前回は多対多の概念の学習ということで、元々IDを割り振った、つまりは第二、第三正規形を満たしているような状況で説明をしました。残るは第一正規形を満たすようにするということを考えれば、「中間テーブル」を持つことがあたかも自然に発生するように説明しましたが、ちょっとレールに乗り過ぎたようです。改めて、前回のような、学生の管理、履修科目の管理という視点から、「表にする」ことによって分解を進めるということがどういうふうに進むのかを考えてみましょう。
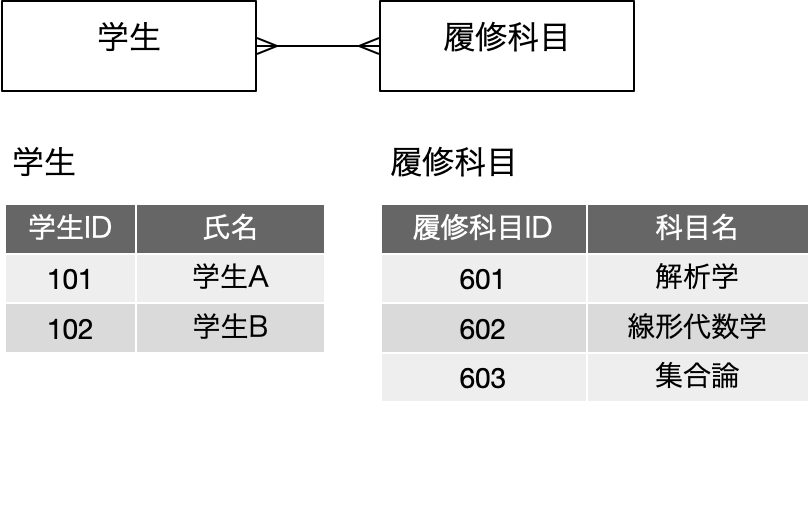
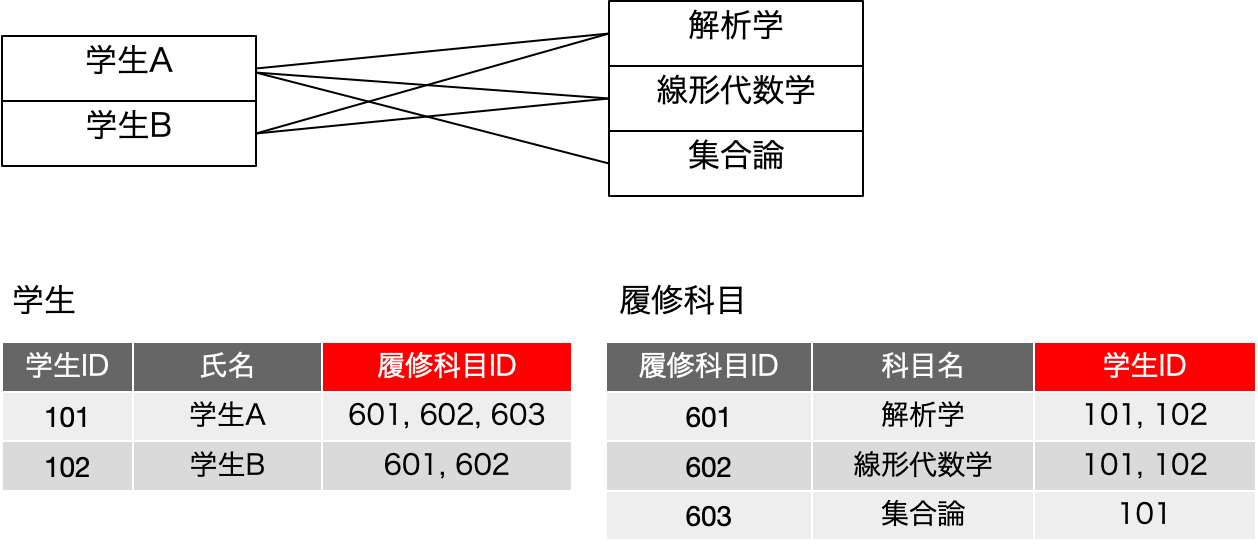
まず、「学生」という表があるとします。学校としては、入学した学生の一覧は必ず作るでしょうから、学生一覧がExcelで作られていると想定しましょう。以下の図では、氏名だけがフィールドとして存在していますが、実際には読み仮名や学科、入学年度、住所など多数のフィールドがあると思われます。今回はそれを書きませんが、氏名以外にもフィールドがあるという前提で考えてください。そして、学生課では、入学した2人の学生が(そんなに少ないわけではないのですが)、科目履修をすることになりました。申込用紙を作るなどして希望を集めた結果、「履修科目」フィールドに履修科目をカンマ区切りで描きました。