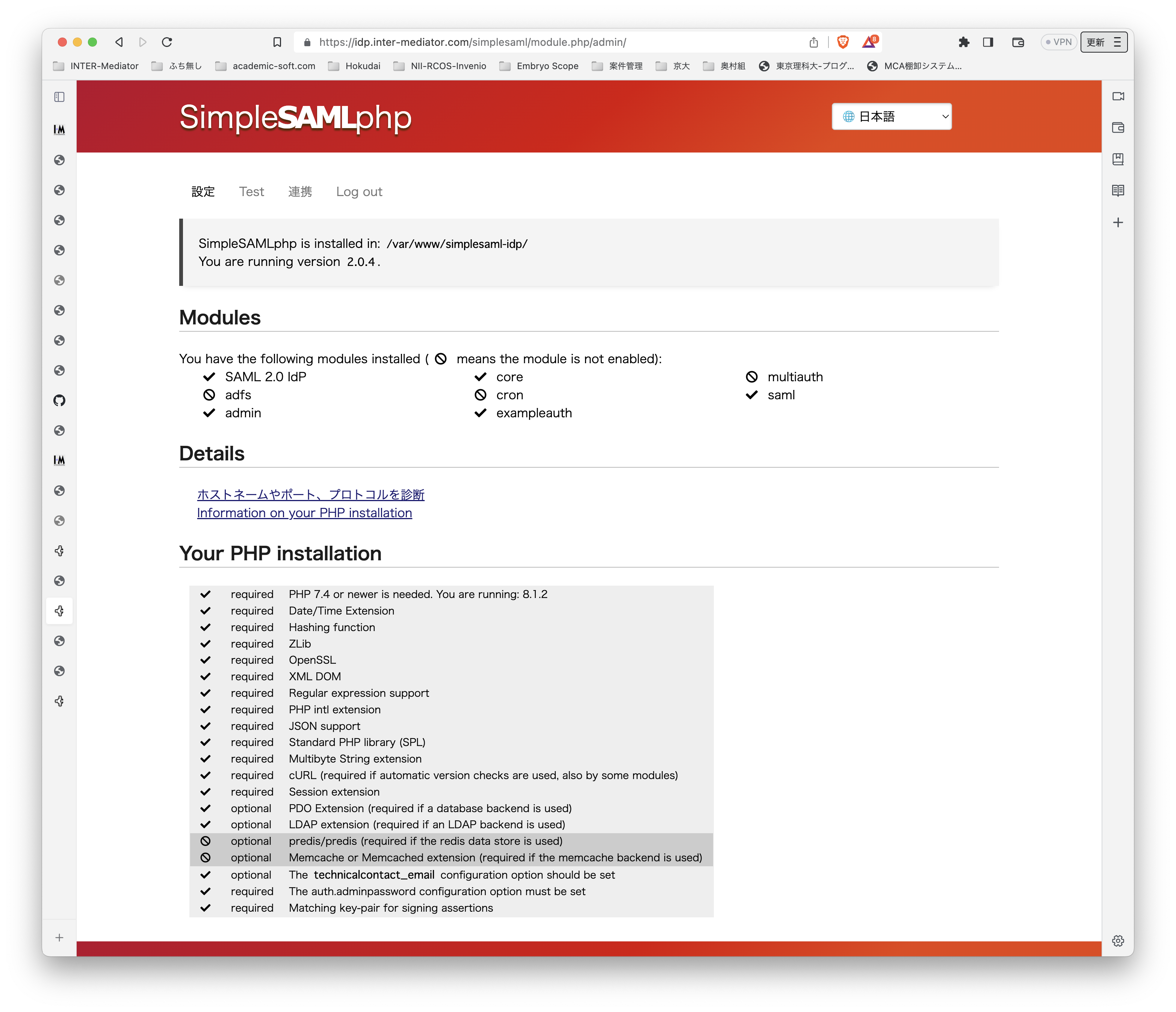
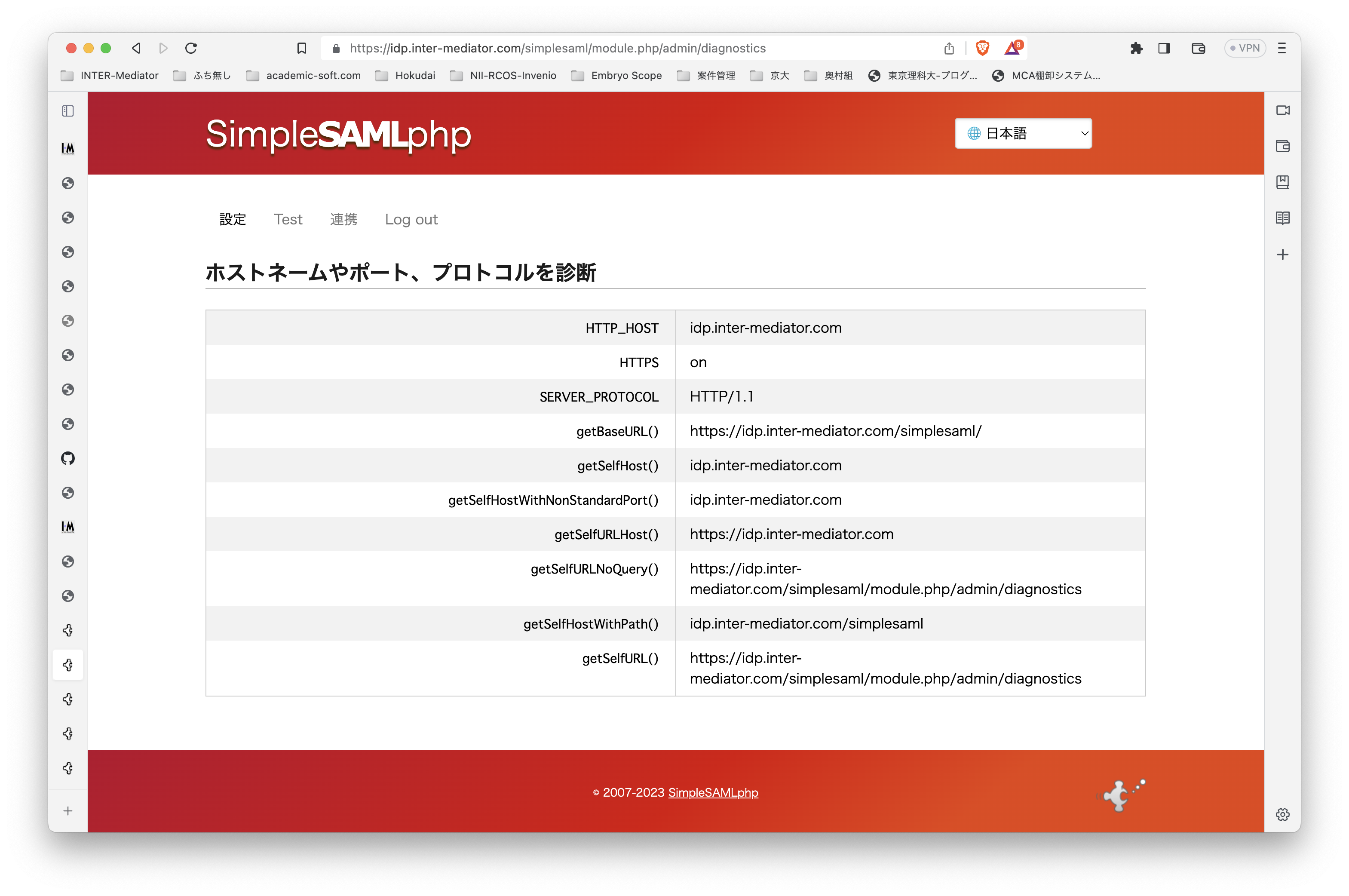
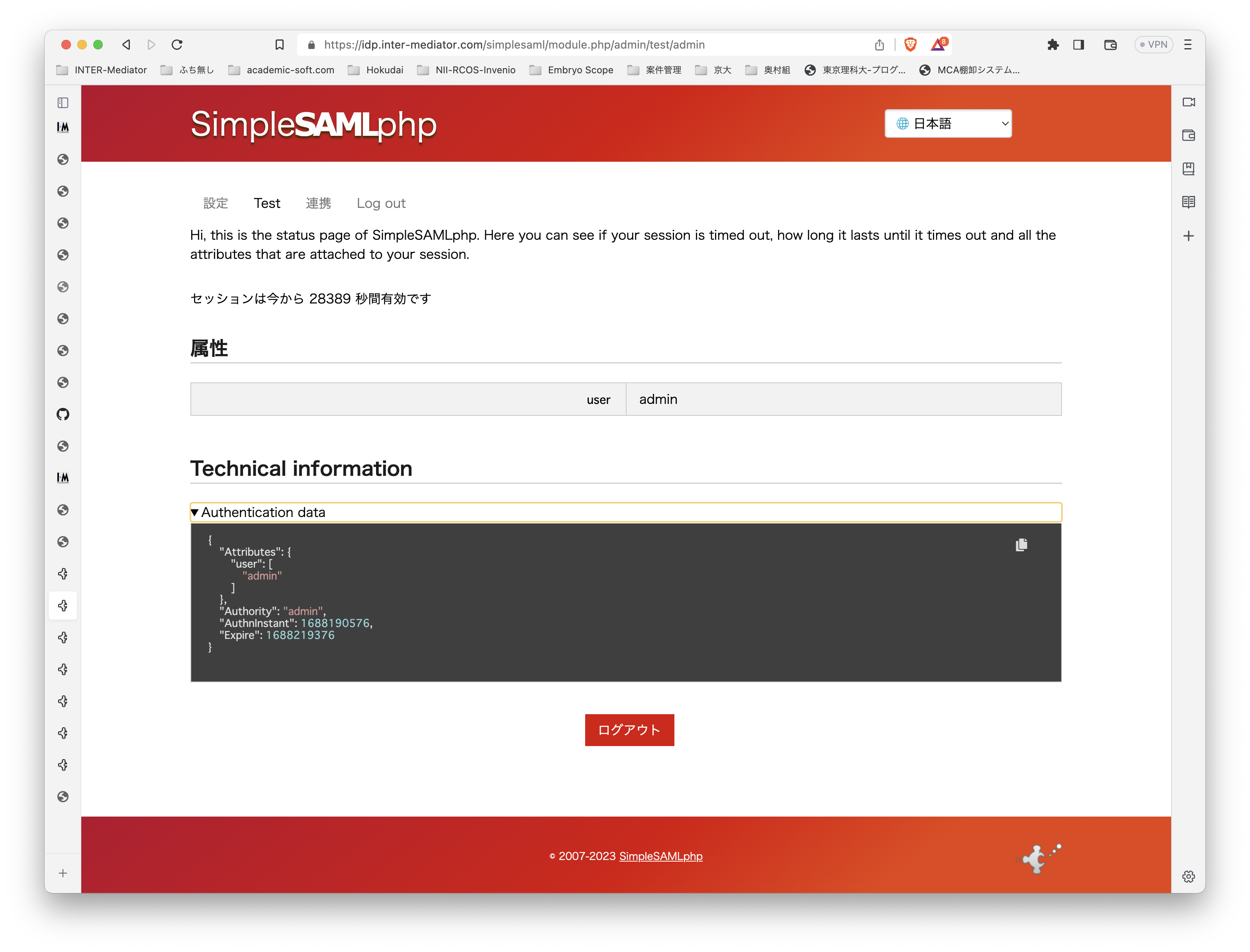
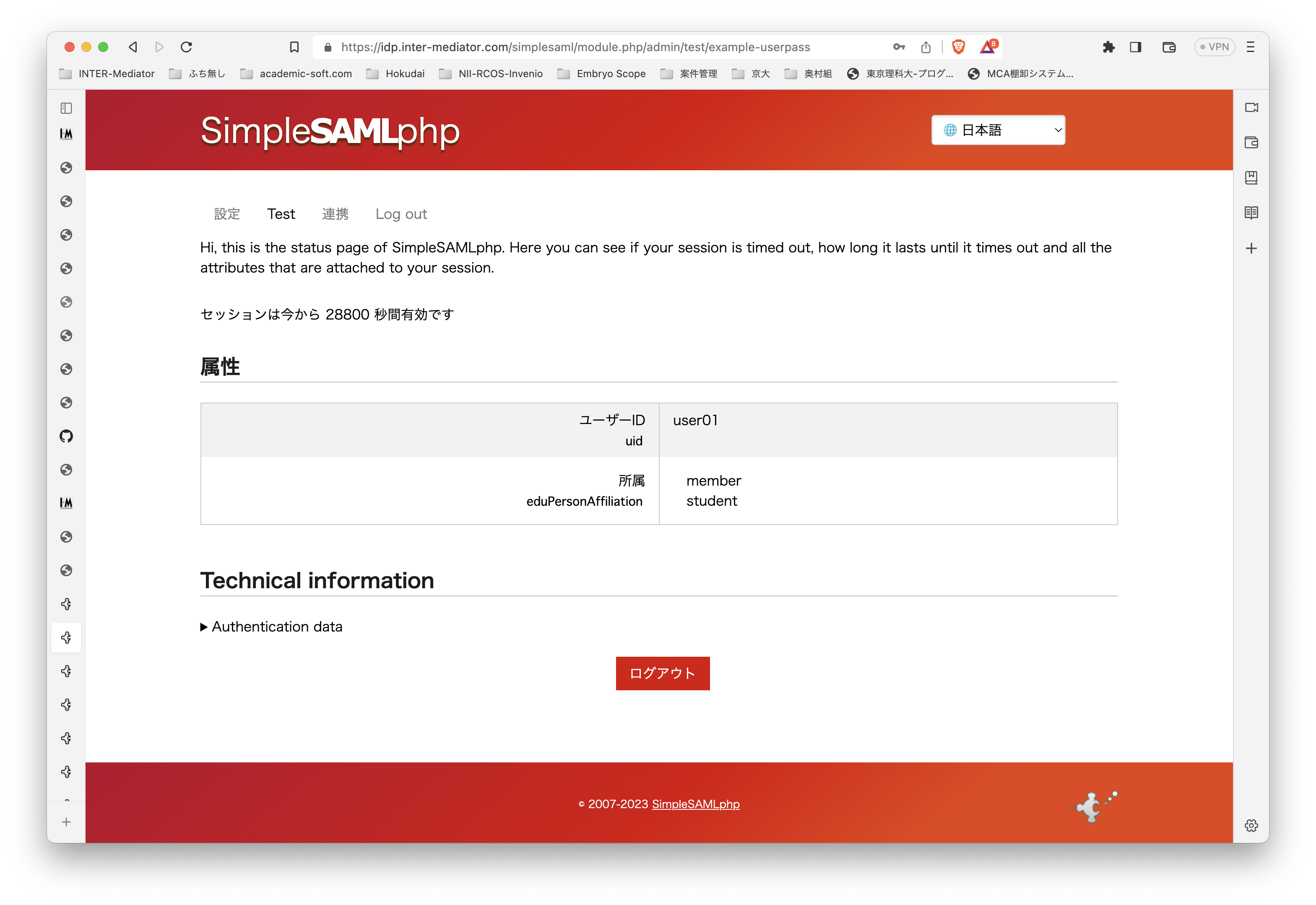
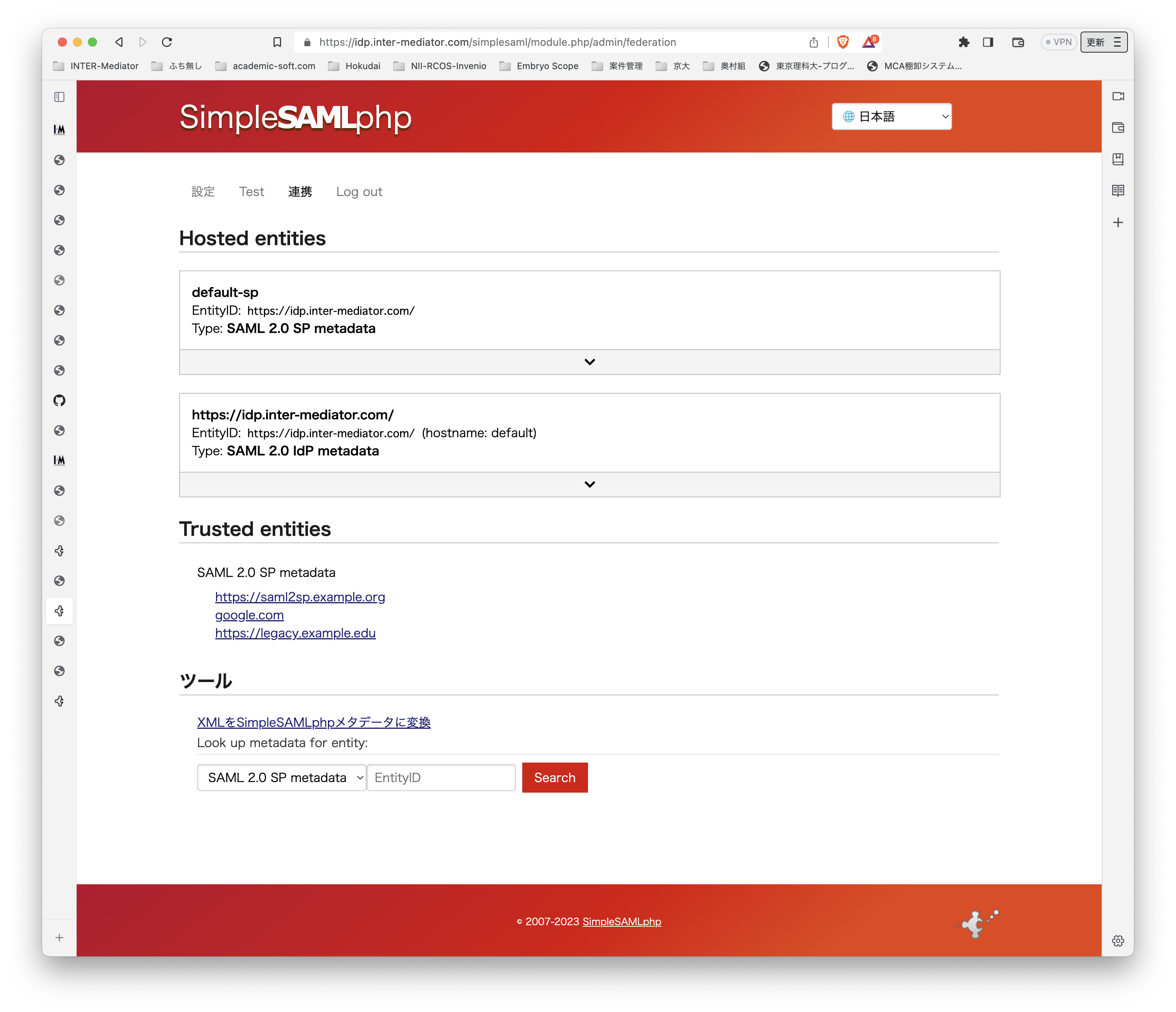
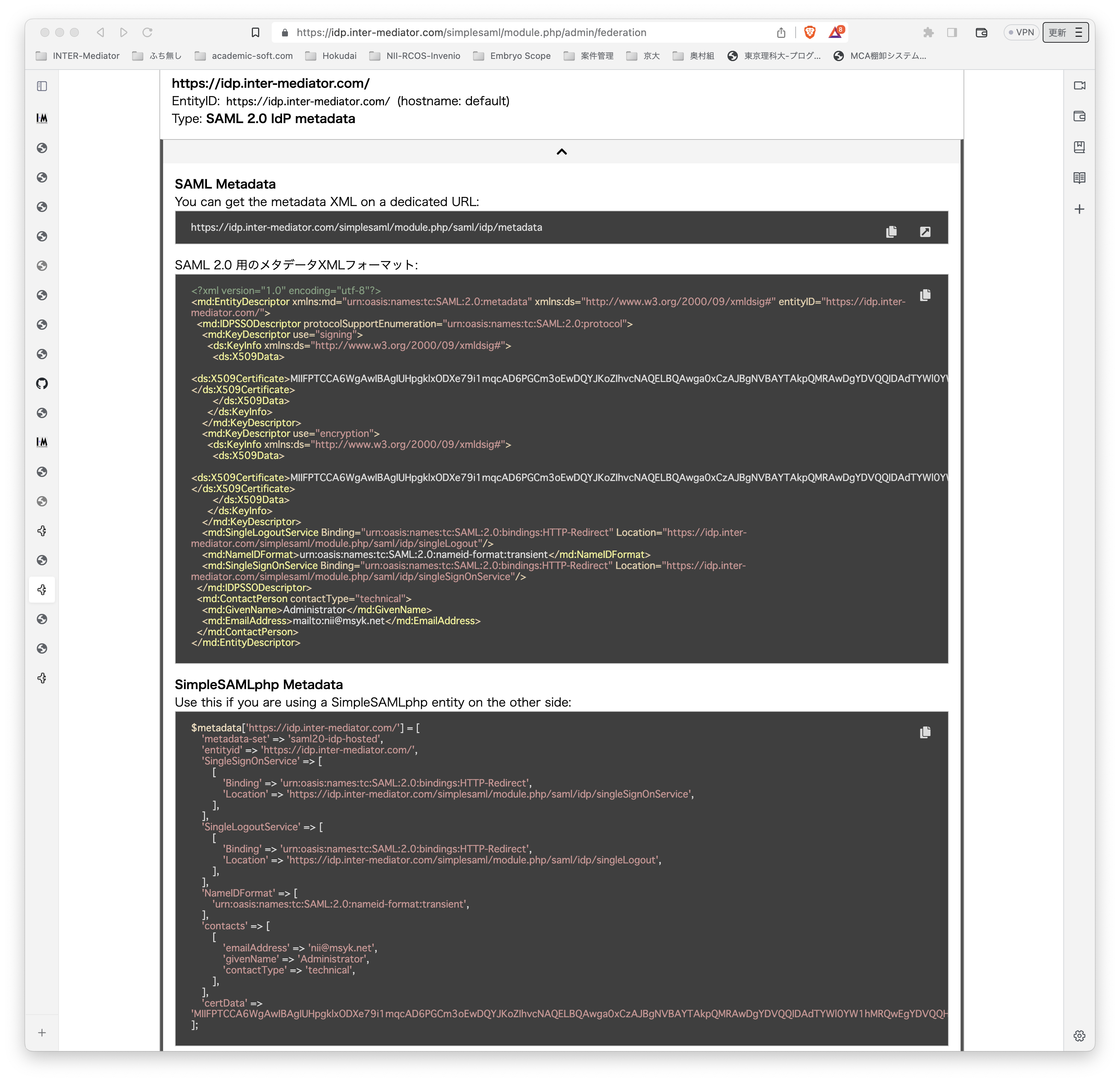
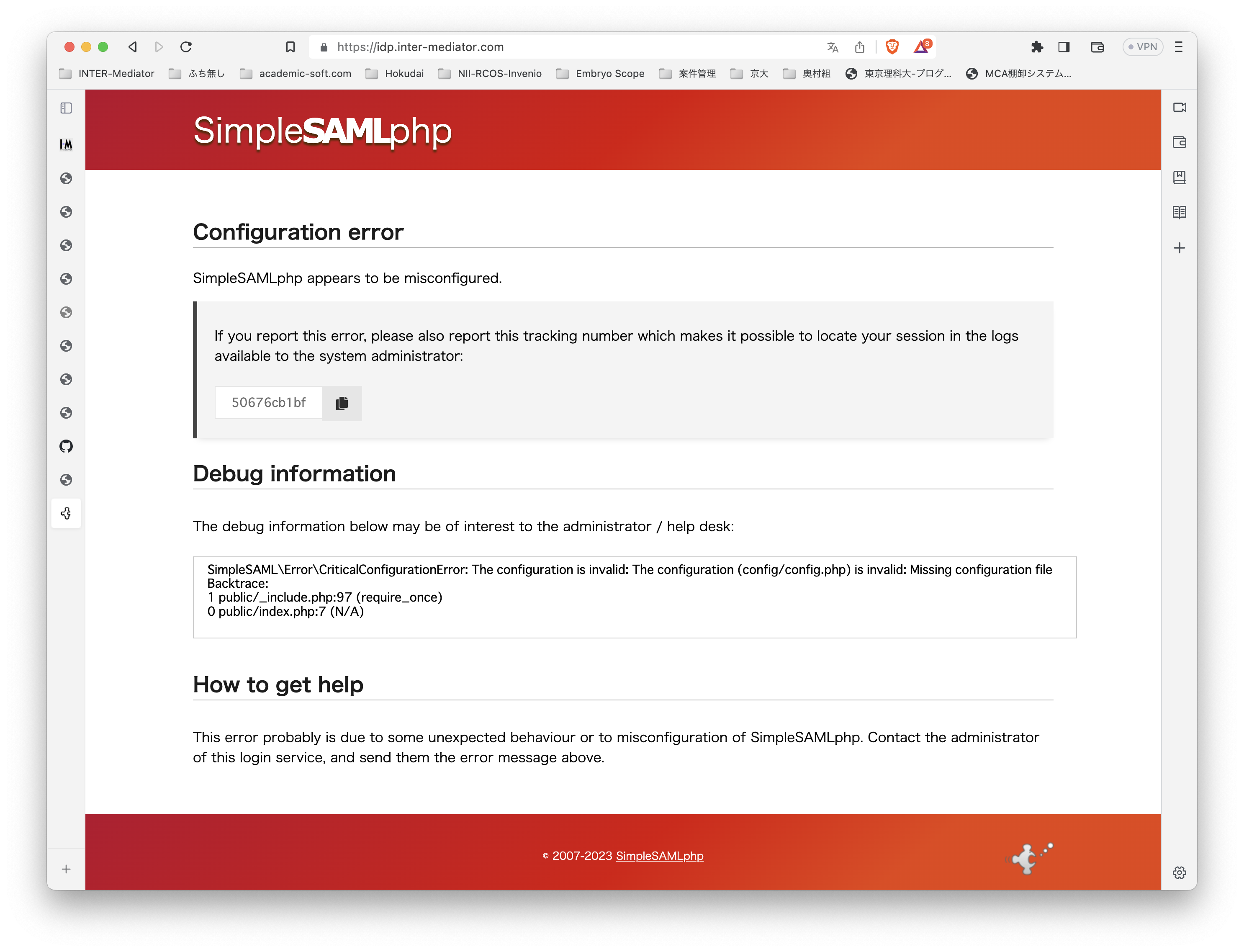
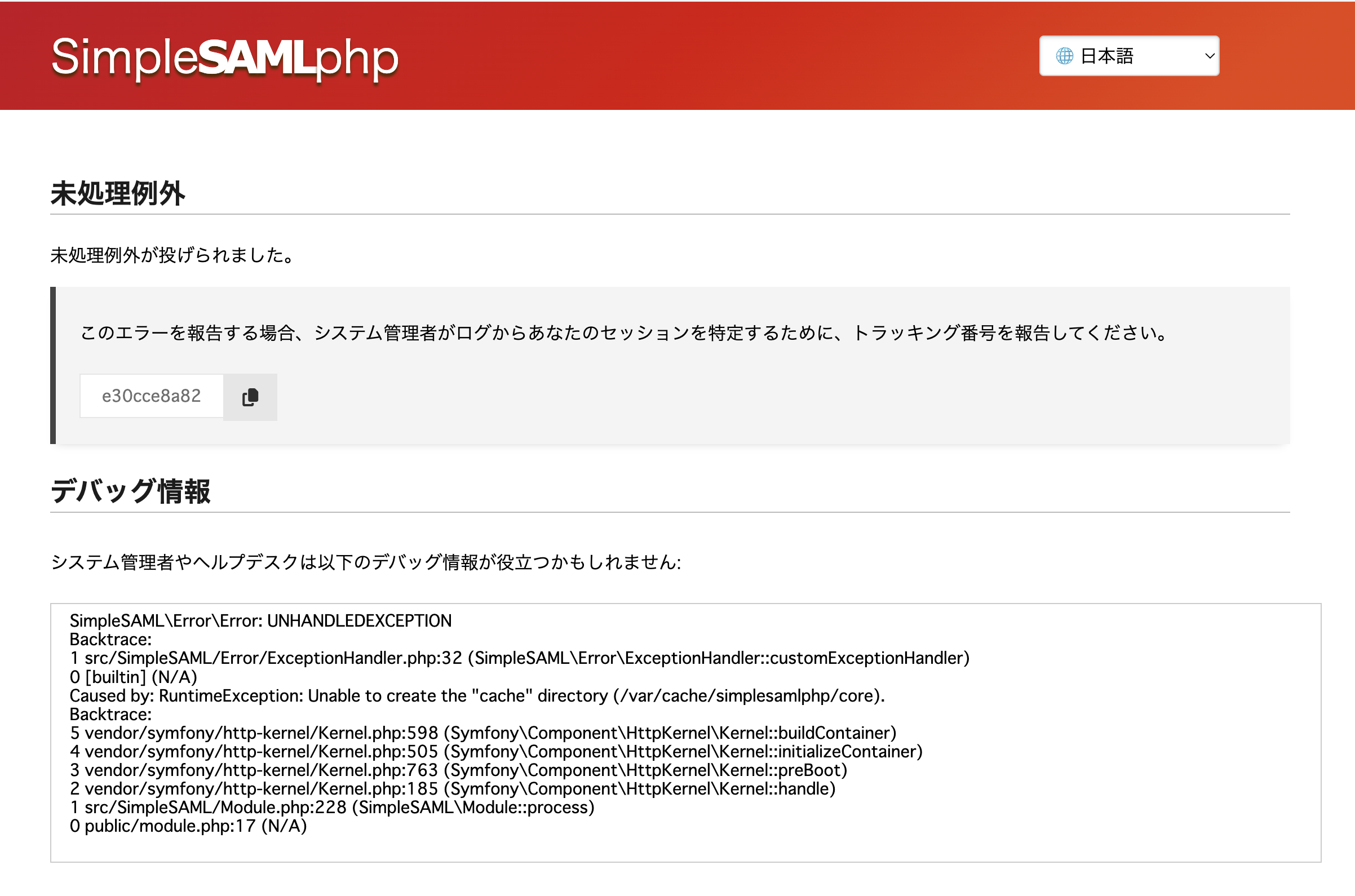
