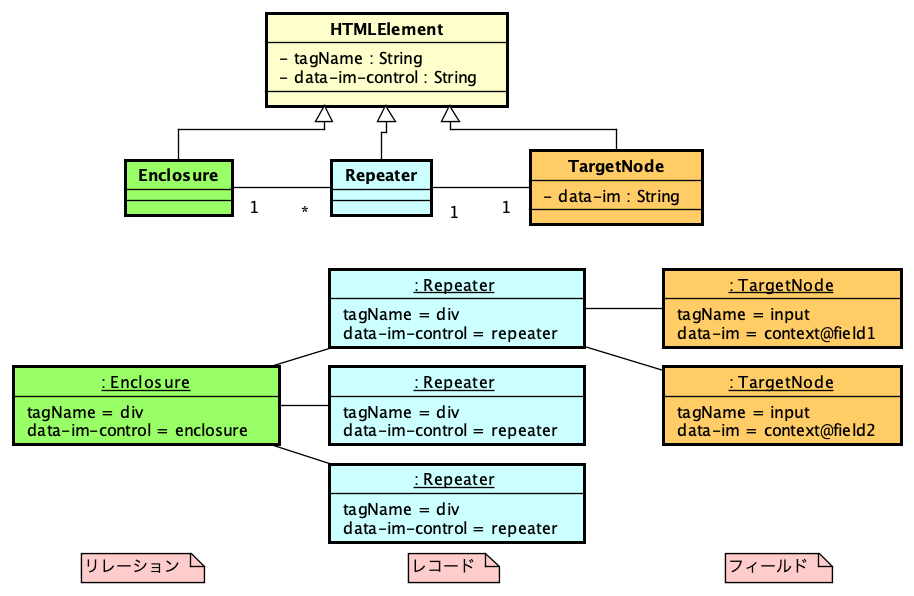
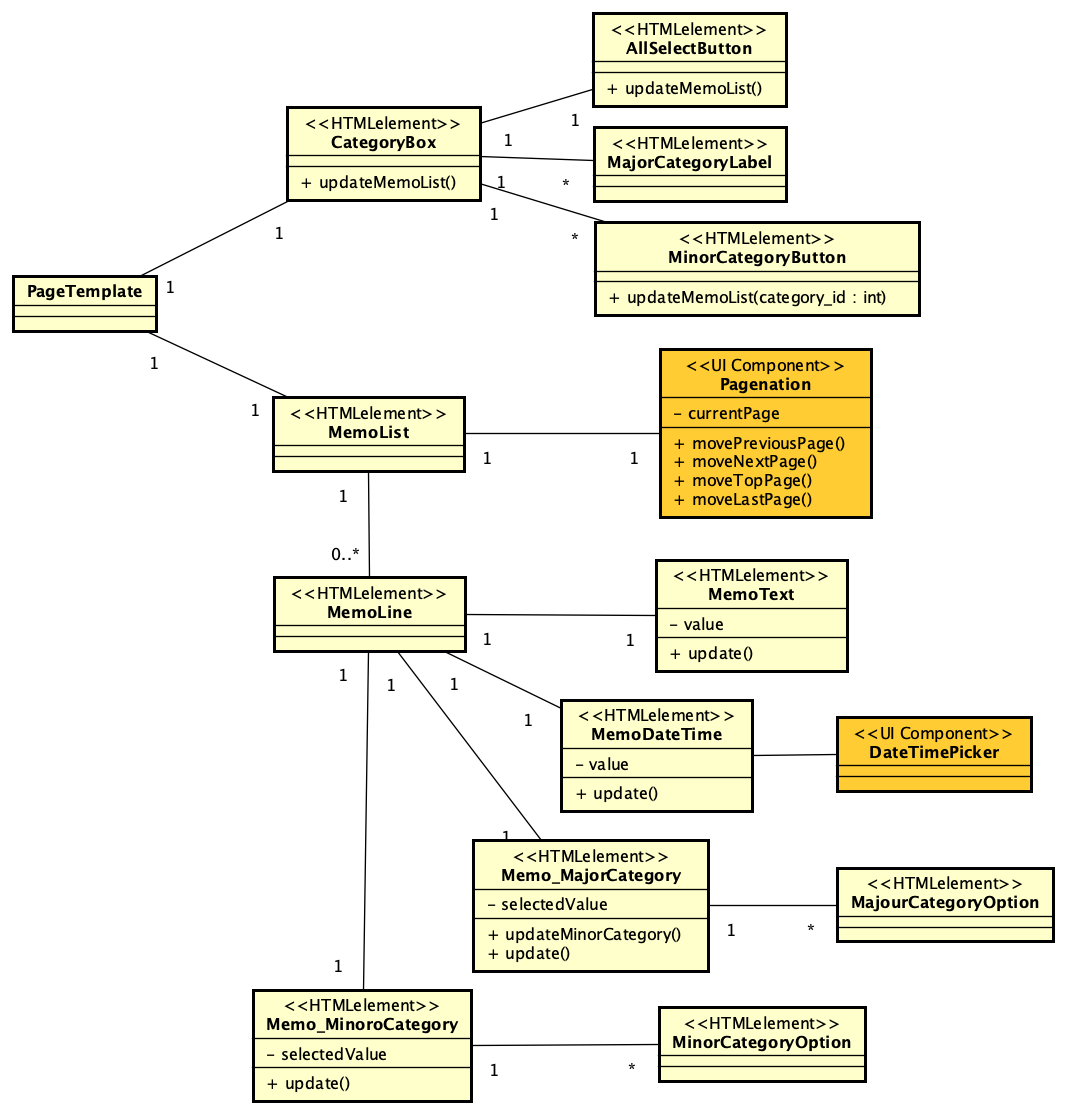
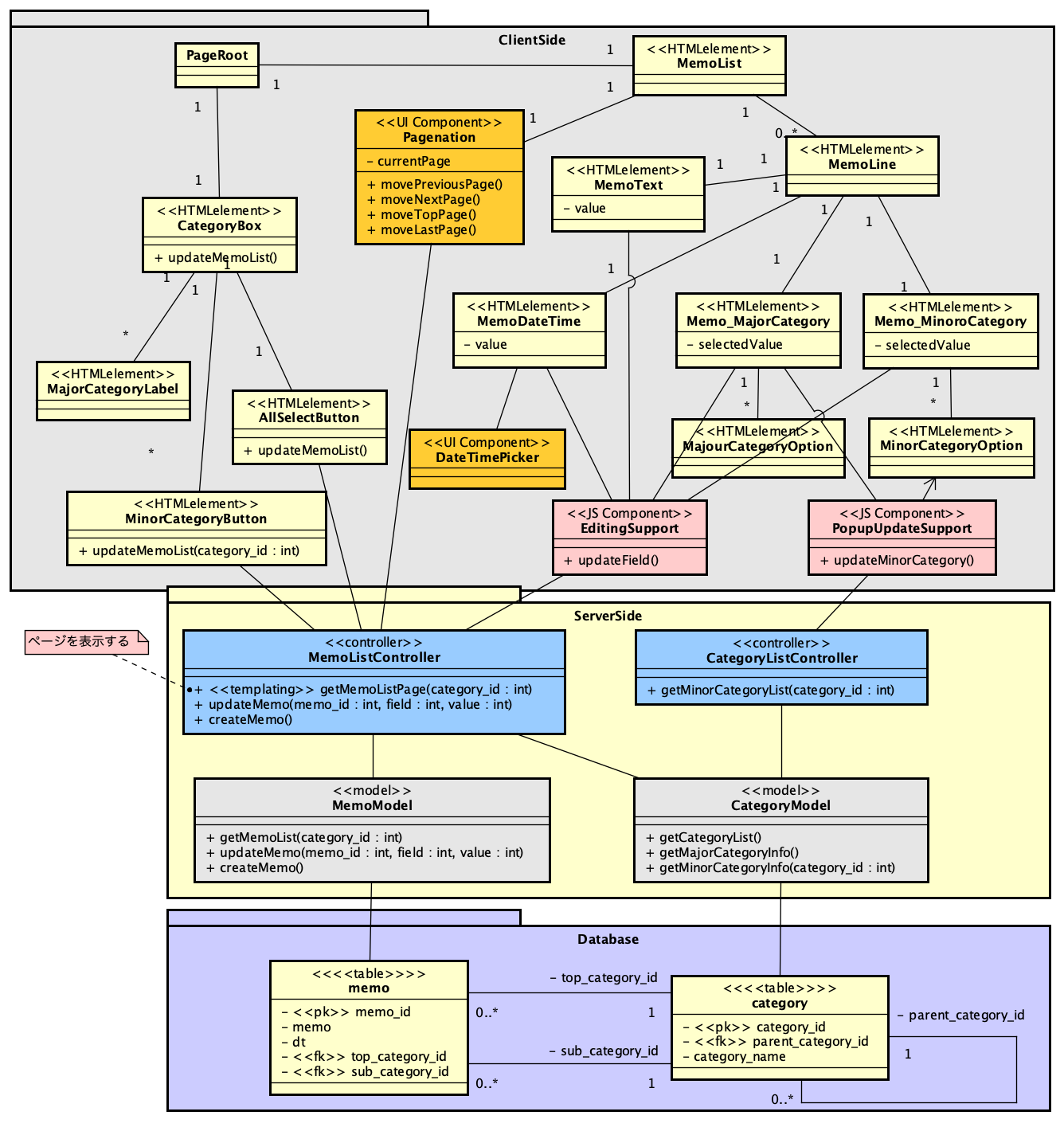
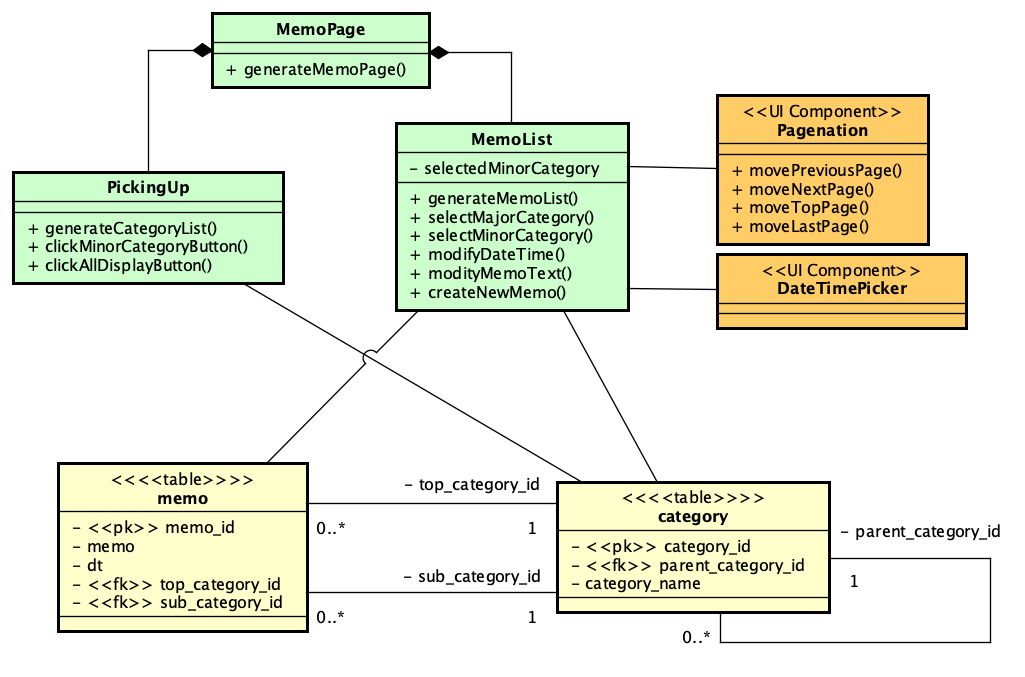
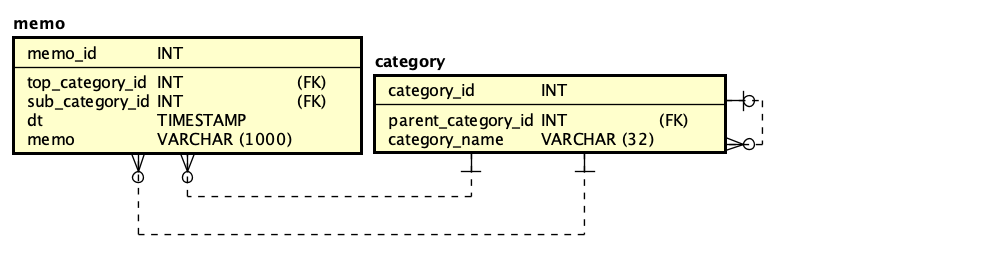
PHPでSAML認証を実現するライブラリ、SimpleSAMLphpが、2023年からVer.2となりました。SAML 2.0に対応するのは以前から、つまり、SimpleSAMLphp Ver.1でもSAML 2.0に対応していましたが、どちらのバージョンも「2」になったということです。バージョン記述がややこしいですが、まあ、これを読んでいる方は慣れているかと思いますので、先に進みます。
この記事は2023 7/1に最初に記述しましたが、状況が変わりつつあるのとノウハウが少し溜まったこともあって、2024/3/2までに追記を何度か行なっています。
INTER-MediatorはSimpleSAMLphpベースでSAML対応しています(勉強会での発表ビデオはこちらです)。SAMLというか、Shibboleth認証の案件を実際に行ったこともあります。ということで、SimpleSAMLphp Ver.2は早めにチェックしようと思いつつ、今になってしまいました。
SimpleSAMLphp Ver.2になっての違いはこちらのページに記載されています。かいつまんで説明すると、Shibboleth 1.3、SAML 1.1にはもう対応しないということで、SAML 2.0のみ対応となっています。ということは、Shibboleth案件は、Ver.1.19.xあたりで作業する必要があるということになります。(この部分、勘違いでした。ShibbolethのVer.2以降に対応しているということですかね。あまり明確には書いていませんが、今時の動いているShibboleth IDPに対しては使えるということのようです。)設定ファイル名は変わっていないものの、「作り直したほうがいい」となっていますので、手順を含めて、引き続いてそのあたりは説明したいと思います。それから、いくつかの重要なパスも変わっています。これも説明で紹介します。
INTER-MediatorのSAMLのテストは、SimpleSAMLphpによるIdPと、SimpleSAMLphpによるSPを使って行うようにセットアップをしてあるのですが、改めて、この環境を構築し直しを始めました。その記録をブログにつけていこうと思います。IdPには、テスト用のアカウントをいくつか記録する程度で、そこから別の認証サービスを使うまではとりあえずは考えていません。
