UMLのクラス図は、ER図とよく似ています。ER図ではテーブルを1つのボックスで記述しますが、テーブルをクラスであるとみなせば、UMLのクラス図でのクラスでの記述も可能です。クラス図の方が汎用的であるので、いろいろな書きようがあるため、クラス図で記述する場合のルールは自分自身やあるいはチームとして決めておく必要があります。クラス図での書き方の提案としては、早い時期からあるものとしては、書籍の「
Refactoring Databases: Evolutionary Database Design」の筆者の一人による「A UML Profile for Data Modeling (Scott W. Ambler)」があります。かなり広範囲にわたってルールは作られているのですが、逆に言えば、どこまでを自分で利用するときに記述として取り入れるかを取捨選択するガイドになると思われます。
ところで、astha*professionalは、クラス図とER図を相互に変換することができます。まず、その機能を見てみましょう。前回に示したER図からクラス図を生成すると次のようになりました。
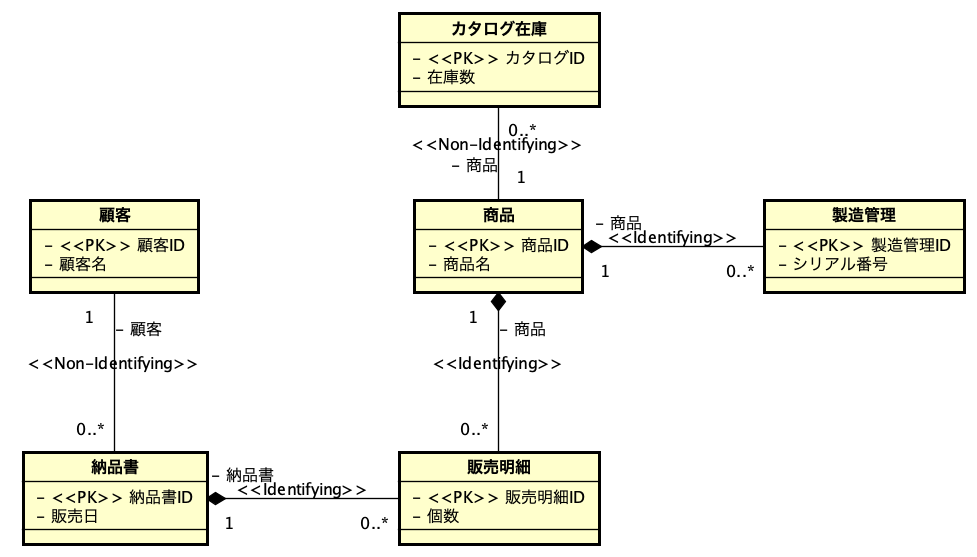
まず、テーブル名がクラス名になります。そして、フィールド定義が、クラスの属性になります。クラスの中の操作については、全部空欄になります。ER図ではクラスの操作に対応する情報はないので、当然かと思いますが、見栄えの上からは操作区画は非表示にするのが良いでしょう。属性の型については非表示になっていますが、定義した結果は背後で記録しています。ただ、図の上で型は見えてなくてもいいのであれば、全部intのままでもいいかもしれません。
そして、属性の中に、<<PK>> というステレオタイプが設定されたものがあります。もちろん、これが主キーを示します。ただ、これだと外部キーの情報が欠けるので、その対処は後で説明しましょう。テーブル間の関連は線で引かれていますが、非依存の関連は<<Non-Indentifying>>、依存は<<Indentifying>>というステレオタイプがついています。そして、非依存は単なる線であって一般的な関連、依存は黒いダイアがあってコンポジションとなっています。依存と非依存の区別が2重な感じがありますが、明確にしたかったのでしょう。納品書の構成要素として販売明細の集合は必須であるということから、確かに、依存関係があれば、コンポジションで表現することは妥当です。
そして、カラスの足跡は残念ながらクラス図では記述ルールにないので、それぞれ、線の端に、「1」や「0..*」などで、個数を示します。つまり、「顧客」と「納品書」の関係は、1対多であり、1つの顧客のレコードに対して、納品書の数は0〜複数個を取り得るということを示しています。この記述は「多重度」と呼ばれます。ここで、線の横に「-顧客」と記載されたものは、「納品書クラスで、顧客を参照できる」ということを意味しています。この外に出た「顧客」がクラス図の定義からは属性の1つになるので(astha*では属性とは別のプロパティになる)ボックスの中に、外部キーが登場しないという状況になります。これはER図上で明示されていたものが消えてしまうというようにしか見えないですし、結合処理の時になんというフィールドを照合するのかという具体性がやや欠けています。もちろん、主キー名と外部キー名を同じにするというルールがあれば、納品書テーブルに顧客IDフィールドがあるのだろうなというのはわかりますが、それは記述をした方が良いのではないかと考えます。
