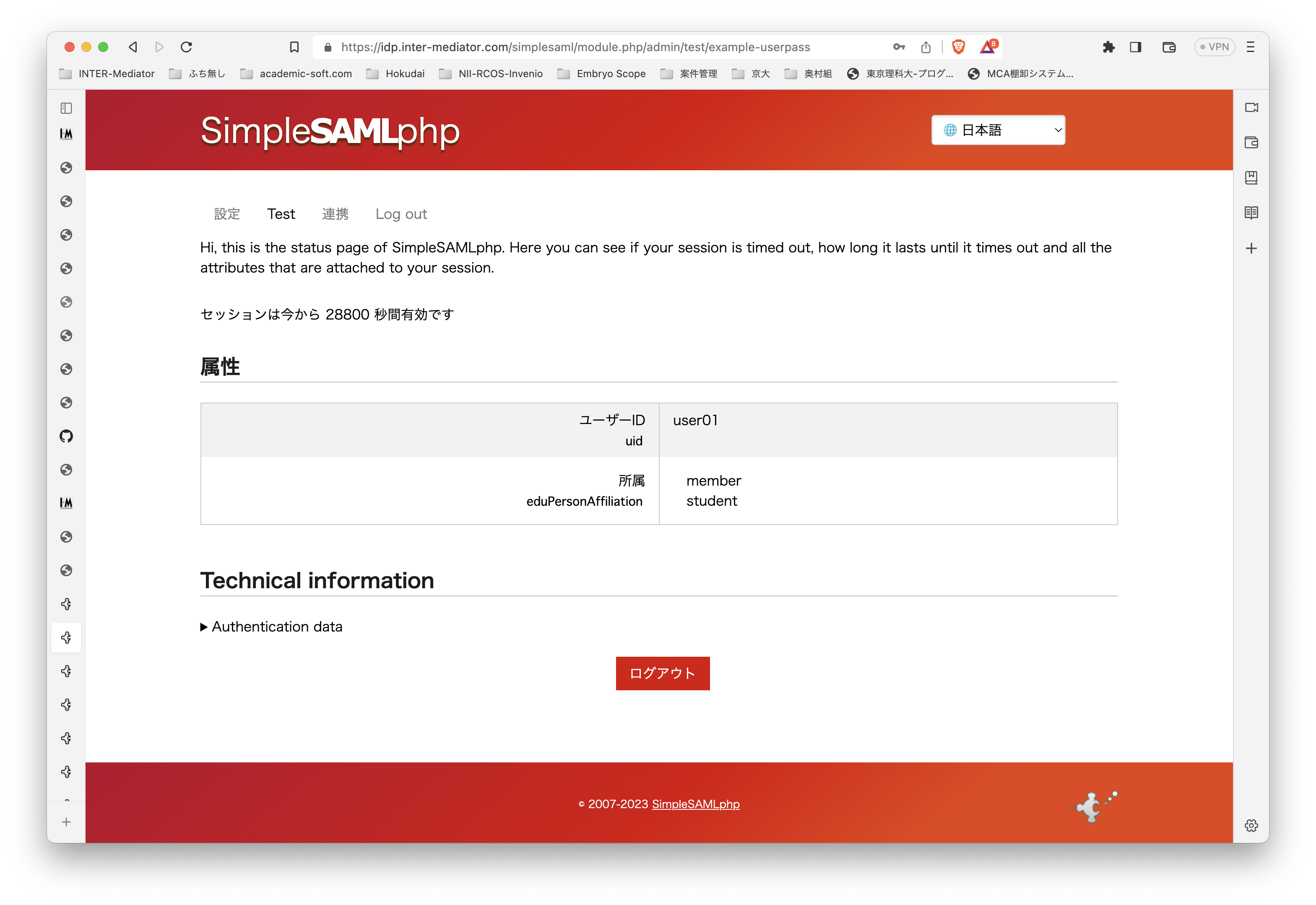
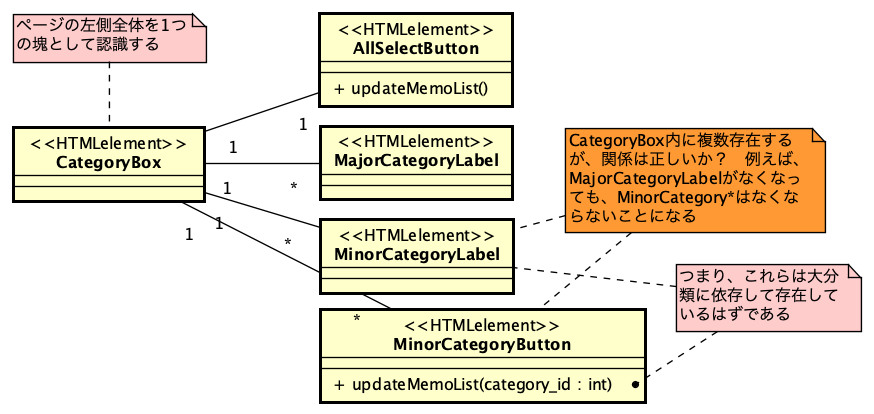
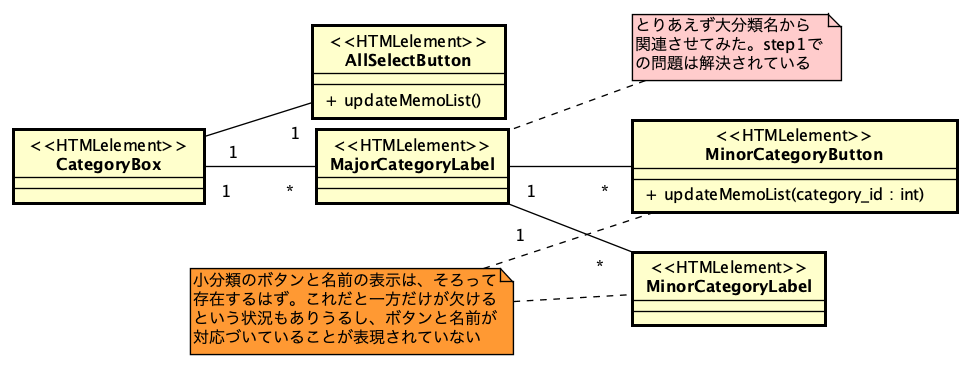
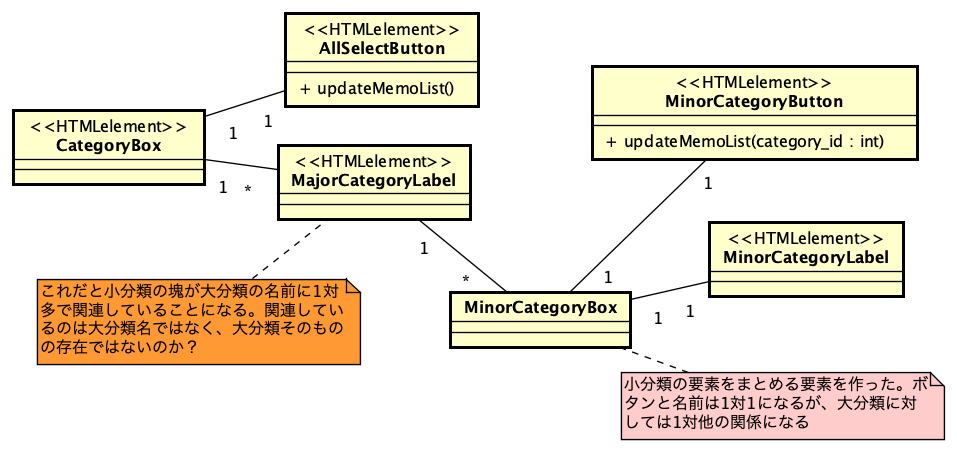
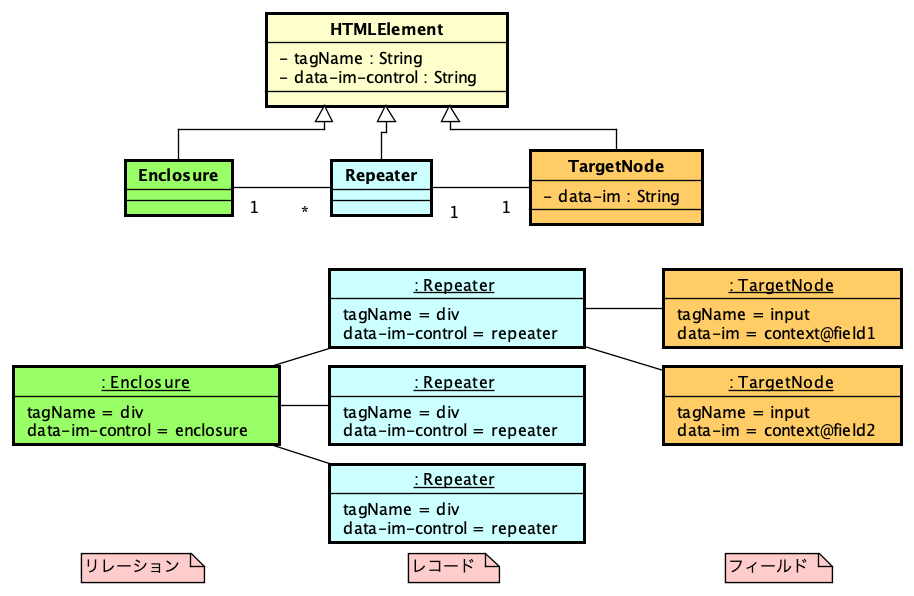
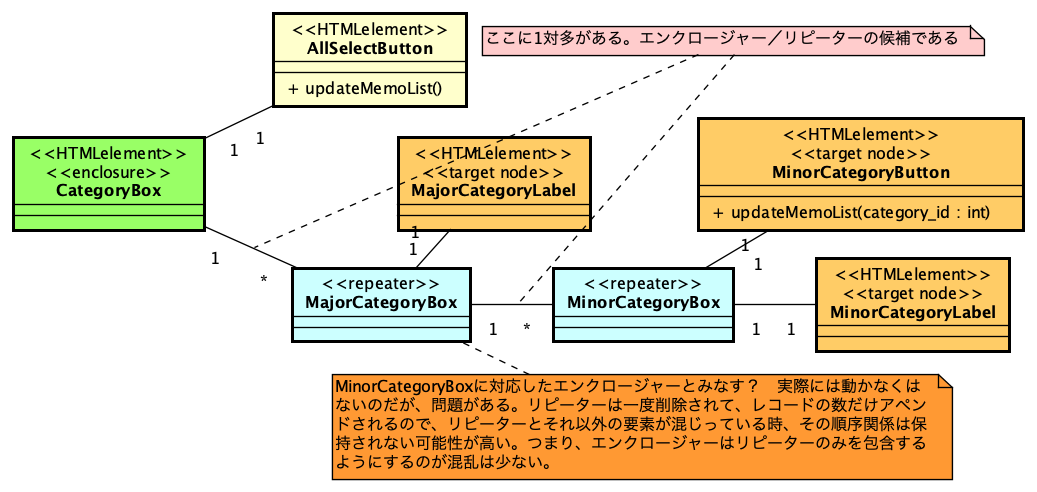
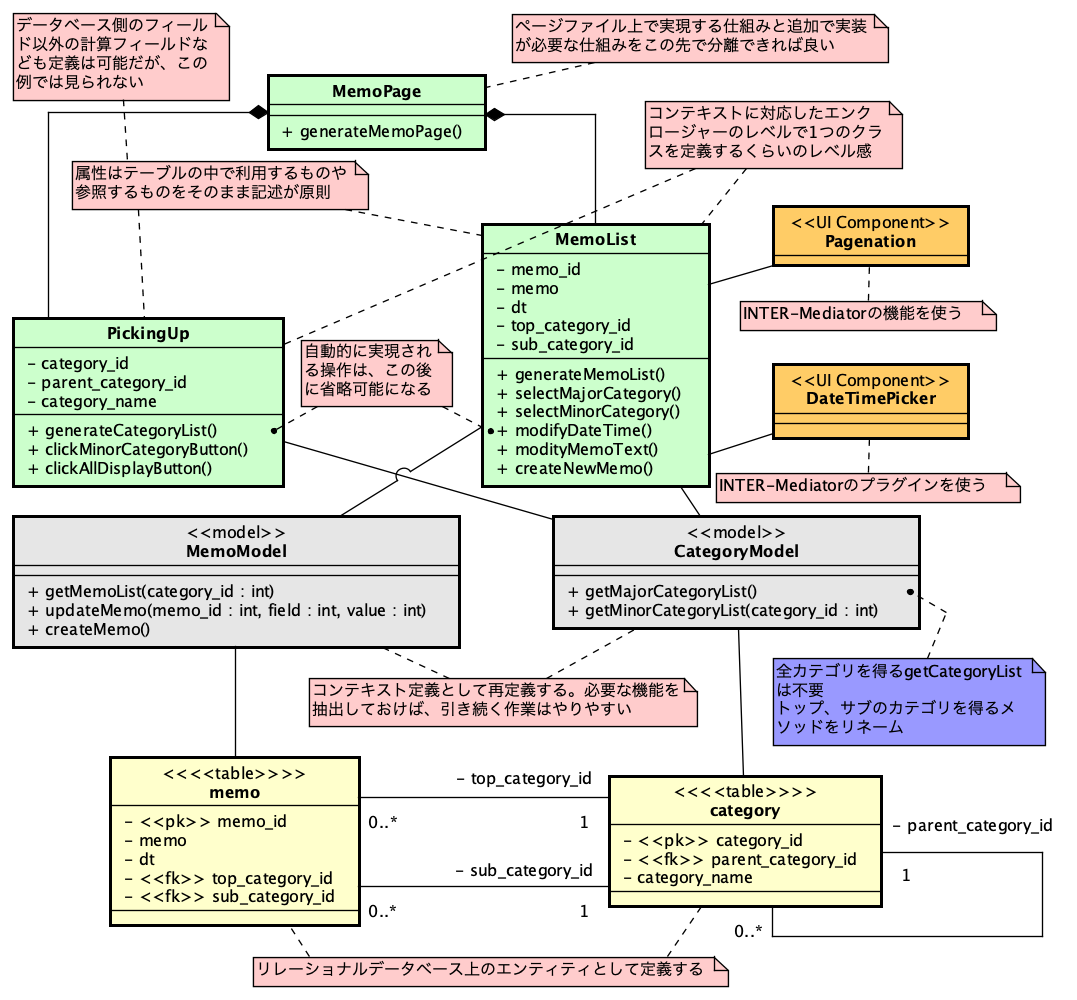
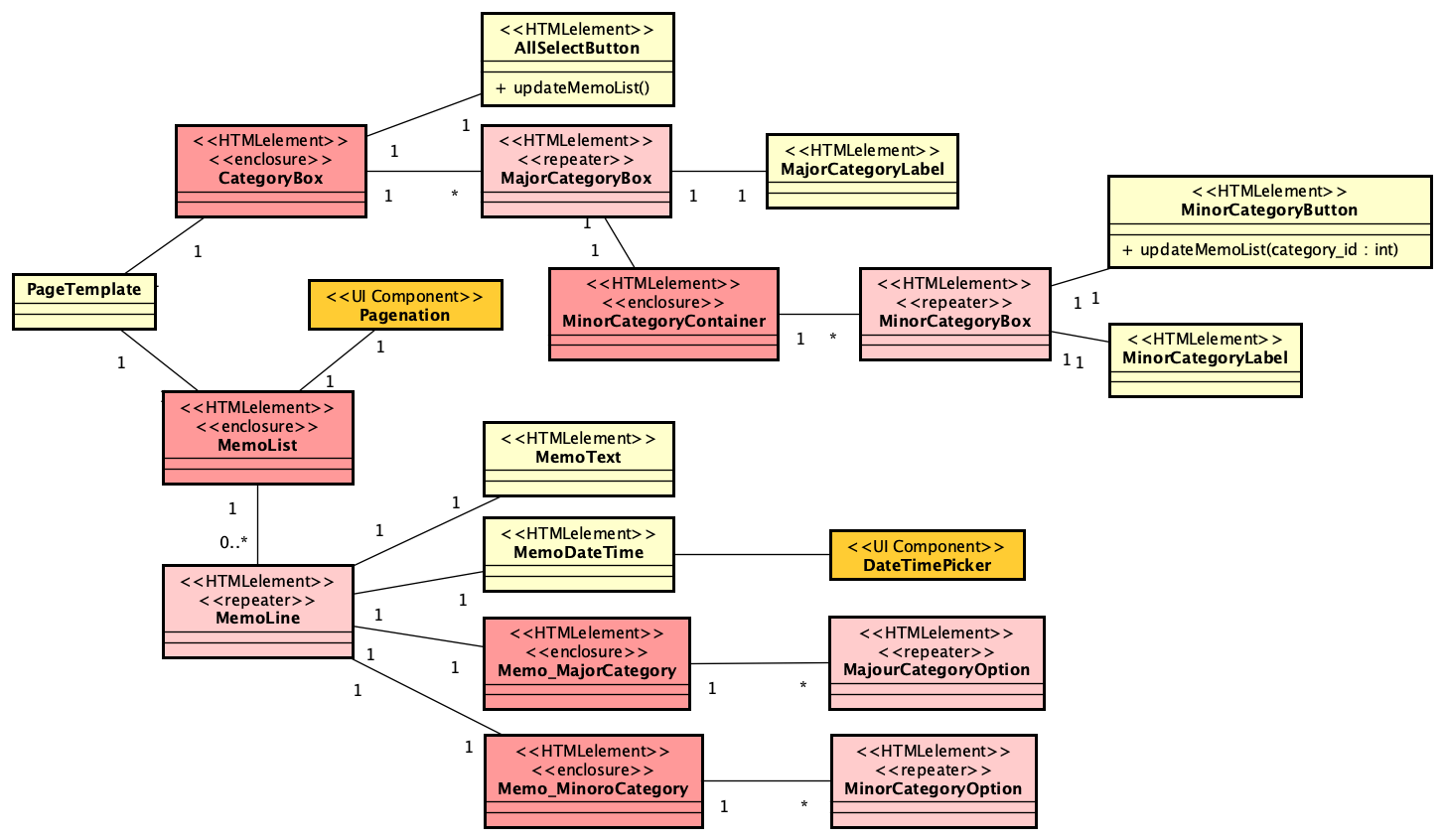
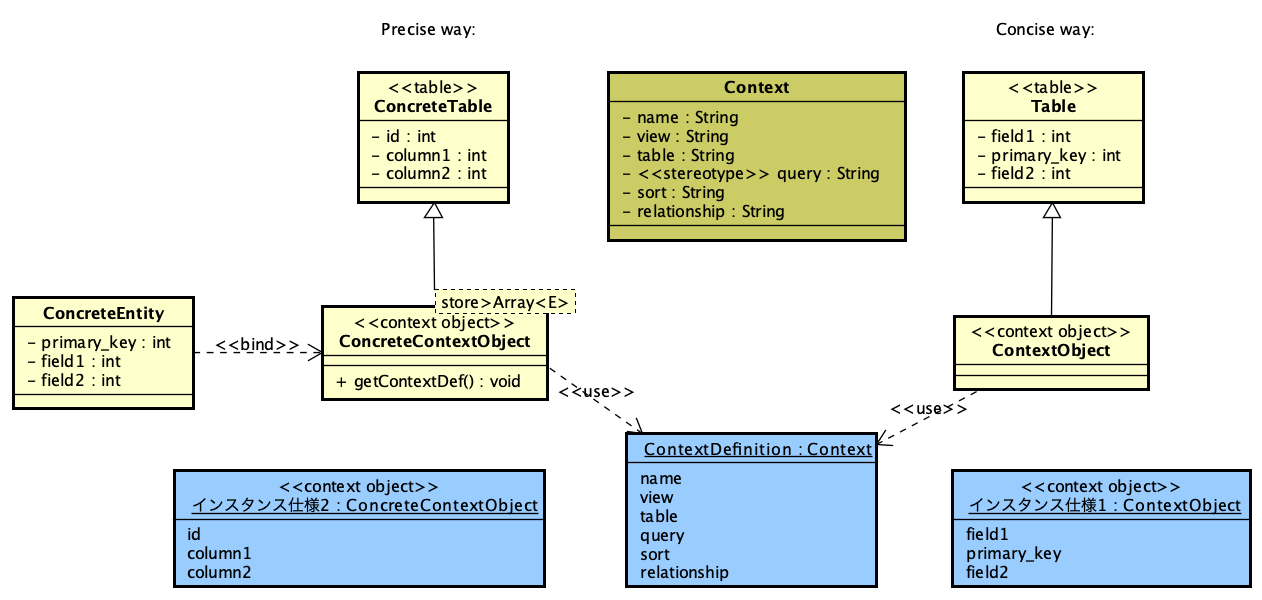
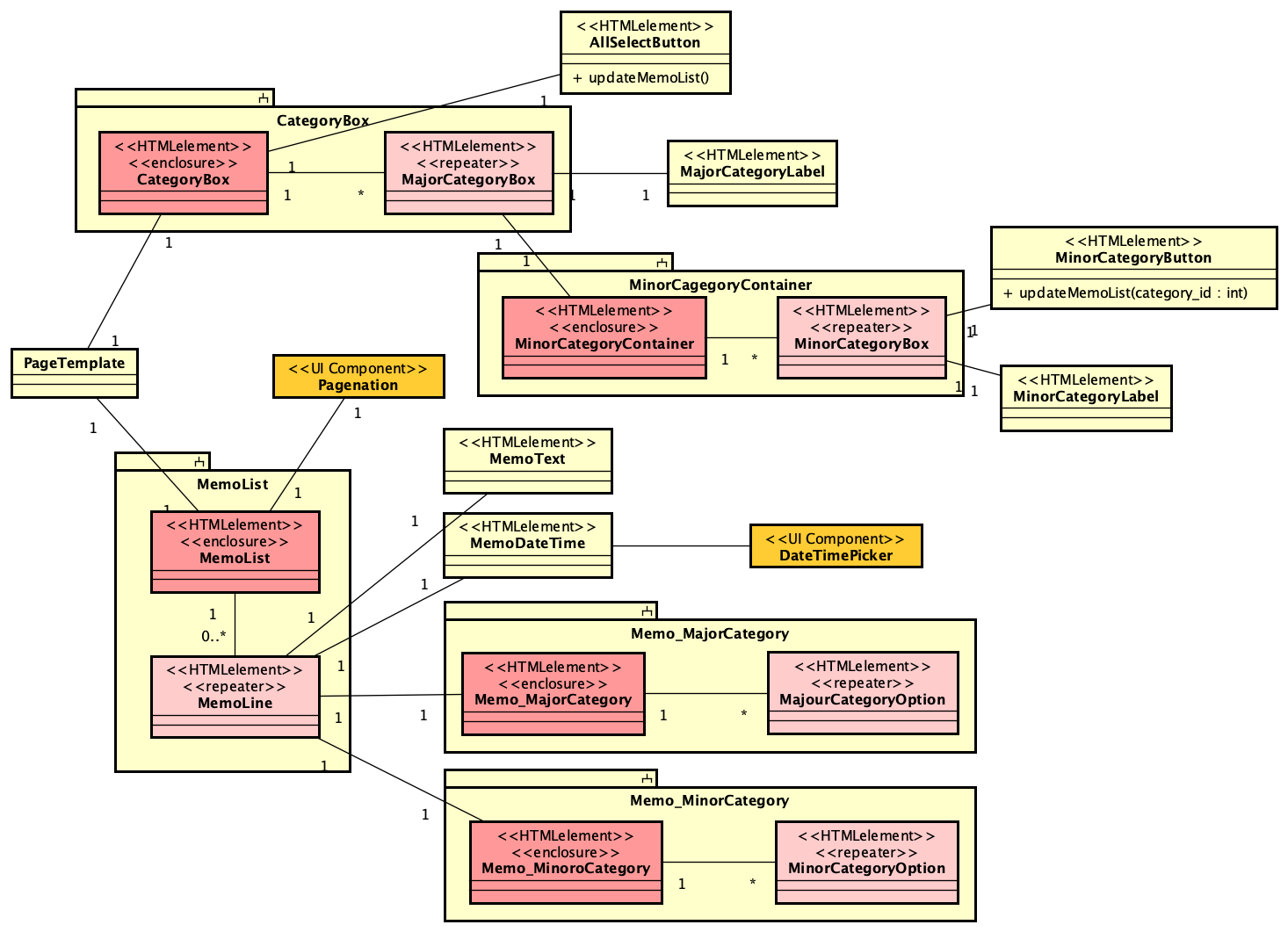
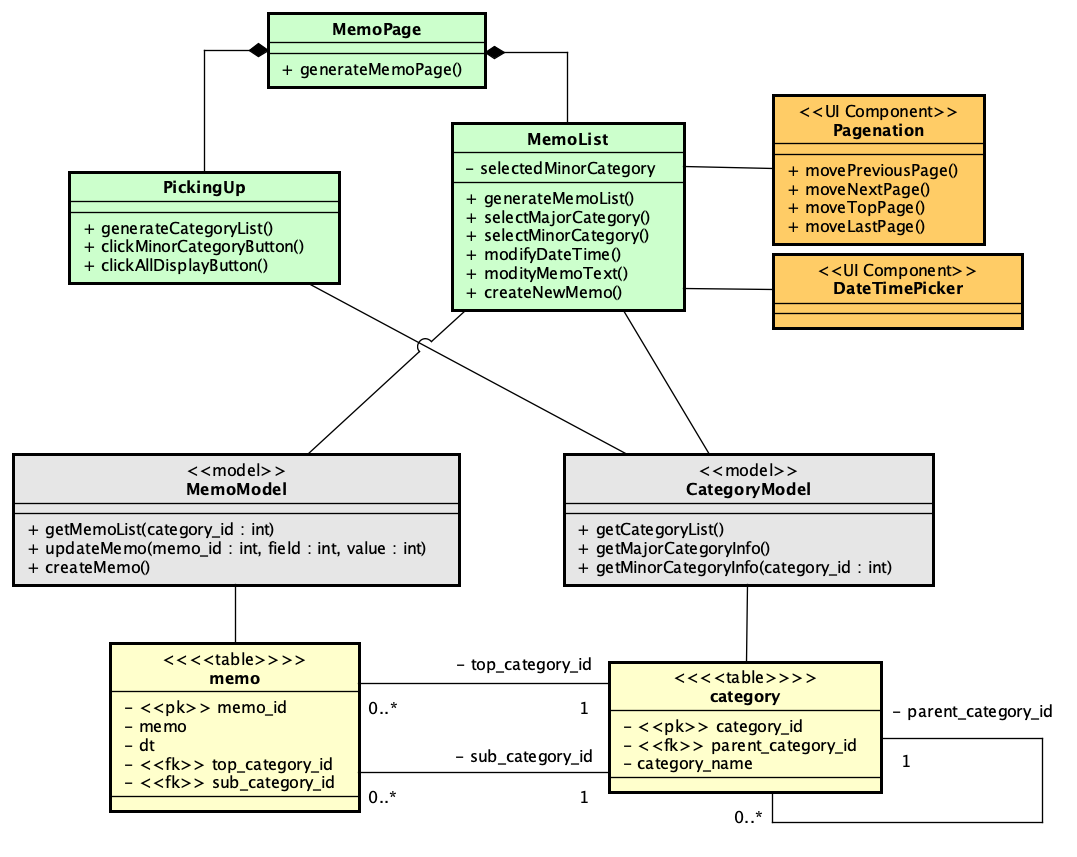
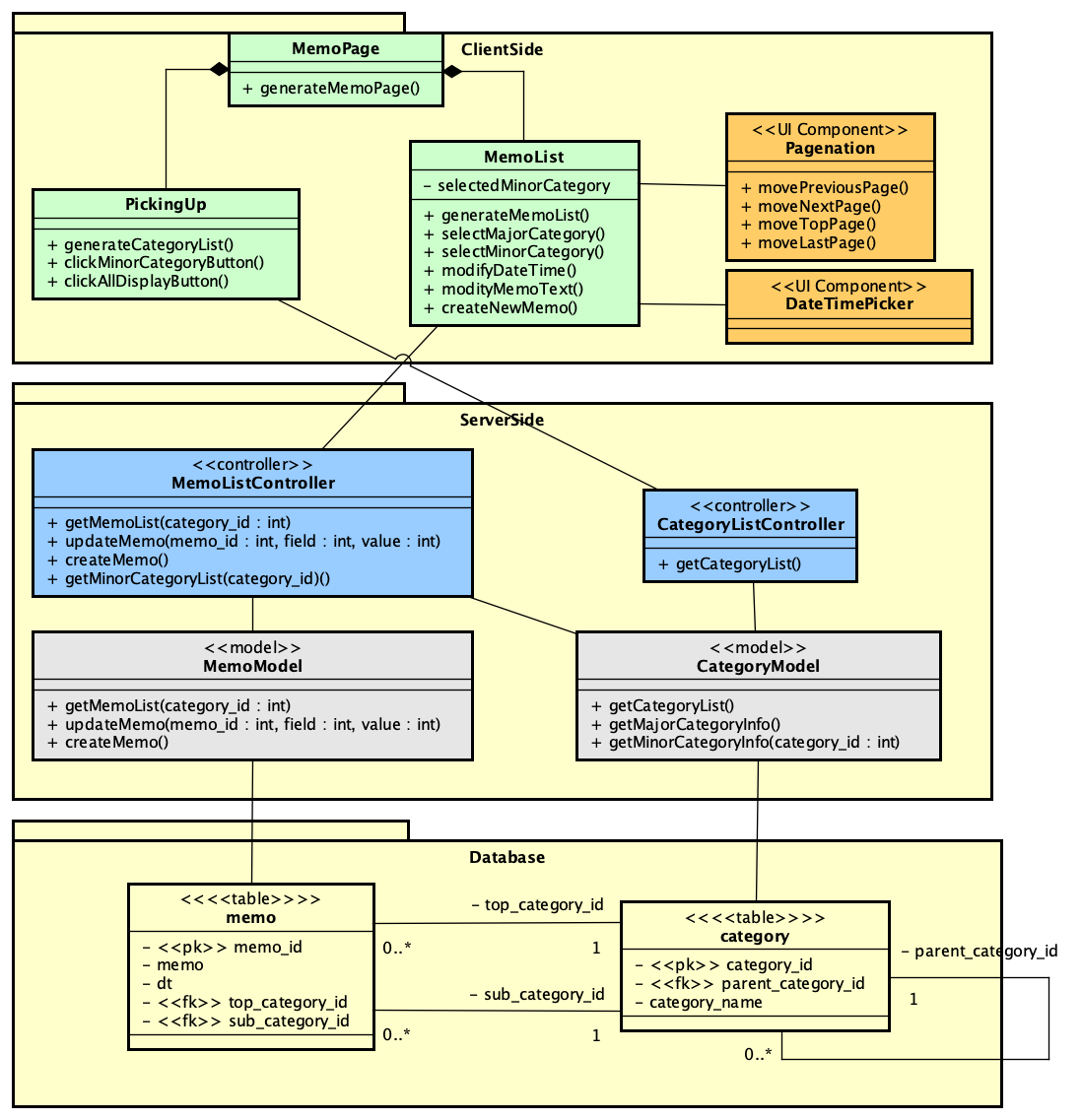
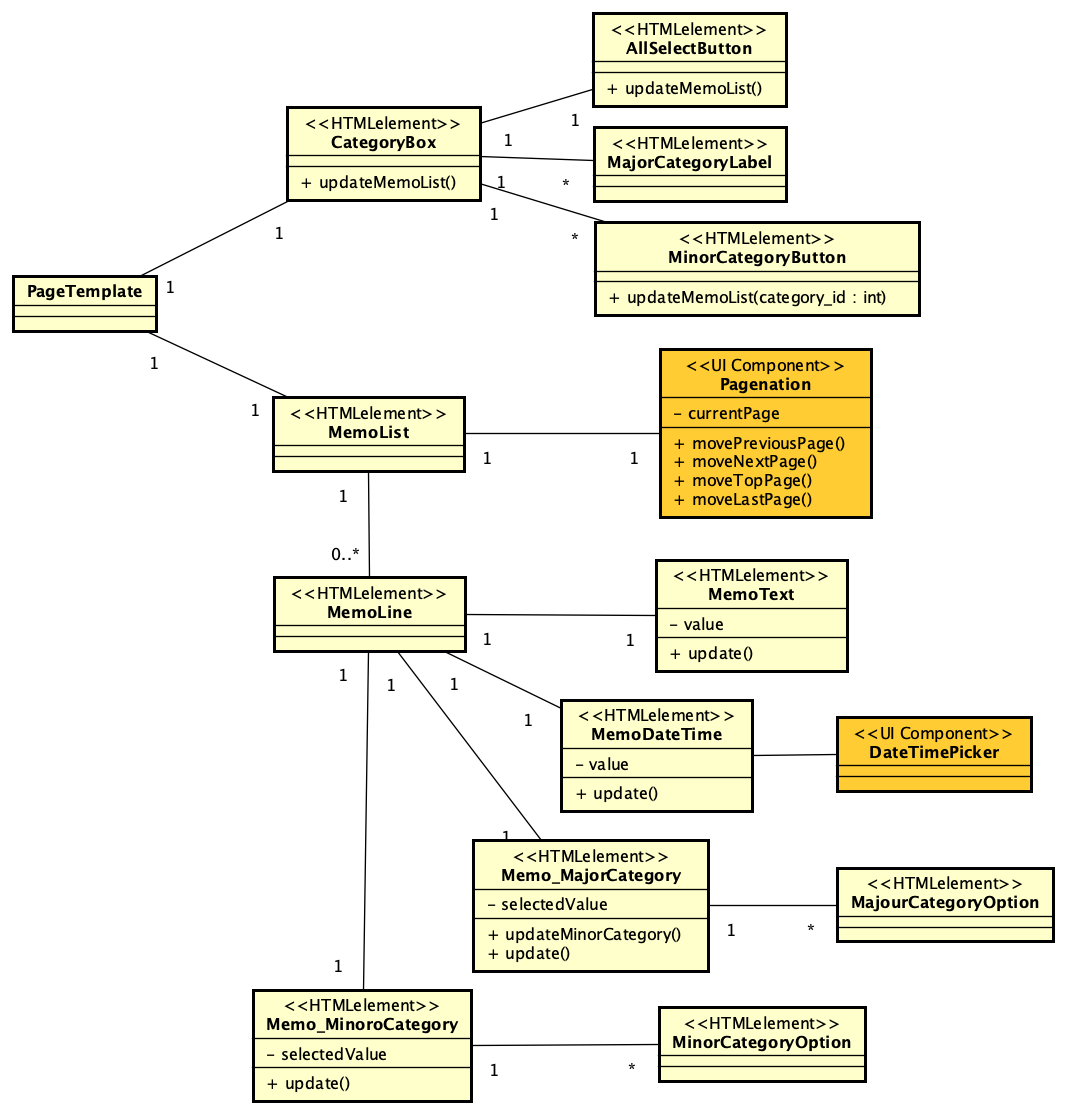
PHPでのSAML認証ライブラリであるsimplesamlphpは、PHPでSAML認証を行う場合にはほぼ一択となる選択肢です。これを利用してIdPを構築する方法は、https://blog.msyk.net/?p=1566 で紹介しました。本項目は、別掲の記事で紹介したIdPが存在する状態で、Google OAuth2、すなわちGoogleのアカウントでSAML認証を行えるようになるまでを紹介します。
