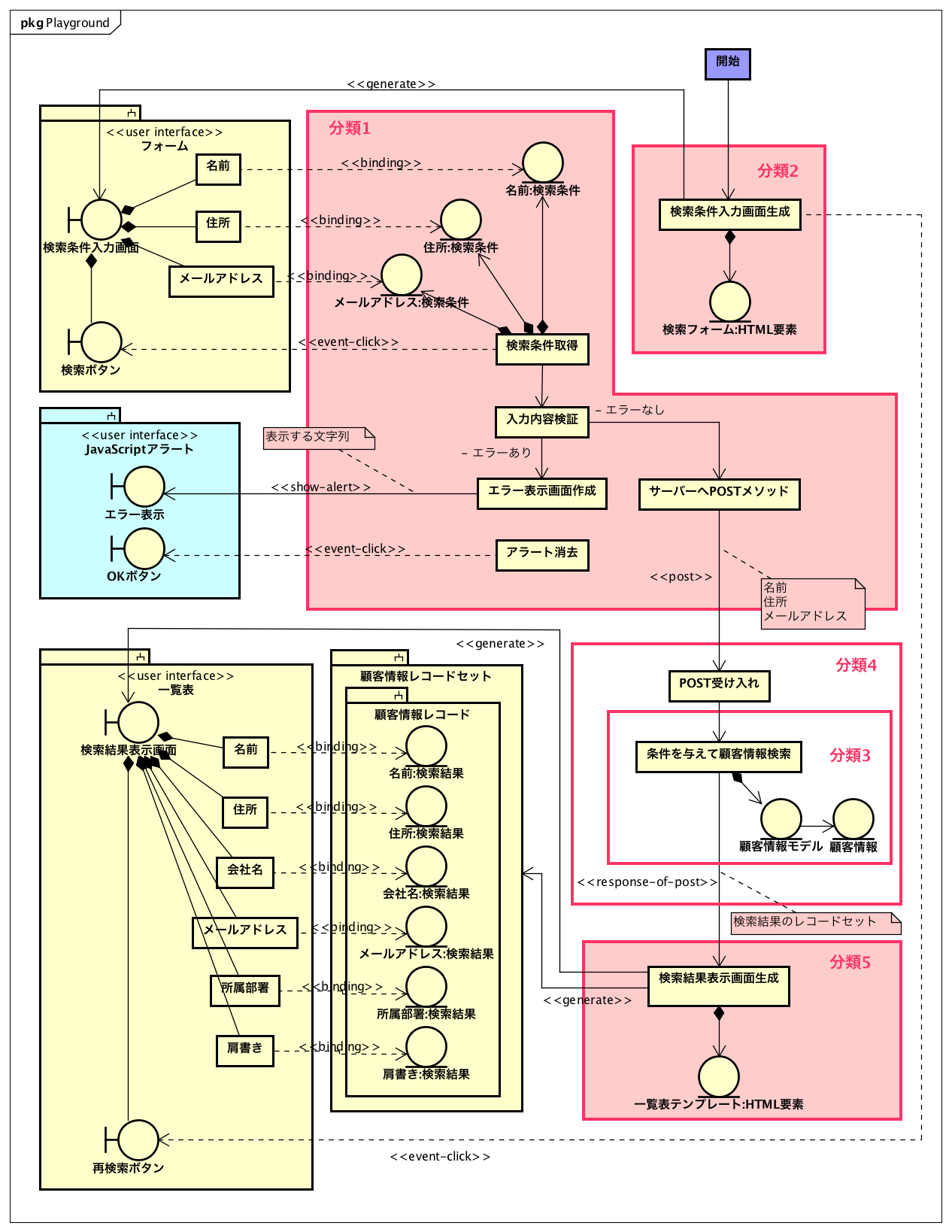
まず、次の図は、クラス図を元に、一覧と検索を持つようなWebページのモデルを記述したものである。astah*でクラス図を用意して、バウンダリーは大まかながら、主要なコンポーネントを抜き出して1画面を枠で囲う形式で記述した。モデルは、この段階では概略として記述し、コントロールの中の処理の1ステップずつをクラスで記述した。

この図を描きながら考えたことは、まず、処理には順序があるということである。入力されるバウンダリーから、出力されるバウンダリーに向かっていけば判別つかなくもないが、図を明確にするには、処理の順序を矢印で示し、どちらが先なのかを記載する必要があるということだ。
続いて、どうしても「分岐」は必要になる。前の図は、クラス図で適当に書いたものである。この点から、前の図にはないが、繰り返しや並行処理的なものを記述が必要になることは十分に可能性があるがある。
ここまでに至るまでにすでにお気付きのように、コントロールの処理を詳細化したものは「フローチャート」なのである。もっとも、UMLでフローチャートに近いものといえば、アクティビティ図である。前述のモデルをastah*のアクティビティ図で記述してみた。ほとんど同様な図が描かれているが、バウンダリーやエンティティのアイコンに接続された矢印が今ひとつうまく処理できていない。astah*でこの状態にするには、オブジェクトのオブジェクト名を空、ベースクラスをバウンダリーで使ったクラス名を選択することででき、その後に右クリックして、標準アイコンを選択するもこのようになってしまった。フローチャート部分は作りやすいが、astah*での作業は明らかにクラス図の方がみやすい図を作れる。

