以前からやろうやろうと思っていたベンチマークを必要に迫られてやらないと行けなくなったので、やりました。昔、2008年や2009年にFileMakerのイベントでお話しさせていただいた通り、当時のFMSのカスタムWebは同時にアクセスすると、なぜか倍以上の時間がかかるみたいな状態だったのですが、そんな実装はいつの間にかなくなってそこそこちゃんと動くようになっています。今の焦点は、Custom WebとData APIの違いがどの程度なのかというところかと思います。CloudやLinux版ではCustom Webがなくなっているため、いずれData APIに移行するのか、はたまたFileMakerを諦めるのかはそろそろ心算が必要な時期ではないでしょうか?
では先に結果を書きます。評価条件などは後から記載します。以下のグラフは、レコードの検索にかかる時間を100回行った場合の平均値です。横軸は1回の検索で取り出すレコード数で、それぞれのレコード数の検索を100回ずつ行った結果です。FileMaker Serverはこの作業以外は行わない状態にしました。FXはCustom WebのXML共有を使ったものです。APIはFileMaker APIを意味します。いずれも、INTER-MediatorのサーバーサイドのAPIを使って、検索を行いました。ベンチマークというかPHPで作ったプログラムがあるMacで動いていて、別のMacでFileMaker Server 19が動いているという状況での計測値です。
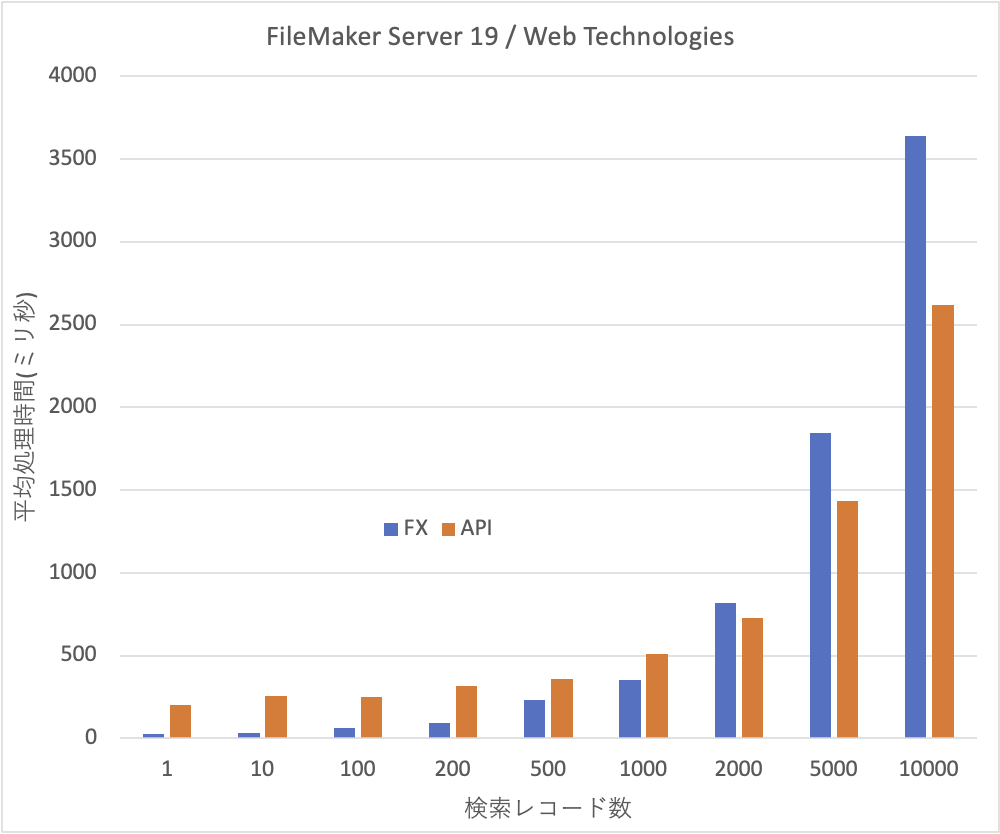
レコード数が少ない状況では、圧倒的にFXが早いです。200レコードの場合でもAPIの方は3.5倍も時間がかかっています。1つには、FXが1回のネットワークアクセスで処理が終わるのに対して、APIは認証、検索、ログアウトの3つのアクセスがあるので、ある程度時間がかかるのは仕方ないと思われます。しかしながら、ほとんどデータのやりとりがない1レコードの検索でも、200msほどかかっており、これがAPIのベースの処理に必要な時間と思って良いかと思います。100レコードでも253msとあまり変わらずです。ちなみに1レコードの場合は、FXは24msほどでした。
ところが、レコードの件数が2000件を超えると、FXよりAPIの方が処理が早く終わります。つまりデータが増えても処理時間の伸びは抑えられています。大量のデータに向くかどうかはさておき、FXよりもAPIの方が、比較の上ではデータが増えてもパフォーマンスの低下は少ないと言えるでしょう。同じデータを散布図で描くと次のように、かなり直線上に乗る感じです。傾きが違うのが見て取れるかと思います。
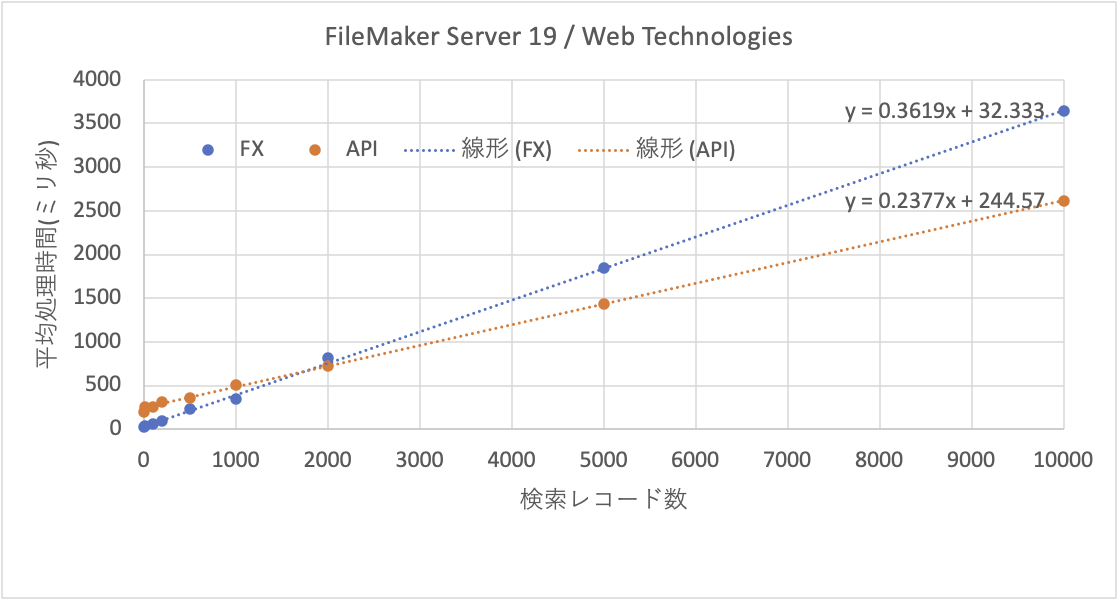
FXとAPIの違いの原因はなんでしょうか? もちろん、アルゴリズムが違うのは違うのでしょうけど、FXはXML、APIはJSONであり、これらの処理ライブラリを考えれば、JSONの方がパフォーマンスは上げやすいのではないかと考えられます(竹内さん、アドバイスありがとうございます)。