とりあえずセットアップ方法とテスト方法は残しておかないといけないと思いつつ、まずは記事を書いたのです。INTER-MediatorでのGoogleアカウントでの認証は成功してはいませんでした。そして1日経過し、ふと疑問に思った事があります。simplesamlphpの追加モジュールとしてcirrusidentity/simplesamlphp-module-authoauth2を使うことにしています。このモジュールは、OAuth2の汎用モジュールなので、Google向けということではありません。さて、このモジュールは、IdPに必要なのか、SPに必要なのか、どちらなのでしょうか? このことは、ライブラリのインストールのページにも書いていません。当たり前のことなのかな?
以下の方法で、IdPにまずはインストールして設定を追加して、リダイレクトURLはIdP側にしたのですが、認証されている状態になりませんでした。そこで、全く同じようにSP側にもモジュールを追加し、リダイレクトURLをSP側にしましたが、なんと、全く同じ結果になりました。どちらでもいいのかもしれません。どちらでやっても同じ結果になったので、どっちが正しいのかという結論はとりあえずは出ていません。しかし、OAuth2の認証サーバがすでにあるという前提を考えれば、SPだけを用意してそれを利用する方が明らかに作業は少なくて済みます。ということは、SP側にモジュールを追加して運用するのが正しいような気がします。IdPに登録したユーザで認証する結果をみていると、一旦IdPに行ってログインパネルを出して、そこから、SP内部へリダイレクトして認証結果が伝わってくるように思えるので、やはりそのこともあって、SPへモジュールを追加するのが正しいように思います。
Googleのプロジェクトから認証情報を得る
