久しぶりにタイトルのような事をやりました。この記事のハイライトは、変数でXSLTファイルの位置を指定できるようになったものの、エラーが出るという事象に遭遇しますが、その対処方法が分かったということです。
XML出力は、FileMaker 5くらいからありますし、出力するXMLデータにXSLTを適用して、テキストやらHTMLやらを生成することができるので、ちまちまと文字列処理を書かなくてもいいので便利です。XSLTの習得が大変という話もありますが、今時この種の情報は「基本知識」でしょうから、勉強すればいいのです。私自身は幸いにも、今はなくなってしまったXSLTでのWeb公開の時代に、かなり勉強していたし実稼働させたソリューションもあったので、自分的にはXSLTはOKです。この記事では、XMLやXSLTあるいはそれらを利用するFileMakerの機能については詳細には説明しませんので、必要な方は予習をしてください。
現実にXML/XSLTを使うとき、当然ながらXMLはテーブルを出力するときのフォーマットなので、テーブルから生成されることになります。一方、XSLTはどうでしょうか? 確実は方法は、Webサーバ等に配置して、URLで指定することですが、データベースファイルと別の管理対象ができて不便です。そこで、XSLTのテキスト自体をテーブルのフィールドにテキストとして保存しておくことで、データベースと一体化して管理ができて便利です。ただし、そのXSLTのテキストを利用するときにはファイルにしなければなりません。現実にはスクリプトを組むとして、1フィールド、1レコードだけのタブ区切りで出力すれば、余計な “” などは含まれません。ただし、その1フィールドに、改行が入っていると、コード番号12のものに置き換えられます。後から変更するのは面倒なので、XSLTのテキストから改行を除去する計算式を設定した計算フィールドをエクスポートすればいいのです。もちろん、XSLT内では改行の有無で動作が変わらないにしなければなりません。
さて、そこで、このXSLTファイルをどこに保存するのかということですが、WindowsでもMacで稼働できるようするには、テンポラリフォルダがいいのではないでしょうかということで、次のようなスクリプトで変数にパスを入れることにしました。順当な方法かと思います。
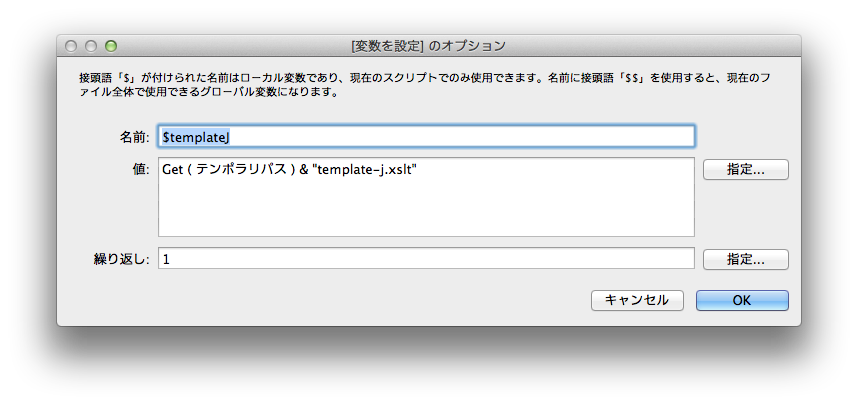
この変数$templateJの結果を利用して、XSLTのテキストをエクスポートします。前に説明したように、スクリプトで、1レコードのみを対象レコードとして、改行を省いたテキストのフィールドだけをタブ区切りで出力します。出力ファイルに、変数$templateJを指定します。
ここで、XSLTによる変換をスクリプトのどこかで組み込むとします。スクリプトステップの「レコードのエクスポート」で、「出力ファイルの指定」を行い、OKボタンを押すと、ファイルタイプが「XML」の場合はさらに次のダイアログボックスが表示されます。ここで「XSLスタイルシートを使用」を選択し、ファイルを指定するわけですが、「ファイル」だとダイアログボックスが出て来て、特定のファイルの指定が必要です。Get ( テンポラリパス ) は一定のパスではない模様ですし、Win/Macでパスは違います。なので、「計算」を選択して、前の変数$templateJを指定して、実際に動かしてみます。ボタンと計算式の文字列が重なっているところにFileMaker社のこの機能への姿勢が見て取れます。