一方、FileMaker Serverに対して並列にアクセスをかけた場合の結果を以下に示します。500件のレコードを検索する処理を100回順番に実行するのが1つのタスクとします。並行実行処理数が1の場合は、そのタスクが1つだけ動く場合なので、前述のグラフの500の場合と同じ測定をしています。並行実行処理数が2、4、8は、そのタスクを同時にこの数字だけ稼働して、全てのタスクが終わるまでの時間を測定しました。従って、2の場合は検索数は200回行っているということになります。
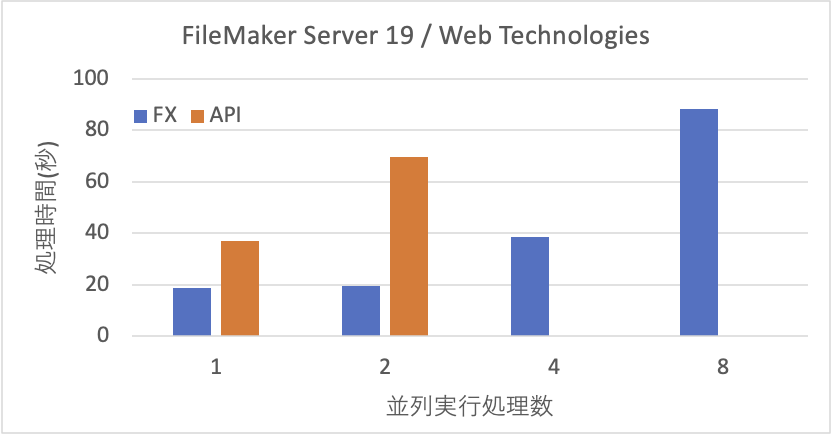
Custom WebのFXは、並列数が1も2も時間に違いがありません。しかし、4、8となると線形的に増加しています。どうやら、2つくらいの並列処理くらいまでは現実に並列に処理をしているのではないかと思われます。サーバー側のプロセスであるfmdcwpcは1タスクだけだとCPUの利用率は30%くらいなのに、2タスク以上だと80〜90%と本当に仕事を頑張っている様子です。ところが、APIは2並列で稼働すると時間が2倍かかっています。つまり、サーバー側で並行的に効率良く処理する仕組みが稼働してはないかと思われます。APIの処理プロセスはfmwipdのようで1タスクだと3-〜50%くらいですが、タスクを増やしてもあまりCPUの利用効率は上がりませんでした。
また、次のグラフは、前述の時間を検索数で割ったものです。FXは、このように1の場合の半分の検索時間の値が2以上8まで推移しているので、どうやら1検索の2倍のパフォーマンスを上限として、順次処理を進めることができる模様です。ところが、APIは1検索のパフォーマンス以上は出せていません。その結果、2並列では2倍の時間がかかるということが分かります。
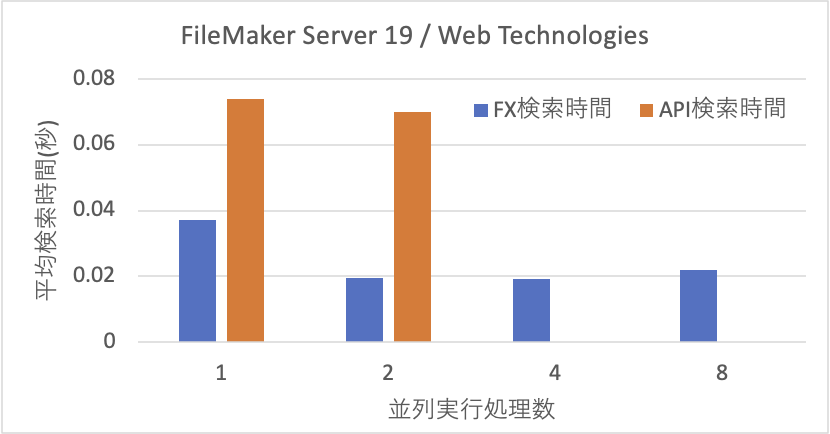
以上のことから、APIはやはりWebアプリケーションに使うとしてもアクセスが集中しないような用途に限定すべきでしょう。FXでもある意味そうなのですが、まだ、性能が高い面があります。また、Webアプリケーションでは小さなレコード数のアクセスが多いだけにFXで運用する方が有利ではないでしょうか。FileMaker Data APIはもちろん汎用的に使えるのですが、レコード数の増大に強い面があるとしたら、やはり大量のデータ交換に耐えうる設計がなされていると見るべきでしょう。
ちなみにこの並列処理の実験で気付いたのですが、FXは、8つのプロセスであってもほぼ同時に8つのプロセスが終了します。ところが、APIは、事実上、最初に入ったプロセスの検索を終えてから、2つ目の処理に移行しています。同時にプロセスは上がっているのですが、どうやら片方が優先的に処理されるようです。キープしたコネクションを優先的に使用するのかもしれません。実際の測定値は、1つ目のプロセスが34.5秒で終わり、2つ目は69.8秒で終わります。この場合、測定値は、69.8秒としました。同時に開始し、最後に終わったプロセスの経過時間を採用しました。