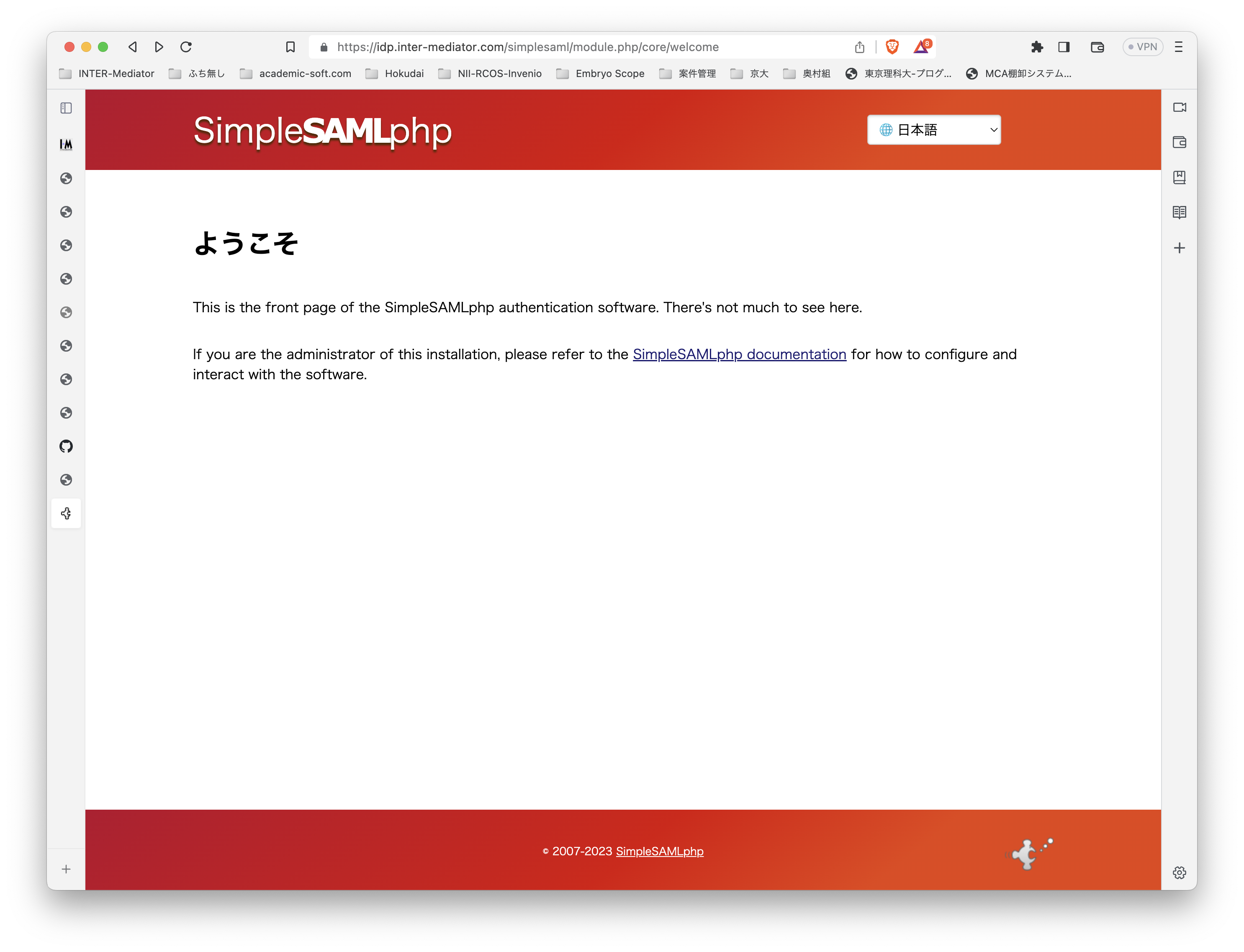
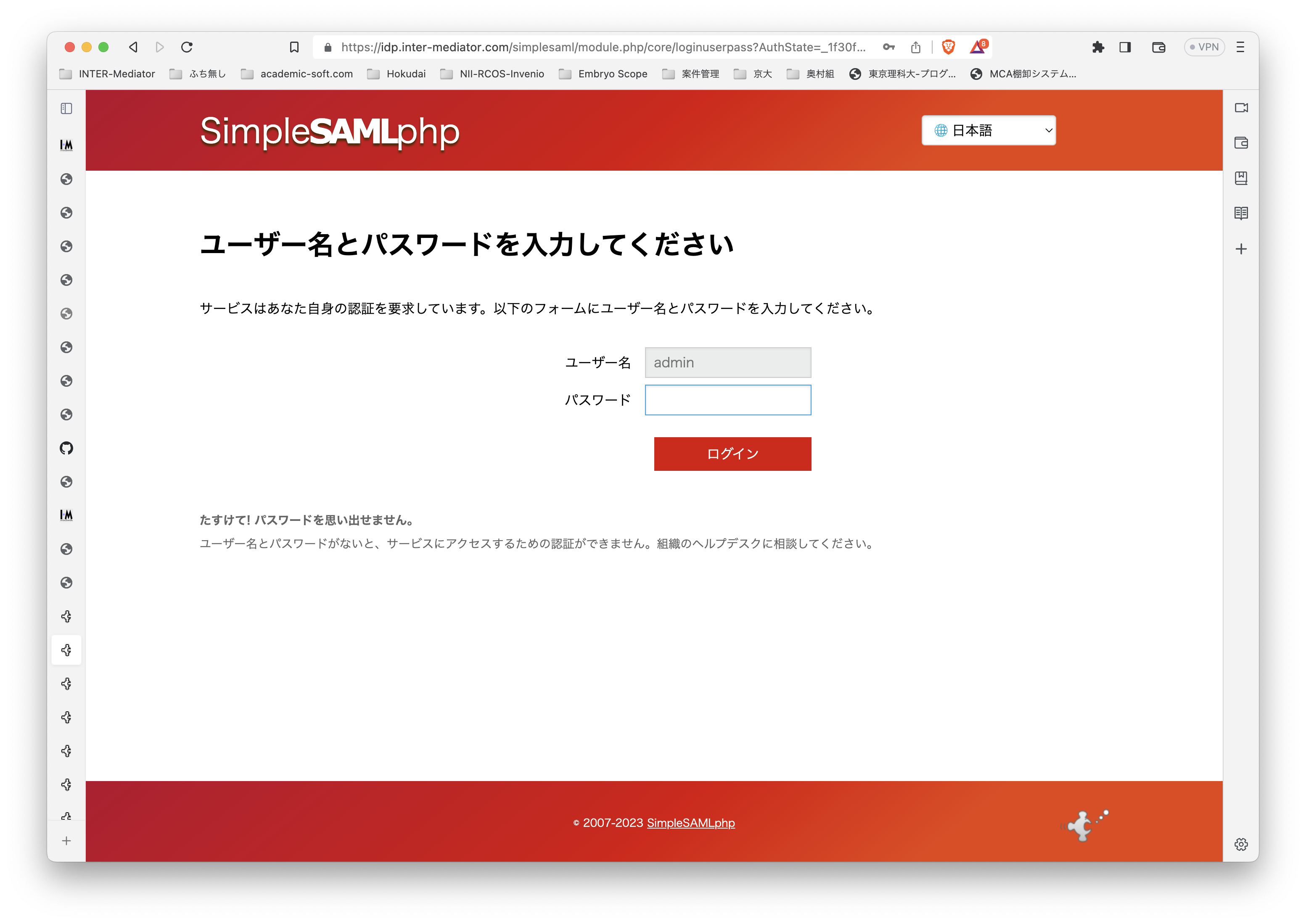
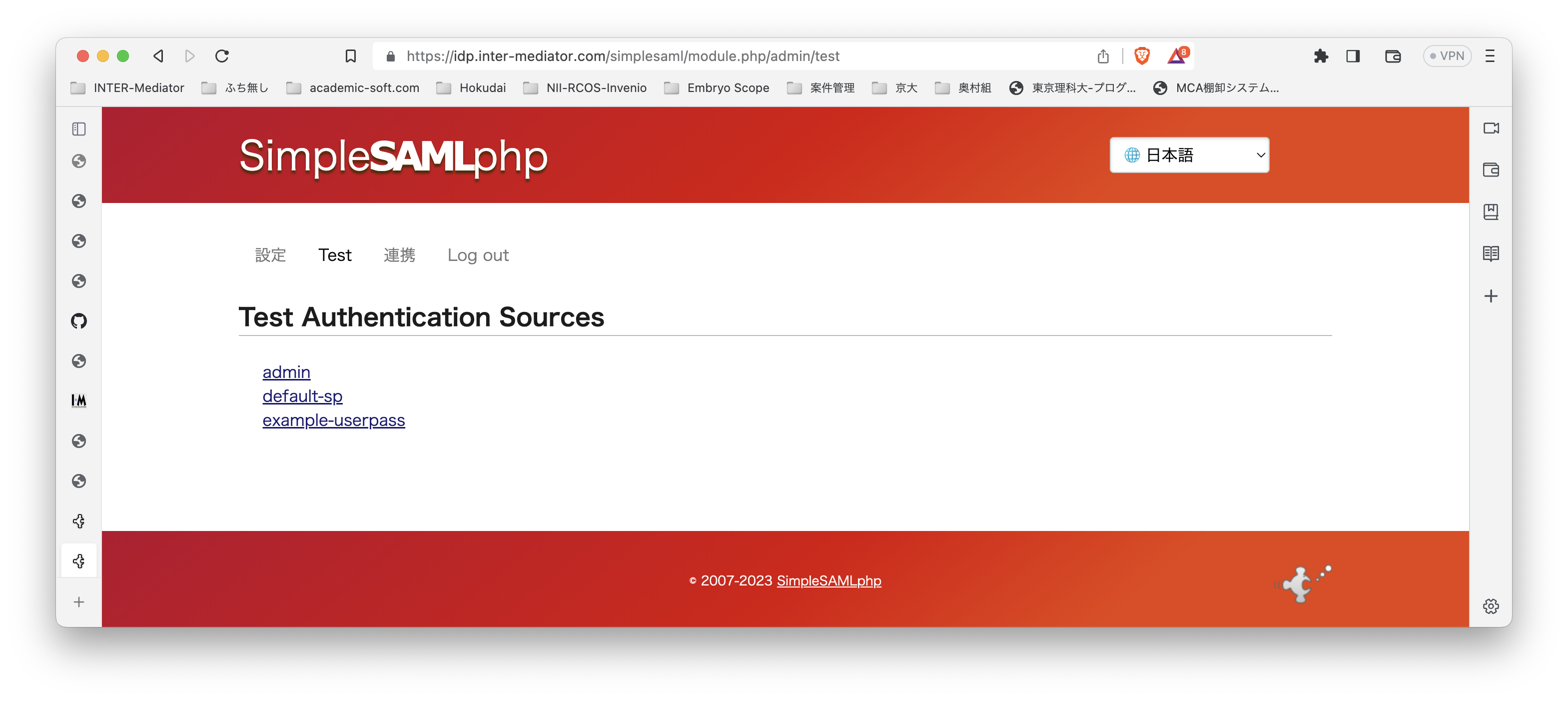
テスト環境ですが、Ubuntu Server 22.0.4 LTSです。よって、PHPは8.1です。普通に、Apache2、PHPとモジュールをインストールしました。INTER-Mediatorをインストールする以外には、PHPのSOAPモジュールを追加するだけで大丈夫でした。 テスト用のアプリケーションも当然ながらINTER-Mediatorで作ってあるのですが、SimpleSAMLphpのVer.1とVer.2の相互運用も考えないといけないのかなとも考えられます。