SimpleSAMLphpの設定の前に、GoogleからクライアントIDとシークレットを取得します。その方法はあちらこちらのサイトで記載されていますので、例えば、Shinonome Tech BlogのOAuth 2.0 を使用してGoogle API にアクセスする方法 に記載された「1.Google API ConsoleでOAuth2.0の認証情報を取得」の作業を行なってクライアントIDとシークレットを取得します。以下、それぞれ、MYCLIENTID、MYCLIENTSECRETと記述します。つまり、これらのキーワードが登場したら、Google Developer Consoleで取得した実際の値に置き換えて設定等を行なってください。なお、「承認済みのリダイレクトURI」には、以下のURLを指定します。module.php以下のパスは常に同じですが、それ以前は実際にSPのサイトをどのようにセットアップしたかに依存します。
https://demo.inter-mediator.com/simplesaml/module.php/authoauth2/linkback.phpなお、実際のSPは「アプリケーション内のsimplesamlphp」でもあるので、エイリアスを使わないパスだとこのようになります。いずれにしても、Google側への登録と、後で説明する認証画面を出すためのURLの両方に、同一のリダイレクトURLを指定する必要があります。
https://demo.inter-mediator.com/saml-trial/lib/src/INTER-Mediator/vendor/simplesamlphp/simplesamlphp/public/module.php/authoauth2/linkback.phpSPにモジュールを追加する