これで、誰が、どの科目を、履修しているのか、という点では記録できたわけです。使いやすいかどうかは別にしてともかく記録はできていると言えるでしょう。一方、教務課では若干興味が違います。履修科目はおそらく入学前から決まっていてこの場合は3科目あり、「履修科目」表に記載しています。この表も同様に名前以外に年度、教室、担当教員などいろいろありそうですが、それがともかくぶら下がっていると考えてください。そして、学生課から教務課へ、学生が書いた履修希望の記入用紙が「そちらも必要でしょう」ということで回ってきました。こちらは科目が興味の中心なので、「履修者」というフィールドを設けて、履修する学生をカンマで区切って記載しました。ここで、2つの部署で、「履修登録用紙」を元にしたデータをそれぞれ作ってしまっています。ということで、まずは表を増やさないで、つまりは気持ちの上での「データの一元化」を果たすため、フィールドを追加してやや強引にデータを追加したとしましょう。現実の学校では、学生数や科目数を考えれば、即座に破綻しそうですが、ここでは架空の状況としてそのように考えましょう。
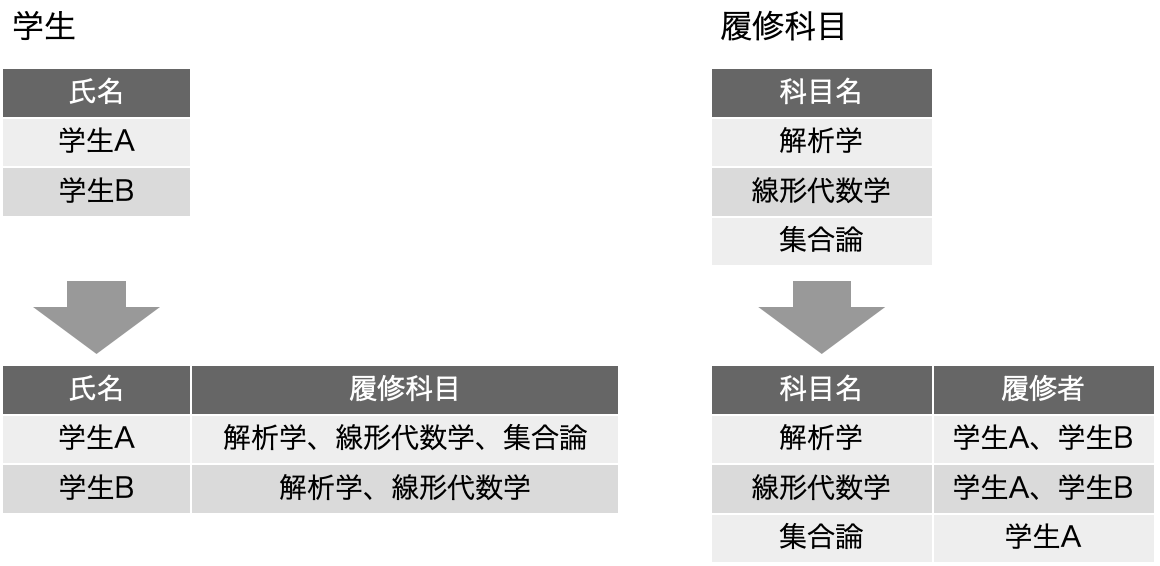
ここで、教務課ではふと思いつきました。「担当の先生に履修者名簿を渡さないと行けない」ので、さてどうしましょう。履修者フィールドの句点を改行に変えるとか、それをRPAでやればいいではないか!DX〜!!!