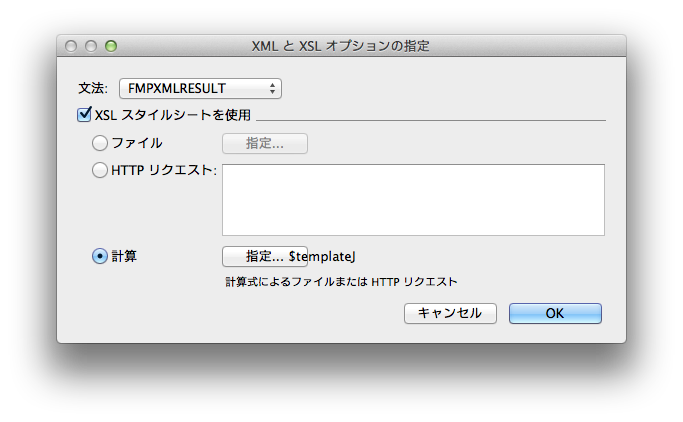
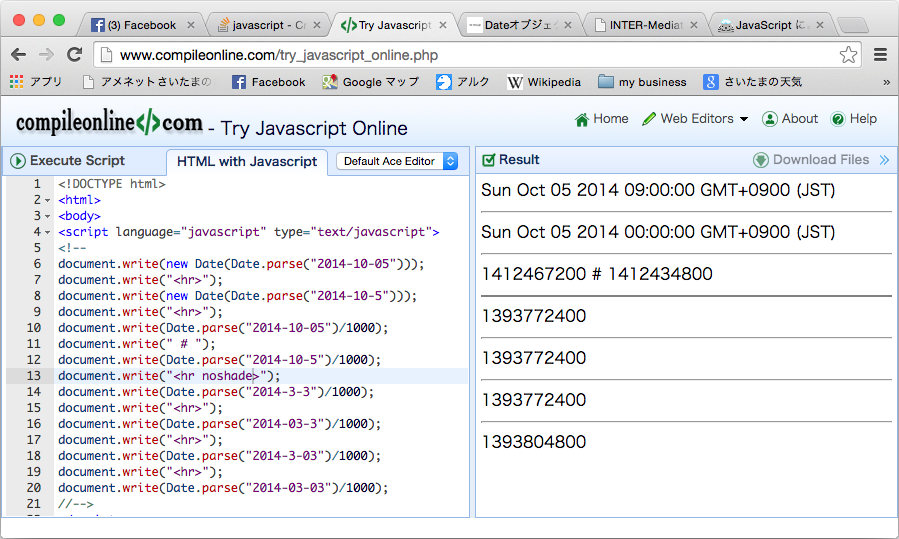
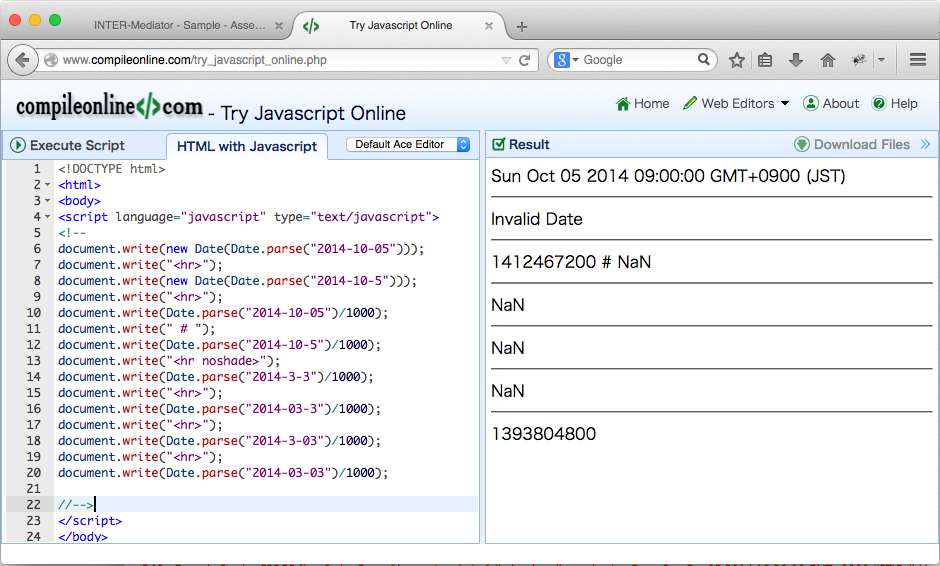
すると、XMLのエクスポートをするときに、次のようなエラーが出ます。SAX(XMLのパーサ)のエラーがそのまま見えていて意味が分かりにくいですが、ようするにファイルが見つからないということです。Windowsでは、実際に見つからなかったパスも見えています。
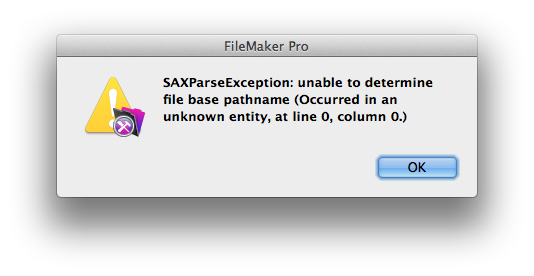
変数$templateJで出力し、その直後に変数$templateJでファイル参照して見つからない。ようするにバグなのですが、バグで使えません、以上ということでは前に進みません。バグは直らない可能性もあるからです。
そこで、変数$templateJの内容を、MacとWindowsで調べ見ました。Macだと、「/Macintosh HD/var/tmp/….」みたいになっています。Windowsだと、「/C:/Users/msyk/….」となっています。まず、Macは、明らかにパスの最初のコンポーネントを取り去れば、存在可能なUNIXパスになります。Windowsは…ともかく、まず、XSLTのテキストをエクスポートした後、以下のような「変数を設定」スクリプトステップを追加して、最初のコンポーネントを省いてみました。
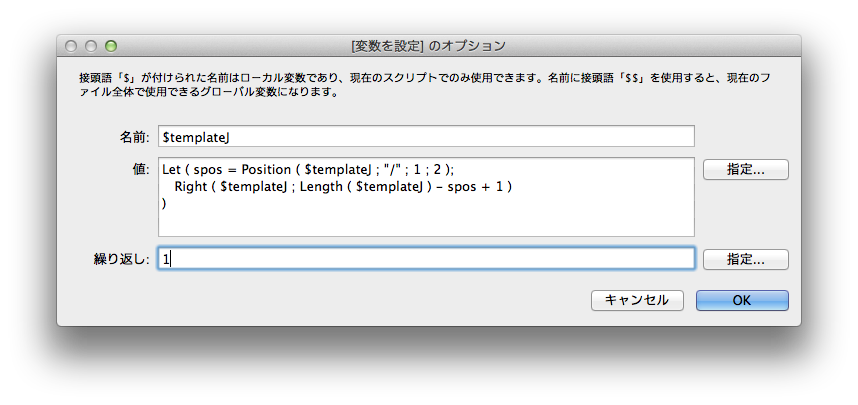
Macでは、予想通り、それでエラーなく動きました。一方、Windowsは別の対策をしないといけないかと思ったのですが、なんと、ちゃんと動きました。UNIXみたいなパスの与え方でどうやら動くようです。
XSLTのTipsを少し書いておきましょう。関連レコードのフィールドは、TOさえあれば出力できると思っていたら、ポータルに展開しないと出力されません。ポータルがない場合は、ちゃんと警告メッセージを出して、最初のレコードの値だけが出力されると言われます。ということで、ポータル作成はさぼれません。
関連レコードのデータは、たとえば2つのフィールドがあるとして、関連レコードが3つあると、次のように出力します。このノードの上位ノードのタグはROWになります。
<COL><DATA>1</DATA><DATA>2</DATA><DATA>3</DATA></COL>
<COL><DATA>abc</DATA><DATA>def</DATA><DATA>ghi</DATA></COL>
上記の2つのフィールドの番号を1、2とします。ROWタグがカレントノードのとき、上記のデータを展開するのにfor-eachを使うのですが、同じポータルにある関連レコードがいくつかるとき、for-eachをそのうち1つのフィールドに対して行います。次のような感じです。ネームスペースの略号は、xsl、fmrとしています。