Country Name (2 letter code) [AU]:JP
State or Province Name (full name) [Some-State]:Saitama
Locality Name (eg, city) []:Midori-ward
Organization Name (eg, company) [Internet Widgits Pty Ltd]:INTER-Mediator
Organizational Unit Name (eg, section) []:Authentication Support
Common Name (e.g. server FQDN or YOUR name) []:idp.inter-mediator.com
Email Address []:nii@msyk.net
$metadata['https://idp.inter-mediator.com/'] = [
/*
* The hostname of the server (VHOST) that will use this SAML entity.
*
* Can be '__DEFAULT__', to use this entry by default.
*/
'host' => '__DEFAULT__',
// X.509 key and certificate. Relative to the cert directory.
'privatekey' => 'idp.inter-mediator.com.pem',
'certificate' => 'idp.inter-mediator.com.crt',
Ubuntu Server 22.04.1 LTS上で、INTER-Mediatorのサンプルを、MySQLで動かすところまでのセットアップ方法を紹介します。サーバは普通にDVD等でインストールします。ほぼ、デフォルトでセットアップした状態を想定しているので、Minimalの方ではありません。また、サーバアプリケーションは、SSH Serverだけをセットアップ時に含めているとします。
brew tap shivammathur/php
brew install shivammathur/php/php@7.4
この後に、brew link …とすればいいかと思うのですが、現行バージョンのver.8.2をunlinkする前だと、–overwriteをつけろとメッセージが出てきます。以下の流れだと、–overwriteは不要かもしれませんが、エラーの時には試してみましょう。
% brew unlink php@8.2
% brew link --overwrite php@7.4
Linking /usr/local/Cellar/php@7.4/7.4.33... 25 symlinks created.