SPで使用するモジュールは、https://github.com/cirrusidentity/simplesamlphp-module-authoauth2.git です。simplesamlphp自体にはGoogle OAuth2に対応した処理を実行できる素材はないので、外部から追加します。composer.jsonに組み込むか、あるいは次ようなコマンドで追加でインストールを行います。
composer require cirrusidentity/simplesamlphp-module-authoauth2続いて、SP側のsimplesamlphpのconfig/config.phpファイルを修正します。まず、この先で、SAML認証結果を利用するアプリケーションのドメインを追加します。既定値では[]になっていますが、OAuth2のモジュールはこの設定を見ているようです。
'trusted.url.domains' => ['demo.inter-mediator.com'],そして、OAuth2モジュールを利用可能にします。IdPとしてセットアップするときに値を変更した配列に、1行加えます。
'module.enable' => [
'exampleauth' => true,
'core' => true,
'admin' => true,
'saml' => true,
'authoauth2' => true,
],次に、config/authsources.phpに次の指定を加えます。’default-sp’などと同じ階層にキーとして’google’を指定し、値として配列を指定します。MYCLIENTID、MYCLIENTSECRETは実際に取得した値にもちろん置き換えて指定します。
'google' => [
'authoauth2:OAuth2',
'template' => 'GoogleOIDC',
'clientId' => 'MYCLIENTID',
'clientSecret' => 'MYCLIENTSECRET'
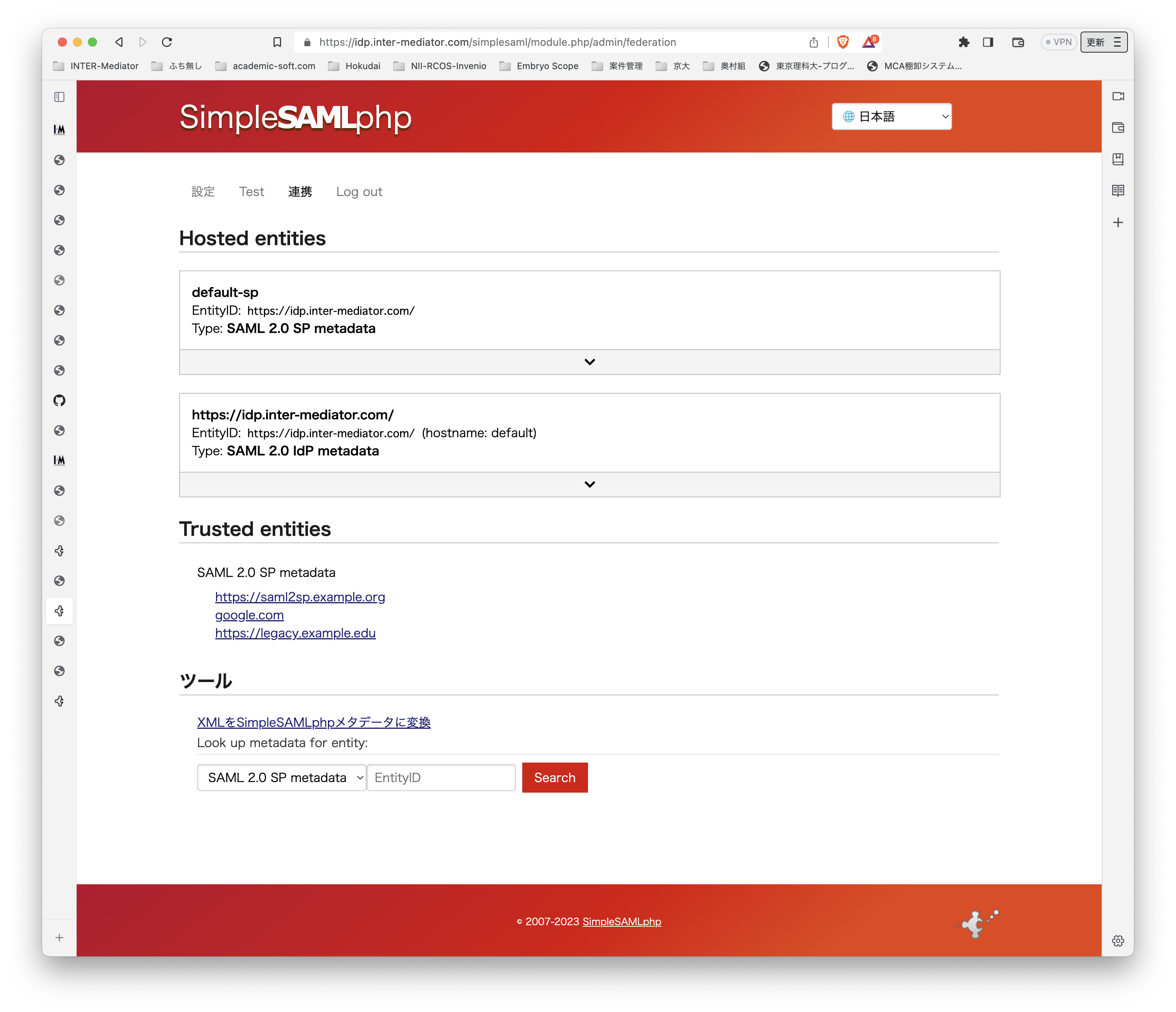
],SP側の設定はとりあえずこれでOKのようです。SPの管理画面に、authoauth2モジュールが稼働していることが見えています。
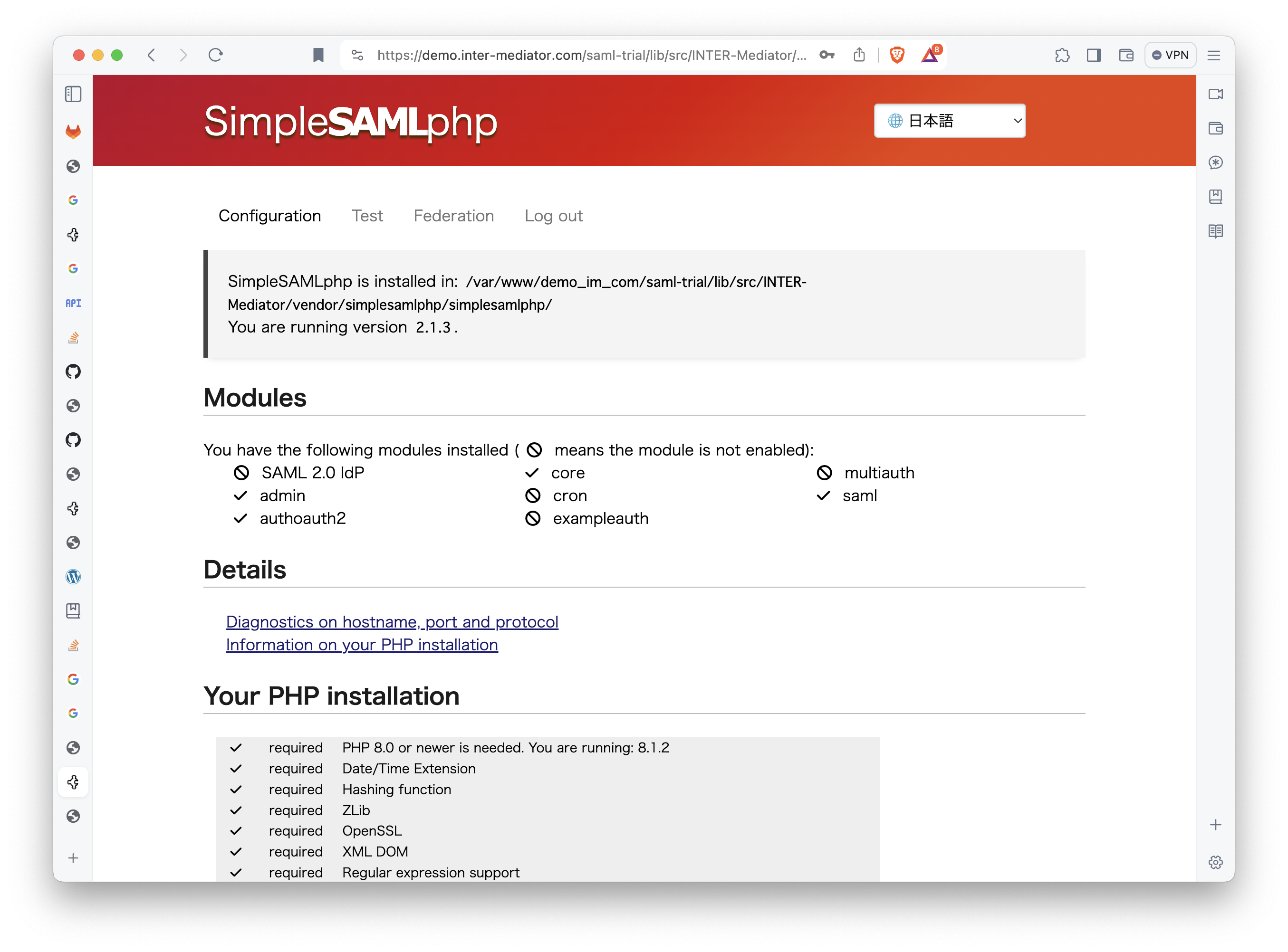
なお、Testのところに「google」というリンクが出ており、クリックするとGoogleのページを表示しますが、認証処理までには至りません。リダイレクトのURLが設定されていないというようなメッセージが見えます。
認証プロセスを通して見る
ここで実際に使用しているアプリケーションのURLは「https://demo.inter-mediator.com/saml-trial/chat.html」です。このURLと最初の方でGoogle Consoleで指定したリダイレクトURL「https://demo.inter-mediator.com/simplesaml/module.php/authoauth2/linkback.php」がこの後必要になります。これらのURLに加えて、MYCLIENTIDを含め、以下のURLの文字列をエディタ上などで整えます。URLEncodingをしてもいいのですが、問題ある文字列はないので、そのままこの文字列に置き換えて利用してもいいでしょう。そして、このURLをブラウザのアドレス欄に貼り付けて、Enterキーを押し、GoogleのOAuth2の認証プロセスに入ります。なお、URLの細かい点では別の機会に改めてきちんと処理すると言うことにして、まずは動く状態にしたいと思います。