とか言い出しそうですが、もう少し伝統的なExcelライクな方法もあります。以下のように、履修科目ごとにシートを作って、そこに履修者名簿を作るのです。これだと、最近までやっていましたという学校もあるかもしれません。

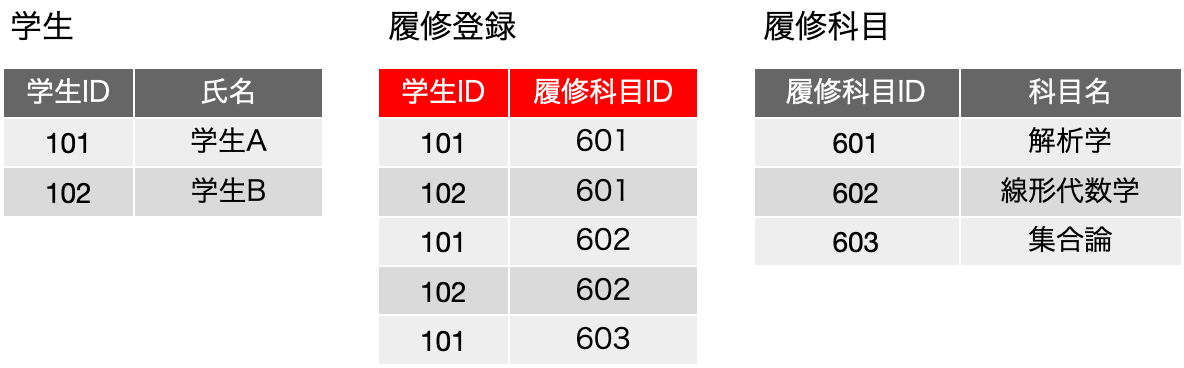
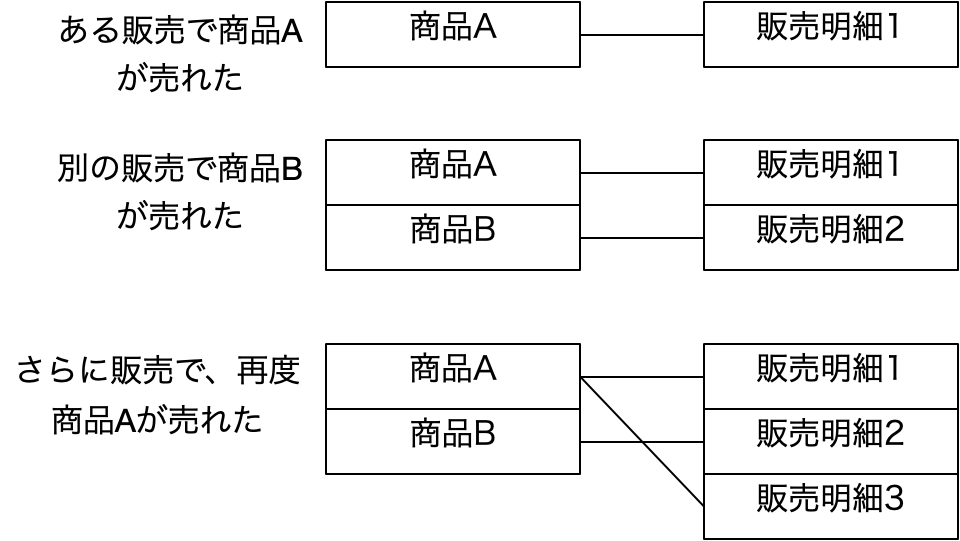
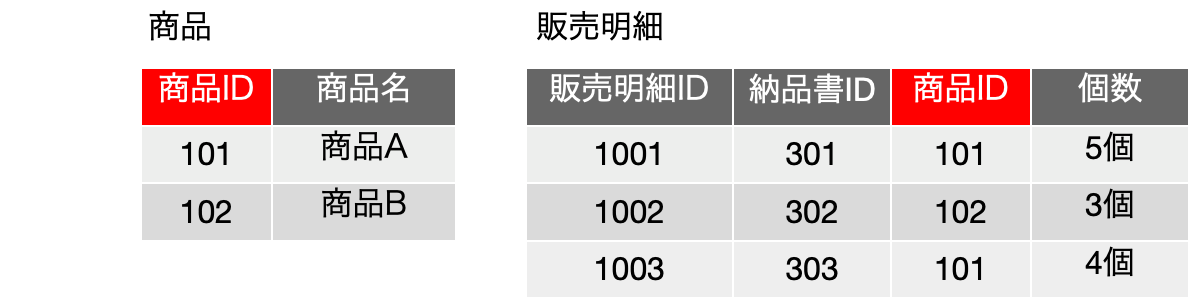
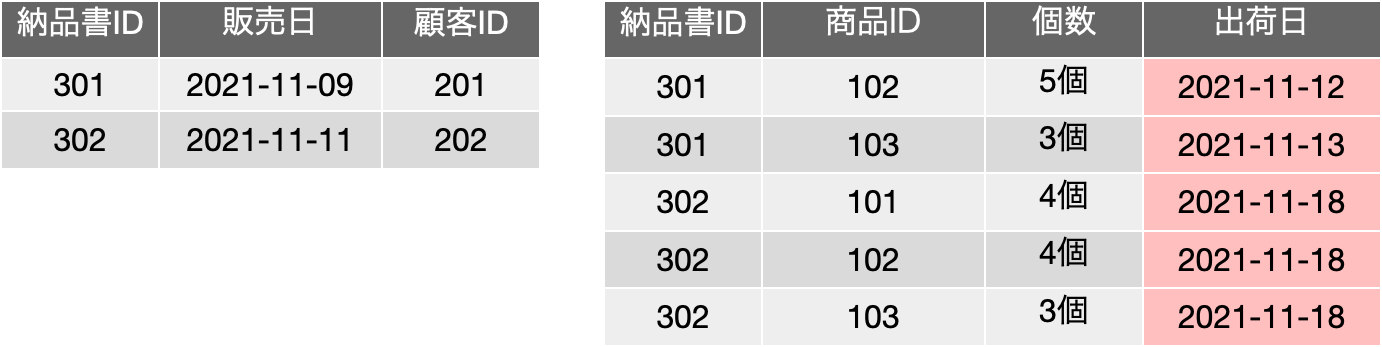
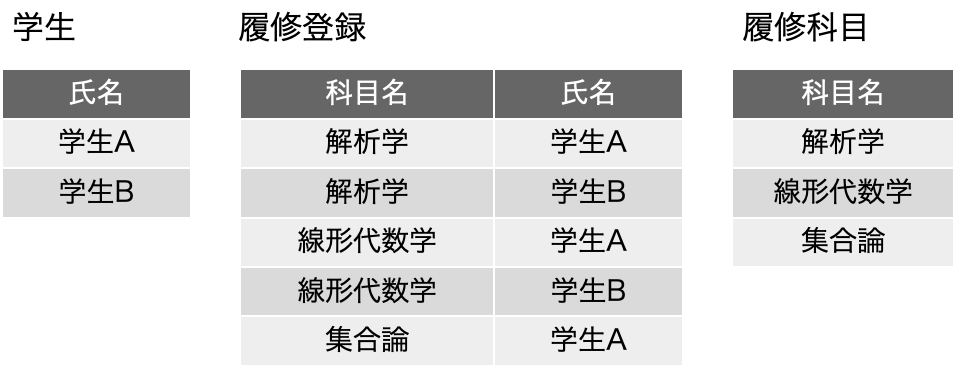
ここで、中央に3つある履修科目ごとの履修登録の表は、どうみても、同じフィールド構成になります。つまり、縦に繋げられるじゃないかと。だけど、それじゃあ解析学の履修登録名簿はどうやって得られるのだと突っ込まれます。ここで、ありがちな鋭い登場人物が出てきて、「それは検索すればいいのです」ということで、以下のような表にまとめることができるということに気づきます。これは、実は単独の履修科目で発生していることを、どの履修科目でも発生しているということに気づき、前の図を得るには、履修登録表で、指定した科目名のレコードだけを残せば良い、つまりは検索すれば前の表の情報が得られるように、表の構成を工夫したということです。