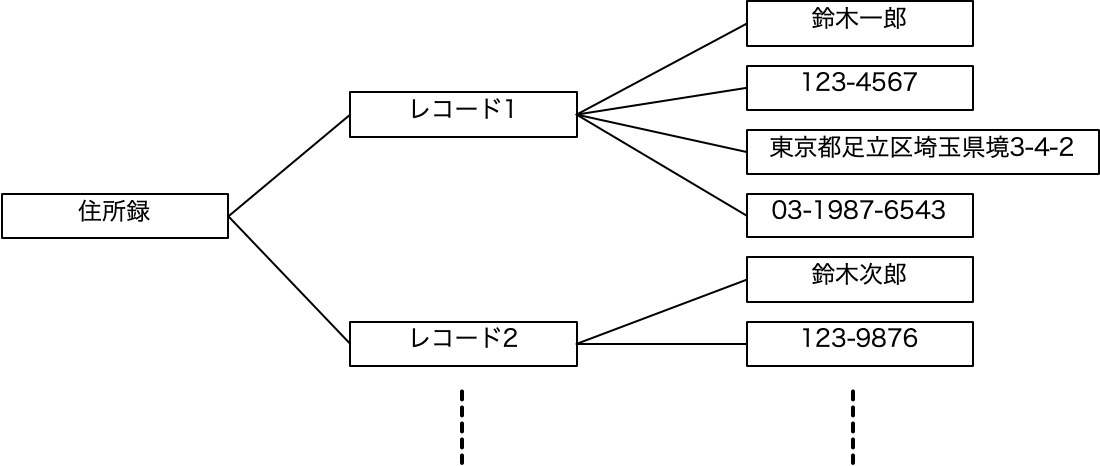
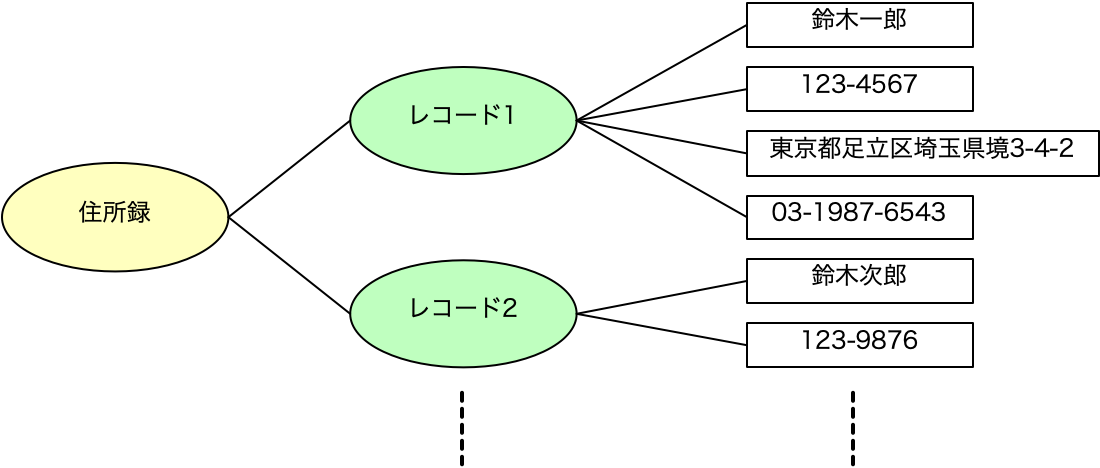
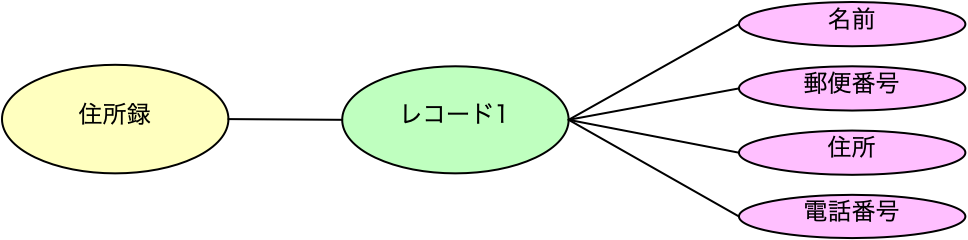
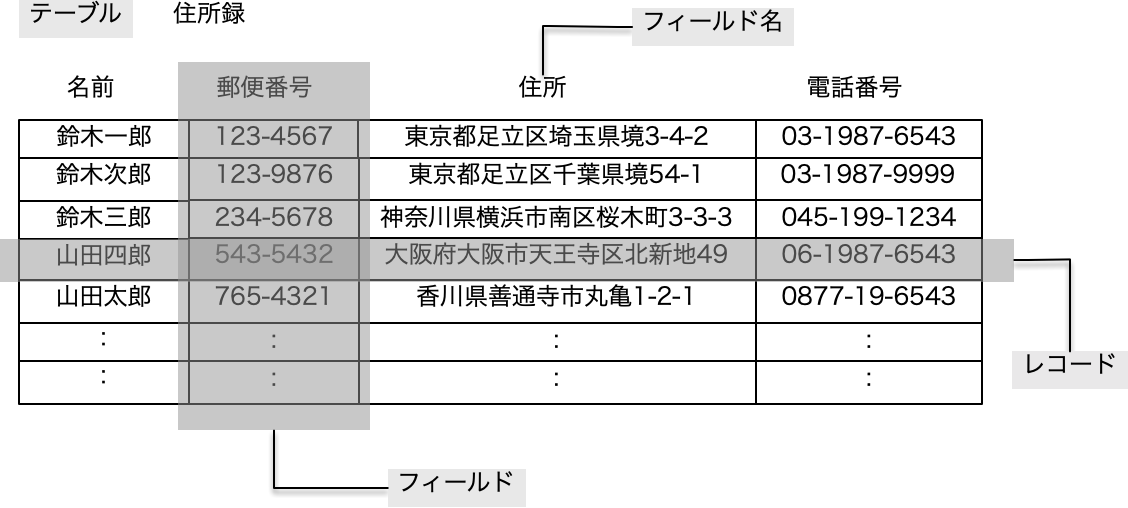
ここまでに、業務全体をみながら、同じ「商品」でも部署ごとに異なる対象として扱っていることから、記録したいデータは異なるとして、それらを表として表現しました。一方、その中でも共通の「商品」に対する情報を別の表でまとめて共有することも考えました。
この、別の表にしたもの、つまり、複数の表にしたものを1つの表として表現するということが、リレーショナルデータベースのわかりやすいメリットの1つです。なお、この1つにまとめた表は、場合によってはどこかに保存することもあるかもしれませんが、原則として一時的に利用するものであって、それを保存するデータとして利用はしません。あくまで、複数の表として保存し、必要な時にそこから元の表を一時的に得るというのが原則です。
しかし、表を分割したとしても、その2つの表の関連性はどのように確保するのでしょうか? ここで、本来はデータベースの難しい理論を勉強しなければならないのですが、1つの理解の仕方は、参照される側に「番号を降る」ということをやるのです。次の図は、「製造管理」の表に、もともと商品名があったのですが、その商品の名前は営業部門などと共有できそうなので、「商品」という表を分離しました。しかし、分離してしまったらただ消すだけです。製造管理の1行において、どの商品についての製造管理情報なのかを示すために、ここでは「商品ID」という番号を振ることにします。ここでは、「商品」側にも「商品ID」があります。商品IDは、商品が重複しない表の上で、適当な番号を頭から振っていったものです。当然ながら、商品の表の商品IDは重複がありません。言い換えれば、商品IDが決まれば、「どの商品なのか」ということが一意に決まるということです。こうすれば、製造管理の1行目は商品IDが102なので、商品の表より「ロボットいか2号」についての情報であるということがわかるのです。もちろん、ソフトウェアなのでこれをある意味機械的に行うのですが、ここでは設計に必要な概念を整理するために、まずは番号を振るということを考えます。ちなみに、番号を101から順番に振りましたが、別に1、2、3でも、10001からでも構いません。とにかく行ごとに異なる番号であればいいのです。一桁だと、個数っぽいので、わざと桁を多めにして、直感的に判断しやすいようにという意図です。