テスト環境ですが、Ubuntu Server 22.0.4 LTSです。よって、PHPは8.1です。普通に、Apache2、PHPとモジュールをインストールしました。INTER-Mediatorをインストールする以外には、PHPのSOAPモジュールを追加するだけで大丈夫でした。 テスト用のアプリケーションも当然ながらINTER-Mediatorで作ってあるのですが、SimpleSAMLphpのVer.1とVer.2の相互運用も考えないといけないのかなとも考えられます。
さて、数年前に一生懸命検証をした時の1つの結論は、「ちゃんとドメインを切って、正しい証明書をセットアップしたサイト」にするということです。その時の設定はまだあって、IdP用にidp.inter-mediator.com、アプリケーションとSPはdemo.inter-mediator.com/saml-trialにしました。いずれも、Let’s Encryptではありますが、それぞれ有効な証明書が動き、通信はすべてHTTPSで動くという状態になっています。
IdPサイトの構築
IdPのサイトは、SimpleSAMLphpのコードをそのまま使って構築します。Ubuntuなので、/var/www以下に、例えば、以下ようなコマンドで、コードを取り出します。バージョンごとにタグがあるので、Ver.2系列の最新版である2.1.4をインストールすることにします。そして、composerを動かして、必要なライブラリのインストールを行います。
cd /var/www
git clone https://github.com/simplesamlphp/simplesamlphp simplesaml-idp
cd simplesaml-idp
git checkout v2.1.4
composer update/var/www以下は、ログインしたユーザであれば書き込みできるという前提で説明をします。また、ログインしたユーザはsudoコマンド可能であって、root権限が必要な処理はsudoを利用するという方針でコマンドを示します。また、ログインユーザはadminsグループにも登録してあるものとします。
前述のコマンドで、/var/www/simplesaml-idpというディレクトリができ、そこにレポジトリの内容が展開されました。このディレクトリを公開するのかというと、そうではなくて、この中のpublicを公開します。以前はwwwというディレクトリでしたが、Ver.2でpublicという名前に変えたそうです。ということで、Apache2のidp.inter-mediator.comのサイト設定ファイルは、大体以下のような記述つまり、DocumentRootがある感じです(実際には証明書の設定などもあってもっとややこしい)。/simplesamlはIdPの設定ファイルに書かれているbaseurlpathの値でもあるので、とりあえずAliasを定義しておきます。