3つある表を単に合体しただけでは元の3つの表は得られませんが、その時、各レコードに、どの表からそのレコードを持ってきたのかを記録すればいいわけです。そのことを単純に実現するためには、科目名フィールドを追加するということで、それを検索の手がかりにすれば、元の表が得られるということになります。これを素で思いつくのは本当に優秀な人なんでしょうけど、少なくとも普通の私たちは、事例を通じてこうした抽象化の1つの流れを学習し、学生と科目以外の他の関係にも適用できるようになっておきましょう。そして、その知見を元にすれば、その時々の状況に応じてデータベースの設計ができるようになります。
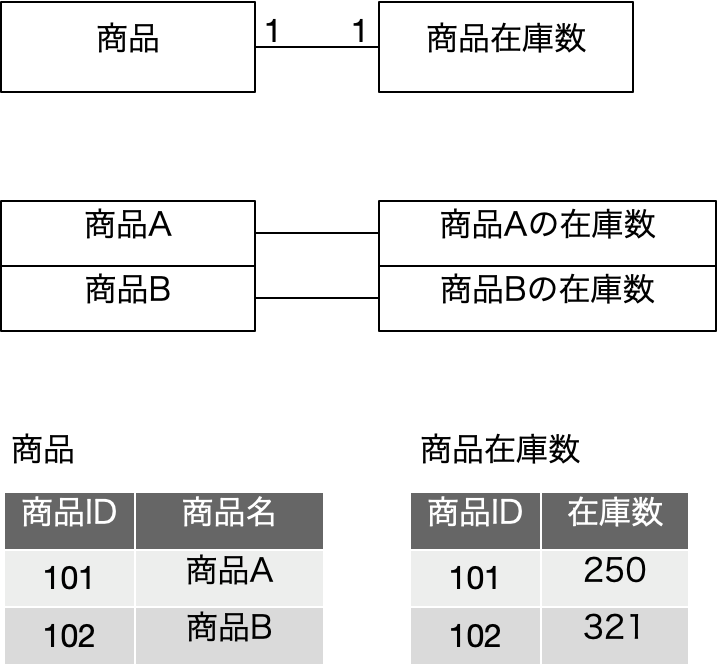
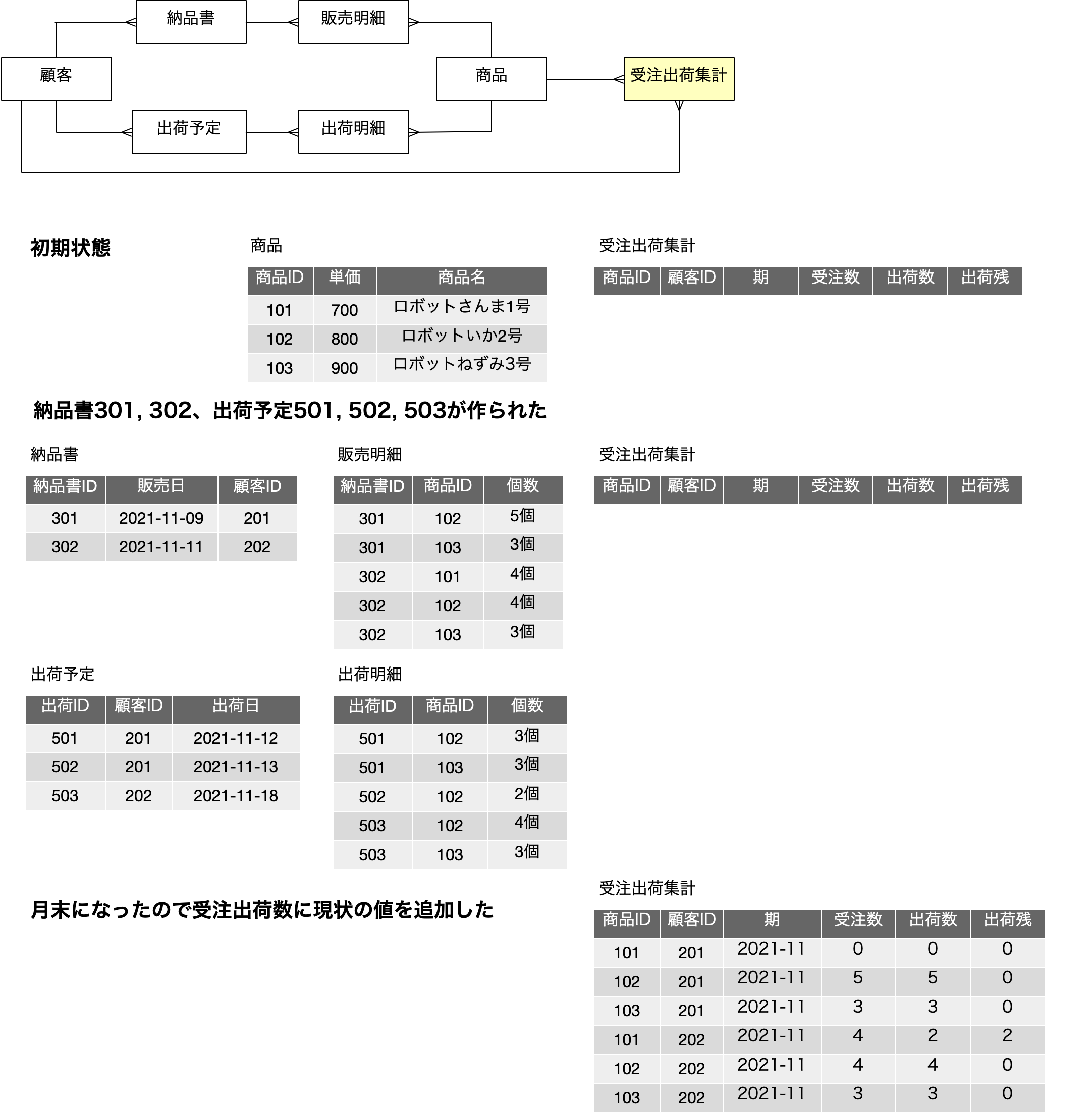
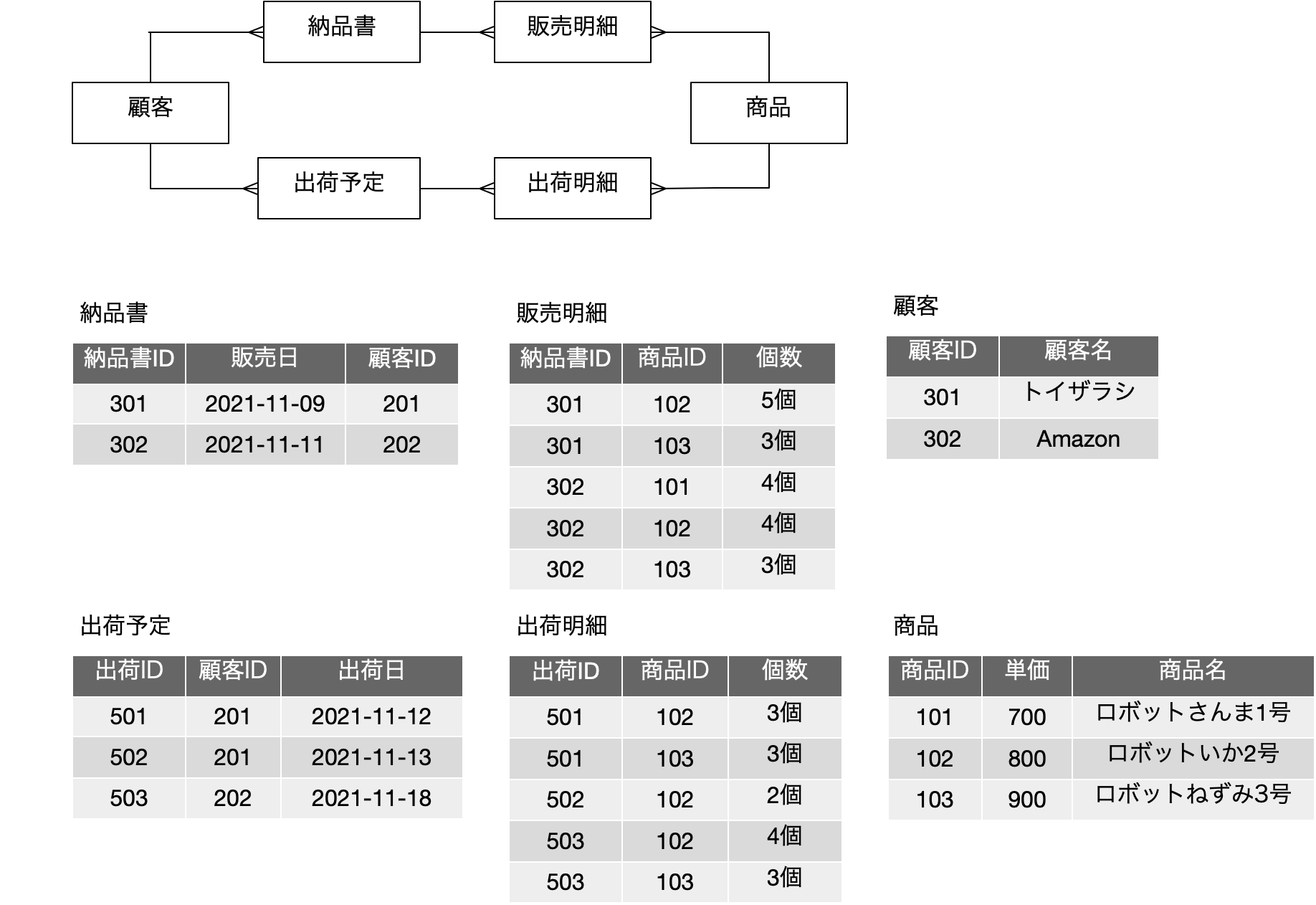
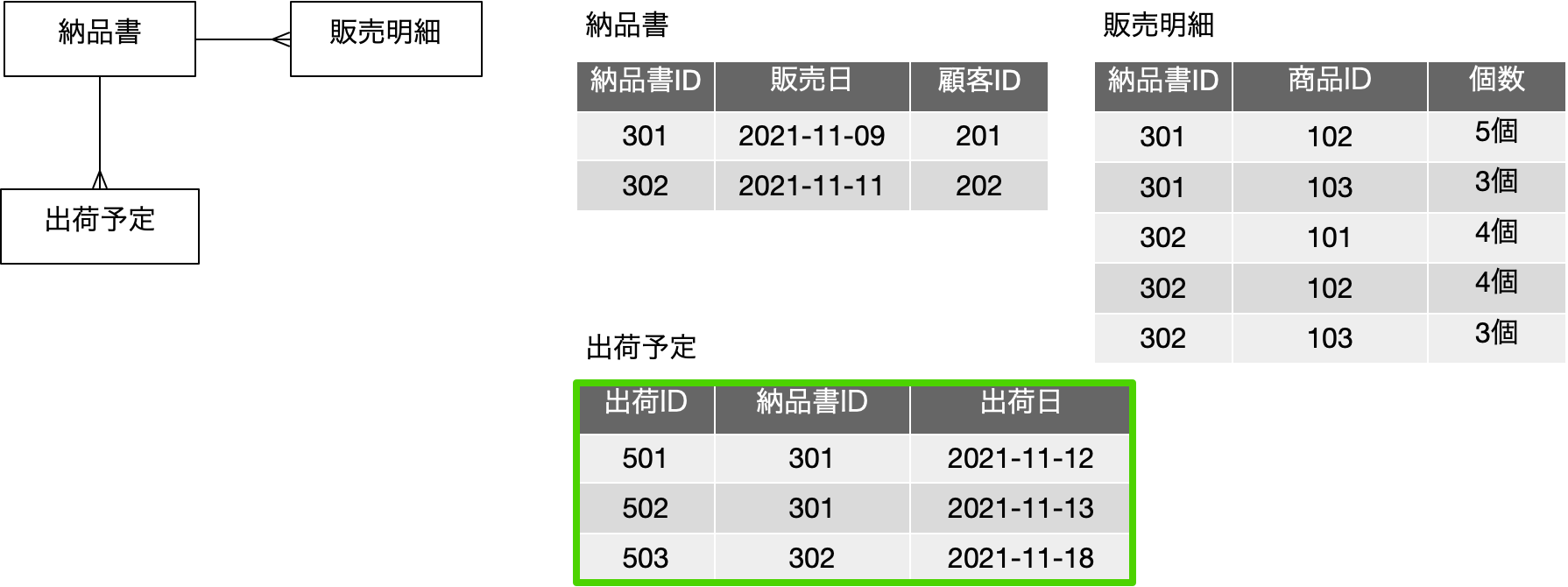
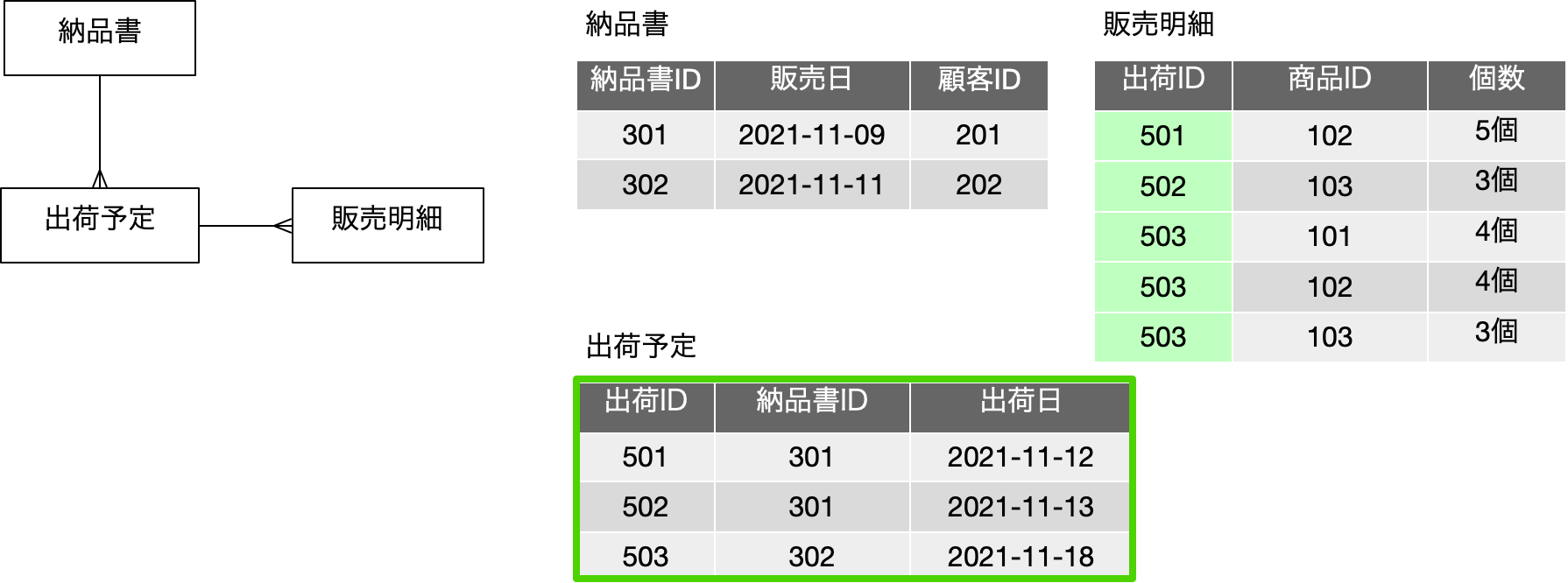
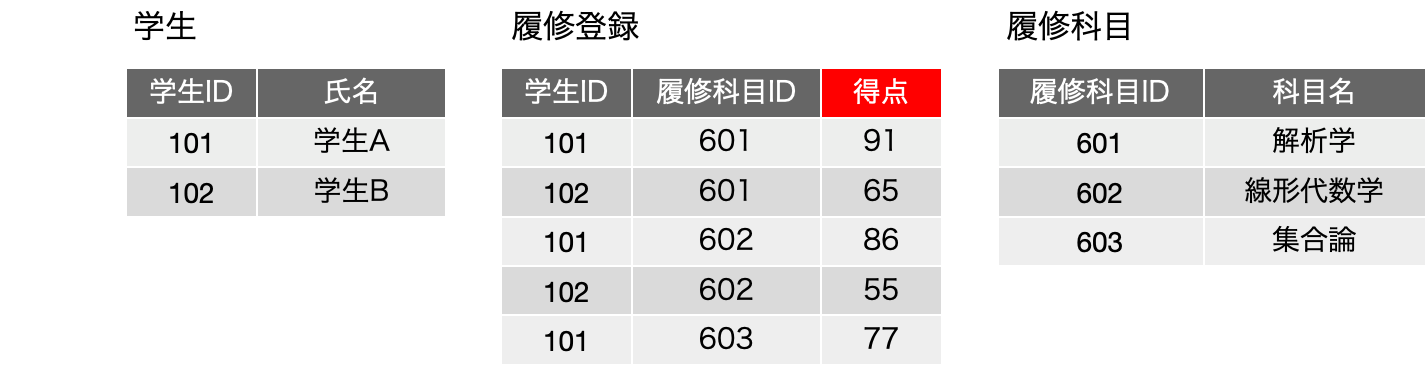
