INTER-Mediatorの試用や学習用にVMでの配布を始めていますが、INTER-Mediator以外にもこのVMは便利に使えています。サーバアプリケーションを動かしたいけど、サーバを立てるほどのこともないといった用途はよくありますよね? そんなときはVMで動かせばいいわけです。今年になってから、Railsで作られたアプリの稼働用、それから古いMoodleを動かす環境というように、2回もVMを作りました。しかし、作ったドライブの容量が少ない場合に、容量をアップするという方法がなかなか完了せず苦労したので、やり方を書いておこうと思います。以下、VirtualBoxはVer.4.3.26です。
INTER-Mediator搭載のVM
INTER-Mediatorを組み込んだVMは、Ubuntu 14.04 Serverをベースに、Apache2、PHP5、MySQL、PostgreSQL、SQLiteを組み込み、即座にサンプルを動かしたり、あるいはコードを入れてみたりということができるものです。こちらのページからダウンロードできます。ページに記載の通り、「仮想アプリライアンスのインポート」を行い、ネットワークアダプタをホストオンリーネットワークが使える状態にしておくことで、原則として即座に利用できます。
VirtualBoxのVMディレクトリ(OS Xだと~/VirtualBox VMs)にINTER-Mediator-Serverフォルダが作られ、その中にあるINTER-Mediator-Server-disk1.vmdkというのが、OSなどがインストールされたディスク装置のファイルということになります。
このディスクは6.3GBです。INTER-Mediatorの試用では、別に少なくなることはまずないと思いますが、ここにいろいろインストールしたり、データを入れたりするとする、もっと大きくしたいと考えます。
ボリュームの容量アップの流れ
ボリュームサイズをアップするには、全体に定期には次の3つの作業が必要かと思われます。かなり試行錯誤しましたが、この流れで行けそうです。