(「本セミナー」と書いてあるのは、もともとセミナー用に作った資料を流用しているからです。すみませんが無視してください。なお、いずれ、正規形についての情報は色々な形で紹介すると思います。)
ここで、製造管理は5行、商品は3行です。「ロボットいか2号」についての情報が製造管理には2つあり、つまり、2個の商品の製造をしたことがわかります。一方で、商品の表については、ここでは名前の共有だけを目指しているようなのですが、2個製造した「ロボットいか2号」は、どちらも同一の「ロボットいか2号」という商品名です。ということは、商品側では1つの存在で良いと言えます。
商品から逆に製造管理を見たとき、1つの商品「ロボットいか2号」についての情報が1行目と2行目の複数の行にあります。このような関係を「1対多」と呼ばれます。この製造管理の表はおそらく全体の表の一部なので、2個しか製造していないということはないでしょう。つまり、100個あるいは10000個と作っているような状況を想定します。具体的なデータでは何個という個数は求められますが、設計については、具体的な個数よりも「多」であって「1」や「0」といった決まった数値ではないということが重要になります。もちろん、0、1、2・・・と増えていくということで、1である瞬間はあるのかもしれませんが、「関係そのものについて、1なのか多なのか」ということを考えます。となると、商品と製造管理は、1対多であると言えるわけです。
1対多の「1」は、1行しかないということではありません。商品の1つから多数の製造管理が存在し得るということです。そして、逆に見た時には、1つの製造管理から、1つの商品が特定できるということです。このような関係を1対多と呼んでいます。逆に見た時は1対1じゃないかと思うかもしれませんが、一方が1対多なら、関係は1対多と判断します。ちなみに、「多対1」も基本的には同一概念です。説明上の順番で、「商品と製品管理は1対多」、「製品管理と商品は多対1」のような表現がされるだけで、どっちが先に書いてあるのかくらいの違いしかありません。

現実のデータベース設計ではこの「1対多」の関係を、確実に抽出しなければなりません。これに対して、前回説明した「1対1」の関係もあります。1対1の関係は、多くの場合はフィールド、つまり表の列にまとめることができます。一方、1対多の関係は、別々の表として表現するというのが確実な方法になります。本来1対多であるはずの関係を間違えて1対1であるとみなしてしまったら、単純な意味では2つ以上のデータの存在をシステム上では適切に表現できないということになります。すなわち、1対多の関係の把握が、データベース設計での肝になるということになります。