再掲になりますが、前回に出てきた以下の図は、上記の図を、学生、履修科目に対して、ID番号に置き換えて、それぞれIDで参照するという前提で書き直したものです。IDがあること以外は、表現している内容は同一のはずです。
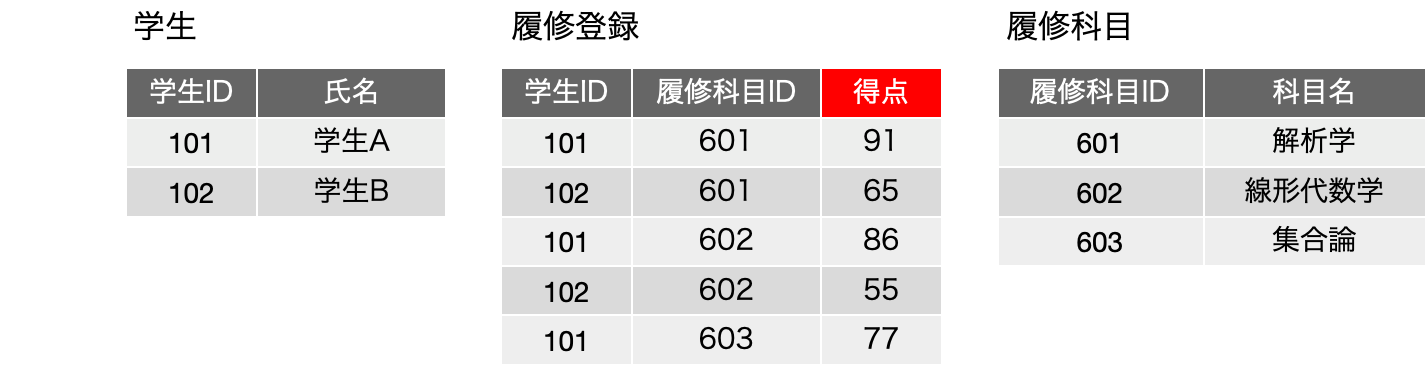
改めて、学生課、教務課に立ち戻って考えてみたいのですが、このまま学年が進み、最初の2人の学生が卒業する時になって、「あ!成績表を作らないといけない」となったとします(普通はそんなことはない!)。その場合、今日の2つ目の表のように、「成績表-学生A」「成績表-学生B」というシートを作ればいいじゃないかということになりますが、3つ目の図のように、学生に関わらず構成が同じということを発見すれば、結果的に「成績表」という1つにまとめられます。そして、その「成績表」は細かいフィールド構成を考えなければ、つまり、学生と科目を結びつける存在というより抽象度の高い存在意義を考えれば、実は「履修登録」と同じになります。よって、履修登録に成績を記述することは合理的と言えるでしょう。
履修名簿も、成績表も、どちらも同じ表から得られます。それらは何を基準にして検索するかの違いしかありません。もちろん、実際にレイアウトを作る時にはいろいろ違いがあるでしょうが、データの在り方、すなわちデータベース設計においては、どちらも同じここでの「履修登録」表からの得られるということで、この表はデータベース内において存在すべき表である、そして必要十分な表と言えるのです。