If you need to have this software first in your PATH instead consider running:
echo 'export PATH="/usr/local/opt/php@7.4/bin:$PATH"' >> ~/.zshrc
echo 'export PATH="/usr/local/opt/php@7.4/sbin:$PATH"' >> ~/.zshrc
% php -v
PHP 7.4.33 (cli) (built: Dec 8 2022 21:39:37) ( NTS )
Copyright (c) The PHP Group
Zend Engine v3.4.0, Copyright (c) Zend Technologies
with Zend OPcache v7.4.33, Copyright (c), by Zend Technologies
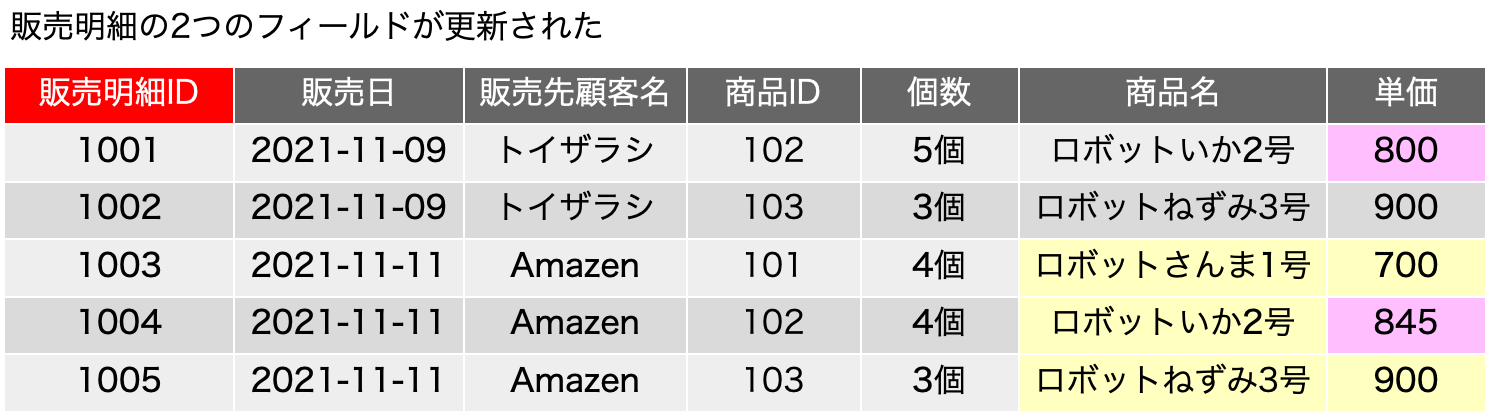
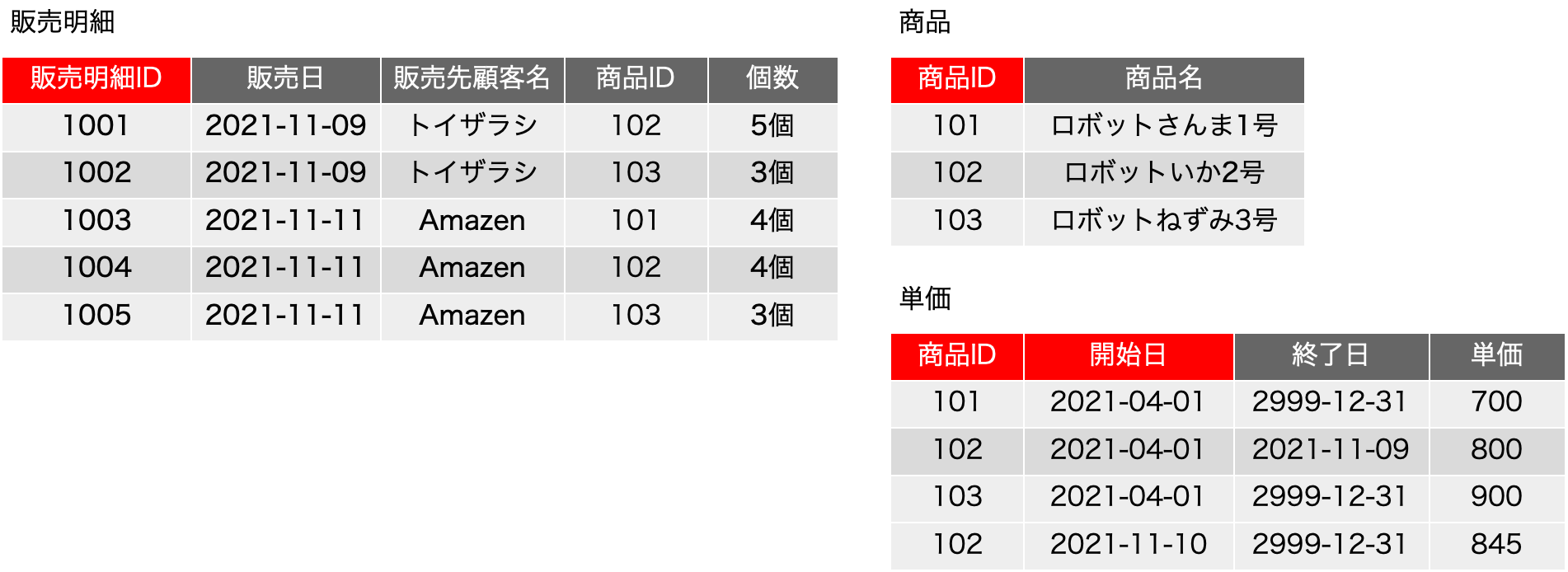
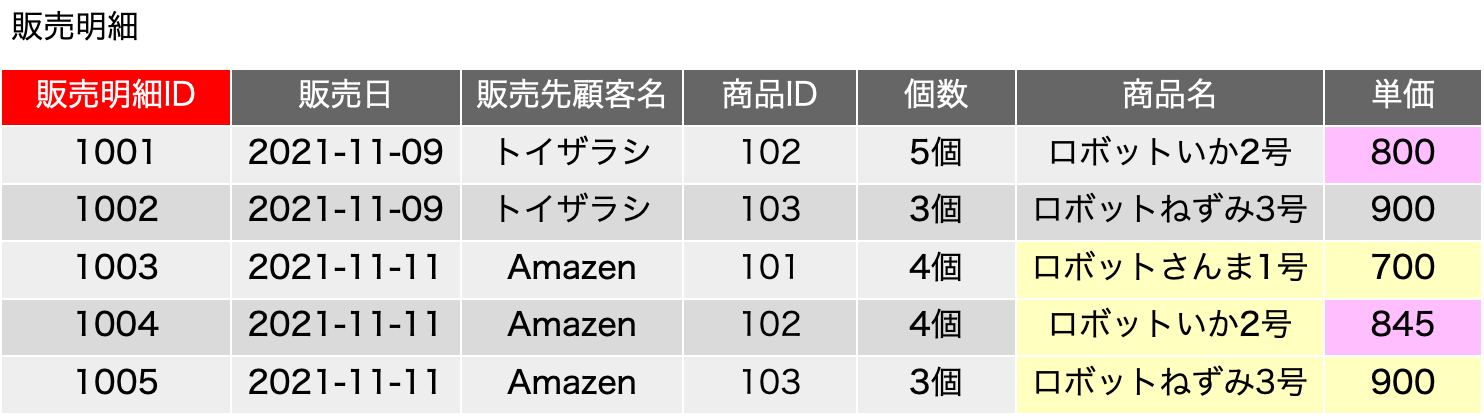
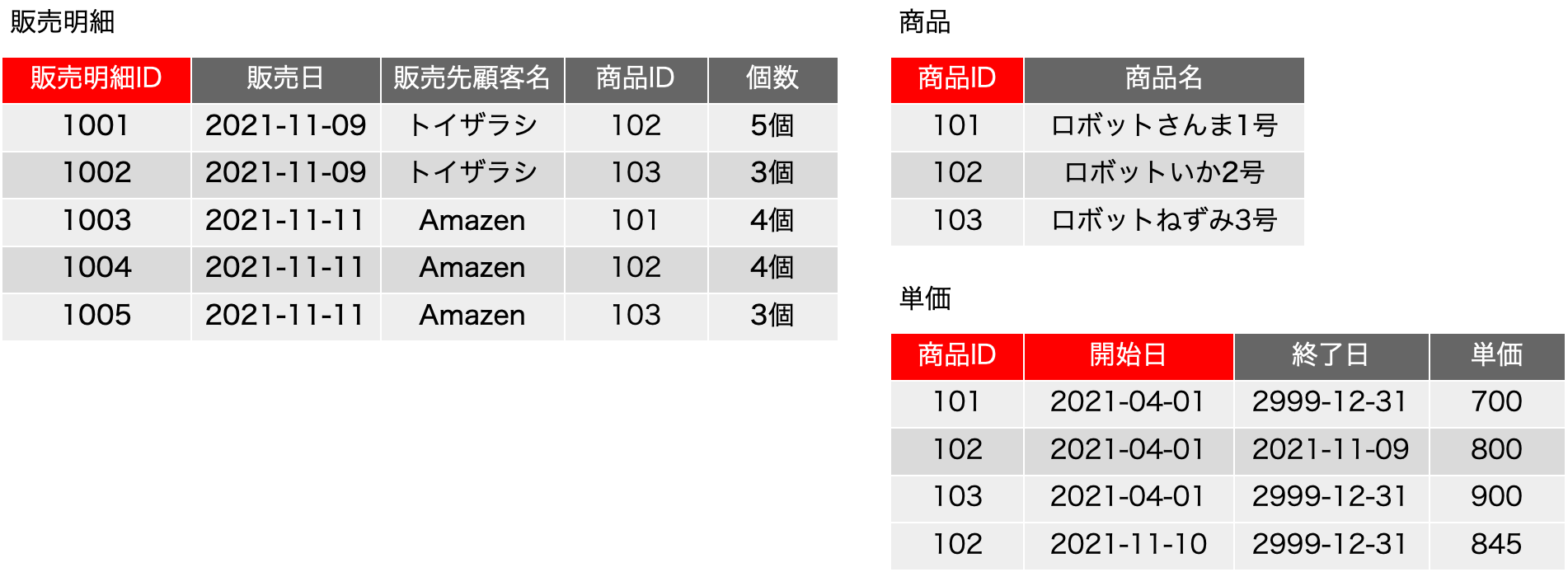
ただ、ここで、販売日をそのまま扱うのかという問題があります。日付をドメインに考えたとき、これも正規形の議論での会議室予約の問題として出てきましたが、無限大に取り得る値を取り、全部の値を書き並べることは現実的ではないようなことが起こり得ます。日付は年月日時分秒の複合オブジェクトなどと考えると非常に複雑だと思ってしまいますが、一方で、日付は整数と同じように、連続しつつ、ステップで変化するという特徴があります。整数の桁のように、すべて同じルールで桁が変わるわけではないし、閏年など面倒なルールもありますが、連続しつつ、ステップであるという点だけを見れば、整数と同じ判定ができます。そこで、こうした日が絡むものは、「期間」という概念で包括してしまうという手法が考えられます。