- 作業1:ディスク装置のファイルの増量
- 作業2:追加した領域をデバイスに組み込む
- 作業3:デバイスに組み込んだ領域をOSで使えるようにする
もし、もっと、違うやり方があるのなら知りたいのですが、これだけの作業が必要になる模様です。
作業1:ディスク装置のファイルの増量
ディスク装置のファイルは、VirtualBoxで見ると、たとえば8GBなどのサイズが見えています。この上限サイズは越えられないサイズなのですが、それをまずもっと大きな値にしたいと考えます。ここで、VirtualBoxはさまざまな形式のディスク装置ファイルをサポートしていますが、vmdkファイルはサイズの変更ができません。やろうとしてもエラーになります。そのため、まず、vmdkファイルをvdiファイルに変換します(サイズ変更可能な別の形式でもかまいません)。VirtualBoxを使って行うには、「ファイル」メニューにある「仮想メディアマネージャー」を利用して、INTER-Mediator-Server-disk1.vmdkと同じフォルダに、INTER-Mediator-Server-disk1.vdiファイルを作れば良いでしょう。コマンドラインであれば、以下の様に入力します。カレントディレクトリを移動してコマンドを入れます。VirtualBoxコマンドがきちんと通るはずです。
cd ~/VirtualBox\ VMs/INTER-Mediator-Server
VBoxManage clonehd INTER-Mediator-Server-disk1.vmdk --format vdi INTER-Mediator-Server-disk1.vdi
この後、次の様なコマンドを入れて、ファイルのサイズを50GB程度にしておきます。このコマンドはすぐに終わります。–resizeはメガバイト単位のサイズを記述します。
VBoxManage modifyhd INTER-Mediator-Server-disk1.vdi --resize 51200