<VirtualHost *:443>
ServerAdmin info@inter-mediator.org
DocumentRoot /var/www/simplesaml-idp/public
ServerName idp.inter-mediator.com
Alias /simplesaml "/var/www/simplesaml-idp/public"
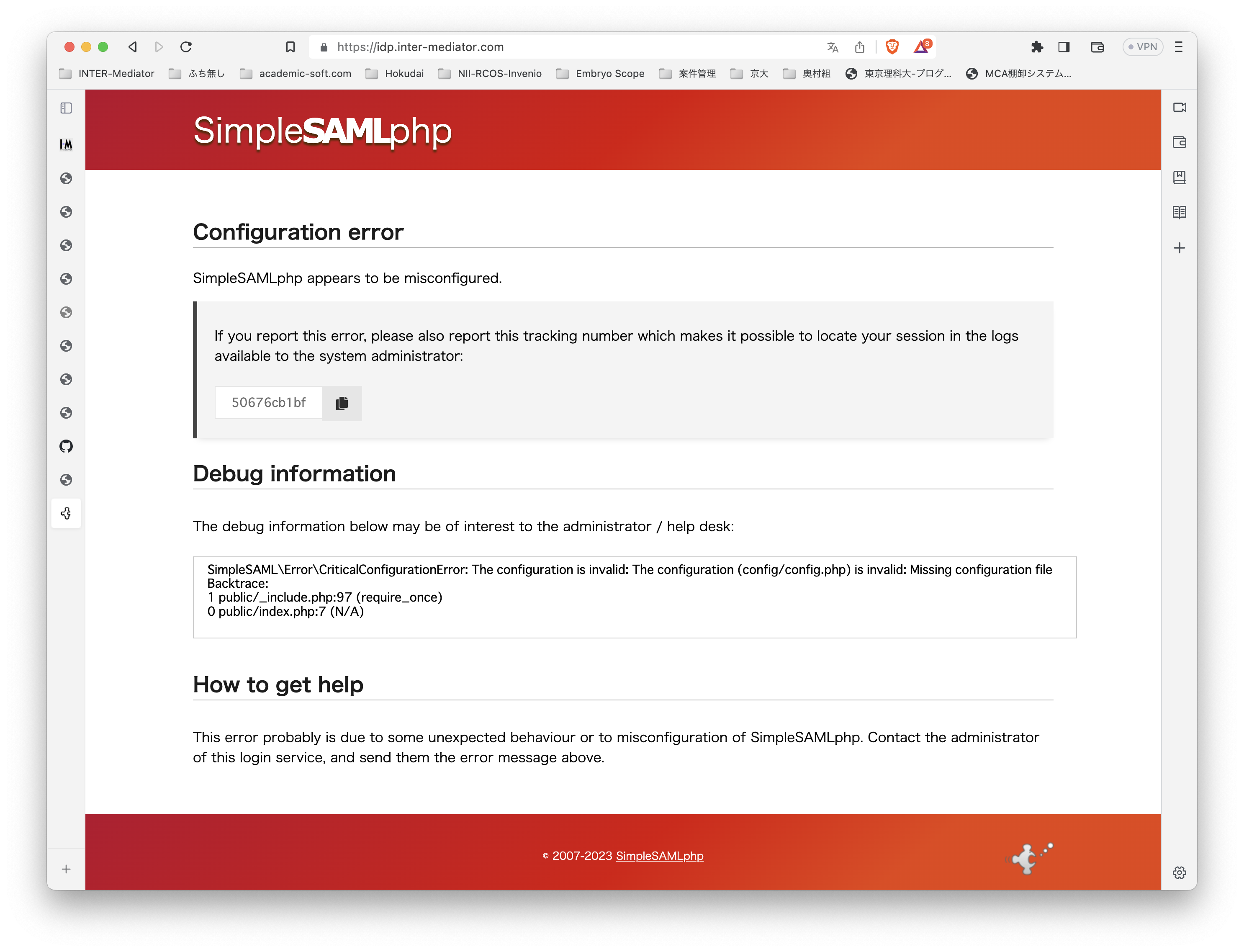
:さて、サーバを見てみましょう!という感じで開くと、次の通りです。当然、セットアップを何もしていないので、そのような表示が出るだけです。ちゃんと、設定ファイルがないとメッセージが出ています。
IdPが使う証明書を用意する
SAMLでは通信の暗号化のために証明書を使います。IdPで使用する証明書は、opensslコマンドを使って作成しますが、レポジトリのcertディレクトリに作るのが一番手軽です。このディレクトリに作った証明書関連のファイルは、フルパスを指定する必要がありません。例えば、以下のようなコマンドで作成できます。
cd /var/www/simplesaml-idp/cert
openssl req -newkey rsa:3072 -new -x509 -days 3652 -nodes \
-out idp.inter-mediator.com.crt -keyout idp.inter-mediator.com.pemコマンド例ではカレントディレクトリを明示するためにcdコマンドを随所で書くようにしますが、もちろん、コマンドの理解がある方は自分の状況に応じてコマンドを入れてください。そして、opensslコマンドの-outと-keyoutの2つのパラメータは実際に保存されるファイル名になるので、自分のドメイン等に変えるか、server.cert、privatekey.pemみたいな名前にするのが良いでしょう。
乱数生成などの後、入力を促されます。要するに大雑把な住所と組織などを入力します。以下は私が入力した例ですが、もちろん、ご自分の状況に合わせてください。Common Nameについては、FQDNを入れるのが良いと思われます。
Country Name (2 letter code) [AU]:JP