なお、以前にもよく雑誌記事などを書いたときに、リレーショナルデータベースの説明を依頼されたことがあります。そこで必ず言われるのが「番号が分かりにくい。番号が出てきたらもわからない」という編集者からの指摘です。まあ、そうですね。なんで101なのとか(前に説明した通りこれは適当な番号です)、データベースは直感的と言われるのだからもっと簡単なのじゃないかとか言われるのですが、この「番号振ります」は、単なる手続きなので、難しいことではありません。普段から番号を振って、順序を考える基準にするなどしていることと同じことなのです。ただ、普段番号を振らない、あるいは元々番号を使っていない対象に単に振っているだけです。番号振ること自体をディープに理解してほしいわけではなく、ここである意味、表に分割した結果を単純化するために番号を振るという状況を頭の中で作ってほしいというだけで、考えすぎる必要はないと思います。繰り返しますが、番号を振るのは単なる手続きです。
一方、この「ID番号」は、リレーショナルデータベースの理論の上からは必須の定義ではありません。リレーショナルデータベースは、その表の1行を特定できるデータが何かということが重視されるので、それは商品名でもいいですし、社内で使っている商品番号でもいいのです。むしろ、論理的にはその方が現実に近いということもあります。こうした表の1行を特定可能なデータを「キー」などと呼ばれます。ただ、これまでの色々な設計の経験からして、全ての表に連番を振っておくのがある意味確実だと考えます。まず、データベースは連番を振ることを自動的にできるからです。場合によってはその連番を使わないこともありますが、それによって処理が遅くなったり、ディスク容量を圧迫するようなことはないのが一般的なので、「全ての表にキーが絶対に存在する」ことを優先して、数値連番フィールドを設定します。商品名がキーでもいいじゃないかと思われるかもしれませんが、文字列は比較処理がある意味安定していません。整数やUUIDのような一定のコードは比較処理が安定しています。文字列の場合、もちろんルールを定めれば、確実に比較はできますが、Unicodeのさまざまルールや、同じ文字でもコードが違うものが大量にあるなど、文字列比較は間違える要因が多いのです。であれば、整数連番の確実性を取りたいと考えるわけです。付けられた連番がデータと無関係にランダムになるのを嫌う場合もありますが、このキーになるデータは「利用者に見せない」のが基本です。仮に見せたとしても絶対に編集可能にしてはいけません。最近は多くの開発にフレームワークを使うこともあるので、自動的に数値連番をつけることもありますし、単一の数値での処理が組み込まれていることもあるので、結果的に数値連番フィールドを使うことになるのではないでしょうか。
次回は、この分離した表から元の表が求められるということを、細かい流れになりますが、説明しましょう。