その後、ツールバーの「設定」をクリックするなどして、該当するVMの設定を変更します。ダイアログボックスのツールバーで「ストレージ」を洗濯して、「コントローラー: SATA」の下位にあるディスクを、INTER-Mediator-Server-disk1.vdiに切り替えます。右側の「属性」のポップアップメニューのさらに右にあるアイコンをクリックして、「仮想ハードディスクファイルの選択」を選択し、そしてファイルを選択すれば良いでしょう。SATAコントールの分類に、INTER-Mediator-Server-disk1.vdiが追加されればいいのですが、ダイアログボックスが小さくて確認できないのがちょっと難点です。「仮想的なサイズ」が50GBになっていることで、まずはディスク装置のファイルのレベルでサイズがアップしていることを確認します。
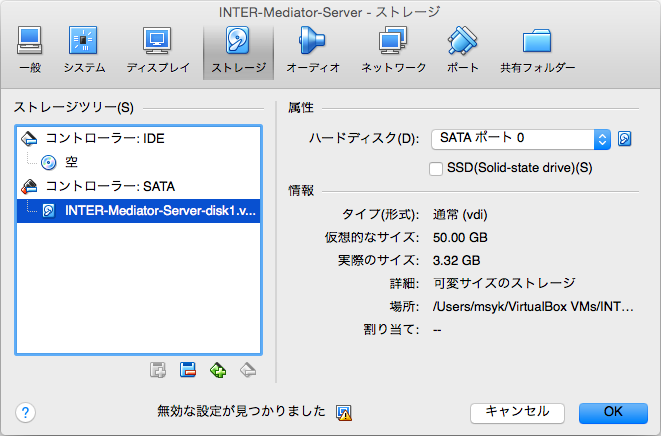
作業2:追加した領域をデバイスに組み込む
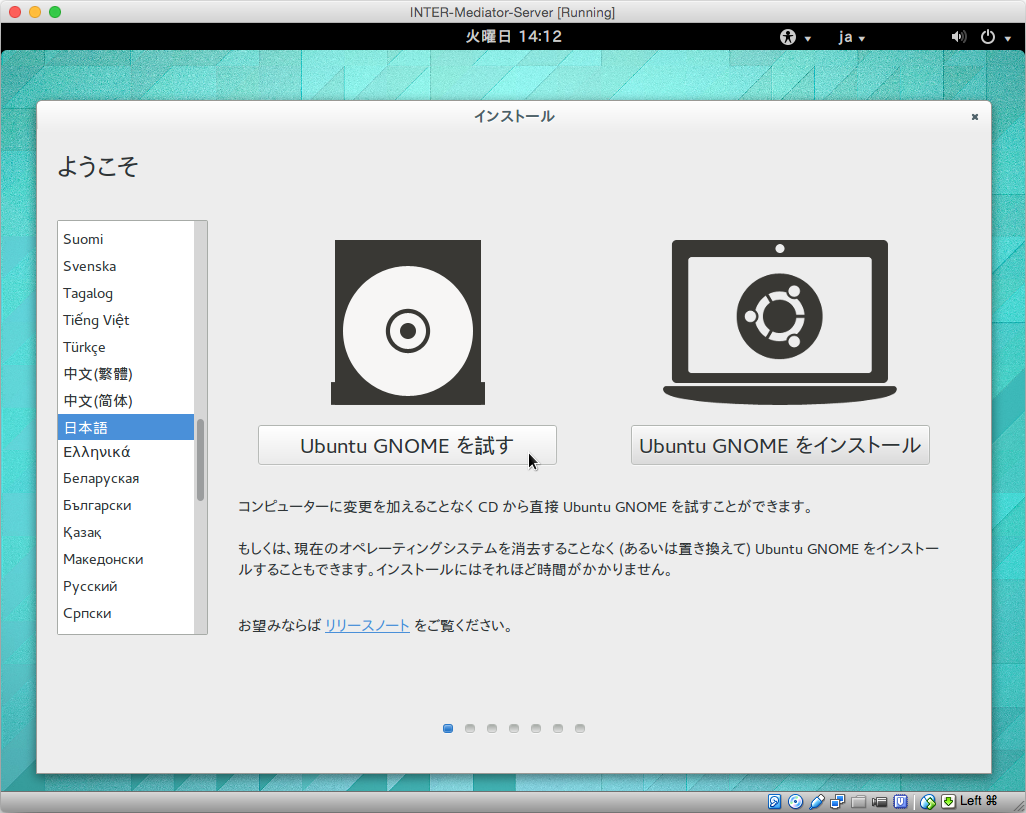
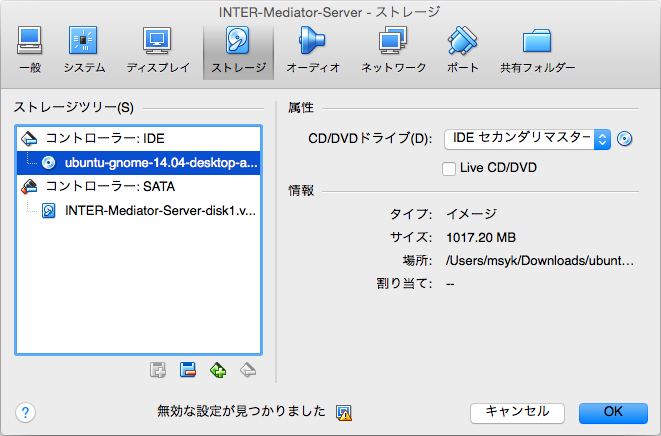
ここまでの作業では、50GBのサイズのファイルの中に、6.3GBのボリュームがあるという状態です。未使用領域を、ボリューム領域として利用するために、作業2を行います。ここで、対象ボリューム自体のマウントを解除して作業するために、別のボリュームで起動します。ここでは、Ubuntu GNOMEのライブCDを使って起動しました。ダウンロードはこちらのページから行いました。
そして、そのライブCDのイメージをVMにマウントします。「設定」のダイアログボックスの「ストレージ」にある「コントローラ: IDE」の下位の項目が「空」になっているので、選択した上で、属性のポップアップメニューの右側のアイコンをクリックして「仮想CD/DVDディスクファイルの選択」を選択し、ダウンロードしたライブCDのイメージを選択します。規定値では、SATAよりもIDEにある起動可能なボリュームが優先されるので、この状態で起動すればライブCD側のシステムで稼働します。なお「Live CD/DVD」のチェックは入れなくても使えました。