厳密には、要求を満たしているかを常に検討はします。元はと言えば、学生課と教務課で同じデータを作ったため、どちらから考えても、論理的には同じ「履修登録」表ができているとも言えます。
前回は、今回の最初の図のような状況において、学生の表にある履修科目フィールドを見ると、あっさり第一正規形を満たしていないからテーブル分けましょうと言いましたが、ここで第一正規形について、改めて詳しく説明しましょう。ただ、本来は集合論の話から入らないといけないのですが、そこはうまく飛ばして説明を試みます。
以下の図の左上は、最初の図にも出てきていましたが、これをもう少し拡張高く(笑)書くと、要素に集合があるという左下の書き方や、表の要素が表であるという右側のような書き方になります。いずれも履修科目フィールドには、合成あるいは繰り返したデータがあるという見方をします。第一正規形はこうした合成や繰り返しが存在しない状態になっているということです。ちなみに、集合と表は、データベースの世界ではほぼ同じと考えてよく、表を抽象的に捉えると集合であるということに他なりません。この時、何を持って合成や繰り返しとみなすのか?つまり、何回も出てきている「素なデータ」、つまりこれ以上分割できないデータの解釈が問題になります。「素」は意味的には数学の素数のことになります。これは次回からのテーマにしたいのですが、ここでは定義として「単一の科目」が素なデータであるとみなしているとします。集合も表も、素なデータではなく、少なくとも「複数の素なデータ」です。もう少し詳細に言えば、「素ではないデータがどこかにあるかもしれない、あるいは素でないデータが存在する可能性がある」ということで、たまたま現状の表で素なデータばかりだとしても今後素ではなくなる可能性があるのなら、そこは第一正規形を満たしていないポイントとして見る必要があります。
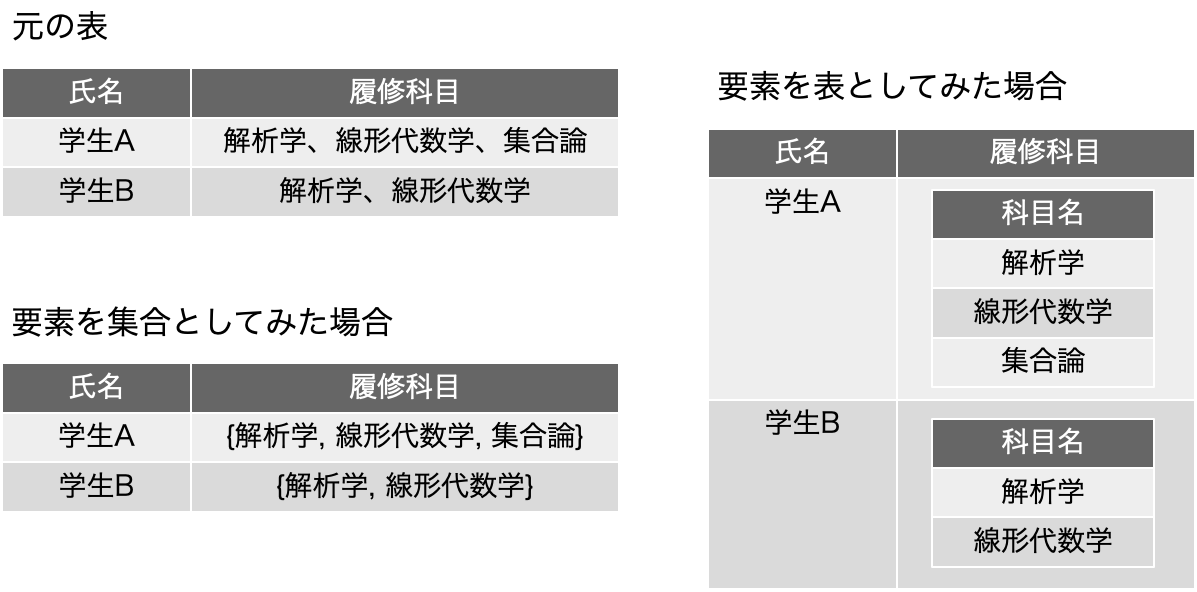
これらの表を第一正規形を満たすように変換した結果は、事実上、今回の3つ目の図にある「履修登録」表になります。図では、科目名が先にありますが、学生フィールドが先にある方が考えやすいかもしれません。ここで、上の図だと、同一の「履修科目」が複数登場しますが、学生は1回しか登場しません。これに対して、「履修登録」表は、学生も履修科目も複数登場します。同じデータがあちこちに登場してしまって、効率が悪く変更も大変ということになるのですが、それを解決するのが第二、第三正規形の考え方です。要するに、フィールド内で繰り返すのをやめよう、レコードとして繰り返しているものはなんとかなります、というのがリレーショナルデータベースの動作の基本ということなのです。