さて、なぜ、APIは4や8の測定値がないのでしょう。並列度をそこまで上げれば、812のエラー(Exceed host’s capacity)が出ます。ちなみに、Developer版なので、3ユーザですね。Data APIはデータ量の制限はあるのは知っていますが、ユーザ数による並列処理制限があるのでしょうか? これは始めて知りました。ちなみに、2並列ではエラーは出ないのですが、3並列ではうち1つの並列プロセスで812のエラーになってしまうため、測定不可能としました。ちなみに、この一連のベンチマークのために、3.3Gの転送量が計上されていました。
ベンチマーク測定においては、FileMaker Server 19側は特に設定は変更していません。コマンドで、XML共有をオンにしただけです。ベンチマークのプログラムは別のPHP 7.4が稼働するMacで動かしました。その2つのMac間は、Gigabit Ethernetなので、ネットワークのパフォーマンスは非常に高い状態です。なお、並列処理を行うために、php -Sによるサーバープロセスを最大8つまで異なるポート番号で起動して、ブラウザからそれぞれのポートのphpによるWebサーバーに接続し、ほぼ並列に動く状態を作りました。このマックはQuad CoreのCore i7です。ベンチマークのプログラムはこちらです。lib/src以下にINTER-Mediatorをクローンし、INTER-Mediatorをカレントにしてcomposer updateを行った後に、dist-docs/buildup.shを稼働させて(3)を選択して、lib/INTER-Mediatorを生成します。なお、INTER-Mediatorは、Pull Reuqest #1487が含まれたものである必要があります。fms-benchのディレクトリをルートにして「php -S localhost:9000」などで起動して、「http://localhost/do_bench.php」でベンチマークを動かしました。
ここでのベンチマークの検索プログラムは、レコード数12万件余りの郵便番号データベースを使っています。検索ごとに、乱数を使って異なるスタートポジションを指定して、そこから決められた数のレコードを取り出しています。フィールド検索には入っていませんが、データベース内部をランダムに探る必要がある点からデータベース自体の入出力により近い結果が得られることを期待しています。検索やリレーションシップが絡むと、データそのものによる要因が発生するので、今回のベンチマークではスタート位置のランダム化で測定を行いました。
いずれ機会があれば、更新系の処理もやってみたいですが、機会があるかどうか定かではありません。
2022/5/5追記:サーバ復旧時に画像が復活していなかったので、画像だけ埋め込みました。