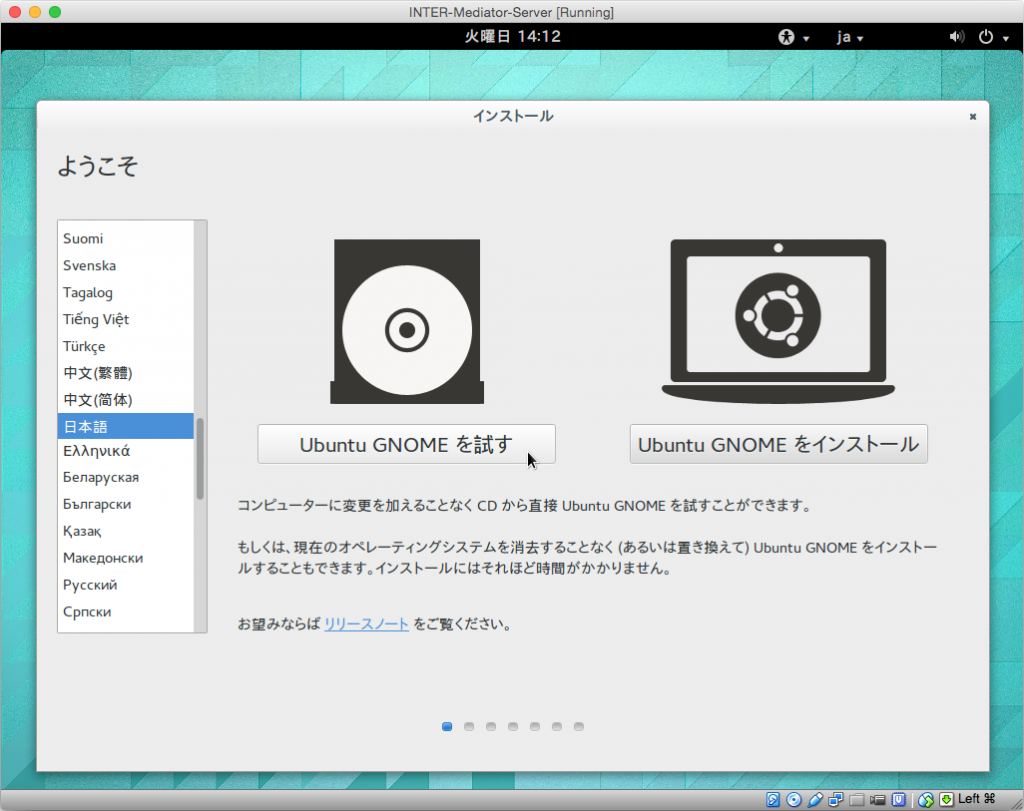
ライブCDで起動すると、最初に次の様な画面になります。ここで、左側の「Ubuntu GNOMEを試す」をクリックします。マウスも、特に何もせずともきちんと動作しています。
しばらく待つとデスクトップ画面になります。左上の「アクティビティ」をクリックして少し待ちます。
続いて、左側のアイコンが出てきます。一番下の「アプリケーションを表示する」の部分をクリックします。
続いて、アイコンがたくさん出てくるので、Gpartedをクリックします。

パーティションを変更するツールが起動します。最初、少し時間がかかります。最初から、該当ボリュームが選択されていますが、選択されていない場合には、ツールバー右端にある部分でボリューム選択ができます。
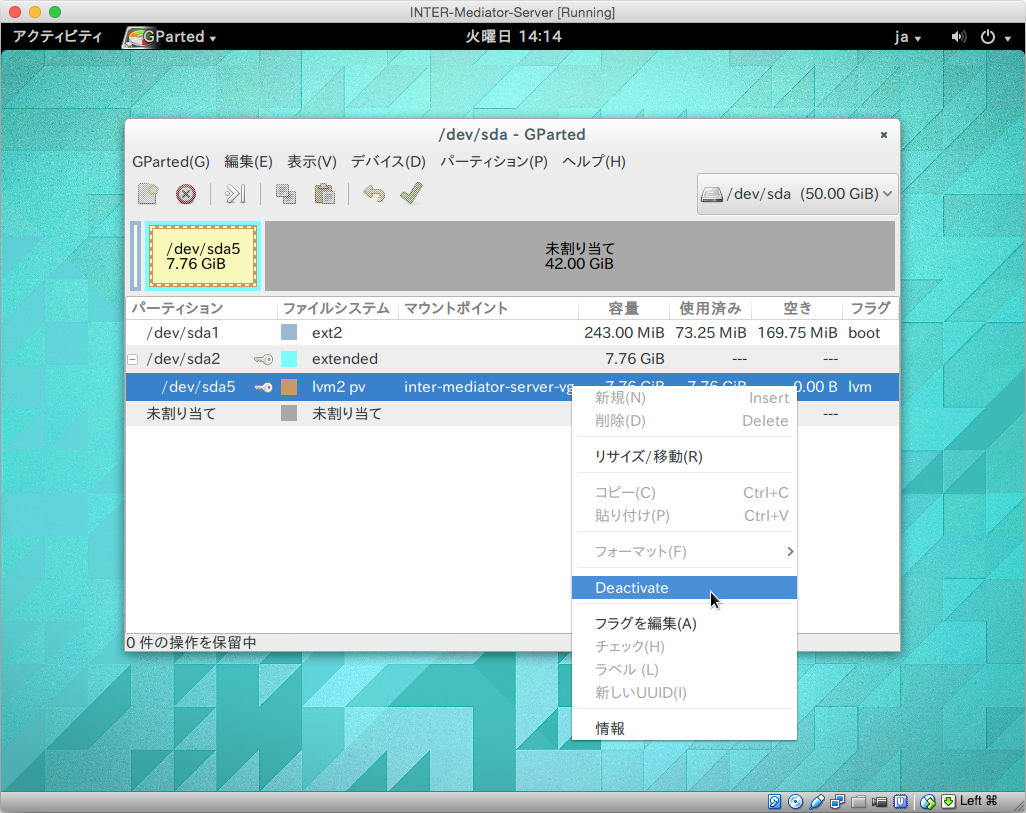
ここで、一覧を見て明らかなように、/dev/sda5が、実際のボリュームになっていて、その上位が/dev/sda2のファイルシステムとういことになります。ここで、鍵のアイコンがあるのは、利用中であることを示します。ここで、マウンドの解除などの作業をするのですが、/dev/sda2の方は何もメニューが選択できません。一方、/dev/sda5の方は、右ボタンクリックすると、「Deactivate」という項目があるのでそれをクリックします。これで、設定の変更ができる状態になると言えばいいのでしょうか。
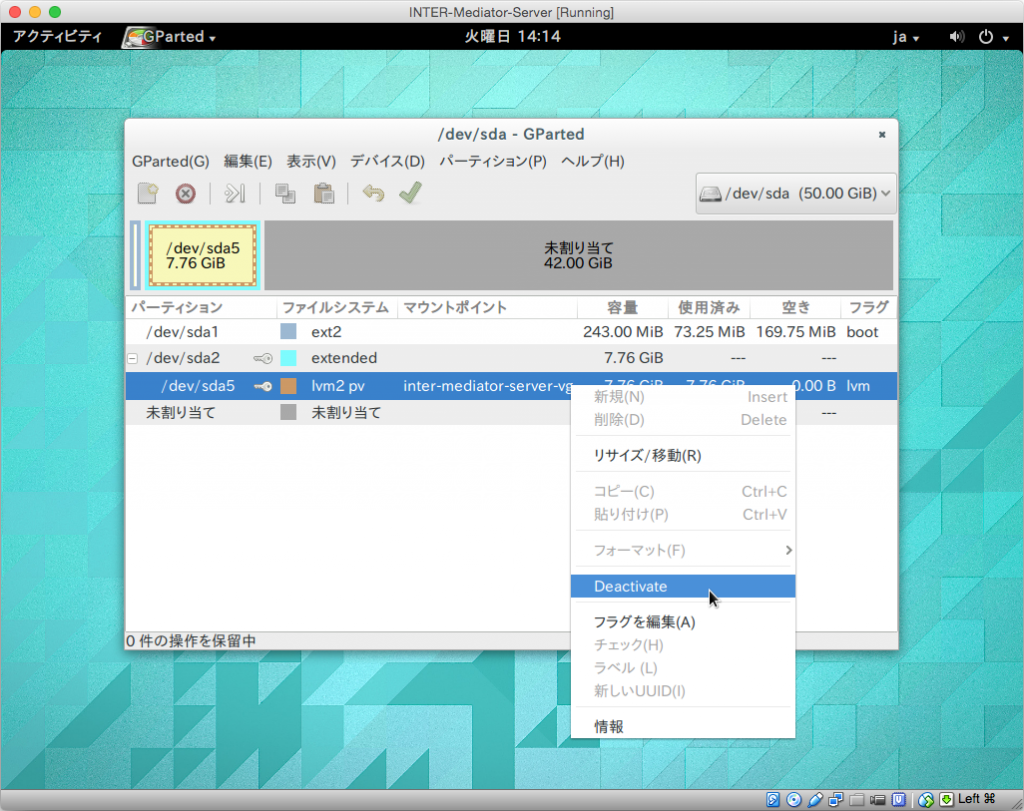
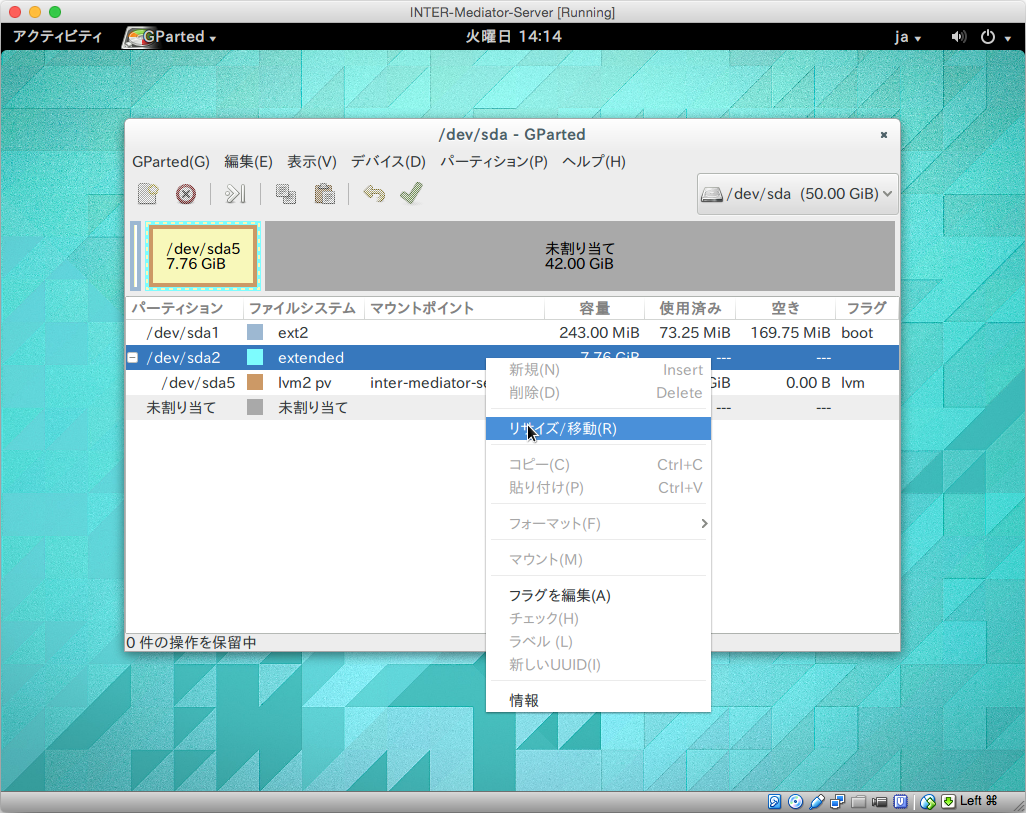
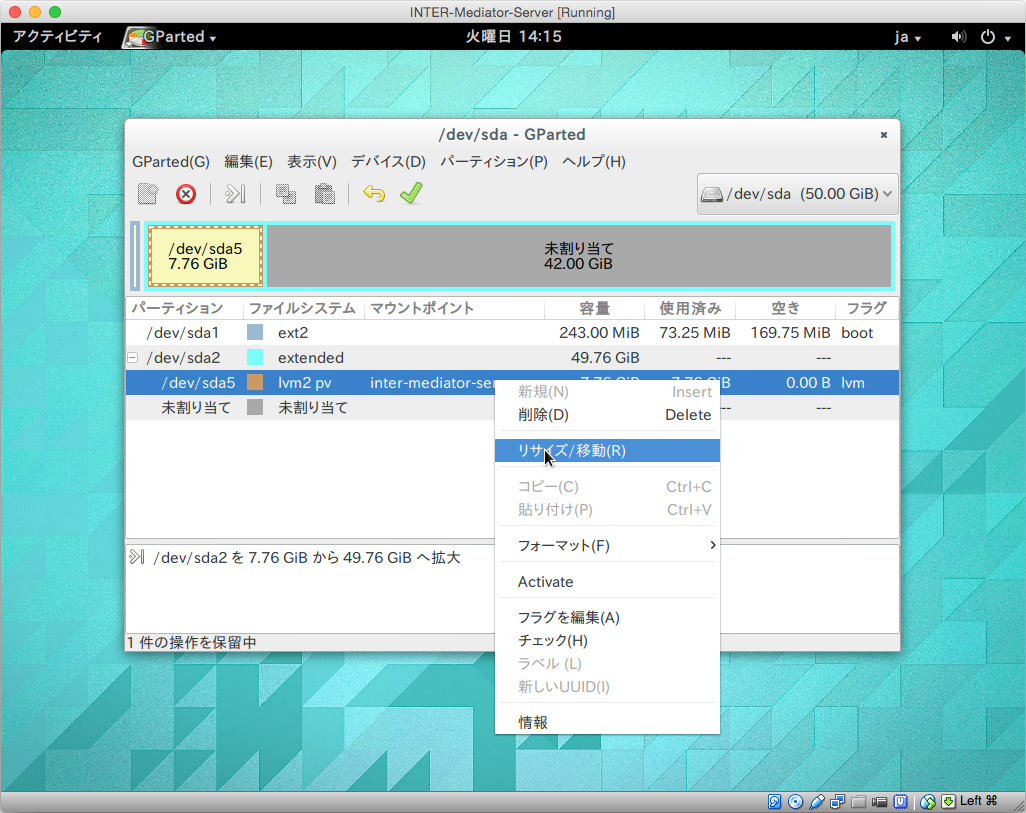
Dectivateすれば、今度は、/dev/sda2の方を右クリックして、「リサイズ/移動」を選択します。
