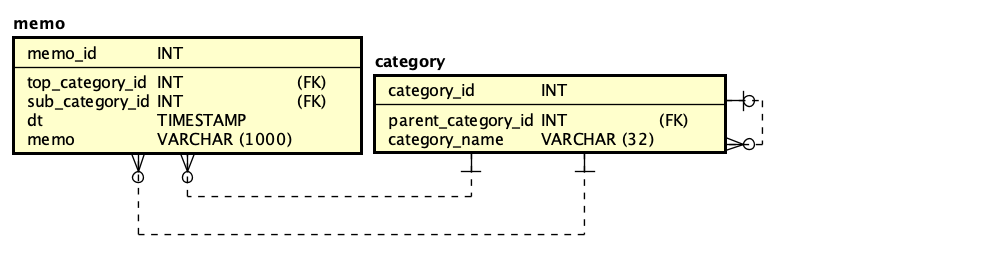
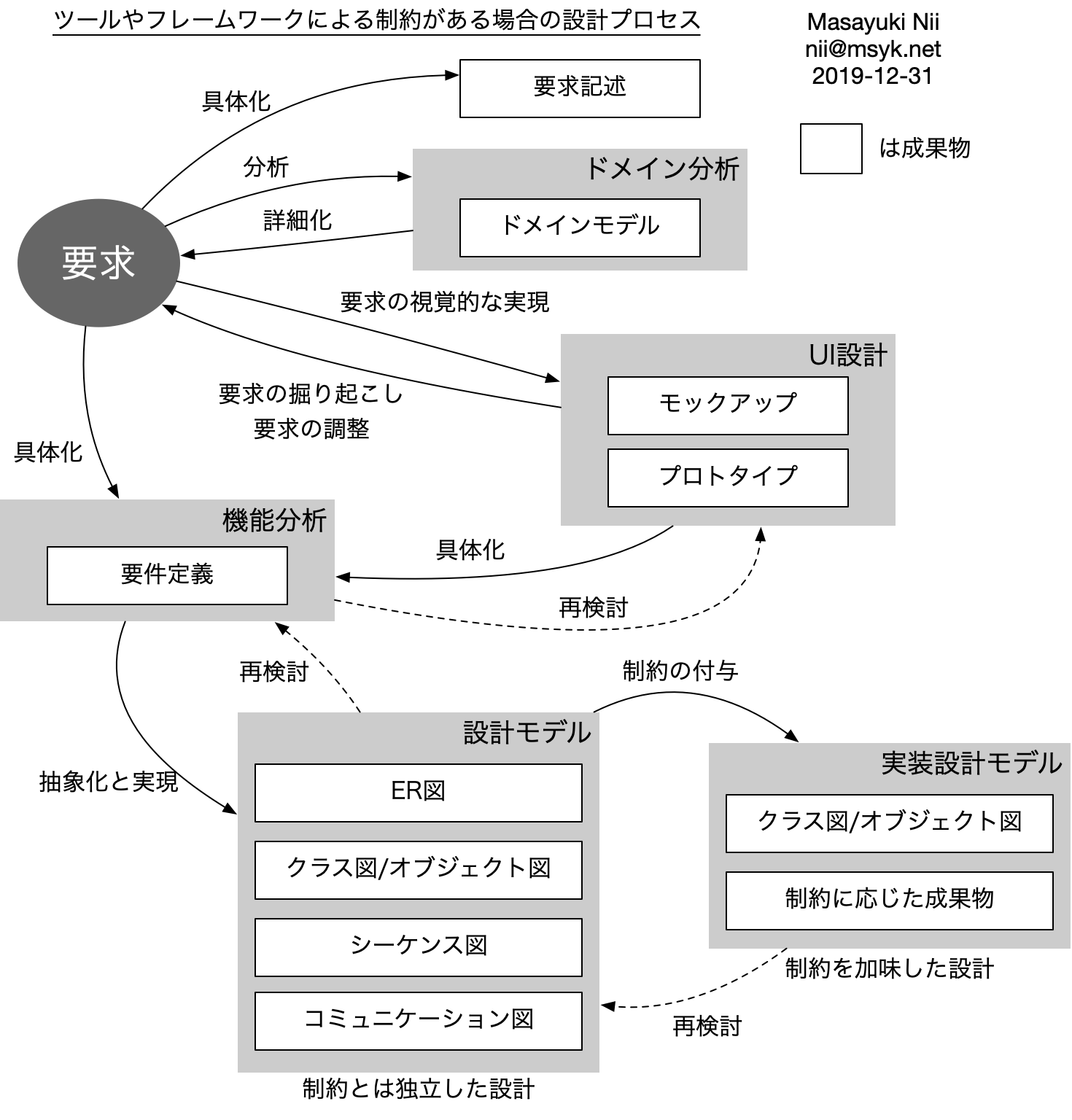
少し間が空きましたが、開発プロセスの中で、まずはUIのモックアップを中心に要求を固めて、そこから設計に入る場合に、まず、データベースのスキーマから入る方法があるというのを説明しました。レイヤー構造で構築する場合、データは低い位置にあるので先に決めるという点に意義はないとは思いますが、一方で、あらゆる状況を加味したデータベース設計ができるのかという問題もあります。ですが、ここでは先に決めるという流れでプロセスを追っています。
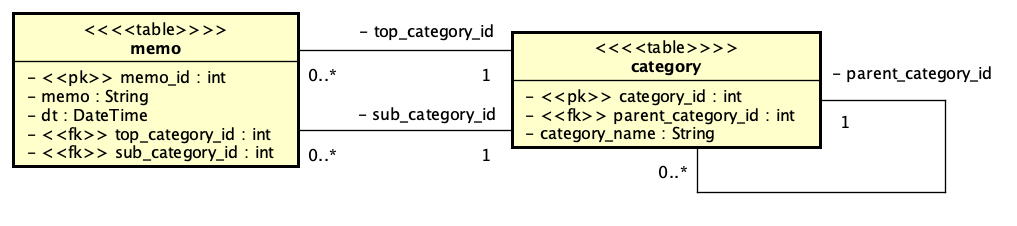
データベース設計ができれば、そこに対してどんな仕組みをかぶせることで動くアプリケーションができるのかということを考えます。UIの設計から、まずは目に見える機能を取り出し、それをどのように構成するのが良いのかを考えます。ここで、「機能の一覧」を書き出すことが1つの方針としてはあり得るのですが、その機能をある程度分類しないと、構成が定まりません。そこで、メモのページ全体をMemoPoageとして、それらが、メモ一覧を示すMemoListと、左側のカテゴリ一覧を示すPickingUpの2つのクラスのコンポジションであるという見方をします。まず、目に見える範囲を狭めて、開発単位となるブロックを見つけるということです。