https://accounts.google.com/o/oauth2/v2/auth?response_type=code&client_id=MYCLIENTID&scope=openid%20email&redirect_uri=リダイレクトURL&state=authoauth2|security_token%3D333344445555%26url%3DアプリケーションURL&nonce=0394852-3190485-2490358&hd=gmail.comstateはちょっと適当にしていますが、「authoauth2|」で始まっていないと行けないのは、このモジュールでの実装です。また、stateの中に「url=アプリケーションURL」と言う記述があって、そこが後から効いてきます。
ちなみに、OAuth2に対応したサイト等では、認証がなされていない場合に、GoogleやFacebookの認証プロセスに入るボタンを提供するかと思います。その場合、「Google」ボタンをクリックすると、上記のURLにリンクするような作りになっているはずです。FacebookならFacebookの認証システムへのURLにパラメータを設定してジャンプするようになっています。
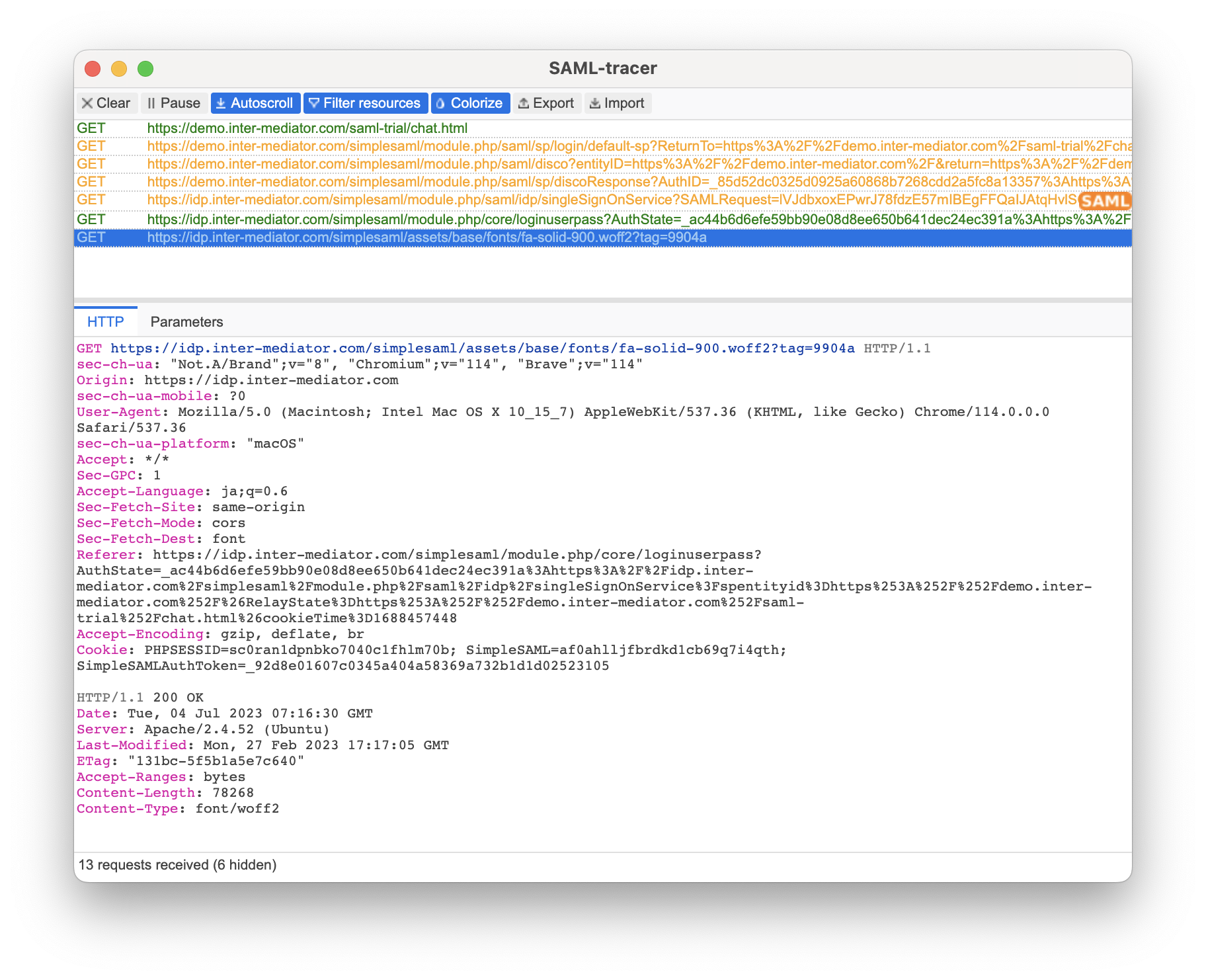
URLをブラウザのアドレス欄に入れると、Googleの認証の画面になります。状況は人によって違うのでしょうけど、いずれにしても、Googleの認証の画面になって、ログインしていない場合はユーザ名とパスワードの入力を行ないます。

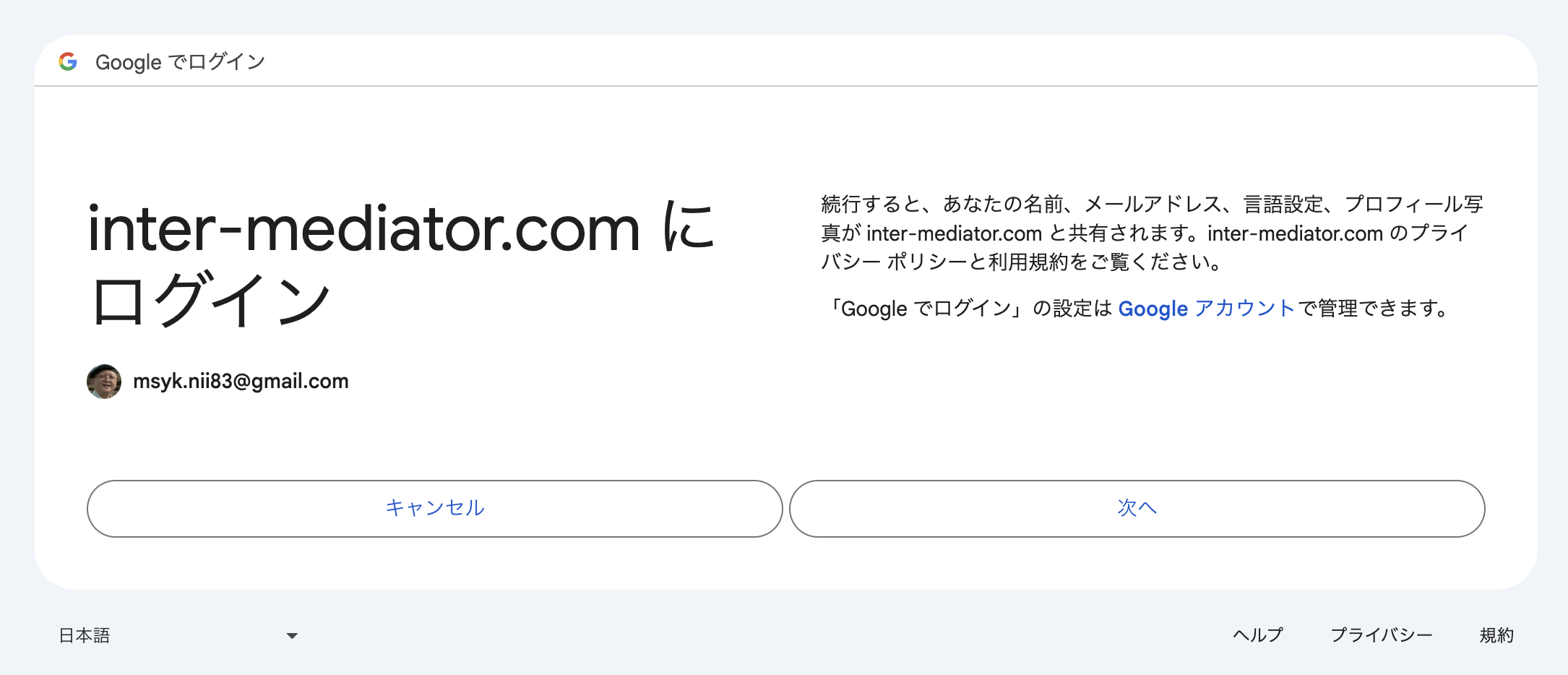