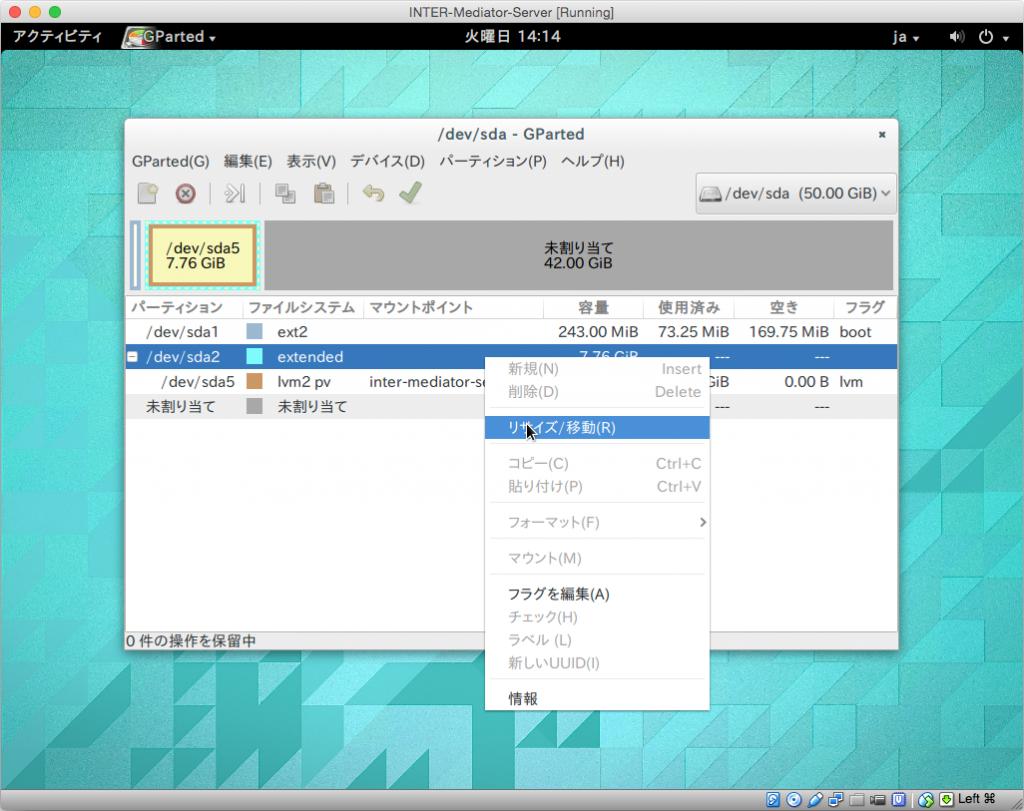
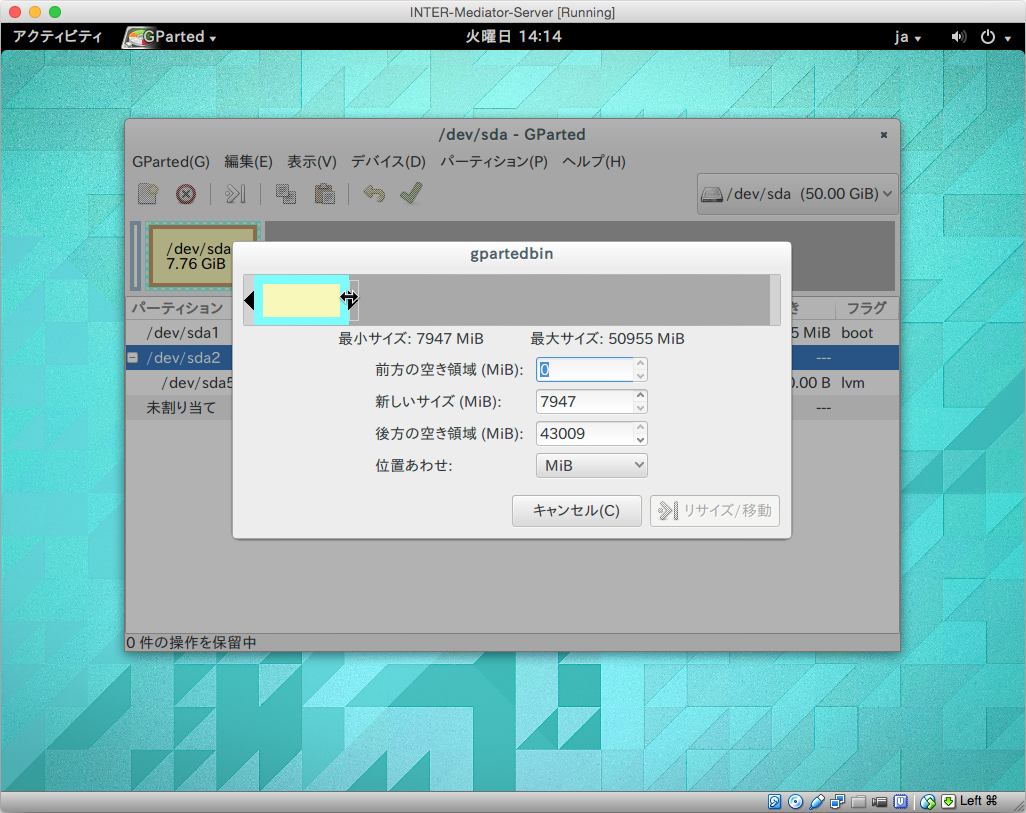
次の様なダイアログボックスが表示されます。ここでは、シアンカラーのボックスが全体の中の利用であり、シアン色の線のうち右側をドラッグすることで、右端の位置を広げれば、/dev/sda2の死サイズを50GB近くまでアップできます。ドラッグして広げたら「リサイズ/移動」ボタンをクリックします。
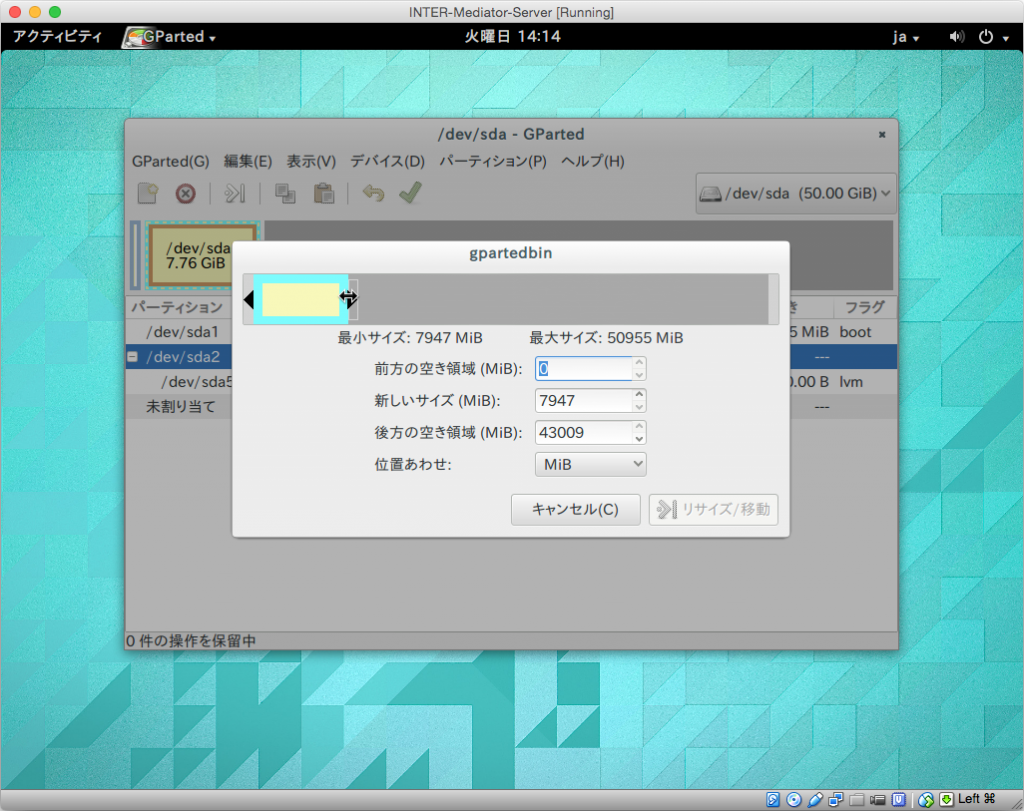
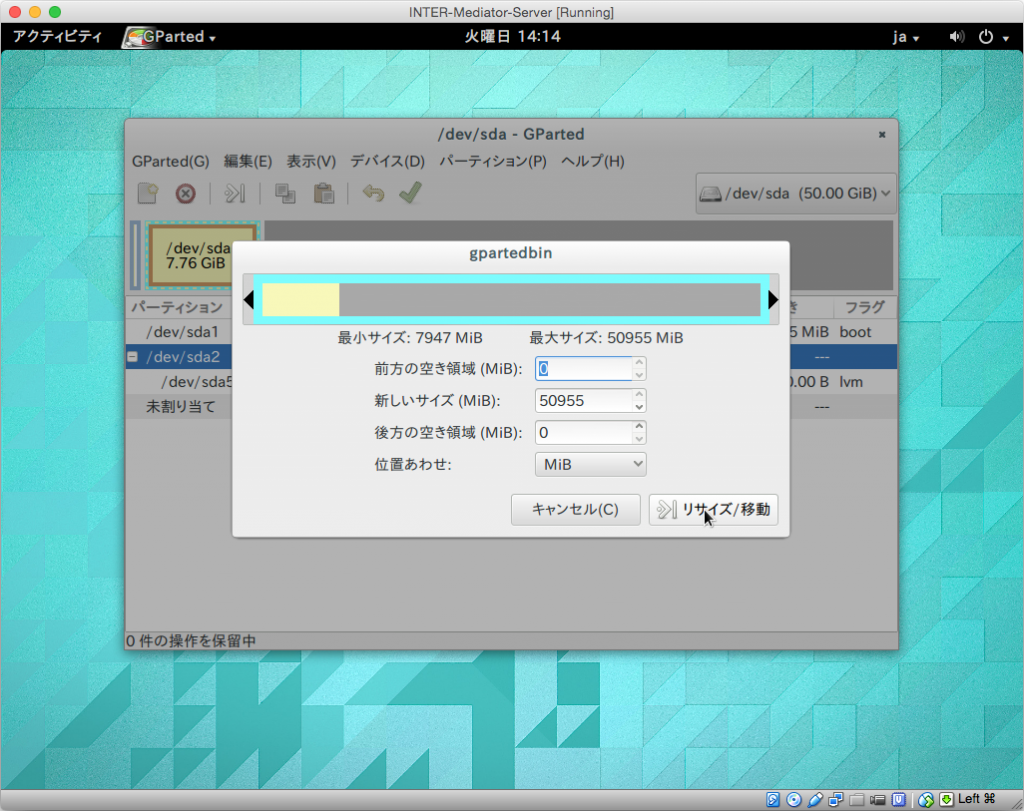
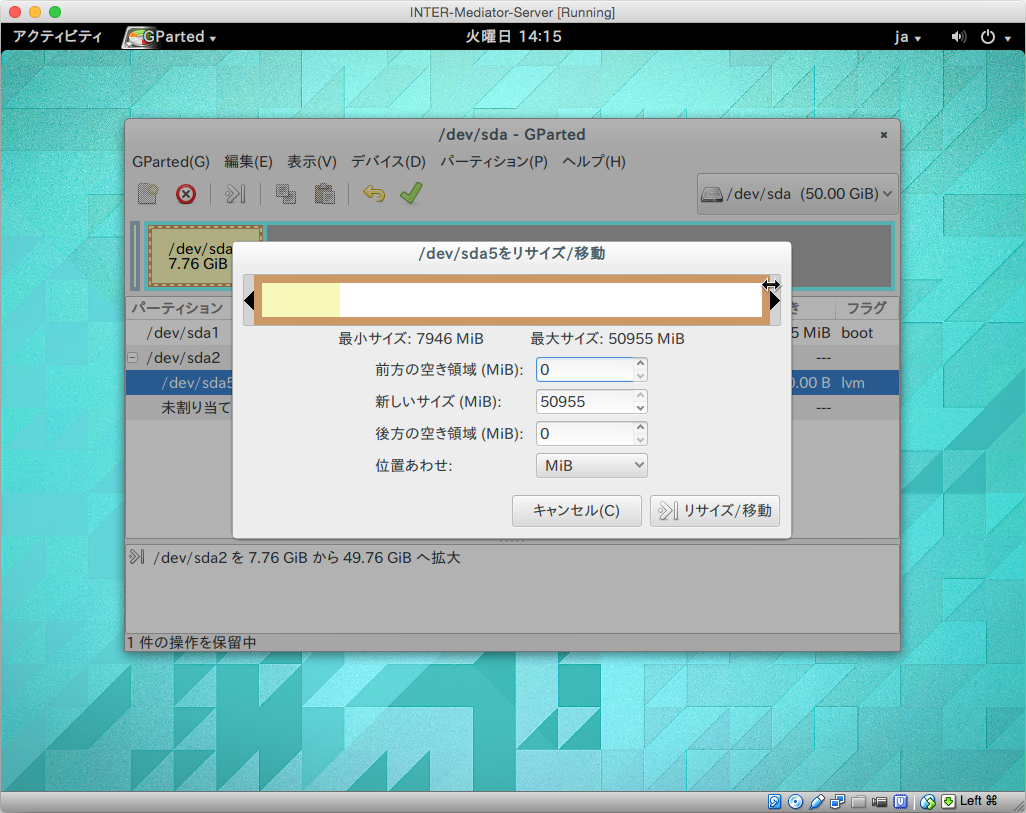
次は、/dev/sda2の内部にある/dev/sda5です。こちらが、OSで見えているボリュームの実態と言えばいいでしょう。こちらの項目を右ボタンをクリックして、「リサイズ/移動」を選択します。ダイアログボックスで同様に、最大まで幅を広げて「リサイズ/移動」ボタンをクリックします。
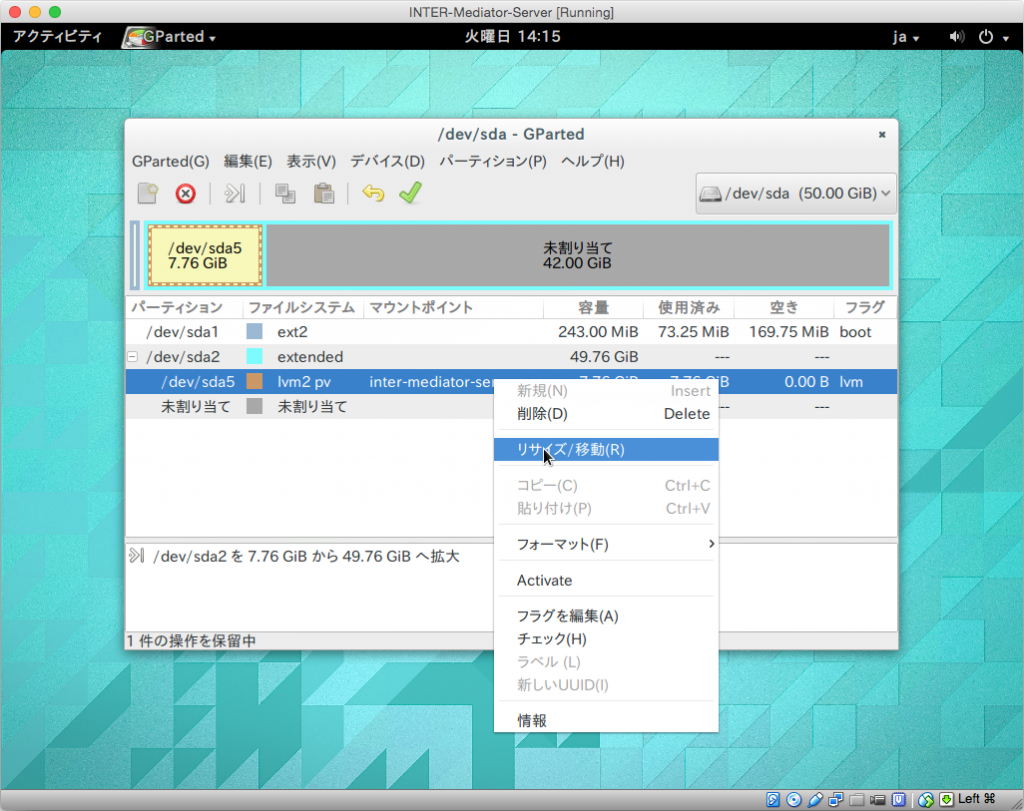
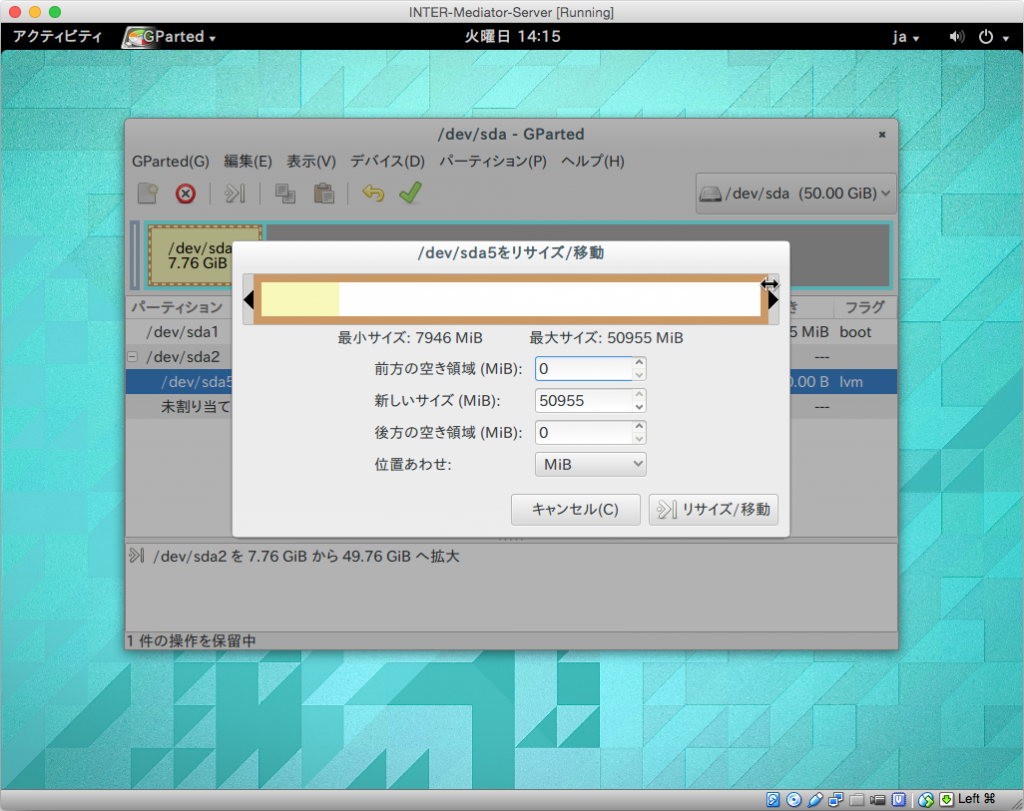
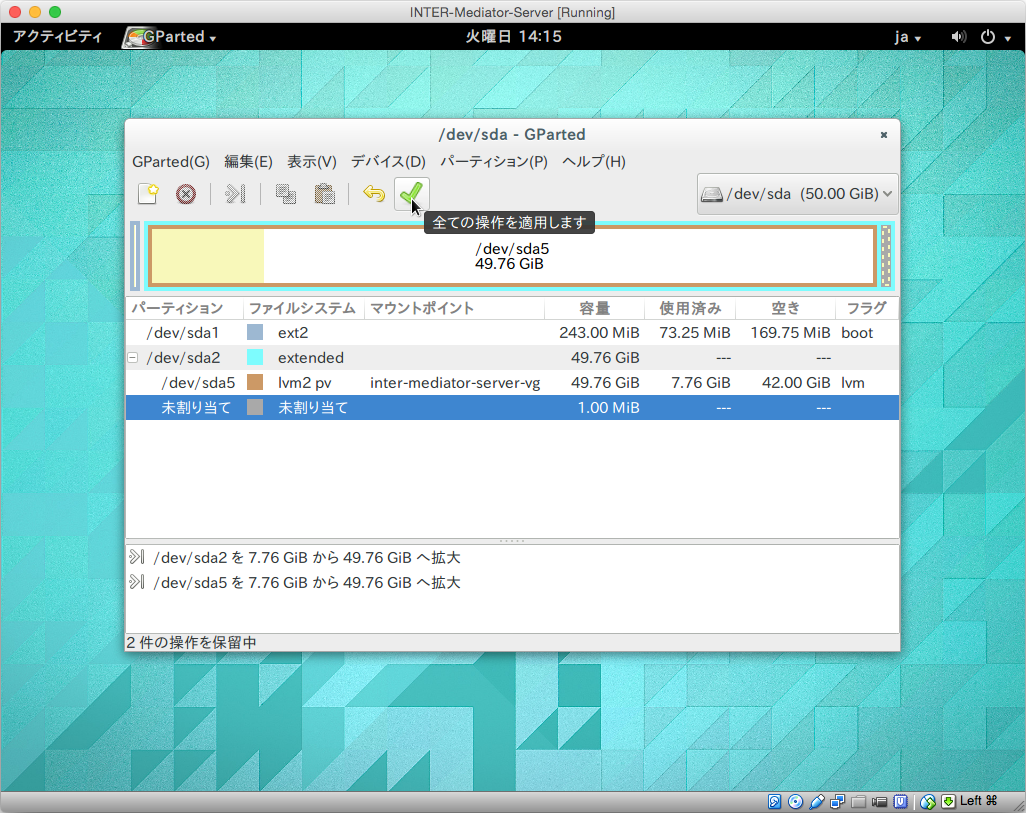
こうして、領域を広げ終わったら、ツールバーにあるチェックマークをクリックします。これは、設定作業が終わり、実際のディスク関連作業に進むことを意味します。
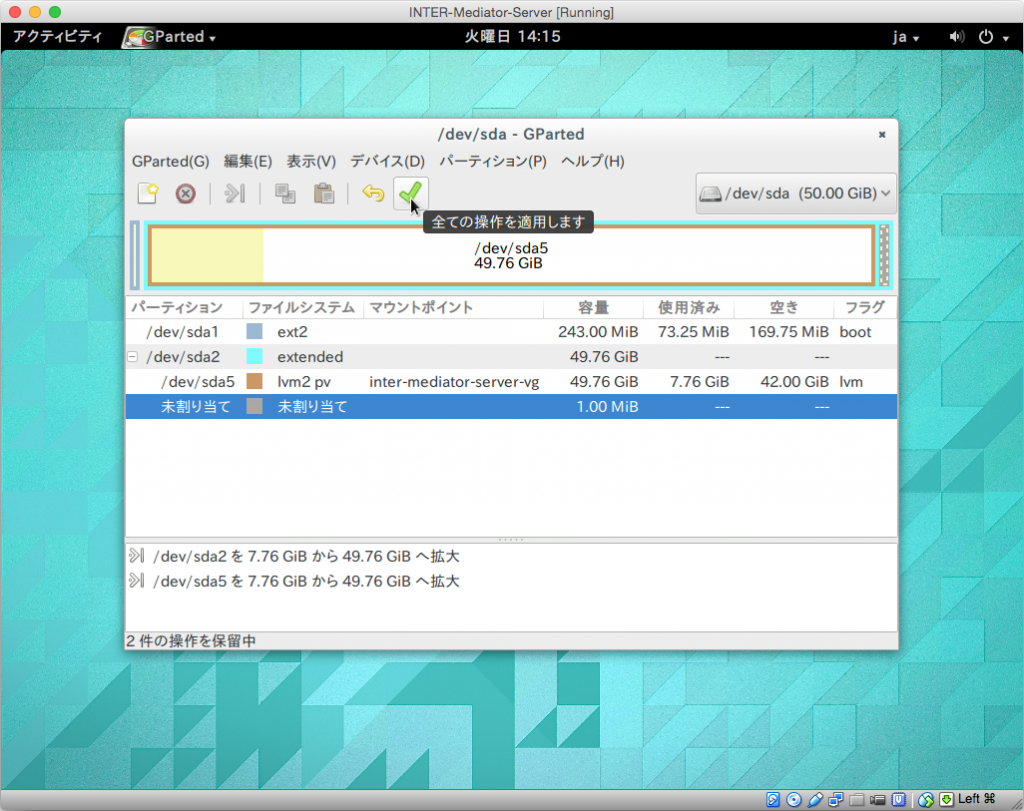
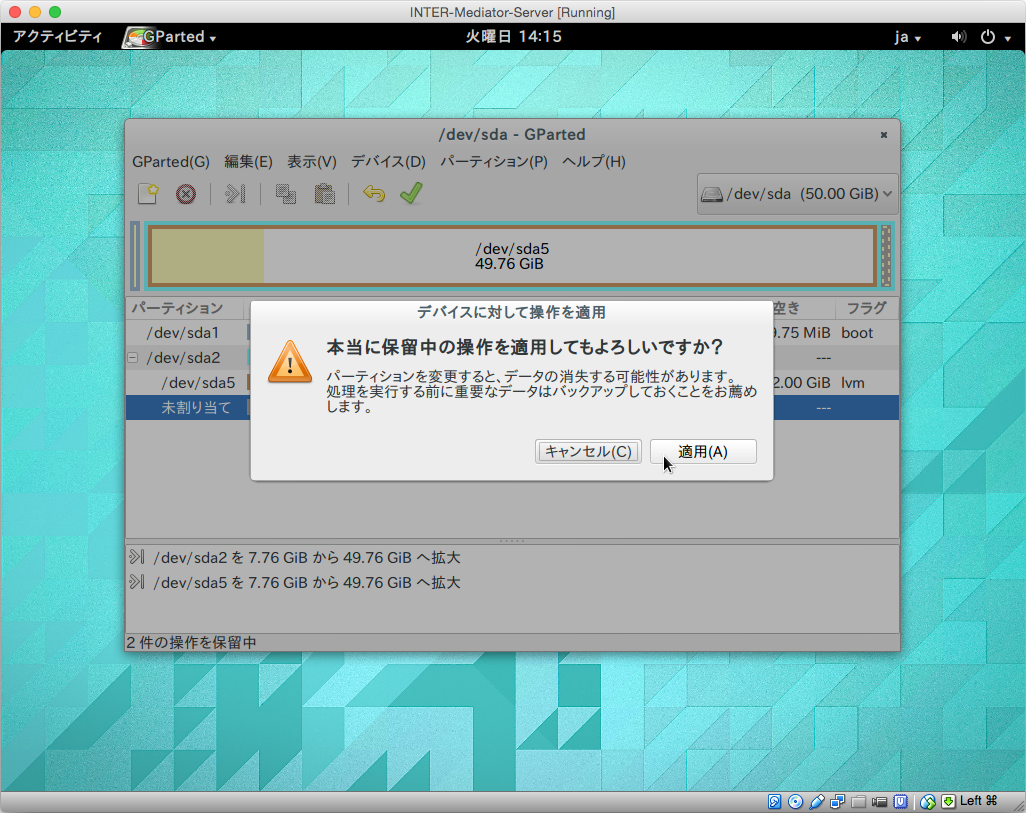
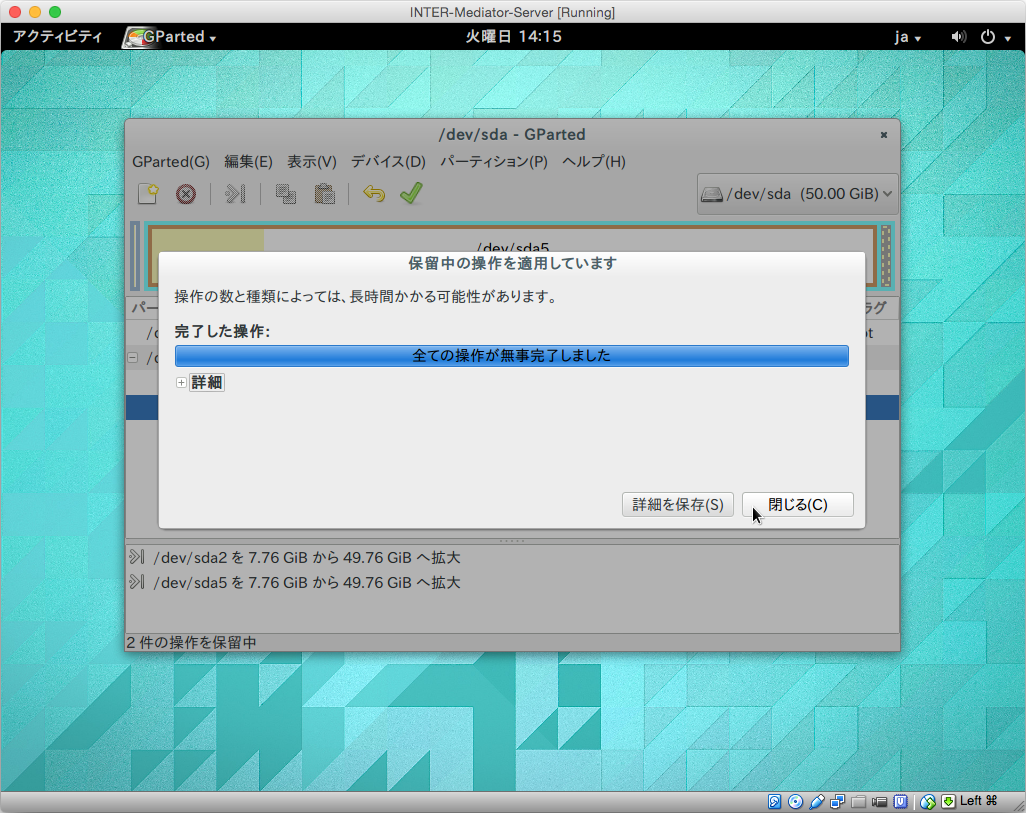
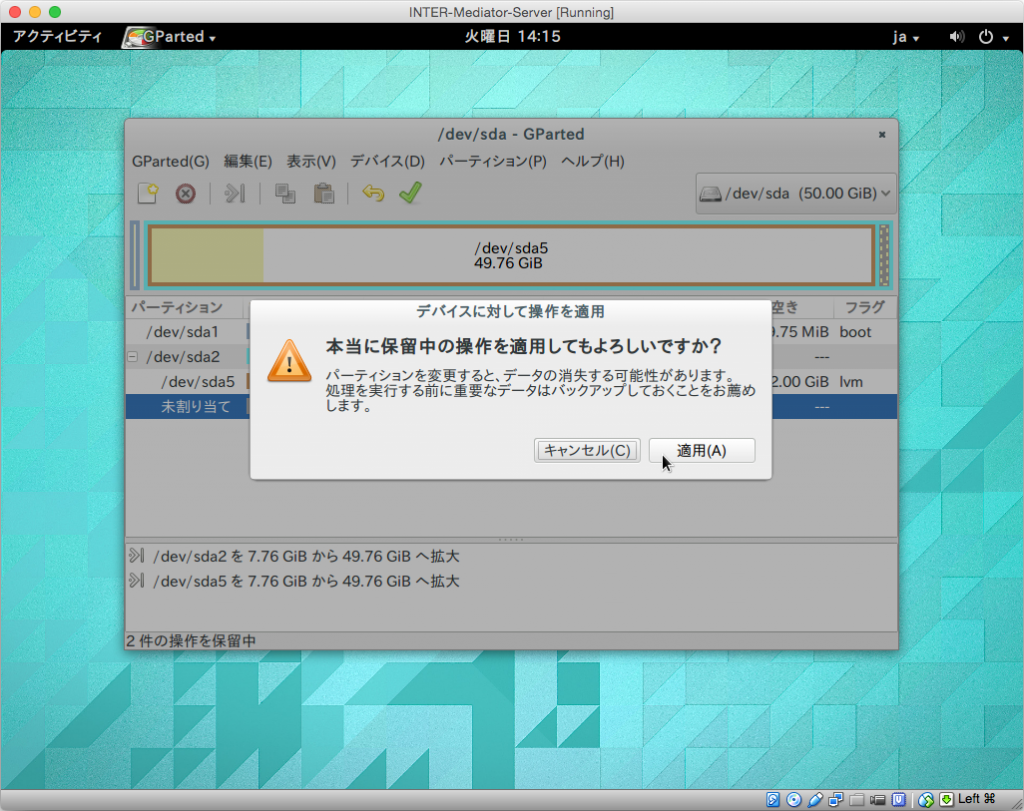