State or Province Name (full name) [Some-State]:Saitama
Locality Name (eg, city) []:Midori-ward
Organization Name (eg, company) [Internet Widgits Pty Ltd]:INTER-Mediator
Organizational Unit Name (eg, section) []:Authentication Support
Common Name (e.g. server FQDN or YOUR name) []:idp.inter-mediator.com
Email Address []:nii@msyk.netなお、生成されたキーファイルは、ownerだけが読み書きできて、gropuやeveryoneに対する読み出し権限すらありません。Apache2のプロセスのユーザ(Ubuntuではwww-data)が読み出し権限があるようにしなければなりません。しかしながら、アクセス権は、レポジトリの内容全体に設定した方が手軽でしょうから、アクセス権の設定は最後にまとめて行います。
configディレクトリの設定を行う
それでは、設定を進めましょう。まず、レポジトリのルートにあるconfigディレクトリの中身です。このファイルには3つの設定ファイルを作りますが、そのうち、config.phpとauthsources.phpの2つのファイルを用意します。このファイルはスクラッチから作るのではなく、ファイル名に.distが付いたテンプレートのファイルがあるので、それをコピーして用意します。まず、ファイルをコピーします。
cd /var/www/simplesaml-idp/config
cp authsources.php.dist authsources.php
cp config.php.dist config.phpconfig.phpファイルは、以下のポイントを修正します。 そのためにvimやnanoなどのエディタで開くことになりますが、その前に、以下のコマンドを入れて、secretsaltキーの値を生成しておきます。このことはファイルのコメントにも書かれてあり、以下のコマンドで生成して、出力結果をコピーしておきます。
LC_ALL=C tr -c -d '0123456789abcdefghijklmnopqrstuvwxyz' </dev/urandom | dd bs=32 count=1 2>/dev/null;echoそして、config.phpファイルを編集します。まず、technicalcontact*は、このサーバの管理者です。基本的には自分を指定すれば良いでしょう。secretsaltはファイルを開く前にコピーしたものを指定すればよく、文字列の中身を消してペーストします。auth.adminpasswordは、IdPのログインする管理者のパスワードです。