そこで、元々あった外部キーのフィールドも、属性としてボックスの中に定義して、<<FK>>というステレオタイプを設定することで、ボックス内に定義したフィールドが見えることになります。依存と非依存の情報は一旦ここでは消してありますが、黒いダイアのマークのコンポジションは、テーブルのライフサイクルを考える上では重要な情報になるので、必要な箇所にはつけておくべきです。ただ、関連の線の上に<<Indentifying>>というステレオタイプを記述するのは、図がちょっとうるさい感じになるので書かなくてもいいのではと思います。以下のように、クラス図を変更してみました。
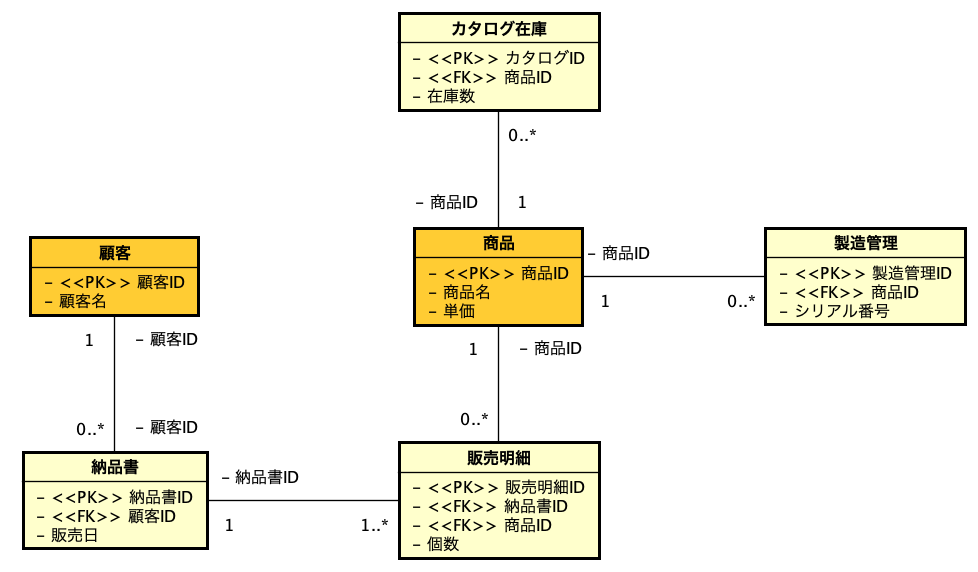
ここで、「顧客」と「納品書」の間の線を見てください。関連付けの線を引いた場合、「0」や「0..*」などの多重度を間違いなく記述するのは必須です。この情報が欠けると設計情報としては未完成と判断されます。ここでは納品書と販売明細の関係において1..*すなわち、販売明細がないということはないという設計情報があります。多くの場合0..*ではあってもなくてもいいということですが、1..*だとそちら側に対応するレコードが必ず1個以上あるようにしないといけません。つまり、納品書のレコードを作ったときに、販売明細のレコードは少なくとも1つは作っておく必要があるということを設計上示唆しているとも言えますし、明細のない納品書はあり得ないということも示唆しています。
そして、照合するフィールドを、線の横に「-顧客ID」などと記述をします。この時、納品書側にある「顧客ID」は、顧客テーブルに定義した主キーの顧客IDと同じものを意味します。実は、ここで、同じものを2つ定義しているのですが、ここからテーブル定義のSQLを自動生成するのでなければ問題はないかと思われます。クラス図では、照合するフィールドを、線の横に書くのですが、「相手側に書く」のがルールです。ちょっとわかりにくいというか、最初は慣れないかと思いますが、ルールだとして気をつけていればすぐに慣れます。なお、このように、双方とも「顧客ID」フィールドであるような場合は、例えば、納品書と販売明細のように、一方だけ書いておくことでも判別はできます。あるいは、PKとFKのステレオタイプから、どのフィールドで照合しているかは明確であるとも言えるので、線の横に照合するフィールド名を記述することを省略するのもあり得るでしょう。その辺りは、好みや設計の複雑さなどと折り合いをつけて自分でルールを決めてしまっていいでしょう。