Googleの認証ページから、アプリケーションURLに指定したURLにリダイレクトされます。
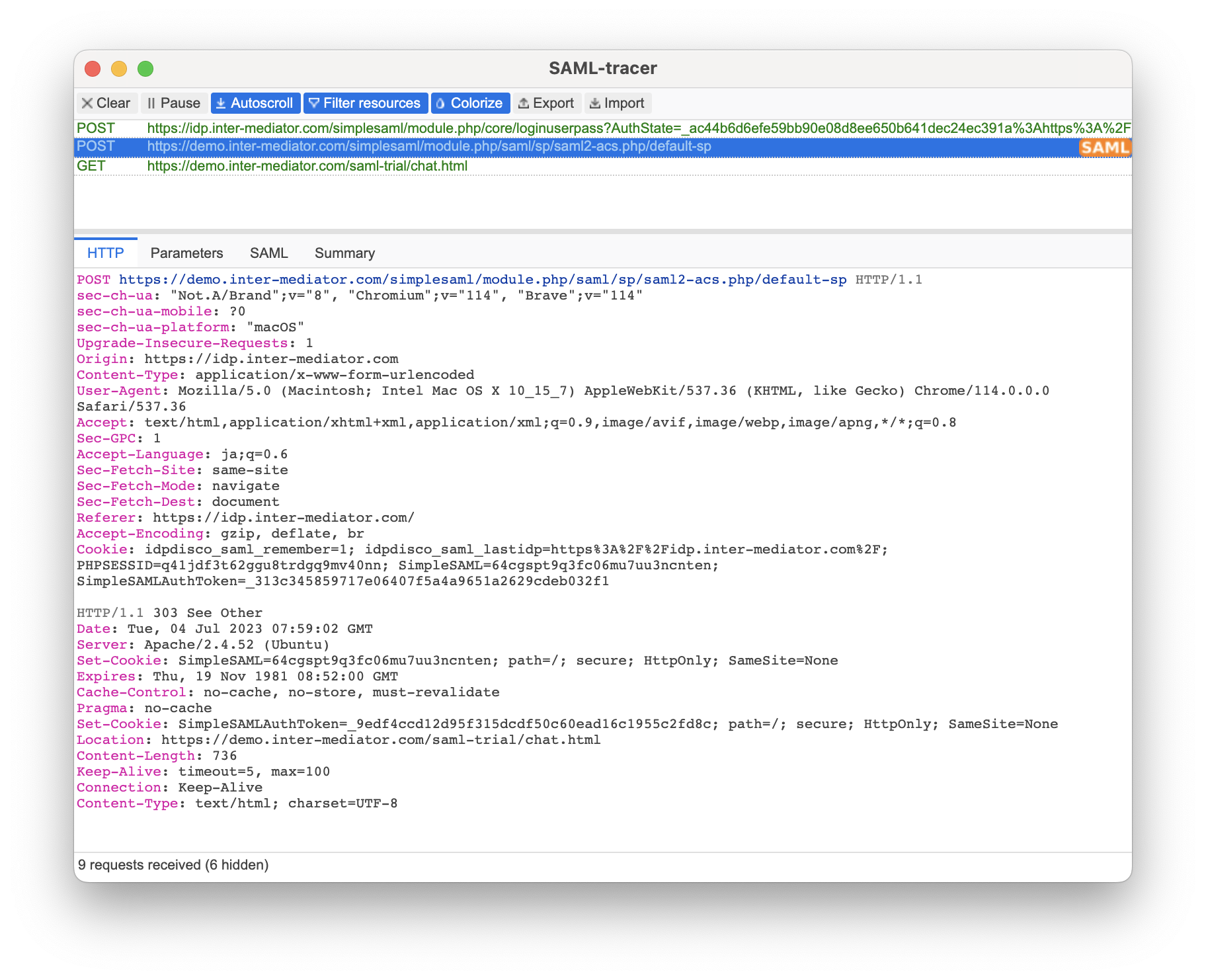
実のところ「よしOK!」とは行きません。INTER-MediatorのSAML対応では、このままでは認証を継続させる事ができないので、これからチェックしないと行けないのですが、アプリケーションURLに対しては、それよりも先にリダイレクトURLにアクセスし、さらにそこからアプリケーションURLへリダイレクトされているようで、GETメソッドで何のパラメータもありません。SAMLのクッキーがHTTP Onlyで乗ってくるだけのようです。ちなみに、SAML認証が成功すると、SimpleSAMLとSimpleSAMLAuthTokenという2つのクッキーが入るのですが、現状、IdP/SPいずれの側を利用しても、前者のクッキーしか入らず、後者は入ってこないのです。
(続報:2024-3-9)その後、色々やってみたのですが、認証が成功した状態のクッキーになりません。と言うことで、コードを読みました。simplesamlphp-module-authoauth2には認証後に返ってくるURL(linkback.phpで終わるもの)が記載されており、実際にそのリダイレクトURIが呼び出されています。そこをチェックすると、前述の「https://accounts.google.com/o/oauth2/v2/auth」に対するstateパラメータの値は、次のようになるはずです。色々試しているうちに、セッションデータが落ちてきたのでわかったことです。