:
'technicalcontact_name' => 'Administrator',
'technicalcontact_email' => 'msyk@msyk.net',
:
'secretsalt' => 'whr5p645s3ig7nm9wxibfckllmjfvjl6',
:
'auth.adminpassword' => 'samltest5682',
:
'enable.saml20-idp' => true,
'enable.adfs-idp' => false,
:
'module.enable' => [
'exampleauth' => true,
'core' => true,
'admin' => true,
'saml' => true
],
enable.saml20-idpは、文字通り、IdPの機能をアクティブにします。module.enableは、exampleauthの値をtrueにしますが、これは、設定ファイルで認証ユーザを提供する仕組みをオンにします。もちろん、簡易的にテストができるようにということです。なお、’baseurlpath’キーの値は、デフォルトの’simplesaml/’のままで大丈夫です。
続いて、config/authsources.phpの修正です。まず、default-sp以下の配列において、entityIDを変更します。そして、この配列内に、privatekeyとcerificateというキーで、それぞれ秘密鍵と証明書のファイル名を指定しておきます。もちろん、ここでは、前の手順でopensslで生成したファイルを指定します。さらに、テスト用のユーザとして、example-userpassの部分のコメントを外して、その中に定義します。以下の例では、user01というユーザとuser02というユーザが定義されており、それぞれ、パスワードはuser01pass、user02passです。キーになっている’user01:user01pass’の部分でユーザ名とパスワードを表現しており、対応する配列は応答する情報を記載します。ちなみに、大学のディレクトリなどでは、eduPersonAffiliationといった属性が入ってきて、それに応じて大学生か、職員かを判断するようなロジックを求められることはよくあるようです。
:
'default-sp' => [
'saml:SP',
// The entity ID of this SP.