設定変更の確認をします。最初のダイアログボックスでは「適用」をクリックします。作業が終了するとその旨を表示するので、「閉じる」ボタンをクリックします。
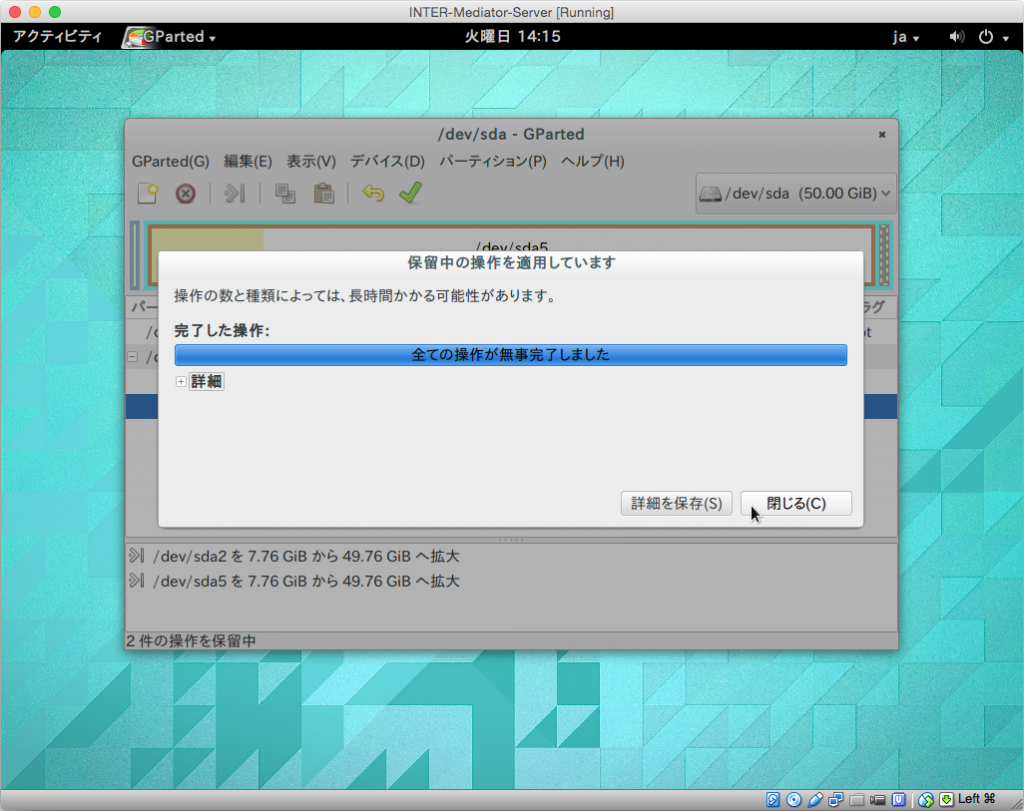
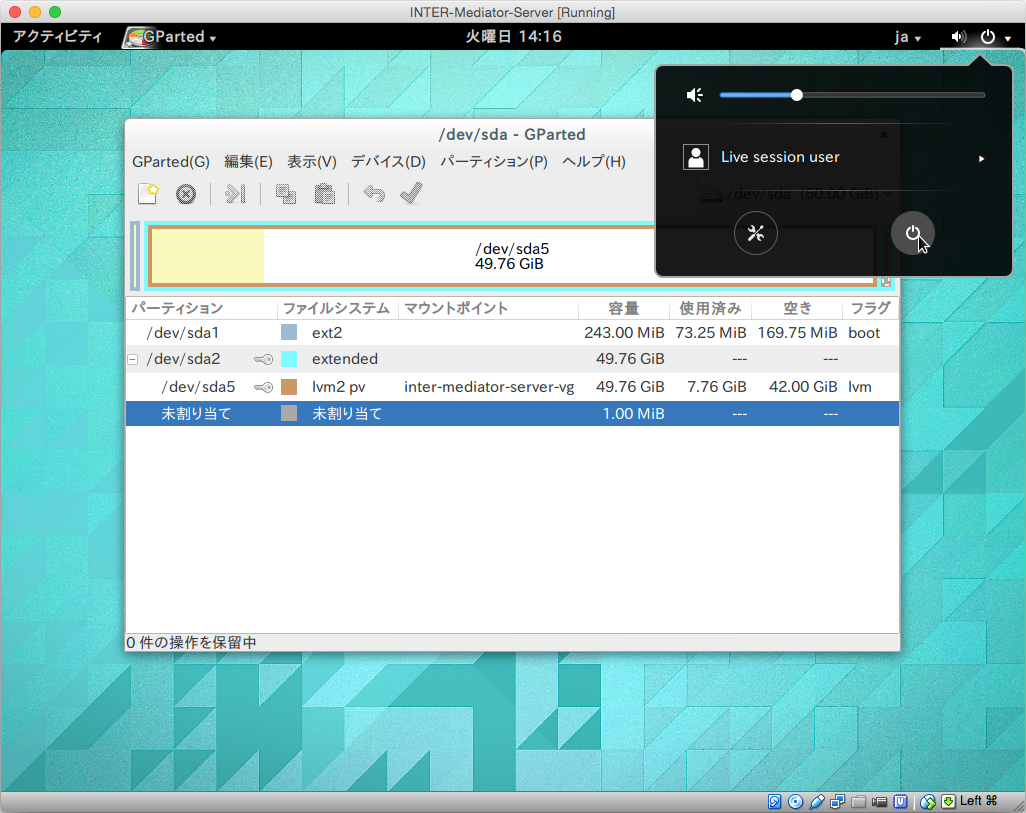
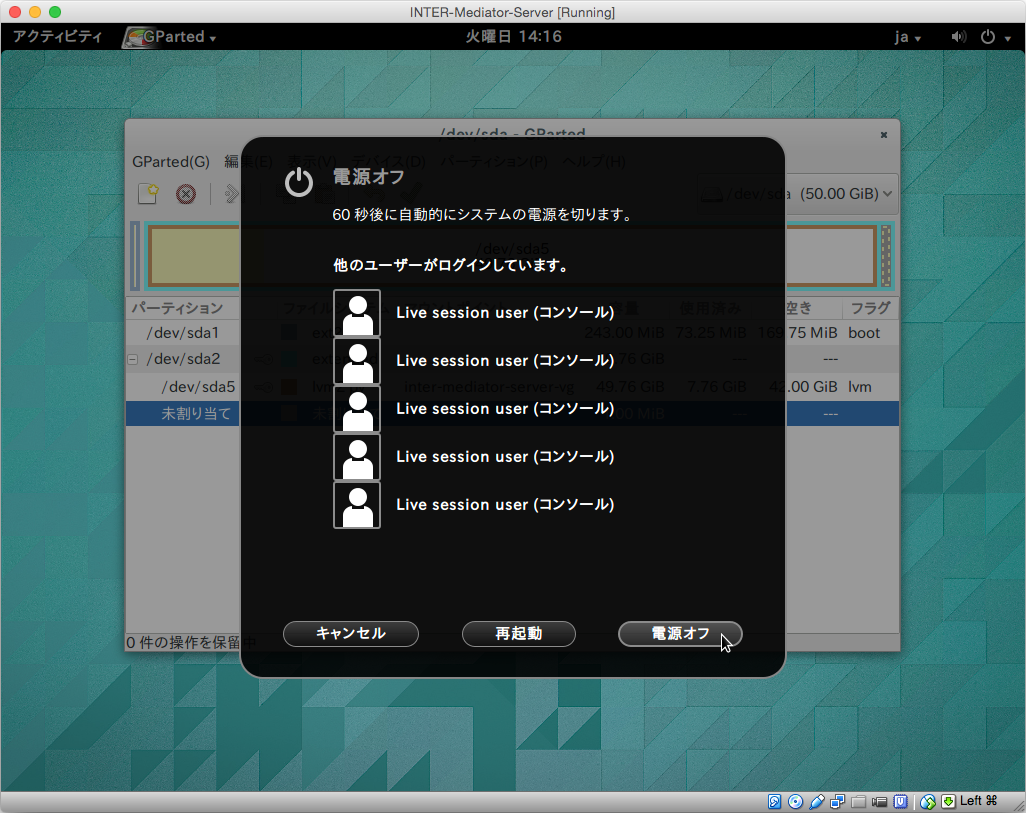
LiveCDを終了するには、画面右上の電源ボタンのような箇所をクリックして表示されるパネルで、やはりMac等で見られる電源ボタンのアイコンをクリックします。その後に「電源オフボタンをクリックします。ただし、実際には電源オフの状態にならないので。VMを適当に止めます。
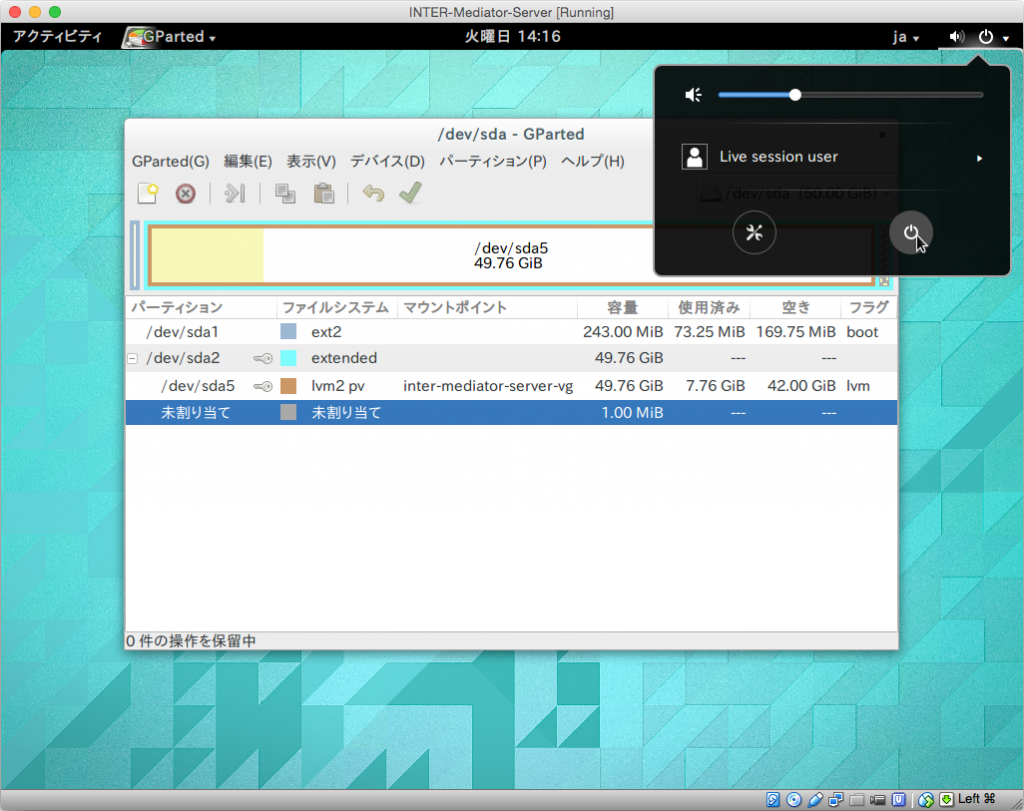
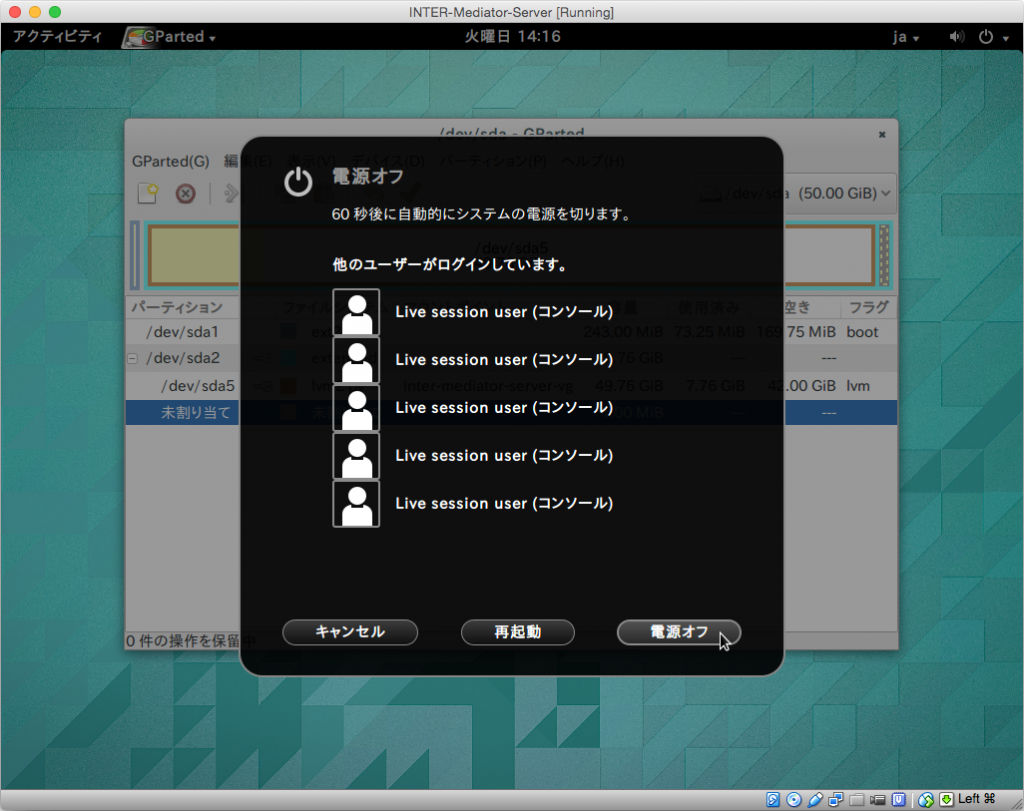
ここで、「設定」の「ストレージ」で、コントローラー: IDEの方のライブCDをマウントする設定を「空」にします。項目を選択して、属性のポップアップメニューの右のアイコンに表示されるメニューから、「仮想ドライブからディスクを削除」を選択します。
作業3:デバイスに組み込んだ領域をOSで使えるようにする
VMを起動して、ルート権限が可能なユーザでログインをします。以下は、行頭の$がプロンプトで、太字が実際に入力するコマンドです。最初、dfコマンドでサイズを見てみますが、6.5GBとなっています。まだ、実際にボリュームとして使えるサイズは変化ありません。ここで、デバイス名が「/dev/mapper/inter–mediator–server–vg-root」であることをチェックします。引き続くコマンドでこのデバイス名を指定します。そして、lvextendコマンドを使って、サイズを可能な限り大きくし、resize2fsコマンドを使って実際にサイズを変更します。その後にdfコマンドを見れば、48GBまでサイズが増加しました。