この先、図をどうやって作成するかは問題だが、とりあえず、クラス図に戻り、バウンダリーの詳細化を行った。画面要素のキーあるいはフィールドの記述をコンポジションでバウンダリーに追加したが、「JavaScriptアラート」のような手法の指定もあるかもしれない。特にこういう場合の記述はないと思われるので、点線矢印で適用先を記述した。

このモデルから実装の方針をもう少し進めよう。バウンダリーの集合が3つあるが中央にある「エラー表示」はシンプルにJavaScriptのアラートを使うとしたら、「エラー表示画面作成」は、単にJavaScriptでwindows.alert(“…”);を実行することである。また、検索ボタンを押した時には検索条件はクライアント側にあるのだから、赤線枠で囲った部分は「検索条件入力画面」のページの中にJavaScriptでの記述が行えることになる。また、そうなれば、エラー表示に伴う「OKボタン」のクリックによる「検索条件入力画面生成」の処理を行う必要はない。その画面を崩さずにアラート表示したのであれば、単にアラートの表示だけでもOKである。結果的に、「エラー表示」は「検索条件入力画面」の一部となった。あとは、検索条件の検証ルールが与えられれば、実装はできそうである。

残りのアクティビティを分類して見る。分類の基準は、順次実行するアクティビティであるという点になる。つまり、まとまって実行されるアクティビティのセットは少なくともある段階では同一のメソッドの連続したステートメントに記述されていることになるので、その点から分類をする。そうなると、「検索条件入力画面生成」が1つ、さらに「条件を与えて顧客情報検索」「検索結果表示画面生成」が別の分類となり、図中ではそれぞれ分類2と分類4で囲った。分類4の中にある2つのアクティビティは、データ検索とビューの生成といった違うことを行なっている。そうであるのなら、さらに分類すべきであるとも考え、図中の分類3で囲った部分が抽出される。結果的に全部バラバラということにもなるが、分類4のみ2つのアクティビティからなるとも言える。
ここで、まず、分類3の「条件を与えて顧客情報検索」であるが、データを扱っているので明らかにモデルに関わる機能である。そして、いくつかある「画面生成」は明らかにビューに関わる機能である。図の右側に対応するコントロールを記述したが、それぞれ対応するオブジェクトを記述できることから、この図はロバストネス図をさらに詳細したものであるという点は明白である。
実際に実装するとなると、分類3「条件を与えて顧客情報検索」はデータ処理が含まれており明らかにサーバーサイドの処理となる。2つの「画面生成」は、例えばPHPのフレームワークのCodeIgniterであれば、サーバーサイドで記述をする。これくらいの機能ものだと1つのコントローラークラスにまとめてしまってもさほどのコード量ではないと考えるかもしれない。
ここで重要な点がある。それは分類1はクライアント、分類2〜4はサーバーサイドでの実装を行う点が、ある状況では決定づけられてしまうということだ。一般にはサーバーサイドのフレームワークの場合「画面生成」という処理から先は自動的に行われる。画面生成に必要な状況をコントローラーで作り出すのが開発作業である。そこで注目したいのは、考慮すべきクライアントとサーバーの切れ目である。画面生成はどちらかといえば、フレームワークでほぼ自動化されいているので、考慮対象外である。一方、「入力内容検証」後にエラーなしとなった場合、「条件を与えて顧客情報検索」に移行する場面がある。ここは矢印が1つだが、実際には、サーバー側にはPOSTメソッドの受け入れから、該当する処理が記述されたメソッドを呼び出すまでの処理(例えば「ルーティング」など)が入ることになる。これらは自動的にできないメソッドも多い。
これらの検討結果を加えたモデルは次のとおりである。まず、検索条件の入力はフォーム(HTMLのformタグ)で記述することにして、フォーム自体をサブシステムとして記述する。入力結果を検証した結果、サーバーへPOSTするのは、ブラウザが本来持っている機能である。また、POSTを受け入れるのフレームワークあるいはCGIとして持っている仕組みを利用できるので、これらは実装対象ではない。ただし、正しく受け入れがなされて意図したメソッドが呼び出されるようにするための処置は必要であり、それはフレームワークごとに違っている。

このように小規模なWebアプリケーションでもクライアントとサーバーの分離やフレームワークのサポートの有無を考慮しながら、実装ポイントを探るということが必要になる。従来のオブジェクト指向を基調としたモデルでは粒度が粗く、実装の具体的な手法までをモデルまで記述することはしなかった。言い換えれば、実装した結果の要約を逆解析するようなものであったとも言える。現実の開発でここまであるいはさらに細かい詳細化がモデルの段階で必要かどうかという議論はあるだろうが、その点は別にしてもWeb開発の学習やフレームワークの理解にはこうした手法が有効であると考える。