'entityID' => 'https://idp.inter-mediator.com/',
:
'proxymode.passAuthnContextClassRef' => false,
'privatekey' => 'idp.inter-mediator.com.pem',
'certificate' => 'idp.inter-mediator.com.crt',
:
'example-userpass' => [
'exampleauth:UserPass',
:
'user01:user01pass' => [
'uid' => ['user01'],
'eduPersonAffiliation' => ['member', 'student'],
],
'user02:user02pass' => [
'uid' => ['user02'],
'eduPersonAffiliation' => ['member', 'employee'],
],
],
metadataディレクトリの設定を行う
続いて、レポジトリルートにあるmetadataディレクトリの設定を行います。このディレクトリも設定ファイルはないものの、拡張子が.distとなっているそれぞれのファイルのテンプレートがあるので、それをコピーして変更して利用します。3つのファイルがありますが、利用するのは2つだけです。コピーしないsaml20-idp-remote.phpファイルは、SPで利用するものです。
cd /var/www/simplesaml-idp/metadata
cp saml20-idp-hosted.php.dist saml20-idp-hosted.php
cp saml20-sp-remote.php.dist saml20-sp-remote.phpちなみに、ファイル名がややこしいと思われるかもしれませんが、それぞれ、IdPの設定、SPの設定を行います。IdP自分自身についてはhostedの方で設定します。そして、SPの設定は自分ではないので、remoteであるということです。ファイル名にはきちんと意味があると思えば、少しは見通しよく見えるのではないでしょうか。