ここで、一覧だと、1行のコンポーネントが複数あるようなことを示さないといけないのかと言えば、これは経験則的には不要だと考えます。ここで「リスト」と言ってしまうことで自明だからです。言い換えれば、1行の要素が繰り返されるということ自体は、そのクラスが持っているという見方をして、過剰に細かくは書かない方が設計は素直で読みやすくなるということです。データベースのテーブルを記述する場合に、クラス図では1つのボックスしか書かないのと同じ理由です。しかしながら、何らかの定義はどこかにあるわけですので、その点も書きたい場合はメモを追加するか、あるいはクラス名の意味をどこかに記載すればいいでしょう。なお、このようなクラス図からオブジェクトを図を想像できるかどうかということは、ダイアグラムの理解には重要なポイントであることは間違いないのですが、設計上どうすればいいかを詳細に決めると多分面倒なだけになりますし、大雑把にするとチーム内でコミュニケーションが中途半端になる可能性があります。機会があればこれは検討したいテーマです。こうして作成したのが以下のクラス図です。
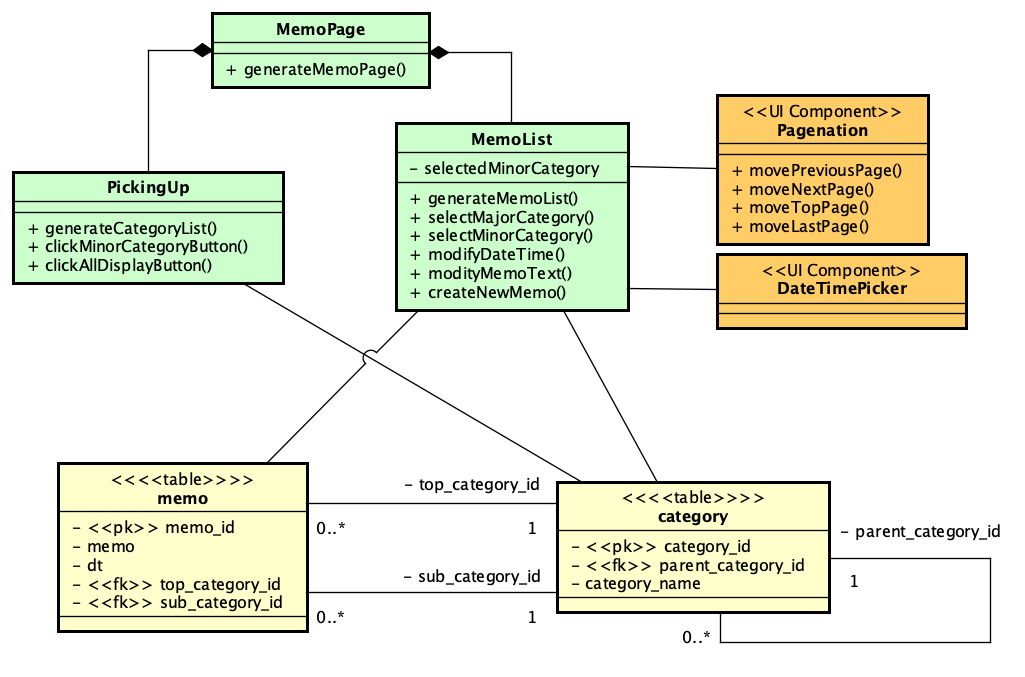
緑色の3つのボックスがUIのブロックを1つのクラスとして記述したものです。中身は、ボタンや編集など、ほぼ、ページ上でのイベントに対応するもの、そしてそのリスト自体を生成するためのものが記載されているだけなので、細かくは説明しません。それぞれ、どのテーブルを利用するかで2つのテーブルに線を引きました。