ちなみに軽く宣伝ですが、表の中に表があるというと、そうですね、INTER-MediatorではそういうUIを構築できます。さらに自慢をしておくと、FileMakerはポータルの中にポータルは配置できませんが、INTER-Mediatorは、表の中の表を何階層にも定義できます。実際には3つ程度でやめておくのがパフォーマンス的には有利ですが、機能は持っています。それじゃあINTER-Mediatorは第一正規形を満たしていないのかというと、それとこれとは意味が違います。INTER-Mediatorは第一正規形を満たしているデータベースから、表の中に表があるようなUIを構築できるのです。データの整合性は設計の上で取れているものから、人間が見てわかりやすい形式に表示できるUIの構築機能があるということで、第一正規形を崩しているわけではありません。データベースのレイヤーで、第一正規形を満たしておき、保存されているデータに整合性が確保されているということが重要なポイントになります。
ちなみに、第一正規形は繰り返しデータだけでなく、合成データにも当てはまります。合成データの代表と言えば、住所ですね。住所として1つに記録するか、都道府県や市区町村を分離するのかなど、議論の的になるのですが、実はこの話は第一正規形に至る部分でデータベースの理論の世界では整理されています。
ということで、次回からは、データベース設計における「1つの塊」をどのように考えるのかということのシリーズに入りましょう。