metadata/saml20-idp-hosted.phpについては、以下を修正します。まず、$metadata配列のキーについてはキーの値を既定値から変更して設定します。ここでは、とりあえず、IdPのドメインにしました。ちなみに、このキーを既定値のままにすると、動作がおかしかったので、これを切り替えるのが必要ではないかと思われます。そして、privatekeyとcertificateキーのファイル名を、生成したファイルのものに切り替えておきます。
$metadata['https://idp.inter-mediator.com/'] = [
/*
* The hostname of the server (VHOST) that will use this SAML entity.
*
* Can be '__DEFAULT__', to use this entry by default.
*/
'host' => '__DEFAULT__',
// X.509 key and certificate. Relative to the cert directory.
'privatekey' => 'idp.inter-mediator.com.pem',
'certificate' => 'idp.inter-mediator.com.crt',
実際にはもっといろいろ変更は必要なのでしょうけど、ここまでの設定だと、証明書やキーのファイルの整合、IdPを稼働、テストユーザの登録程度のことです。
全てのファイルの所有者とグループを揃える
必要なファイルをすべて揃えたので、simplesamlphpのファイルの所有者を、Webサーバのwww-dataに変更しておくのがいいように思います。例えば、次のようなコマンドです。
sudo chown -R www-data:admins /var/www/simplesaml-idp
sudo chmod -R g+w /var/www/simplesaml-idpこうすれば、simplesaml-idp以下のすべてのファイルやフォルダは、所有者がWebサーバのプロセスのユーザであるwww-dataになり、グループはadminsになります。そして、所有者はrwあるいはrwxになりますが、グループも同様なアクセス権になることを期待します。通常ログインするユーザをadminsグループに入れておけば、そのユーザでのファイルの読み書き権限もあり、Webユーザの読み書き権限も確保していると言うことになります。simplesamlphpのIdPでは、ファイルの書き込み権限がWebサーバに対して必要なのかという問題はありますが、とりあえずはメンテナンスしやすい状態にしていると考えてください。