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/inter--mediator--server--vg-root 6.5G 2.1G 4.2G 33% /
none 4.0K 0 4.0K 0% /sys/fs/cgroup
udev 487M 4.0K 487M 1% /dev
tmpfs 100M 436K 99M 1% /run
none 5.0M 4.0K 5.0M 1% /run/lock
none 497M 0 497M 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/sda1 236M 66M 158M 30% /boot
$ sudo lvextend -l +100%FREE /dev/mapper/inter--mediator--server--vg-root
Extending logical volume root to 48.76 GiB
Logical volume root successfully resized
developer@inter-mediator-server:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/inter--mediator--server--vg-root 6.5G 2.1G 4.2G 33% /
none 4.0K 0 4.0K 0% /sys/fs/cgroup
udev 487M 4.0K 487M 1% /dev
tmpfs 100M 436K 99M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 497M 0 497M 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/sda1 236M 66M 158M 30% /boot
$ sudo resize2fs /dev/mapper/inter--mediator--server--vg-root
resize2fs 1.42.9 (4-Feb-2014)
Filesystem at /dev/mapper/inter--mediator--server--vg-root is mounted on /; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 4
The filesystem on /dev/mapper/inter--mediator--server--vg-root is now 12782592 blocks long.
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/inter--mediator--server--vg-root 48G 2.1G 44G 5% /
none 4.0K 0 4.0K 0% /sys/fs/cgroup
udev 487M 4.0K 487M 1% /dev
tmpfs 100M 436K 99M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 497M 0 497M 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/sda1 236M 66M 158M 30% /boot
参考にしたサイト
以下のサイトを参考にさせてもらいました。
- http://www.virment.com/extend-virtualbox-disk/
- http://qiita.com/niwashun/items/f71b0b805a6f97b514ec
- http://nori3tsu.hatenablog.com/entry/2013/11/23/114400
3つ目のサイトには、ここでの作業1〜3が書かれていますが、最初に見たときには手順2については意味がわかりませんでした。手順2については、上記の1のサイトが詳しく書かれていますし、手順1については上記の2のサイトが詳しくかかれています。