なお、複雑なリレーションシップがあるような場合にどう記述するのかと言えば、線の隣のフィールド記述だけではわからないので、自由記述が可能なメモを書いて、線の部分を参照しておくと良いでしょう。クラス図にそういう機能がないのかといえば、実はあります。関連の線に対して「制約」という記述が書けます。原則はOCLという言語による式を書くのですが、作図だけならコンパイルするわけではないので、その意味では自由に記述できます。その記述結果は、線の上に { } で囲われて表示されます。もちろんこの方法でも良いのですが、メモで書く方が手軽ということもあって、追加情報はメモをともかく活用するというのがポイントになります。
キーフィールドについては、PKとFKだけを書いていますが、ここでサロゲートキー、つまり連番の自動入力を使うなどして入力したデータとは直接関係ない主キーフィールドを使う場合も考慮します。サロゲートキーは、参照制約などの説明をしてから改めて議論しますが、この例だと例えば、販売明細の販売明細IDは、サロゲートキーで、本来のモデル上の主キーあるいは候補キーとしては {納品書ID, 商品ID, 個数} であったとします。この時、納品書IDと商品IDは、<<FK>>だけでなく、<<CK>>というステレオタイプを付与し、個数にも<<CK>>をステレオタイプに追加します。ステレオタイプは複数設定でき、属性名の前に併記されます。この記述があれば、モデル上の主キーは<<CK>>がついたものだけど、サロゲートキーによる主キーが<<PK>>で示されているということがわかります。もっとも、Ambler先生のサイトでは、サロゲートキーについては<<sarrogate>>というステレオタイプをつけるということを提唱していますので、明示したい場合にはこのステレオタイプをつけておくと良いでしょう。
クラス図で記述した場合のメリットは、次の図のようなオブジェクト図を記述できることです。クラス図は抽象度が高い図であり、コンパクトに設計情報はまとまっていますが、一方で具体的にきちんと正しいデータが格納されるのかということは頭の中で追っていくことになります。ここで例で出しているような納品書などの例ではそれもそんなに難しくはありませんが、もっと複雑なデータ構造の場合は、データがどのように格納され、変化するのかを具体的に記述してみて、確認する必要が出てきます。

オブジェクト図は、クラスに定義した結果をもとに1つのボックスを1つのオブジェクトとして記述するものです。データベースの場合、1つのボックスが1つのレコードとなります。もちろん、今までに主張してきたように「表にする」でもいいのですが、表だとレコード間の関連付けをビジュアル化しづらいこともあります。レコード間の関連を明示するのはオブジェクト図の方が適しています。一方、オブジェクト図は場所を取ります。ある程度まとまった数のレコードを作っていくとかなり大きな図になり、それはそれでみづらいです。ですが、例えば、ある種のワークフローがスタートして、途中、いろいろとデータが変わって、最後に終わるというところまでを、具体的なデータを当てはめて検証するということができるので、設計の妥当性を確認するツールとしては役に立つものです。
次回は、ビューをモデル化するのかという議論と、SQLのテーブル定義やビュー定義と設計の関係を説明しましょう。