state=authoauth2|_796bed184adf107c10c0faf60c658c7da54d2b0972:アプリケーションURL最初は「authoauth2|」である必要があります。リダイレクトされた最初の段階でチェックしています。続いて、|より後の文字列について、:で区切って、最初をid、最初の:以降をマージしてurlとしています。エラーがあると、そのurlにリダイレクトがします。セッションのデータが何かのきっかけで落ちてきた時に、そこからデータが取り出せるとしたら、|と最初の:の間は上記のコードか、もしくは「_eff7a14ba6adc55b6cd2f08b0399b747ed3ac9844e」である必要があります。このコード、ランダムに充てられている可能性もありますが、このデータで数回セッションデータが得られた後、セッションデータはほぼ空っぽのものばかりになってしまっていました。それで、SPの管理ページのログインテストを利用して、一度認証した状態にしておいて、アプリケーションを動かすと、今度は、セッションデータは何か大量に乗っかってきています。SimpleSAMLAuthTokenクッキーも来ました。しかし、その時のstateの|より後にくるべきコードは違うものでした。やはりランダムでした。このstateは最初にaccounts.google.comを呼び出すときに引数に指定しないといけないと言うことは、開発者が指定しないといけないと考えられますが、それを得る方法はわかりません。あるいは指定したコードが乗ってくるということなのかな?もうちょっとコードを追ってみようと思います。と言うことで、ここまでは行けました。ちょっとだけ進歩したかな。そうこうしているうちに、SimpleSAMLphpのVer.2.2.0が出ましたね。セッションのなかに、「アップデートしろー!」って情報がどっさり。