また、MemoListは、ページネーションと日付時刻のピッカーを、別に用意されているUIのコンポーネントを使うことにします。ここでは、MemoList上にある要素とは別のもの(ここでのページネーション)や、要素の動作を補助する必要があるものを(ここでの日付時刻ピッカー)抽出します。ただ、このUI Componentsは、実装先によって実態は異なると思われます。ここではまだ実装を加味しないということで進めてきましたが、実際にはこのように実装先の状況が徐々に現れることになります。プロセス的にはまず設計をして、実装に関わることを検討しようということを書いていますが、線引きは明確にはできないと思います。ここで重要なことは要素として抽出しながらも、一定の範囲で実装を意識したという点をメモにするか、きちんと意識しておくことです。
ここまでの設計の図を見る限りは、明白にレイヤー構造です。このような簡単なアプリケーションなら、もう実装は簡単にできると言っても良いでしょう。手慣れた方ならここまで図にしなくても、頭の中で設計ができてしまっており、自身の知識を持ってすればすぐに実装の作業ができるはずです。こういう状態を「スキルがある」ということになるかと思います。そのような状態の効率良さは当然ながらあるわけで、その結果「設計は不要」という考えにもつながるでしょう。設計不要論については今回は扱わないつもりですが、設計の行為を体系的に記述するため、ここで終わらずにさらに設計の検討を進めるのが一連の記事の目的です。よって、まだ続きます。次は、実装環境の制約を加味した設計を作っていきます。