キャッシュのディレクトリを用意する
ここで、https://idp.inter-mediator.com/ つまり、Webのルートにアクセスすると次のような画面が出てきます。Ver.2.0.xではこのような画面は出てこなかったのですが、Ver.2.1.xでは出るようになったようです。
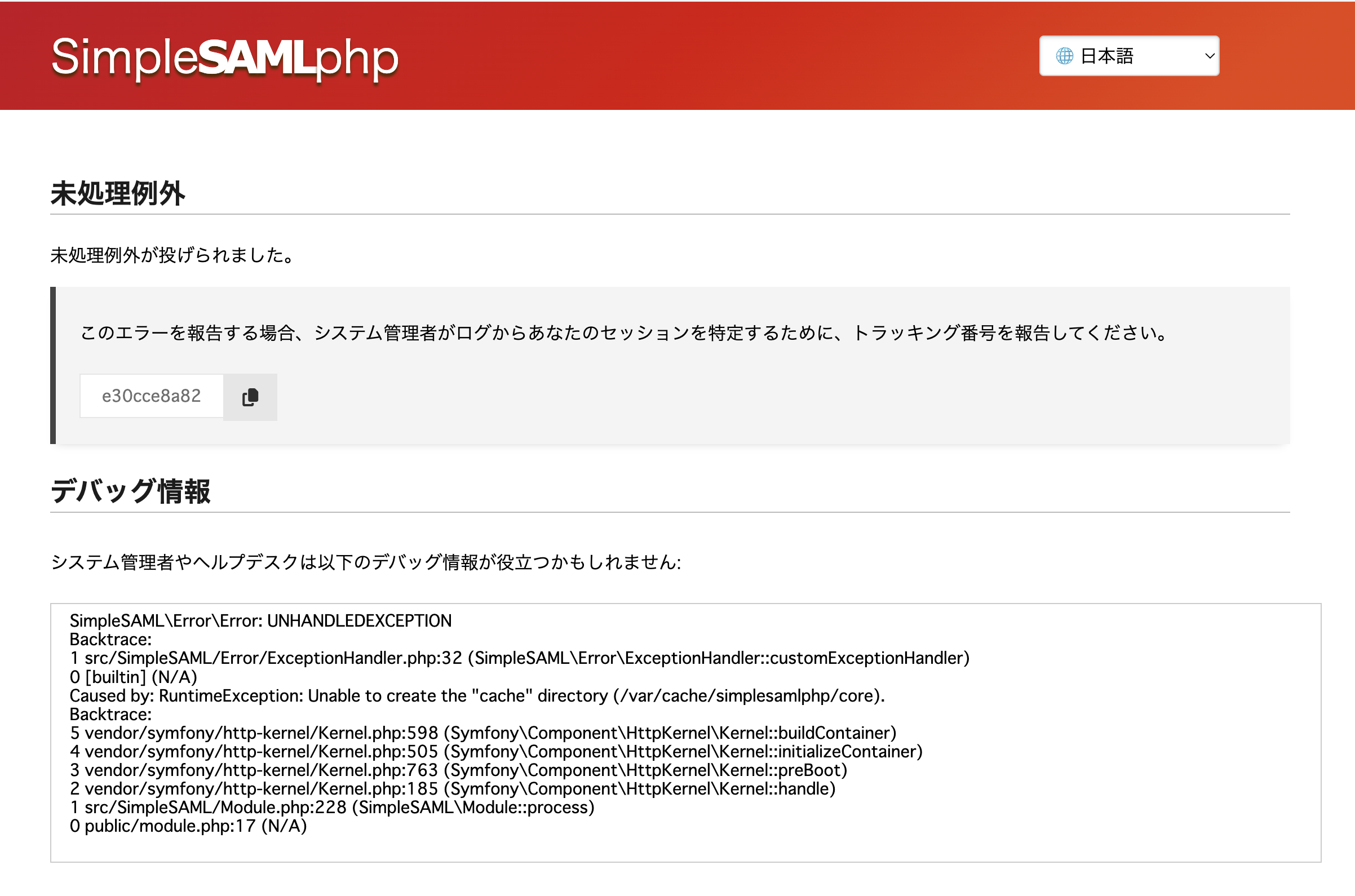
このエラーはよく読むと、意味がわかります。どうやら、既定値では、/var/cache/simplesamlphp以下のキャッシュファイルを作るようで、そのディレクトリが必要ということに加えて、アクセス権も設定が必要なようです。例えば、次のようなコマンドで対処できます。
sudo mkdir -p /var/cache/simplesamlphp
sudo chown -R www-data:admins /var/cache/simplesamlphpキャッシュとして、かなりたくさんのファイルが作られます。
なお、simplesamlphp自体をgitを使って更新した後などは、場合によってはキャッシュをクリアしておかないと起動時にエラーになる場合もあります。エラーにならない時もあるのですが、いずれにしてもソースコードの変更によってキャッシュの整理は場合によっては自分でやらないといけない模様です。謎のエラーが出た場合には、/var/cache/simplesamlphp以下を消してみてください。
管理ツールを稼働する
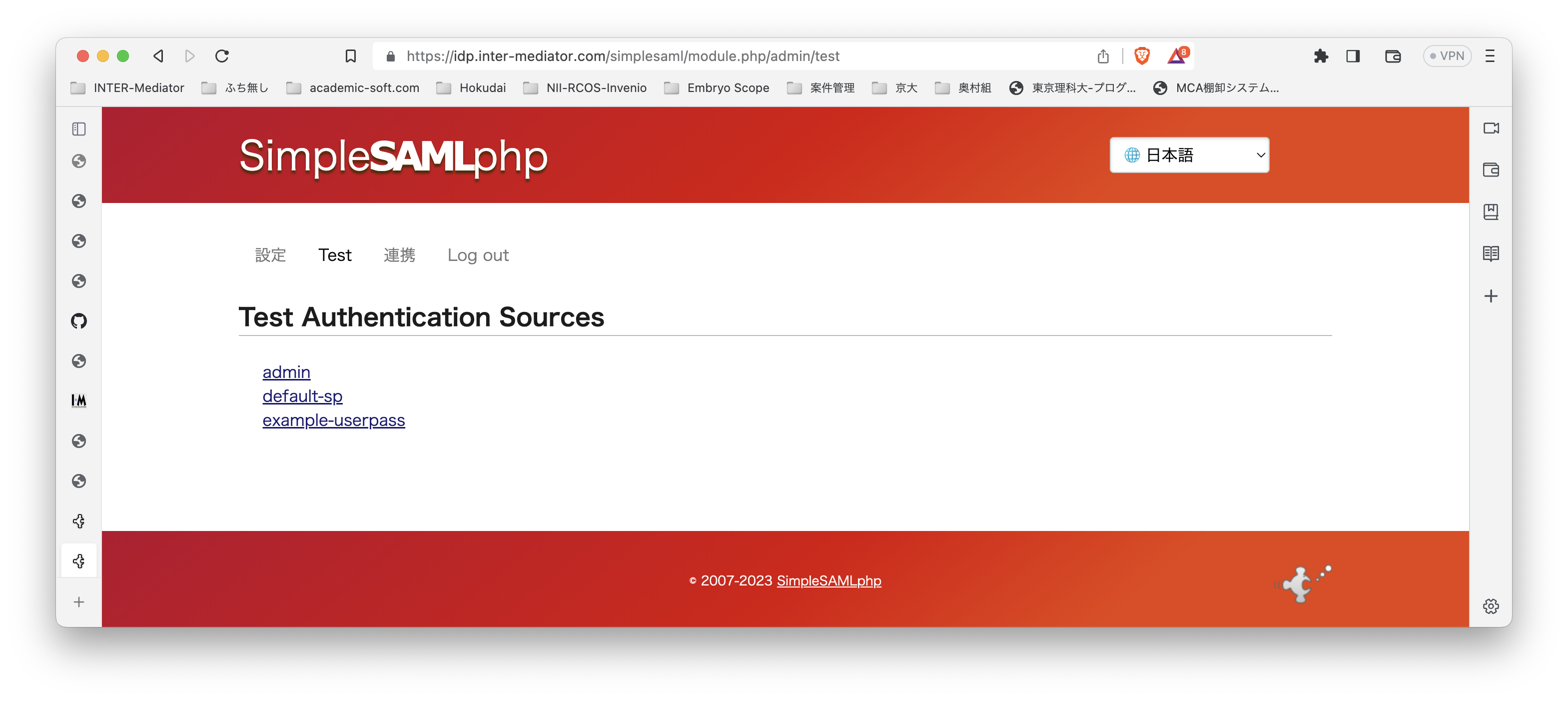
ここで、https://idp.inter-mediator.com/ つまり、Webのルートにアクセスすると次のような画面が出てきます。ちゃんと動いている模様ですが、肝心の管理作業ができません。
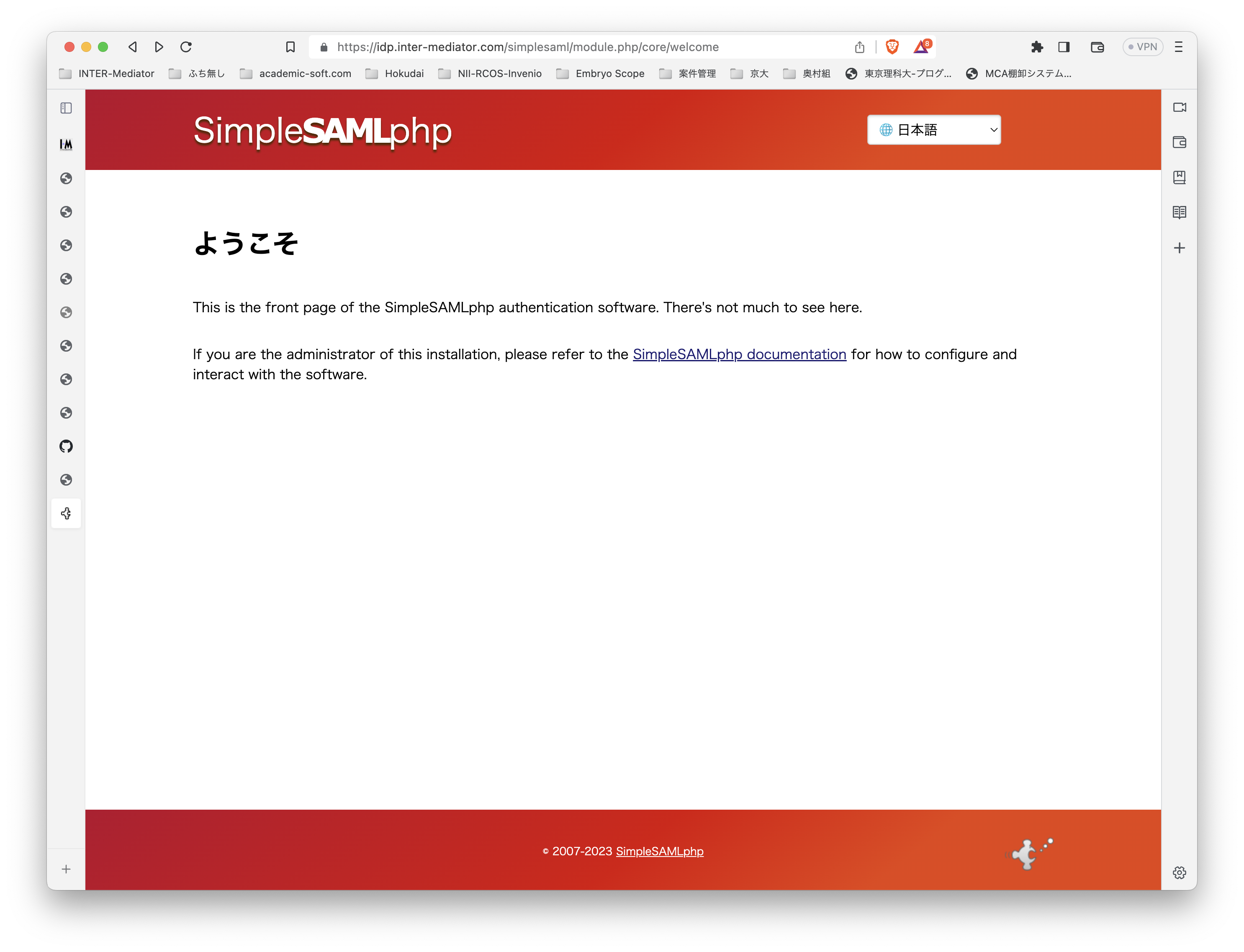
管理作業をするには、https://idp.inter-mediator.com/admin にアクセスします。いろいろリダイレクトしますが、認証画面が出てきます。ここでは、ユーザ名はadmin、パスワードは、config.phpファイルに指定したパスワードを入力して認証します。
最初は、以下のようにTestというタブのページになります。ここから先は次の記事で説明ます。