<xsl:for-each select="fmr:COL[1]/fmr:DATA">
<div>
<xsl:value-of select="." />
<xsl:value-of select="../../fmr:COL[2]/fmr:DATA[position()]" />
</div>
</xsl:for-each>
最初のfor-eachは普通にDATAタグが複数あるので、それを1つ1つ取り出します。3行目の「.」によって、1つ目のフィールドの現在のDATAのテキストを取り出すので、「1」「2」「3」という値が順次取り出されます。2つ目のフィールドは、4行目にあるように、XPATHの記述で、カレントノードからROWまで「../..」でさかのぼり、そこから、COL、DATA集合へと下ります。そして「position()」というのは関数です。for-eachでループしているときに、何番目なのかを示す値を返します。これで、「abc」「def」「ghi」という文字列が順次得られます。
最後に大サービスで(笑)、FileMakerのXML出力向け(ただし、FMRXMLRESULTスキーマ)の汎用的なテンプレートを書いておきましょう。コピペして、あとはデータの順序に合わせてFMPXMLRESULTやROWタグ要素に対応するテンプレートにHTML等で出力テンプレートを書くだけです。
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xhtml="http://www.w3.org/1999/xhtml"
xmlns:fmr="http://www.filemaker.com/fmpxmlresult"
exclude-result-prefixes="xhtml fmr">
<xsl:output encoding="UTF-8" method="xml" indent="yes"
omit-xml-declaration="yes"/>
<xsl:template match="fmr:ERRORCODE | fmr:PRODUCT | fmr:METADATA">
</xsl:template>
<xsl:template match="fmr:FMPXMLRESULT">
<html><body><table>
<tr><th>Name</th><th>Activity</th></tr>
<xsl:apply-templates />
</table></body></html>
</xsl:template>
<xsl:template match="fmr:ROW">
<tr>
<td><xsl:value-of select="fmr:COL[3]/fmr:DATA[position()]" /></td>
<td>
<table>
<xsl:for-each select="fmr:COL[1]/fmr:DATA">
<tr>
<td><xsl:value-of select="." /></td>
<td><xsl:value-of select="../../fmr:COL[2]/fmr:DATA[position()]" /></td>
</tr>
</xsl:for-each>
</table>
</td>
</tr>
</xsl:template>