実際、単価の変化を「正確に」追いたいとしたら、単価が変わった日と、その単価が終わった日を記録するのがまずは妥当と考えます。終わった日は次の単価の前の日という考え方もできるのですが、データベースはレコードをまたがった判断はあまり得意ではありません。ここでは、開始日と終了日があるという考え方を取り入れて考えれば、今までの商品IDの照合のような=演算子ではなく、開始日<=販売日 AND 終了日>=販売日 といった判定を行うことで、単価の表を別に用意して照合可能にすることができるのではないかと考えてみます。つまり、次のような表の分割ができるということに目を付けます。
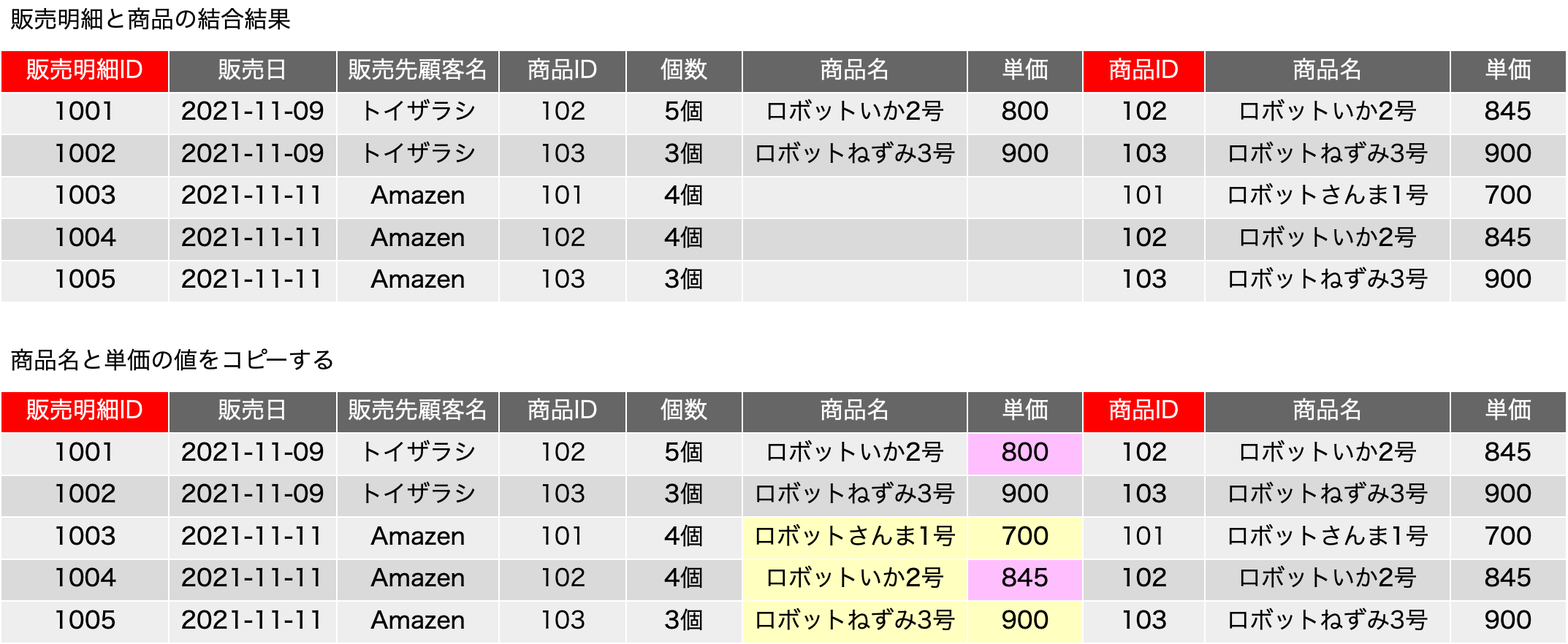
元の販売明細の表を作る手順について、商品は商品IDで照合するのは今まで通りです。ここで、単価は{(販売日), 商品ID}→{単価}という関数従属だったので、2つのフィールドに関わる照合が必要です。つまり、商品IDが一致するもの、かつ、「開始日<=販売日 AND 終了日>=販売日」という式がキーフィールドの照合に相当する検索処理になるわけです。具体的に見てみましょう。販売明細の1行目と4行目に商品IDが102のレコードがありますが、1行目は11/9です。なので、開始日がそれよりも後でかつ終了日がそれよりも前のものとしては、単価の表の2行目だけがあり、2行目のみにマッチします。1レコードへのマッチなので、単価は800円と決定できます。一方、販売明細の4行目も同じ商品IDですが、マッチするのは単価の4行目だけなので、単価は845円に決定できます。SQLで表の合成を記述すると、次のようになります。そのまま動くかどうかは微妙ですので、考え方の確認としてご覧ください。
SELECT 販売明細ID, 販売日, 販売先顧客名, 販売明細.商品ID, 個数, 商品名, 単価
FROM 販売明細
INNER JOIN 商品 ON 販売明細.商品ID = 商品.商品ID
INNER JOIN 単価 ON 販売明細.商品ID = 単価.商品ID
AND 開始日<=販売日 AND 終了日>=販売日